 夜雨聆风
夜雨聆风





阿姆斯特丹如何借助AI讲好城市故事
今天,几乎每座城市都在谈更新,谈文旅,谈品牌,谈流量,谈年轻人,谈城市IP。但城市IP如果只停留在符号层面,很容易变成空洞的视觉包装。真正有生命力的城市IP,应该来自城市自身的记忆深处。——而阿姆斯特丹所做的尝试,或许可以给很多城市参考。2025年,阿姆斯特丹迎来建城750周年。围绕这个特殊节点,阿姆斯特丹市档案馆与 Capgemini、微软合作,推出了“与历史聊天”(Chat with History)项目。
引子——1574年,一封来自汉堡商人的抗议信

1574年,一个来自汉堡的商人,带着谷物驶向阿姆斯特丹。他的名字叫 Jan Lambertsz。这原本应该是一趟普通的生意:从易北河流域收购谷物,运到荷兰港口出售,换回利润,再继续下一段航程。可事情很快失控。船在途中被扣押,货物损失了一半。等他终于抵达目的地,当地官员又告诉他:这批谷物不能在这里出售。
对于一个异乡商人来说,这几乎是灭顶之灾。Jan Lambertsz 没有坐以待毙。他的同乡 Mertyn 和 Heynric Gherytsz 兄弟,代表他向当局递交了一封正式抗议信。信里写得很清楚:汉堡商人一直按规矩缴纳通行费、关税,甚至为航海基础设施额外付费。既然他拥有合法许可,为什么到了阿姆斯特丹却无法交易?[1]
这封信后来被保存了下来。之后发生了什么,我们已经不得而知。Jan Lambertsz 是否拿回了损失?那批谷物最后有没有卖出去?他是否还会再来阿姆斯特丹?历史没有给出答案。但近450年后,他的名字又一次浮现出来。
不是因为一位历史学家偶然翻到了这封信,也不是因为某本新书重新书写了这段往事,而是因为一次普通的AI问答。工作人员向系统提出一个关于16世纪贸易纠纷的问题。系统在档案中检索、识别、翻译、摘要,最终定位到这封抗议信。一个被尘封在纸堆里的普通商人,突然重新出现在今天的屏幕上。
这件事发生在阿姆斯特丹750岁生日之际。这是一个AI技术的应用案例,但真正重要的地方并不只是技术。它提示我们:一座城市的历史,不应该只是被妥善保存;它还应该能够被重新提问、重新讲述,并重新进入今天的公共生活。
一、城市故事的第一步,让资料可被进入
阿姆斯特丹市中心有一座庄严的建筑,名叫 De Bazel。这里是阿姆斯特丹市档案馆的所在地,也是这座城市750年记忆的栖身之所。从1275年荷兰伯爵弗洛里斯五世颁发那纸通行费豁免特许状算起,阿姆斯特丹已经走过七个半世纪。那份特许状被视为城市的“出生证明”,至今仍被小心保存在档案馆里。

如果走进档案馆库房,会看到一排排密集架从地面延伸到天花板。羊皮纸卷、商人信件、教会登记簿、城市图纸、港口记录、家族文书、照片和地图,层层叠叠地保存着这座城市漫长的生命。Capgemini 的项目介绍称,阿姆斯特丹城市档案馆保存着约50公里长的纸质档案,内容覆盖数百万份文档、地图、信件和登记簿。[2]
这听起来是一座城市令人羡慕的记忆宝库。但问题是:宝库并不等于公共记忆。
很长一段时间里,档案馆保存的是城市历史,却未必真正向普通人敞开。它当然可以被访问,可以被研究,可以被申请查阅,但对于大多数人来说,档案馆仍然是一种“看得见却进不去”的知识系统。
第一道墙,是语言。16世纪的信件不是现代英语,也不是今天普通人熟悉的荷兰语。它们常常写成古荷兰语,且多为手写。字母连笔、缩写复杂、墨迹模糊,很多地方像虫子一样蜷曲在纸面上。你可以看到扫描件,却无法真正读懂它。
第二道墙,是检索。即使一份档案已经完成数字化,普通人也未必知道怎样找到它。你需要理解档案馆的分类方式,知道全宗、目录、索引、关键词之间的关系,也需要具备某种专业训练,才能在海量资料中定位到真正有用的内容。
第三道墙,是解释。哪怕你读懂了单份文献,也未必知道它与一座城市的经济、贸易、空间、制度和日常生活有什么关系。Jan Lambertsz 的抗议信本身只是一份文件,但它背后牵涉的是16世纪的港口贸易、城市治理、跨境商人网络、通行税制度和地方官僚体系。没有解释,一份档案很难自动变成一个故事。
所以,城市要讲好故事,第一步不是文案,而是知识组织。所谓“讲好城市故事”,不能只理解为写几句漂亮口号,或者提炼几个传播标签。更底层的工作,是把沉睡的资料变成公众可以进入的知识结构。
二、数字化不是终点,可被理解才是开始
过去许多年,阿姆斯特丹市档案馆一直在推进数字化工作。基础数字化的第一步,是扫描。让纸质档案变成图像,让人们可以通过网站远程查看。这个过程已经极大改善了档案的可访问性。
但扫描并不等于理解。一张16世纪手稿的高清图片,只是把原本放在库房里的困难搬到了屏幕上。纸张纹理更清楚了,墨迹更完整了,印章和折痕也被忠实记录了下来。可如果你仍然读不懂上面的文字,它就依旧是一份沉默的图像。
因此,真正关键的一步,是让手写文本变成机器能够识别、检索、分析的文字。这里涉及的不是普通意义上的OCR,而是 HTR,也就是 Handwritten Text Recognition,手写文本识别。传统OCR主要面对印刷文字,字体相对稳定,版面结构也更可预测;而历史手稿面对的是不同人的笔迹、不同年代的书写习惯、模糊破损的纸面,以及不断变化的语言形态。Transkribus 对 HTR 的解释是:它使用深度学习神经网络,将手写文本图像转换为机器可读字符;与印刷文本OCR不同,HTR必须处理人类手写中近乎无限的变化,包括不同字母形态、连笔和个人书写风格。[3]

更具体地说,一份历史文档进入AI系统之前,通常要经过一条“档案数据流水线”:第一步是图像采集与清洗,尽可能提高扫描质量;第二步是版面分析,识别正文区、页边注、表格、印章、插图等不同区域;第三步是行检测,把页面切分成可识别的文字行;第四步是字符或词级别识别,将笔迹转化为机器文本;第五步是人工校对和置信度管理,对模型不确定的文字进行修订;第六步是结构化导出,把结果保存为可被后续检索、分析和长期保存的格式。
这意味着,所谓“让历史开口说话”,并不是把一堆扫描件直接丢给大模型。它背后真正困难的地方,是把非结构化、不可读、不可检索的历史材料,逐步转化为可计算、可索引、可追溯的知识对象。
这也解释了为什么许多城市虽然有大量档案、地方志、老照片和文献,却仍然讲不好自己的故事。因为资料存在,不等于知识形成;知识形成,也不等于公众能够进入;公众能够进入,才真正接近城市叙事的开始。
三、AI讲故事,不是凭空生成,而是检索增强
如果只从用户界面看,阿姆斯特丹的“Chat with History”像是一个聊天机器人。但如果从系统架构看,它更接近一个面向历史档案的 RAG 系统,也就是 Retrieval-Augmented Generation,检索增强生成。
RAG 的基本逻辑,不是让大模型凭记忆回答,而是在生成答案之前,先从可信知识库里检索相关材料,再把这些材料作为上下文交给模型组织回答。微软文档对 RAG 的解释是:它将搜索与大语言模型结合,使回答建立在用户自己的数据和检索到的依据之上;当需要基于私有数据或频繁变化的信息作答时,RAG 可以先检索相关信息,再把这些信息作为 grounding data 提供给模型,并生成带有来源引用的回答。[4]
对于历史档案而言,RAG尤其重要。因为档案不是百科知识,也不是大模型训练语料中稳定存在的常识,而是具体、稀缺、局部、有来源的原始材料。如果没有检索和溯源,大模型很容易把“可能如此”说成“确有其事”,把风格化的历史叙事误认为真实档案内容。这对于公共文化系统来说是危险的。
一个更严谨的档案RAG系统,至少包含四个层次。第一层是原始档案层,包括扫描图像、元数据、目录信息、馆藏编号、版权与访问权限。第二层是文本化层,包括HTR转写结果、人工校对版本、不同语言的翻译文本,以及每一段文本对应原图的位置。第三层是索引层,包括关键词索引、向量索引、时间地点人物标签、主题分类、档案类型字段。第四层才是生成层,也就是用户看到的自然语言问答、摘要、解释、推荐和多语言输出。
这四层里,最容易被普通读者忽略的,是索引层。因为它决定了用户问出一个问题后,系统究竟能不能找到正确材料。现代AI检索通常不会只依赖关键词,而会引入向量检索。所谓向量,就是把一段文本转化为高维数字表示,让机器能够判断“语义相近”,而不只是“字面相同”。Azure AI Search 的技术文档解释说,向量搜索支持对内容的数值化表示进行索引和查询,因此可以匹配与查询向量最相似的内容;它也支持语义相似、多语言内容以及多模态内容的检索。[5]
但向量检索也不是万能的。历史档案中有大量专名、地名、时间、货币单位、职位名称、机构名称,如果只靠语义相似,可能会漏掉关键的精确匹配。因此更稳健的做法,是混合检索:同时运行关键词搜索与向量搜索,再合并结果。Azure AI Search 的文档也明确提到,混合搜索会在同一个请求中并行运行向量搜索和关键词搜索,并把结果合并为统一排序的结果集。[5:1]
这正是档案系统需要的技术特征:既要能找到“17世纪贸易纠纷”这种语义问题,也要能锁定“Jan Lambertsz”“Mertyn”“Heynric Gherytsz”这样的具体名字;既要能回答一个孩子的日常问题,也要能服务研究者对人物、地点、事件的精确追索。
四、多智能体的关键是把复杂流程拆开
Capgemini 在项目介绍中提到,“Chat with History”建立在 Microsoft Azure AI Foundry、Agentic Services 和 Microsoft Agent Framework 之上,系统包含 query handler、document retriever、summarizer 等不同代理,由框架进行协调。[6] 这句话看上去技术味很重,但它其实解释了这个项目为什么不是一个普通聊天机器人。
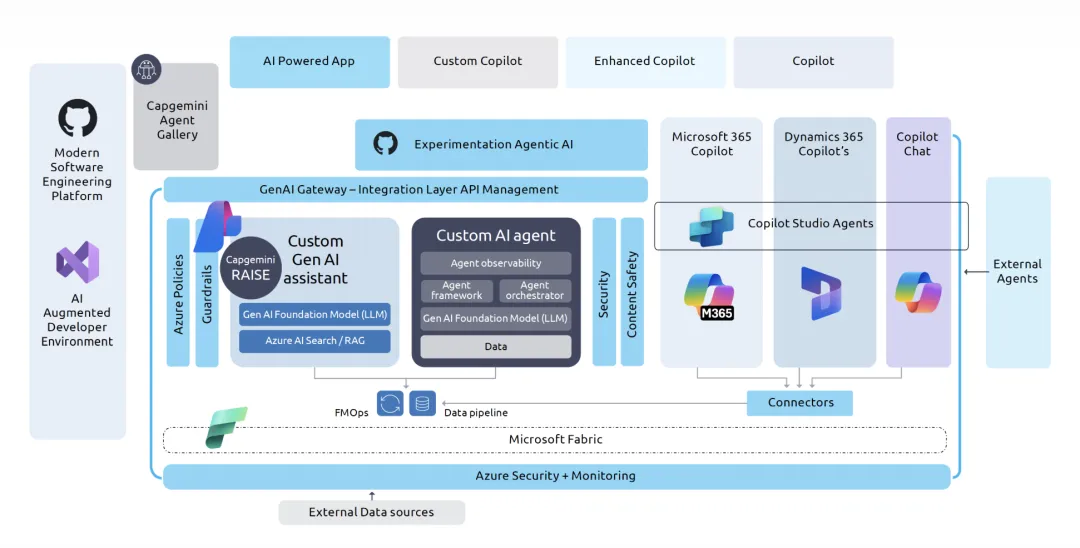
普通聊天机器人像一个人包办所有工作:理解问题、想答案、组织语言、输出结果。多智能体系统则更像一个工作小组:有人负责听懂问题,有人负责拆解问题,有人负责查档案,有人负责翻译,有人负责核对来源,有人负责把复杂材料写成普通人能读懂的语言。
放到档案场景中,一个较成熟的多智能体系统可以被拆成几类角色。Query Agent 负责理解用户问题,把一句模糊的问题拆成时间、地点、人物、事件和可能的档案类型。Retrieval Agent 负责调用关键词检索、向量检索和元数据过滤,在不同索引中找到候选材料。Source Evaluation Agent 负责判断材料的可靠性、时间范围和相关度,避免把相似但无关的材料混进答案。Translation Agent 负责古荷兰语、现代荷兰语、英语和用户语言之间的转换。Summarization Agent 负责把多份档案材料组织为简洁叙述。Citation Agent 负责保留馆藏编号、页码、图像坐标、转写段落和引用关系。Safety & Uncertainty Agent 则负责标记“不确定”“推测”“缺少证据”的部分。
这听起来复杂,但对于公共历史系统来说非常必要。因为档案问答的目标不是“说得像真的”,而是“知道自己凭什么这样说”。
也正是在这个意义上,AI讲城市故事的关键并不只是“生成能力”,而是“证据链能力”。一个城市叙事系统如果不能回答“这个故事来自哪里”,就很容易从公共知识变成公共想象。技术真正要解决的,不只是让故事更动人,而是让故事有据可依。
五、从“搜索历史”到“体验历史”
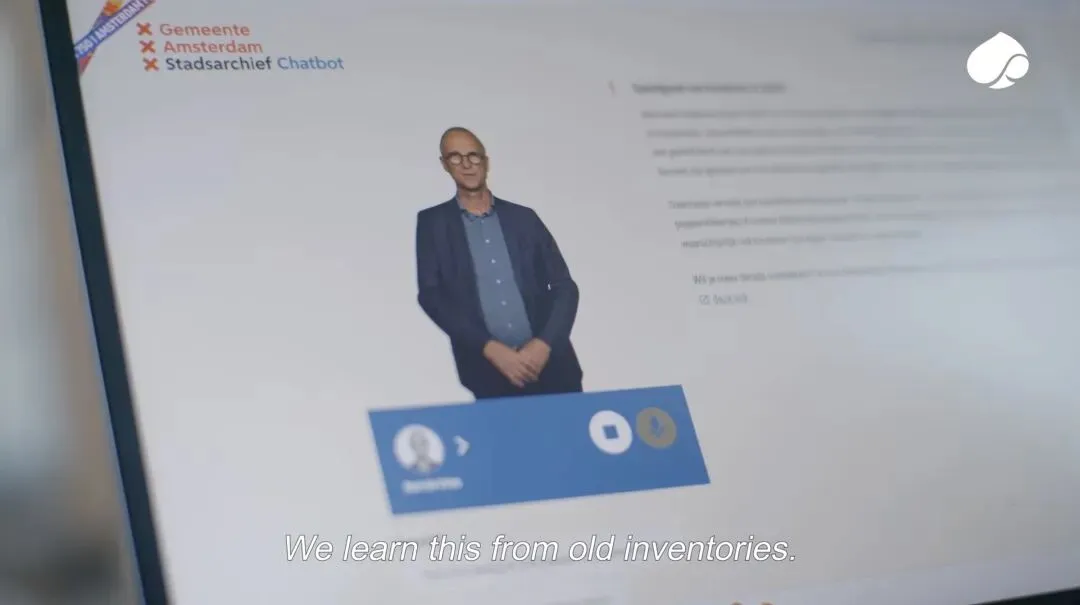
2025年,阿姆斯特丹迎来建城750周年。围绕这个特殊节点,阿姆斯特丹市档案馆与 Capgemini、微软合作,推出了“Chat with History”。它的目标不是再做一个更复杂的档案检索网站,而是让公众可以像和一位熟悉城市历史的馆员对话一样,直接向档案提问。Capgemini 的客户案例中写到,用户可以通过简单界面,用自己的语言提出问题,比如“17世纪的儿童玩什么游戏?”或者“我的街道是什么时候建成的?”系统会基于已数字化、转写并从古荷兰语翻译为现代荷兰语的档案材料生成回答。[7]
这是一种从“检索系统”到“对话界面”的转变。你不必知道某份文件属于哪个目录,也不必先掌握古荷兰语,更不必理解档案馆内部的分类系统。你只需要提出自己的问题:17世纪的阿姆斯特丹港口是什么样子?我的祖先是否可能在这里留下过记录?运河边曾经发生过哪些普通人的故事?城市最早的居民如何生活?
Capgemini 的生成式AI工程师 Lucas Puddifoot 对这个项目有一句很准确的概括:重要的不再是知道去哪里搜索,而是能够去探索。他进一步指出,AI把“寻找知识”转化为“体验知识”。[8]
这句话真正点出了传统档案系统和新型AI叙事系统之间的差别。搜索,是你已经知道自己要找什么;探索,是你带着一个模糊的问题出发,并允许自己在途中遇见意外。对于专业研究者来说,搜索已经足够重要。他们知道关键词,知道史料类型,知道该去哪个目录下面找,也知道如何判断一份材料的价值。但普通人与城市历史之间的关系,往往不是这样开始的。

一个孩子可能只是好奇:几百年前的人吃什么?一个老人可能想知道:自己家族曾经住过的街区以前是什么样子?一个游客可能想问:这条运河边发生过什么故事?一个设计师可能关心:某个广场在不同时代承担过哪些公共生活?
这些问题未必专业,却非常真实。它们是人们进入城市记忆的入口。过去,档案馆更擅长回答专业问题。未来,城市或许需要学会回答普通人的问题。这不是知识的降级,恰恰是知识重新进入公共生活。一座城市如果只能被专家解释,那么它的历史就仍然停留在少数人的系统里。只有当普通人也能提问、理解、追索、联想,城市记忆才真正从档案馆走向社会。
六、城市故事需要角色,而不只是年表
“Chat with History”的下一步设想,是让系统拥有更具人格化的入口。项目团队希望引入虚拟向导,让用户不只是面对一个搜索框,而是和一个可以引导探索的角色对话。Capgemini 文章中提到,未来系统可能扩展到让用户与历史人物互动,例如 Alewijn,文中称其为“the first Amsterdammer”。[9]
这个想法很有意思。因为它说明,城市历史的公共传播,不能只依靠信息量,还需要依靠角色、场景和关系。
人很难和“750年历史”建立关系,但可以和一个具体的人建立关系。人很难被“档案数字化工程”打动,但会被一个在450年前遭遇贸易纠纷的商人打动。人很难记住一座城市的完整年表,但可能记住一个孩子、一个船长、一个商人、一个修女、一个档案员、一个移民、一位画师、一名工匠。
这正是城市叙事最重要的转译能力:把年代转译为命运,把档案转译为故事,把空间转译为经验,把宏大的城市历史,转译为普通人可以进入的生命现场。
所以,AI在这里真正有价值的地方,不是把一堆资料总结得更快,而是帮助城市重新组织自己的叙事入口。一个好的城市AI系统,最终不应该只是“问答工具”,而应该成为一座城市的角色库、事件库、空间库、图像库、路线库和解释系统。
它可以告诉你某条街的建成年代,也可以带你理解这条街为什么出现;它可以检索一份旧地图,也可以把地图重新放回今天的城市现场;它可以找到某个人名,也可以让你意识到这个普通人与一座城市的贸易、制度、迁徙和生活方式有什么关系。
七、档案馆正在从仓库变成界面
如果从更长的城市史来看,档案馆的角色正在发生变化。过去,档案馆首先是保存机构。它的核心任务是保护文件、建立目录、维护秩序、服务研究。它像一座城市记忆的仓库,确保那些重要的证据不会散失。
后来,档案馆逐渐成为公共文化机构。通过展览、出版、教育活动和线上数据库,它开始主动面向市民开放。
而AI带来的新变化在于:档案馆可能进一步变成一座城市的叙事界面。所谓界面,就是人和复杂系统之间的连接方式。城市历史极其复杂。它包含制度、空间、人口、产业、灾害、贸易、战争、移民、建筑、道路、家庭、商业和日常生活。没有界面,普通人很难进入其中。
过去,这个界面可能是一座博物馆、一场展览、一本城市史、一条讲解路线,或者一位经验丰富的导览员。现在,AI提供了一种新的界面形式:对话。人们可以不再按照展陈规定的路线理解城市,而是从自己的问题出发,进入城市记忆。这会带来一种新的公共性。城市不再只是被讲述给公众听,而是允许公众向它提问。
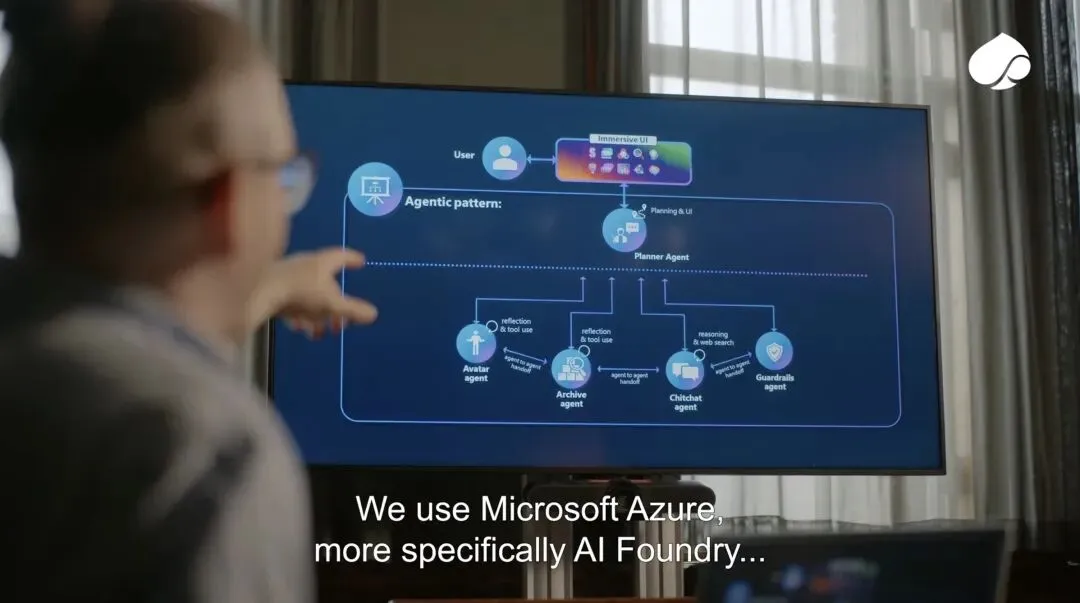
从技术角度看,这个“界面”最终可能不止是聊天框,而是一个多模态的城市记忆系统:文字问答负责解释,语音交互降低使用门槛,虚拟形象提供情感入口,老地图负责空间定位,历史照片负责视觉证据,地理信息系统负责把事件重新放回城市现场。Capgemini 也提到,未来系统会扩展新数据集、改进语言模型,并加入语音交互以及老地图、照片等视觉上下文。[10]
八、讲好城市故事,是一种新的公共能力
今天,几乎每座城市都在谈更新,谈文旅,谈品牌,谈流量,谈年轻人,谈城市IP。但城市IP如果只停留在符号层面,很容易变成空洞的视觉包装。真正有生命力的城市IP,应该来自城市自身的记忆深处。问题在于,记忆本身并不会自动转化为传播力。一份档案不会自己讲故事。一张老照片不会自己找到观众。一段地方志里的文字,也不会自动变成年轻人愿意转发的内容。中间需要一种转译能力。
过去,这种能力主要依赖作家、策展人、历史学者、建筑师、城市研究者和媒体编辑。未来,AI可能成为这个系统中的新成员。它不是取代人的判断,而是帮助人更快地连接资料、发现线索、生成入口、组织叙事。但也正因为如此,人类的判断会变得更重要。
AI可以检索档案,却不能天然知道一座城市最值得讲述的精神线索是什么。AI可以生成摘要,却不能自动判断一个故事对今天的公共生活意味着什么。AI可以让历史变得更容易访问,却不能替代我们对城市价值的重新选择。
阿姆斯特丹这个案例最值得学习的地方,恰恰在这里:它没有把AI当作炫技工具,而是把AI放进一个清楚的公共目标里——让城市历史从档案馆走向公众。这才是技术真正有意义的位置。
Jan Lambertsz 不是什么大人物。他不是国王,不是将军,不是哲学家,也不是城市规划者。他只是一个在16世纪来到阿姆斯特丹做生意的汉堡商人,遭遇了一场贸易纠纷,然后留下了一封抗议信。
在漫长的城市历史中,这样的人有无数个。他们修过路,开过店,搬过家,坐过船,缴过税,写过信,告过状,结过婚,也在某条街上度过过一个普通的下午。历史书很难记住他们,但城市记得。它把他们的名字、笔迹、契约、账本、照片和生活痕迹,藏在档案馆里,藏在街道背后,藏在建筑缝隙中,也藏在一代代人的讲述里。
过去,我们以为保存就是对记忆最好的尊重。现在也许应该再往前走一步。让记忆被重新看见,让档案被重新提问,让普通人的故事重新进入城市叙事。750岁的阿姆斯特丹,正在学习用AI讲述自己。而更多城市真正需要学习的,也许不是某一项技术,而是一种新的态度:城市的记忆,不该只睡在档案馆里。它应该醒来,并且向每一个愿意倾听的人开口。
参考资料
引用链接
-
Capgemini, “Bringing 750 years of history to life: Revolutionizing accessibility using agentic AI,” 2026-03-10. 文中关于 Jan Lambertsz、Mertyn、Heynric Gherytsz 兄弟及1574年抗议信的叙述,主要参考该文相关段落。https://www.capgemini.com/insights/expert-perspectives/bringing-750-years-of-history-to-life/↩︎
-
Capgemini, “Amsterdam brings 750 years of history to life with AI.” 关于阿姆斯特丹城市档案馆约50公里纸质档案及馆藏类型的介绍。https://www.capgemini.com/news/client-stories/amsterdam-brings-750-years-of-history-to-life-with-ai/↩︎
-
Transkribus, “Handwriting to Text — AI Recognition.” 关于 HTR 与 OCR 区别、深度学习识别手写文本的解释。https://www.transkribus.org/handwriting-to-text↩︎
-
Microsoft Learn, “Retrieval augmented generation (RAG) and indexes in Microsoft Foundry.” 关于 RAG 将搜索与大语言模型结合、让回答基于 grounding data 的解释。https://learn.microsoft.com/en-us/azure/foundry/concepts/retrieval-augmented-generation↩︎
-
Microsoft Learn, “Vector Search Overview — Azure AI Search.” 关于向量搜索、语义相似、多语言内容、多模态内容和混合搜索的说明。https://learn.microsoft.com/en-us/azure/search/vector-search-overview↩︎↩︎
-
Capgemini, “Bringing 750 years of history to life: Revolutionizing accessibility using agentic AI.” 关于 Microsoft Azure AI Foundry、Agentic Services、Microsoft Agent Framework、query handler、document retriever、summarizer 等多智能体架构的说明。https://www.capgemini.com/insights/expert-perspectives/bringing-750-years-of-history-to-life/↩︎
-
Capgemini, “Amsterdam brings 750 years of history to life with AI.” 关于 Chat with History 用户可以用自然语言提问,并基于数字化、转写、翻译的档案材料生成回答的介绍。https://www.capgemini.com/news/client-stories/amsterdam-brings-750-years-of-history-to-life-with-ai/↩︎
-
Capgemini, “Amsterdam brings 750 years of history to life with AI.” Lucas Puddifoot 关于“search”与“explore”、以及“search for knowledge”到“experiencing of knowledge”的表述。https://www.capgemini.com/news/client-stories/amsterdam-brings-750-years-of-history-to-life-with-ai/↩︎
-
Capgemini, “Bringing 750 years of history to life: Revolutionizing accessibility using agentic AI.” 关于未来加入历史角色 Alewijn 的设想。https://www.capgemini.com/insights/expert-perspectives/bringing-750-years-of-history-to-life/↩︎
-
Capgemini, “Amsterdam brings 750 years of history to life with AI.” 关于未来扩展新数据集、改进语言模型、语音交互及老地图、照片等视觉上下文的说明。https://www.capgemini.com/news/client-stories/amsterdam-brings-750-years-of-history-to-life-with-ai/↩︎