 夜雨聆风
夜雨聆风





290M次下载的开源项目,正在把「自己的AI」变成现实
先看两个数字。
124,000 GitHub stars 。 290,000,000 次 Docker 下载。
这不是某家大公司的产品,是一个叫 Timothy Jaeryang Baek 的开发者几年前开始做的开源项目——Open WebUI。
现在它是自托管 AI 界事实上的标准界面。
它是什么,解决了什么问题
Open WebUI 本质上做一件事:给本地运行的大模型一个好用的聊天界面。
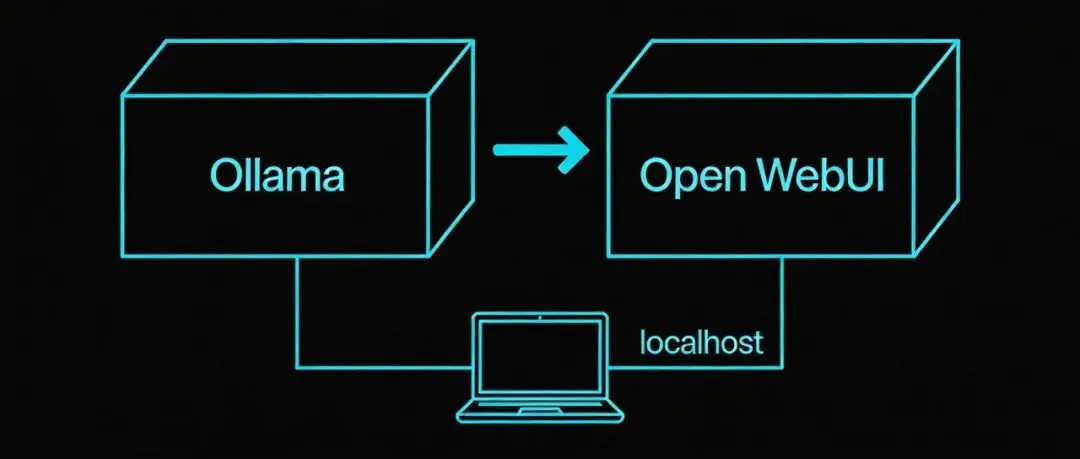
它最早是 Ollama 的前端——Ollama 让你在自己电脑上跑 Llama 、 Mistral 、 DeepSeek 等模型,但交互方式只有命令行。 Open WebUI 接上去,变成了一个跟 ChatGPT 视觉上高度相似的 Web 界面,只是模型全跑在你自己的服务器上。
用一个 Docker 命令安装,五分钟内能用起来。
但它后来没有停在”好看的界面”这里。
2026 年它变成了什么
现在的 Open WebUI 已经不是一个聊天框了。
RAG 知识库: 上传文档,模型直接基于你的文件回答问题。内置混合检索和重排序,不需要额外配置向量数据库。
Python 工具工作区: 在浏览器里写 Python 函数,直接暴露给 LLM 作为工具调用。换句话说,你可以让模型自主触发你的自定义逻辑——查数据库、调 API 、生成报告——不需要改任何应用代码。
语音和视频通话: 接入 Whisper 、 ElevenLabs 、 OpenAI TTS ,直接用说话跟模型交互,支持实时语音。
多用户 + 权限控制: Admin 、 Power User 、 User 三级角色,细粒度控制谁能访问哪些模型、谁能修改系统配置。团队部署可用。
日历和任务管理( 2026 年新增): 模型现在可以在对话里帮你创建任务、拆解目标、追踪进度,还有日历视图。这一步迈得比较大——从聊天工具向个人助手方向走。
一个 pip install 或 docker run 之后,你拥有的不是一个聊天框,是一个本地 AI 工作站。
290M 下载量背后的趋势
这个数字不是偶然的。
2023-2024 年,大多数人用 AI 的方式是:打开 ChatGPT 、 Claude 或者 Gemini 的网页,输入问题。数据在对方的服务器上,生成的内容对方的系统会处理,你对”隐私”这件事基本没有控制权。
这对个人用户来说是可以接受的。对企业来说,不一定。
医疗、法律、金融——这些行业有合规要求,数据不能出域。即便是一般企业,把内部文档、客户信息、业务数据喂给第三方 API ,也是一个合规风险。自托管的需求一直在,只是之前技术门槛太高。
Ollama 把”在本地跑大模型”的门槛降到了普通开发者能接受的程度。 Open WebUI 把使用门槛再往下降了一层——不需要懂命令行,装 Docker 就够了。
这条路打通之后, 290M 的下载量就有了解释。
不过坦白说,这里面也有水分——很多下载是 CI/CD 自动拉镜像,不等于真实用户数。但哪怕打五折, 1.4 亿次有效使用,也已经是一个很可观的数字了。
它有什么问题
不靠谱的地方也要说清楚。
安全完全是你的责任。 Open WebUI 自己不提供 HTTPS 、不提供反向代理、不处理 DDoS 。你把它暴露在公网,那是你的问题。正确的部署方式是放在 Nginx/Caddy 后面,加好 SSO ,做好访问控制。很多人图省事直接开放端口,真实风险很高。踩过坑的人都知道,图省事这三个字在安全这件事上代价很贵。
资源消耗不小。 跑 7B 参数模型至少要 8GB 显存或内存, 13B 要 16GB 起步。对于想在家里部署的普通用户,入门门槛仍然存在。想着”随便一台旧电脑就能跑”——不现实,先别信这话。
更新节奏很快,稳定性参差不齐。 主仓库平均每周多次更新,新特性多,但也意味着时不时有 breaking change 。生产部署建议锁版本,不要跟 latest 。这个坑不少人掉进去过,早上还好好的,下午拉了最新镜像跑不起来了,焦虑死人。
为什么值得关注
我的判断是——这个方向不是小众爱好者的玩具,是下一阶段企业 AI 落地的基础设施候选之一。
理由不复杂:大模型能力已经足够强,部署成本在下降( H100 租用成本一年内降了一半以上,说白了就是贵的东西在变便宜),合规驱动的自托管需求是刚需,不会消失。而 Open WebUI 在这个节点上,把”自己的 AI”的使用体验做到了接近商业产品的水平。
说实话,两年前如果你说要自己部署一套 AI 对话系统,周围人大概觉得你在折腾没必要的事。现在不一样了——大公司已经在认真评估这条路线了,躺平在云厂商 API 上的日子开始让很多合规部门头疼。
目前它的短板主要在运维复杂度上。这一点目前行业内有不同的解法——有人在做一键部署方案,有人在基于它做商业封装。值得持续跟踪,现在下结论为时尚早。
但 290M 下载量说明了一件事:想把 AI 放在自己服务器上的人,比你想象的多。
快速上手
本地体验只需要两步(前提是已安装 Docker ):
dockerrun-d-vollama:/root/.ollama-p11434:11434ollama/ollama dockerexec-it<容器ID>ollamapullllama3.2 dockerrun-d-p3000:8080\-eOLLAMA_BASE_URL=http://host.docker.internal:11434\-vopen-webui:/app/backend/data\--nameopen-webui\ghcr.io/open-webui/open-webui:main 访问 http://localhost:3000,注册第一个账号(自动成为 Admin ),选模型,开始对话。
整个过程不需要 API Key ,不需要联网,模型完全本地运行。
跟踪要点: Open
WebUI 的 MCP 支持进展;企业版 SSO 和审计日志功能;与 Ollama 之外其他推理后端的兼容性。
GitHub: github.com/open-webui/open-webui