 夜雨聆风
夜雨聆风





给AI按下暂停键:Alibaba Metis Agent如何教模型"躺平"
摘要:当你问大模型“今天北京天气怎么样”,它调三次搜索、再调代码执行、最后才给你一个答案——这不是智能,是“工具上瘾”。Alibaba最新开源的Metis Agent用强化学习框架HDPO,将冗余工具调用从98%降到2%,同时推理准确率不降反升。这篇不仅讲清楚原理,还给出OpenClaw和Hermes环境下的具体落地方案。
你是否见过这种“AI工具狂”?
先还原一个真实场景。
你问某个AI助手:“杜甫的代表作是哪三首?”
一个正常思维的模型应该直接回答。但一个“工具上瘾”的Agent会这样推理:
第一步:调用web_search查“杜甫代表作”(其实它的训练数据里就有答案)
第二步:调用code_interpreter把结果格式化成列表(完全没必要)
第三步:调用knowledge_graph验证诗人信息(又一次画蛇添足)
第四步:输出答案
三次工具调用,换来一个本可以“张口就来”的答案。这是目前大多数AI Agent的通病——盲调工具,不管问题难易,先把工具链跑一遍再说。
这个现象,被Alibaba的研究者称为“元认知缺陷”(Metacognitive Deficit):模型压根不知道自己什么时候该用外部工具,什么时候该躺平靠内部知识。
元认知缺陷:大多数Agent的死穴
问题出在训练阶段。大多数模型的训练信号只有一个目标:把任务做完。至于花了多少时间、调用了多少次API、注入了多少噪声到上下文里——训练时根本不管。
准确率和效率被绑在同一根绳子上。 如果强化学习的reward同时包含“做对题”和“少用工具”,两个目标会互相拉扯。惩罚太重,模型变得过度保守;惩罚太轻,模型依然疯狂调用。
更隐蔽的问题是:过度调用工具会反向损害推理质量。 工具返回的内容注入上下文,会带来噪声、分散注意力,甚至把原本正确的推理链条带偏。
HDPO:把两个目标拆开优化
Alibaba的研究者提出了Hierarchical Decoupled Policy Optimization(HDPO)——“分层解耦策略优化”。核心思想:准确率和效率,先别放在一起优化。
怎么拆?
通道一:准确率通道。 专门盯着“这道题做对没有”,不管效率,只管答案质量。
通道二:效率通道。 在准确率通道达标的前提下,优化“用了多少次工具”,追求越少越好。
两条通道独立计算loss,最后在最终阶段才合并。关键在于:效率信号以准确率为条件——一次错答案永远不会因为调用次数少而被奖励。
隐式认知课程:先难后易,自己学会的
训练初期,模型准确率还很低,优化过程基本被准确率目标主导——模型专心学做题。等到模型推理能力成熟了,效率信号才开始主导——模型自然开始减少冗余工具调用。就像一个学生先要把知识学透,才能自己判断哪些题不用翻书就能做。
数据工程:多阶段筛选,只留精品
第一阶段:监督微调(SFT)。 剔除执行失败和反馈不一致的样本,用Gemini 3.1 Pro作为自动化裁判,把“战略性地使用工具”的样本保留。
第二阶段:强化学习(HDPO)。 在SFT基础上用HDPO进一步优化效率-准确率的平衡。
效果:工具调用从98%降到2%,准确率还上升了
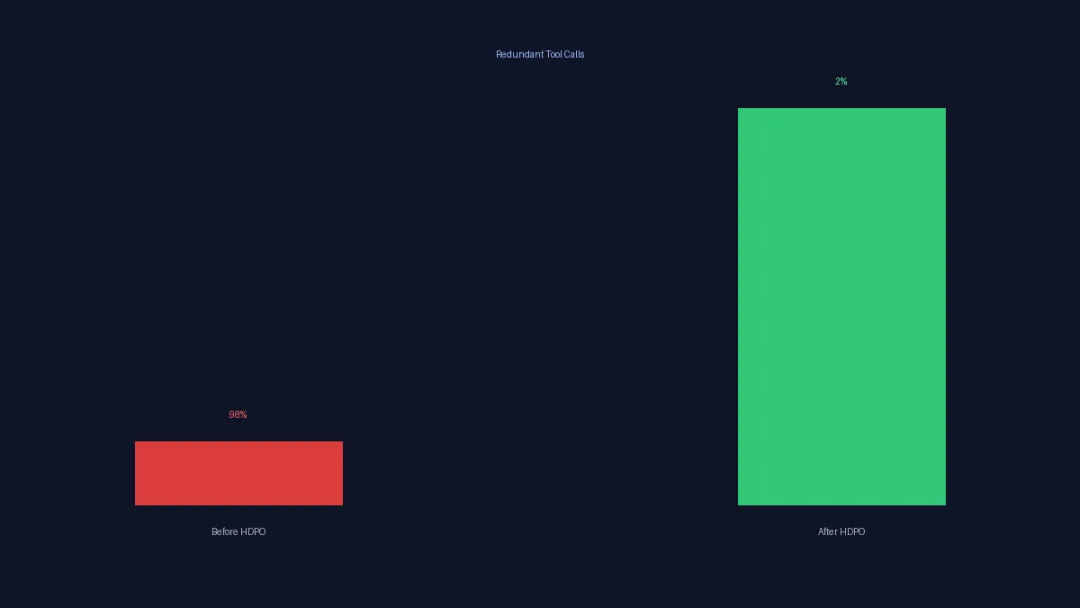
用HDPO训练的Metis Agent,将冗余工具调用从98%降到了2%——在绝大多数本不需要调用外部工具的场景下,模型会直接用自己的内部知识作答。
更重要的是:推理准确率没有下降,反而创了新高。 这个结果验证了HDPO的核心假设:工具调用的减少不仅省了成本、降低了延迟,还减少了上下文噪声,让模型更专注,推理更准确。
OpenClaw和Hermes用户的落地方案
方案一:系统提示词级别的“工具自律”指令(OpenClaw + Hermes 均适用)
最简单、最快生效的手段。HDPO的本质是让模型形成“先判断是否必要,再决定是否调用”的习惯,这个可以通过system prompt直接实现:
你有权拒绝调用工具。如果你判断用户的问题可以凭借你自身的知识直接回答,就直接回答,不必调用任何工具。
调用工具的判断标准:
1. 需要实时数据的场景(股价、天气、新闻)→ 调用
2. 知识截止日期之后发生的事 → 调用
3. 涉及用户个人数据(邮件、日历、文档) → 调用
4. 常识性问答、事实查询、写作建议 → 不调用
方案二:Hermes工具调用预算控制(重点)
Hermes的max_iterations默认90,单轮工具调用上限比OpenClaw激进得多,更容易让模型养成“反正还有budget”的习惯。建议调整:
agent.max_turns: 60(已有)
delegation.max_iterations: 20(建议从默认值降低)
开启工具结果自动持久化(已有机制):Hermes内置tool_result_storage,单轮工具结果超过200K chars自动持久化到磁盘。建议在任务prompt里明确告诉Hermes:
每轮工具调用后,只保留必要的输出结果。如果某个工具返回了大量数据,请只把最终结论告知我,不要把完整输出塞进上下文。
context_compressor提前触发:把threshold从0.5降到0.35,更早压缩历史工具调用对当前推理的干扰:
compression: { threshold: 0.35, protect_last_n: 15 }
方案三:OpenClaw的contextPruning和compaction
把minPrunableToolChars从1200降到800,更激进地压缩短结果:
“contextPruning”: { “minPrunableToolChars”: 800 }
配合compaction + memoryFlush减少工具结果堆积:
“compaction”: { “reserveTokens”: 25000, “keepRecentTokens”: 12000 }
“memoryFlush”: { “softThresholdTokens”: 18000, “forceFlushTranscriptBytes”: “1mb” }
tools.profile切换:“coding”默认值会让模型更积极地调用代码执行工具,对非编码场景:
“tools”: { “profile”: “conversational”, “maxToolCallsPerTurn”: 3 }
方案四:从系统架构层面贯彻”先准确率后效率”
HDPO真正的洞察不只是参数怎么调,而是“效率优化必须等准确率达标之后再引入”这个顺序原则。
不要在Agent能力还不稳定的时候追求效率。 先让Agent自由调用工具把任务解决,等它能稳定完成工作流了,再收紧工具调用限制。如果顺序搞反——Agent能力还没成熟时就把工具调用卡死,结果只能是任务失败率飙升。
判断标准: 一个任务在你的OpenClaw/Hermes配置下连续10次都能正确完成,就可以尝试收紧效率参数,看准确率是否受影响。不受影响,说明已经到了可以优化的阶段。
结语:不止要“会做”,还要知道“什么时候不做”
AI Agent发展的下一个分水岭,不在于模型能调用多少工具,而在于能否自主判断——哪些问题值得调用工具,哪些靠内部知识直接回答就已经足够好。
Metis Agent的HDPO给了我们一个方向:这个问题可以让RL自己学会,不必人工一条条写规则。
对于OpenClaw和Hermes用户来说,HDPO短期内还无法直接使用,但它的核心洞察可以直接落地:控制上下文噪声、设置工具调用的边界条件、在系统设计层面贯彻“先准确率后效率”的原则——你的Agent已经在往更聪明的方向演化了。
当AI开始学会“躺平”,或许才是真正的智能开始。