 夜雨聆风
夜雨聆风





你缺的不是更好的 AI,而是一个"装自己"的系统
将自己的记忆和能力沉淀成 AI 世界能看懂的信息。
写在前面
这篇文章记录了我近期的一个实践:把自己的经验、判断和偏好,变成 AI 可以直接调用的能力。
我管这个叫”把自己 Agent 化”。
为什么要”装自己”?
因为我发现一个规律:AI 越强,个人经验的沉淀反而越重要。
当所有人都在用同一个 GPT,你和别人的差距不在于”你用了什么模型”,而在于”你喂给它多少属于你自己的东西”。同样写一篇文章,有人能拿到 80 分的初稿,有人只能拿到 50 分——区别不是模型不同,而是后者没有把自己的风格、判断标准、过往经验”装进去”。
你的经验、你的判断逻辑、你反复做的事——这些才是你真正的个人资产。但它们目前只存在于你的脑子里,没有被结构化,没有被复用,更没有被 AI 调用过。
怎么”装自己”?
我把它拆成三个词:Memory、Skill、Eval。
-
Memory:把”你是谁、你怎么判断、你偏好什么”长期保存下来,让 AI 不需要你每次重新解释。 -
Skill:把你反复做的事——写文章、筛简历、蒸馏观点——封装成可复用的能力模块,不再每次从零写 Prompt。 -
Eval:每次用完给出反馈,让系统知道什么算”好”、什么算”不好”,越用越贴合你。
三者不是独立的功能,而是一个闭环:Memory 提供上下文 → Skill 执行任务 → Eval 给出反馈 → 反馈更新 Memory 和 Skill → 下一次更好。
这篇文章就是我用这个方法写的。 从收集灵感到蒸馏观点,从搭建 Memory 到调用 Skill 辅助写作,整篇文章的创作过程本身就是一次”个人 Agent 化”的实践。
下面展开说。
一、个人 Agent 化:到底在做什么
先把这个概念说清楚。
“个人 Agent 化”不是做一个虚拟人,不是搞数字分身,也不是让 AI 替你思考。
它做的是一件更朴素的事:
将自己的记忆和能力,沉淀成 AI 世界能看懂的信息。
“记忆”是你的背景、偏好、经验、判断标准——那些你希望 AI 每次都知道的东西。
“能力”是你反复做的任务、反复写的 Prompt、反复给出的判断——那些值得被封装成可复用模块的东西。
“AI 世界能看懂的信息”不是随便堆数据,而是有结构、有格式、有反馈标准的信息——AI 能直接调用、执行、并根据反馈改进的信息。
但这里有一个容易被忽视的边界:不是所有知识都能被沉淀。
沉淀的边界:冰山之下的隐性知识
我研究了一下知识论,发现一个很重要的概念:人类的知识像一座冰山。露出水面的,是能说清、能写明的”显性知识”——你的岗位、你的偏好、你的判断结论。但水面之下,是大量的”隐性知识”——那些说不清但就是知道的直觉、模糊的边界感、只可意会的判断。
比如,一个资深编辑扫一眼就知道一篇文章好不好,但让他解释”你怎么判断的”,他可能说不出几条明确的规则。这种”说不清但就是知道”的能力,是无数次实践沉淀出来的隐性知识。
所以,个人 Agent 化的第一步,不是”把所有东西都存进去”,而是先识别:哪些知识可以显性化,哪些需要保持隐性,如何在两者之间找到平衡。
能沉淀的是显性层,不能沉淀的是隐性层。好的系统,不试图把整座冰山都搬到水面以上。
这个区别很重要。我用一个对比来说明普通使用和个人 Agent 化的区别:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
本质上,普通使用是”每次租一个助手”,个人 Agent 化是”培养一个越来越懂你的搭档”。
但从技术的角度看,这个区别还有一个更本质的说法:普通使用是每次都调用”裸模型”——一个没有你任何个人印记的通用 AI。而个人 Agent 化,是在这个通用模型之上,构建了一层专属于你的个人化数据和能力。就像大模型训练中,预训练模型是通用的,但经过 fine-tuning 之后,它变成了某个领域的专家。你要做的,就是让你的 AI 经过”个人 fine-tuning”。
不是让它变成你,而是让它站在你的肩膀上。
二、三个问题,三个模块:Memory、Skill、Eval
我把个人 Agent 化抽象成三个核心模块。不是因为它们最全面,而是因为它们回答了三个绕不开的问题:
|
|
|
|
|---|---|---|
|
|
Memory |
|
|
|
Skill |
|
|
|
Eval |
|
这三个模块不是平行的三个功能,而是一个闭环:Memory 提供上下文 → Skill 执行任务 → Eval 给出反馈 → 反馈更新 Memory 和 Skill → 下一次更好。
┌─────────────────────────────────────────────┐│ 个人 Agent 的核心闭环 ││ ││ Memory(知道我是谁) ││ ↓ 提供上下文 ││ Skill(帮我做事) ││ ↓ 产出结果 ││ Eval(判断好不好) ││ ↓ 反馈 ││ 更新 Memory / 优化 Skill ││ ↓ ││ 下一次更贴近我 │└─────────────────────────────────────────────┘缺了任何一个,这个闭环都会断。
没有 Memory,Skill 每次执行都没有你的背景,输出就是通用的。没有 Skill,Memory 再丰富也只是数据,不能帮你完成具体任务。没有 Eval,你不知道输出好不好,系统就永远停在第一次的水平,无法迭代。
下面逐个深入说。
2.1 Memory:让 AI 知道你是谁
Memory 回答的问题是:当 AI 开始一个任务时,它已经知道了关于你的什么?
注意,Memory 不是资料库。不是把聊天记录全部堆进去,也不是把所有文件都塞进去。
Memory 的本质是:那些会影响未来判断和行动的信息。
一条”今天午饭吃了什么”不需要进 Memory。但以下这些需要:
身份和背景:
-
我是谁,做什么岗位,团队多大 -
我擅长什么、正在做什么方向
偏好和风格:
-
我喜欢什么样的表达方式 -
我讨厌什么样的输出(太空、太硬、太罗嗦)
经验和判断:
-
我在某个任务上做过什么决策,为什么这样做 -
我对某个方向的判断是什么,依据是什么
正在关注的事:
-
我最近在研究什么 -
哪些问题是我正在思考但还没结论的
但 Memory 不只是这些事实的堆叠。从知识的角度看,Memory 可以分成三个层次:
|
|
|
|
|---|---|---|
| 显性层 |
|
|
| 隐性层 |
|
|
| 情境层 |
|
|
拿我自己举例:
Memory 片段:显性层:身份:AI 算法团队 Leader,大模型后训练工程师方向:SFT、RL、自蒸馏、Agent RL、多模态偏好:结构化表达、有案例、有深度、不空谈禁忌:不要写得像论文,不要堆叠名词,不要纯技术教程隐性层:判断倾向:重视"最小闭环"思维,偏好先跑通再迭代风格直觉:喜欢用对比和类比解释概念,不喜欢直接给定义情境层:当前关注:个人 Agent 化、Memory 系统、Skill 工程、Eval 体系正在思考:隐性知识的边界在哪里?哪些经验可以沉淀,哪些只能靠实践传递?你会发现,显性层最容易被结构化,隐性层需要反复的 Eval 才能逐渐逼近,情境层几乎无法完全固化。 一个好的 Memory 系统,不试图把所有隐性知识都显性化——那样做会丢失精髓。它做的是:把能结构化的尽量结构化,同时在设计中为隐性知识保留空间。
Memory 的价值不是记得多,而是记得对。一条能影响未来决策的 Memory,比一百条无用的聊天记录有价值得多。
Memory 还有一个被忽视的作用:它是 Skill 的基础。 一个 Skill 要输出贴合你的结果,前提是它”知道你是谁”。这个”知道”就来自 Memory。没有 Memory,Skill 就是一个通用 Prompt,不是”你的”Skill。
这就像在大模型训练中,高质量的数据策划(Data Curation)决定了模型的上限。你的 Memory 就是你个人 AI 的”训练数据”——数据质量直接决定输出质量。
2.2 Skill:把经验封装成可复用能力
Skill 回答的问题是:当 AI 需要帮你完成一个任务时,它拿什么来执行?
你可能有这样的体验:有些任务你每隔几天就会做一次,每次都要写一个很长的 Prompt,把背景、要求、格式、偏好全写进去。写完一次,下次又得重写。
如果一个任务反复出现,它就不应该永远只是一个临时 Prompt。它值得被沉淀成一个 Skill。
Skill 和临时 Prompt 的根本区别在于:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一个 Skill,本质上是被结构化保存下来的经验。
它不只是”一段更长的 Prompt”,而是一个完整的执行单元:知道在什么场景下触发、需要什么输入、产出什么格式的输出、依赖什么 Memory、达到什么标准才算合格。
如果用技术类比来看:每个 Skill 就像是你在通用大模型上做的一次”任务微调”(Fine-tuning)。通用模型提供了基础能力(语言理解、逻辑推理),而 Skill 在这个基础上加入了针对特定任务的”参数”——你的偏好、你的格式要求、你的判断标准。所有 Skill 共享 Memory 这个”基础模型”,但各自有自己的”任务适配层”。
好的 Skill 应该”隐退”到背景中。
有一个认知科学的概念叫 From-To 结构:当你用锤子钉钉子时,你的注意力不在锤子上(From),而在钉子上(To)。锤子”隐退”为辅助意识,你才能专注在目标上。
Skill 也应该这样。当你调用一个”外部观点蒸馏 Skill”时,你的焦点是文章的内容本身,而不是 Skill 的操作。如果一个 Skill 让你觉得”我是在操作工具”,那它设计得还不够好。
2.3 Eval:让系统越用越好
Eval 回答的问题是:AI 怎么知道它做的好不好?以及怎么才能做得更好?
这是三个模块里最容易被忽略、但对长期价值最关键的。
想想看:如果你每次用完一个 Skill,只是觉得”还行”或”不太好”,但没有记录具体哪里好、哪里不好,那这个 Skill 永远停在 v1.0。它不会因为你用了 100 次就变好。
没有 Eval,Agent 只是一个更复杂的 Prompt Collection。
从技术的角度看,Eval 其实就是一个个人版的反馈学习系统。在大模型训练中,RLHF(基于人类反馈的强化学习)让模型从人类的偏好中学习”什么叫好、什么叫不好”。Eval 做的是同样的事,只不过规模更小、更个人——它让系统从你的反馈中学习”什么叫好、什么叫不好”。
反馈不是单向的——Eval 有三个方向:
-
向上反馈:优化现有的 Memory 和 Skill(”输出太啰嗦”→更新 Memory 偏好) -
向下反思:质疑知识框架本身(”我的判断标准对吗?”→重新审视 Memory 的结构) -
横向连接:发现不同 Skill 之间的隐藏关联(”简历打分的标准也可以用在文章评审上”)
只有向上反馈,系统会陷入局部最优——越用越贴合你,但贴合的是”过去的你”。加上向下反思和横向连接,系统才能真正进化。
Eval 不需要一开始就搞得很工程化。不需要自动化测试,不需要 benchmark。早期的 Eval 可以非常轻量:
通用 Eval 问题(每次用完 Skill 后问自己):
-
这次输出有没有节省我的时间? -
是否符合我的表达风格? -
是否抓住了真正重要的点? -
我最后手动改动了哪些地方? -
是否需要更新 Memory 或 Skill?
场景 Eval(按任务定制):
比如一篇文章草稿好不好,我看:有没有真实经历、主线是否清晰、概念是否过载、目标读者能不能看懂。
比如一次简历打分好不好,我看:有没有识别出强信号、有没有指出风险、面试验证点是否有价值、和我的判断是否一致。
关键在于:Eval 的结果要回流到系统。
一次 Eval 发现”输出太啰嗦”,就应该更新 Memory 中的偏好,或者更新 Skill 的输出模板。这样下次就不会犯同样的错。
Eval 闭环:Skill 输出结果 ↓我判断好不好(Eval) ↓好 → 记录成功模式,固化到 Memory不好 → 分析原因,更新 Memory 或 Skill ↓下一次输出更贴近我Eval 不一定一开始就自动化,但一定要被记录。没有反馈,Skill 就永远停在 v1.0。
2.4 三者关系:不只是功能组合,而是一个学习系统
最后用一张图把三者的关系收一下:
Memory ──── 提供上下文 ────→ Skill ↑ │ │ ↓ │ 执行任务 │ │ │ ↓ └──── 反馈更新 ←──── Eval(判断好不好)-
Memory 是土壤:没有它,Skill 长出来就是通用的,不是”你的” -
Skill 是工具:没有它,Memory 再丰富也只是数据,不能帮你做事 -
Eval 是方向盘:没有它,系统永远不会变好,用 100 次和用 1 次没有区别
但我想说得更深一点。这三者的闭环,不只是简单的”功能组合”,而是一个涌现系统——当 Memory、Skill、Eval 持续交互,会产生超越各部分总和的新能力。
举个真实例子:我有一个”简历打分 Skill”,最初只是把评分标准结构化。但随着 Eval 反复作用,Skill 进化了——它开始能识别”潜在风险信号”,这是我从没显式教过它的。为什么?因为我的 Eval 反馈中包含了大量的隐性判断(”这个经历我觉得不对劲”),这些反馈被反复输入后,系统”涌现”出了识别风险模式的能力。
这不是魔法。这就像大模型在训练过程中”涌现”出推理能力一样——不是被显式编程的,而是从大量数据交互中自组织出来的。
三者合一,不只是 1+1+1=3,而是让系统开始拥有从你的经验中”学习”的能力。这才是个人 Agent 化的最小单元。
三、先别做大系统,先做一个最小闭环
理清了 Memory、Skill、Eval 三者的关系,接下来的问题是:怎么开始?
说实话,一开始我也想搞一个完整的个人 Agent OS。架构图画得很大,名词列了很多,工具选了一堆。但冷静下来一想,那样很容易变成”看着很酷,跑通的东西很少”。
所以我先把目标缩小到一件事:
做一个最小闭环:让日常输入能被记录、判断、转化、使用和反馈。
日常输入(想法、文章、工作记录) ↓结构化记录(飞书多维表格) ↓Agent 辅助判断(这个输入值得沉淀吗?) ↓转化成 Memory / Skill / 素材 ↓实际调用一次 Skill ↓我给出反馈(Eval) ↓更新 Memory 或 Skill我知道你可能在想:”我哪有时间做这些?””我的经验真的值得沉淀吗?””万一做不好怎么办?”
我经历过同样的犹豫。但当我真正跑通一次闭环——把一个零散想法丢进去,看着它变成 Memory、被 Skill 调用、产出有用结果——我发现这件事不像想象的那么重。它不是”搭系统”,而是”改习惯”。从”看完就忘”变成”看完进入系统”,从”每次从零开始”变成”每次站在上一次的肩膀上”。
举一个真实的例子。
以前:我看到一篇关于 Agent Memory 的文章,觉得很有启发,收藏了。几天后,可能就忘了。
现在:我会把它丢给”外部观点蒸馏 Skill”。它帮我输出:核心观点是什么、和我当前关注的问题有什么关系、哪些值得变成 Memory、哪些可以改进某个 Skill。然后我反馈:哪些提炼有价值,哪些太空,哪些该写入长期 Memory。
这样一次阅读就不只是”看过”,而是进入了系统。
一个最小闭环,比一个宏大的概念更重要。先让输入能沉淀,再谈系统能进化。
四、入口和工具:我用什么把这一切串起来
入口我选了飞书,工具用了三个。这部分不展开,简单带过。
为什么是飞书
个人 Agent 的入口不一定要酷,但一定要离真实场景足够近。
飞书适合承载:文档(沉淀想法)、多维表格(记录 Memory、Skill、Eval)、日报周报(工作痕迹)、机器人(轻量交互)、知识库(整理后的信息)。
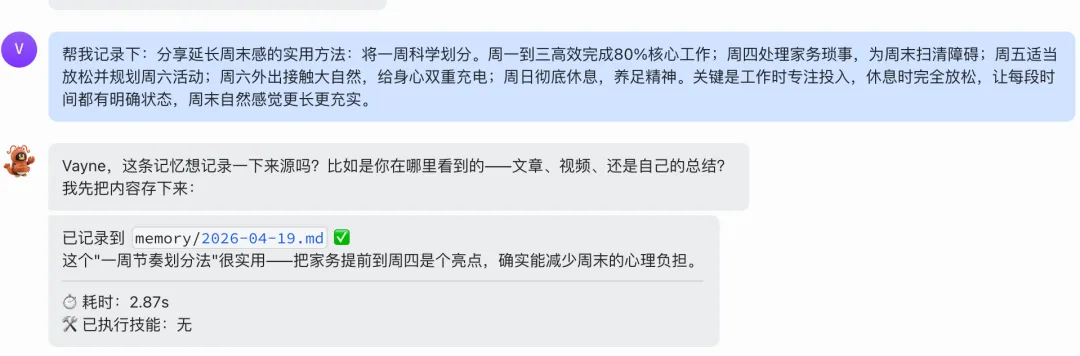
我设计了一个多维表格,字段如下:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
飞书只是一个承载容器。真正重要的是,我开始用结构化方式记录自己的输入、判断和反馈。
工具链
Claude Code:Anthropic 的命令行 AI 工具,所有 Skill 的编写、调试、调用都在这里完成。安装一行命令:
npm install -g @anthropic-ai/claude-code --registry=https://registry.npmmirror.com提示:需要 Node.js 18+,Mac 用户
brew install node即可。 后面再装一下cc-switch,地址是https://github.com/farion1231/cc-switch/releases/download/,选择合适版本,并找一下各个主流大模型厂商的api key。
openclaw:开源 Agent 框架,部署在腾讯云轻量服务器上,2 核 4G 够用。
现在openclaw/hermes在主流云服务器厂商都有一键安装版本的服务器租用。 以openclaw为例,去控制台https://console.cloud.tencent.com/,简单配置下即可。
Hermes:轻量消息调度,把飞书输入转发到 Agent 后端。
工具本身不复杂,复杂的是你要沉淀什么、怎么判断、怎么反馈。 工具链的搭建细节留到后续文章展开。
五、我先做的几个 Skill
前面讲了 Memory、Skill、Eval 的框架,现在落地。
但在讲我自己的 Skill 之前,我想先推荐一个东西——SkillHub。这是目前国内最大的 Claude Code Skill 社区,有超过 35,000 个开源 Skill。我先装了 10 个最实用的,再慢慢叠加自己的。
5.1 社区必装 Skill Top 10
完整排行榜见 skillhub.cn,下载量实时更新。
统一安装方式:在 Claude Code 中直接说”帮我安装 xxx skill”,或访问 skillhub.cn 复制安装命令。
|
|
|
|
|
|
|---|---|---|---|---|
|
|
self-improving-agent |
|
|
|
|
|
summarize |
|
|
|
|
|
find-skills |
|
|
|
|
|
github |
|
|
|
|
|
agent-browser |
|
|
|
|
|
ontology |
|
|
|
|
|
word |
|
|
|
|
|
excel |
|
|
|
|
|
nano-pdf |
|
|
|
|
|
obsidian |
|
|
|
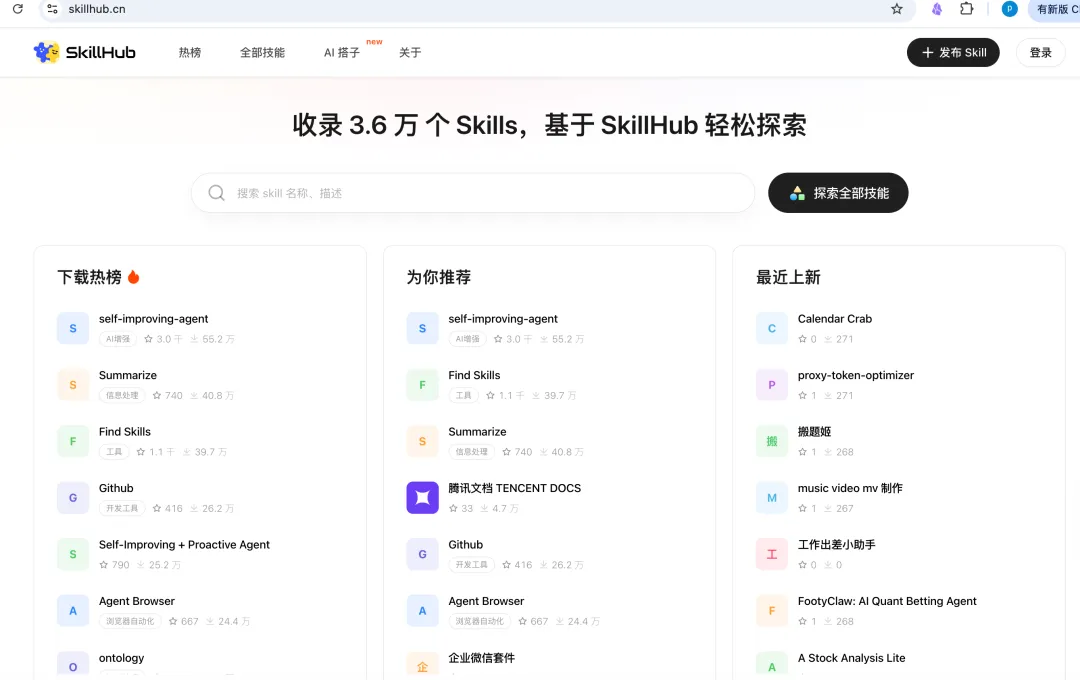
这 10 个 Skill 是”基础设施”——文件处理、信息获取、知识管理、自我进化都覆盖了。装完这些,你的 Agent 已经比 90% 的用户强了。
下面是我自己在基础设施之上叠的几个个性化 Skill——解决我个人高频场景的。
5.2 外部观点蒸馏 Skill:把”看过”变成”吸收”
场景:经常读到很有启发的文章或访谈,当下觉得好,收藏,过几天忘了。
这个 Skill 做什么:不是总结原文,而是回答——这个观点对我有什么用?能进 Memory 吗?能改进 Skill 吗?
示例:
输入:某篇文章认为,Agent 的关键不是固定工作流,而是长期记忆和环境反馈。输出:原始观点:Agent 应该能根据反馈持续调整,不是静态 workflow。我的理解:这和个人 Agent 化高度相关。 没有反馈机制,就只能执行旧流程,不能变得更贴近我。可沉淀 Memory:个人 Agent 需要反馈闭环,不是一次性工作流。可改进 Skill:给 Skill 模板增加 Eval 字段。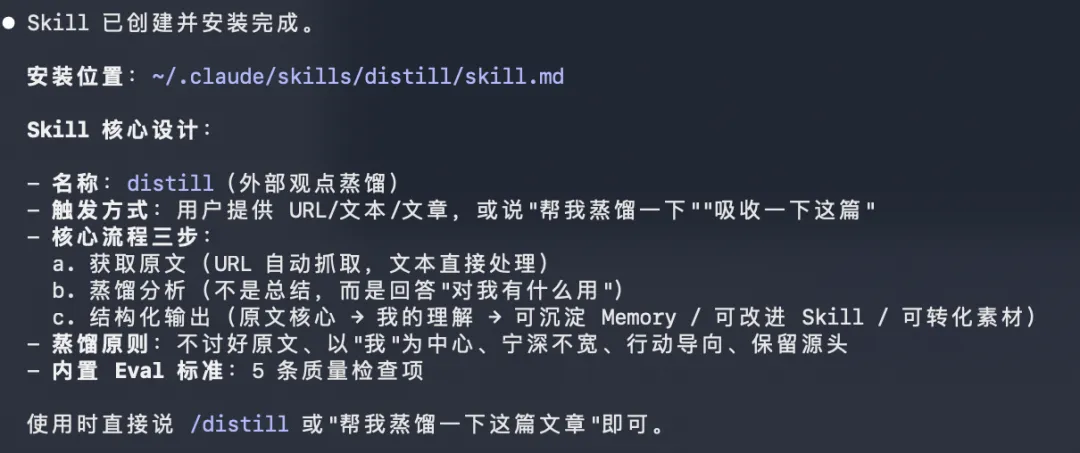
这个 Skill 的核心不是总结别人,而是把外部思想转化成对我有用的能力增量。
5.3 大佬头脑风暴 Skill:让高手替你审视问题
场景:遇到方向性问题,自己的视角容易受限。比如”个人 Agent 应该先做 Memory 还是先做 Skill?”
这个 Skill 做什么:模拟多个”虚拟顾问”,从不同角度审视同一个问题,给出推理过程和取舍分析,最后总结共识和冲突。
输入:个人 Agent 的核心是 Memory 还是 Skill?输出(多视角):产品视角:先解决用户最痛的点——"每次重新解释自己",所以先做 Memory。工程视角:Skill 更容易验证效果,先做一个 Skill 跑通闭环再说。认知科学视角:人的学习是"记忆→模式→技能"三步,Memory 是基础。创业视角:早期用户最在乎的不是系统完整度,而是"有没有一个东西真的帮到我了"。共识:Memory 和 Skill 不应该二选一,而应该一起跑通最小闭环。冲突:先做哪个取决于你的验证目标——是验证"能记住我"还是验证"能帮我做事"。


这个 Skill 的价值不是替你做决策,而是帮你看到自己看不到的角度。
5.4 日报 / 周报整理 Skill:把工作痕迹变成记忆
场景:日报周报不只是汇报,它记录了你做了什么、遇到了什么、判断了什么。这些信息是非常好的 Memory 来源。
这个 Skill 做什么:不只是生成汇报文字,而是帮你提炼:本周解决了什么问题、暴露了什么风险、哪些经验值得进入 Memory。
输入:今天梳理个人 Agent 文章结构,收敛主题,决定聚焦"不要从零开始"。设计了飞书多维表格字段和核心 Skill。输出:关键思考:个人 Agent 的早期价值不是自动化,是让经验可以沉淀、复用和反馈。风险:如果堆叠名词,读者会觉得抽象,需要用案例收住。可沉淀 Memory:第一篇文章主线已确定为"Memory + Skill + Eval 最小闭环"。
日报周报不是为了应付管理,而是为了把工作痕迹变成可复用记忆。
5.5 简要提两个
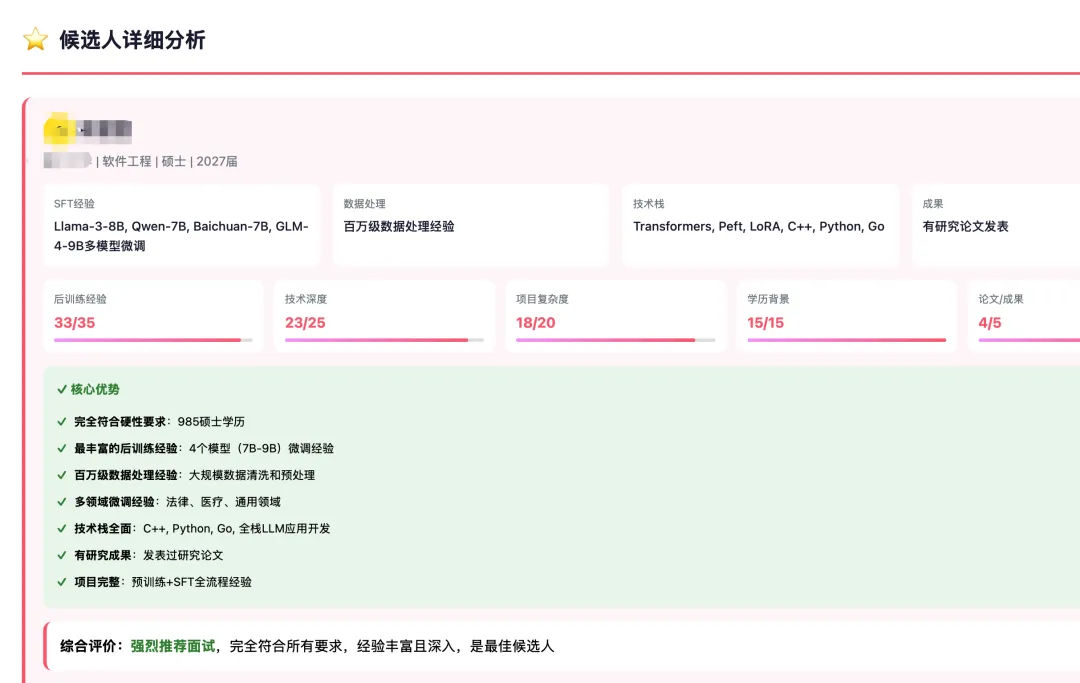
简历打分 Skill:把岗位要求、核心能力、候选人优势/风险、面试验证点拆成固定字段。当评分标准被反复使用和修正,它就不只是一个 Prompt,而是一个可以演化的招聘 Skill。这给了我一个启发:很多 AI 应用的关键,不是让模型自由发挥,而是把一个人的判断标准结构化。

Skill Creator(非常常用!!!):帮我判断一个重复任务是否值得沉淀,并把它包装成 Skill。每个 Skill 都遵循统一模板——名称、场景、输入、输出、偏好、依赖 Memory、Eval 标准、更新记录。

Skill Creator 的意义在于:我的系统不只是拥有 Skill,而是开始拥有制造新 Skill 的能力。
写在最后
这个系统现在还很早期。很多地方需要人工判断,很多 Eval 没有自动化,有的 Skill 用得好,有的还在调。
但我想说一个判断:
个人 Agent 化的本质,是将自己的记忆和能力沉淀成 AI 世界能看懂的信息。
不是让 AI 替你思考,而是让 AI 在帮你时,已经站在你的肩膀上。
不是做一个完整的系统,而是先让 Memory、Skill、Eval 跑通一个最小闭环。
不是追求自动化一切,而是让自己不再每次从零开始。
Memory 是土壤——让 AI 知道你是谁。Skill 是工具——让 AI 帮你做你反复做的事。Eval 是方向盘——让系统用一次比一次好。
三者合一,不只是功能组合,而是让系统拥有从你的经验中学习的能力。你的经验不再随着时间流逝,你的判断标准不再每次从零开始,你的能力可以被复用、被迭代、被放大。
这是这个五一小实验教我最重要的一件事。
下一篇,我想聊一个更具体的问题:当外部信息越来越多时,个人 Agent 如何帮你过滤信息、吸收观点,并把它们转化成新的 Skill。
附录
A. 文中提到的工具
|
|
|
|
|---|---|---|
| Claude Code |
|
docs.anthropic.com/en/docs/claude-code |
| openclaw |
|
|
| Hermes |
|
|
B. SkillHub 必装 Top 10
完整排行榜见 skillhub.cn
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
C. 我的个性化 Skill
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
C. 核心观点
-
个人 Agent 化的本质,是将自己的记忆和能力沉淀成 AI 世界能看懂的信息。 -
普通使用是”每次租一个助手”,个人 Agent 化是”培养一个越来越懂你的搭档”。 -
能沉淀的是显性层,不能沉淀的是隐性层。好的系统,不试图把整座冰山都搬到水面以上。 -
Memory 的价值不是记得多,而是记得对。 -
一个 Skill,本质上是被结构化保存下来的经验。 -
没有 Eval,Agent 只是一个更复杂的 Prompt Collection。 -
三者合一,不只是 1+1+1=3,而是让系统开始拥有从你的经验中”学习”的能力。 -
一个最小闭环,比一个宏大的概念更重要。