 夜雨聆风
夜雨聆风





AI大白话 004-拆解 AI:大模型的万亿参数是怎么来的?
AI大白话 004 篇
AI大白话,把“机器的话”翻译成“人的话”。每篇一个名词,让普通人秒懂AI。
你有没有见过这些新闻:
-
“GPT-3发布,拥有1750亿参数!” -
“国内某大模型参数突破万亿!”
每次看到这些数字,你是不是也好奇:参数到底是什么?为什么总拿它说事?它怎么从几百万涨到几万亿的?参数越多就越聪明吗?
今天我们用大白话,一次讲清楚。
先了解一下:大模型的“身体”长什么样?
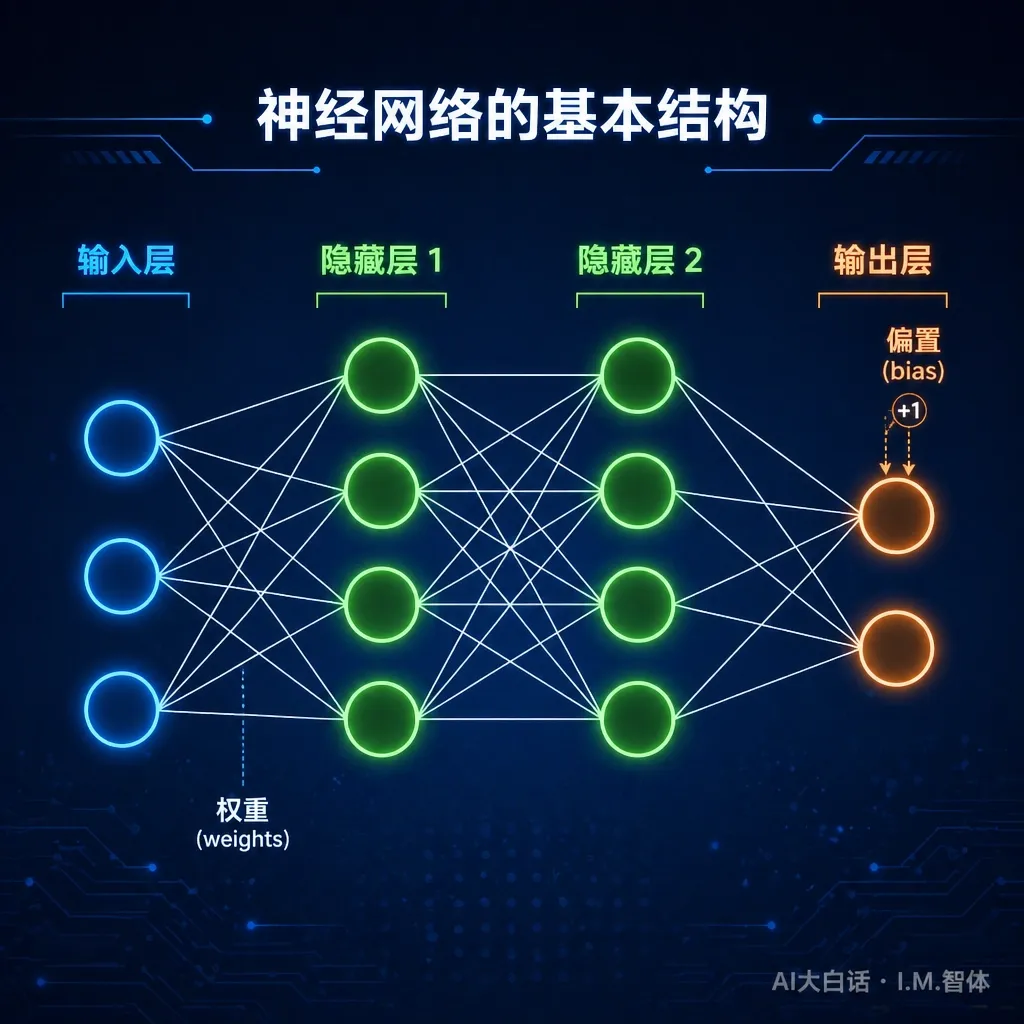
大模型的结构,是一种叫神经网络的东西。
为什么叫神经网络?因为它的设计灵感来自人脑——人脑里有几十亿个神经元,每个神经元和成千上万个其他神经元连接,信号在这些连接之间传递,形成了我们的思维。大模型模仿了这种连接方式,用计算机里的“数字神经元”层层叠在一起,“数字连接线”密密麻麻交织,组成了一个能学习和计算的大网。
这张网分三层:左边是输入层,接收你输入的文字;中间是隐藏层,一层一层地处理信息;右边是输出层,给出最终的答案。
接下来讲的“参数”,就是这张网里每一条连接线上的那个数字和连接线之间的神经元的偏置值之和。
第一步:参数的数量是怎么算出来的?
神经网络里每个节点叫神经元。
但神经元本身不是参数。参数是神经元之间的连接线。 每两个神经元之间有一条连接线,每条线上有一个数。此外,每个神经元自己还有一个额外的数,叫偏置。
总参数 = 连接线的数量 + 神经元的偏置数量。
GPT-3有1750亿参数,相当于这张网上有大约1740亿条连接线和约10亿个偏置。
一句话:参数不是神经元的个数,是连接线的条数加上神经元各自带的偏置数。数参数,是在数“线”为主,不是在数“点”。
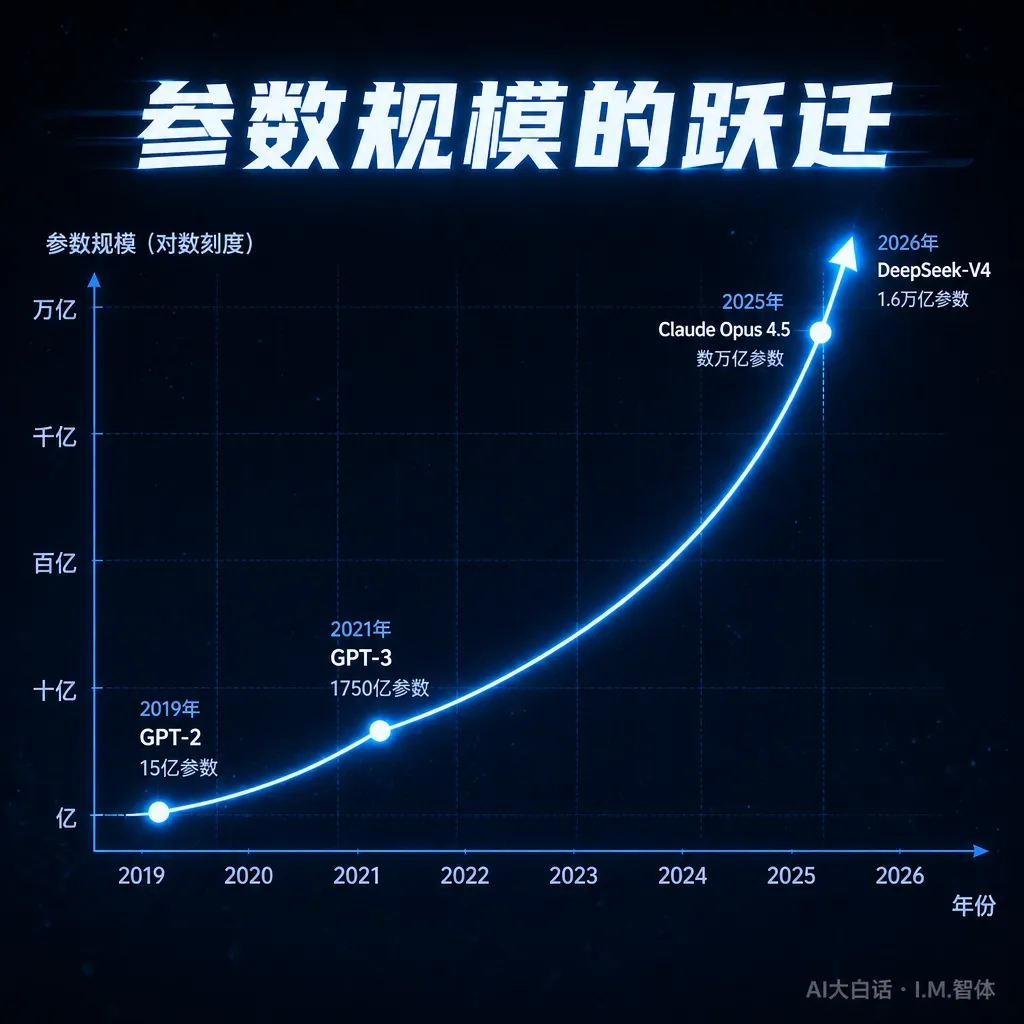
第二步:大模型的参数分哪两种?
参数分两种:权重和偏置。
权重的数量=连接线的线数量:决定“前面的神经元对后面的神经元有多大的影响”。
偏置的数量:部分神经元自带的数字:决定“这个神经元本身有多容易被激活”。
一句大白话:权重管连接线的影响力,偏置管神经元自身的敏感度(不是每个都有)。两种合在一起,就是大模型的“参数组成”。
第三步:每一个参数的数值是怎么定的?
参数不是人一个个设的,是训练中学出来的。
训练刚开始时,所有参数都是随机的。模型开始预测“床前明月___”的下一个字。一开始瞎猜,猜错了,系统会自动把所有参数往“下次猜对”的方向拧一点点。
反复拧几万亿次,1750亿个参数全部被调到了最优位置。
参数(权重和偏置值),就是大模型训练后留下的“记忆”。
第四步:万亿参数是怎么堆出来的?
参数变多,不是“多加几个神经元”那么简单。工程师主要靠三招:
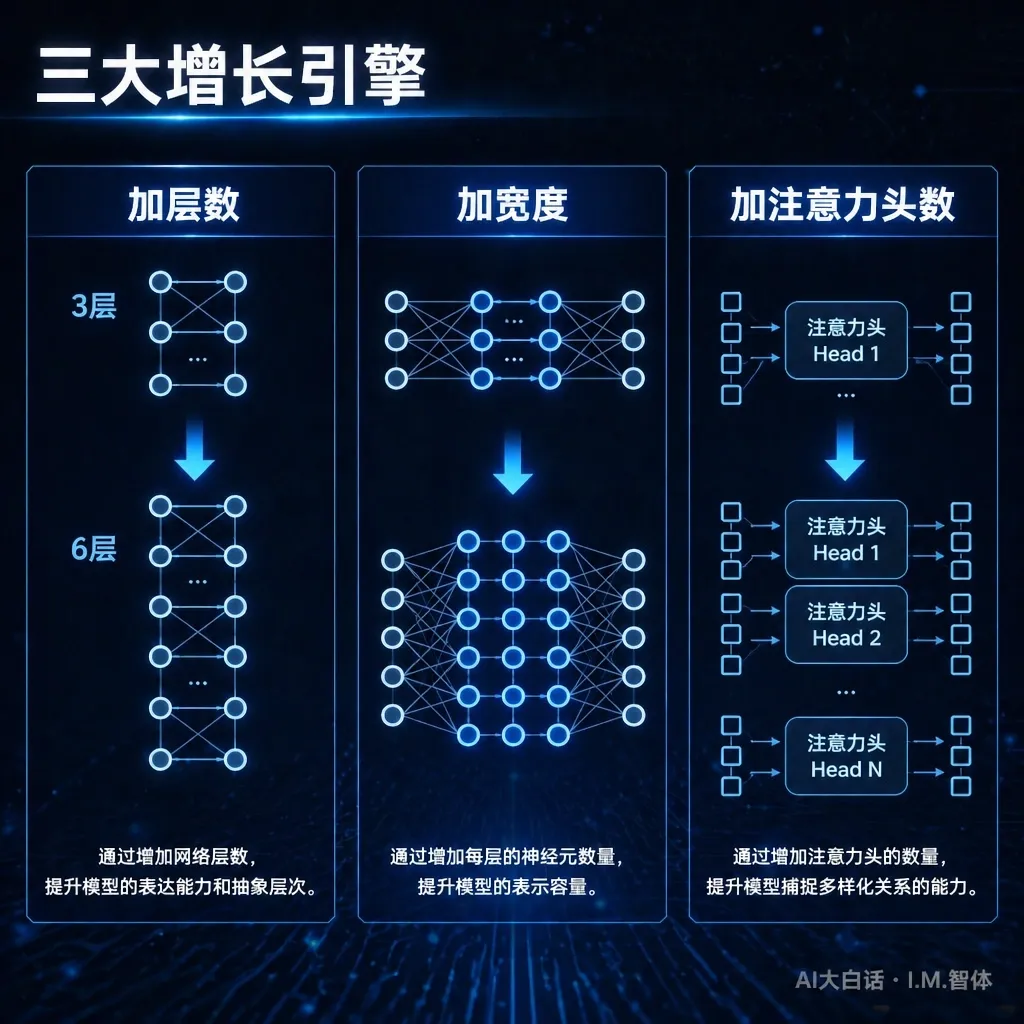
第一招:加层数。 隐藏层堆得更多。GPT-2只有12层,GPT-3堆到了96层。层数越多,连接线数量越庞大——因为每一层要和前后层的所有神经元全连接。
第二招:加宽度。 每一层的神经元数量也变多。GPT-2每层768个,GPT-3每层12288个。宽度翻倍,连接线数量翻四倍。
第三招:加注意力头数。 GPT-2只有12个头,GPT-3有96个头。每个头都有自己独立的Q、K、V权重矩阵。头数翻倍,这部分参数直接翻倍。
三招叠加:更深×更宽×更多头=参数从几亿飙到万亿。每一代新模型,工程师都会在这三个维度上同时加码。
一句话:加层数、加宽度、加头数,三招反复叠加,参数从几百万一路飙到几万亿。
第五步:参数越多越聪明吗?

是也不是,参数更多代表的是大模型训练后能力的上限。
参数越多,这张网就能织得越密,能存储的“规律”就越多。量变会引发质变——参数多到一定程度,模型会突然展现出没人教过却自己学会的新能力。
但参数不是一切。参数翻倍,算力成本翻几倍。参数再多,数据不够好模型也会“学歪”。现在最聪明的做法不是一味堆参数,而是用“混合专家架构”——总参数极大,但每次推理只激活最相关的一小部分,保持实力同时控制成本。
一句话:参数越多,天花板越高。但不是唯一因素——数据质量、架构设计和训练策略同样决定了模型最终有多聪明。
结尾
所以,下次看到“万亿参数”这种新闻,你可以这样理解:
大模型的结构是一种模仿人脑连接方式的神经网络——左边输入层、中间多层隐藏层、右边输出层,层层传递形成一张大网。参数就是网上每条线的数值,工程师通过加深、加宽、加多头让这张网越织越大。参数越多,天花板越高,但光有数量不够,还得有好的数据和聪明的架构。
