当前时间: 2026-05-06 01:55:10
更新时间: 2026-05-06
分类:软件教程
评论(0)
聊聊AI狂飙的这70年:别慌,人工智能没那么神秘
最近在构思公众号的文章,手头也常开着 Cursor 辅助写代码,或者让 AI 生成文档框架。盯着屏幕上如流水般自动吐出的文字,我时常会生出一种恍惚感:这个庞然大物,究竟是怎么走到今天这一步的? 大众往往觉得,AI 就是这两年突然诞生的“黑魔法”,或是一场被资本催熟的泡沫。但如果我们把时间的刻度拉长到过去 70 年,你会发现人工智能褪去神秘的外衣后,其实是一部充满挫折的拓荒史——那是无数顶尖大脑反复跌入低谷,又一次次倔强重来的历程。
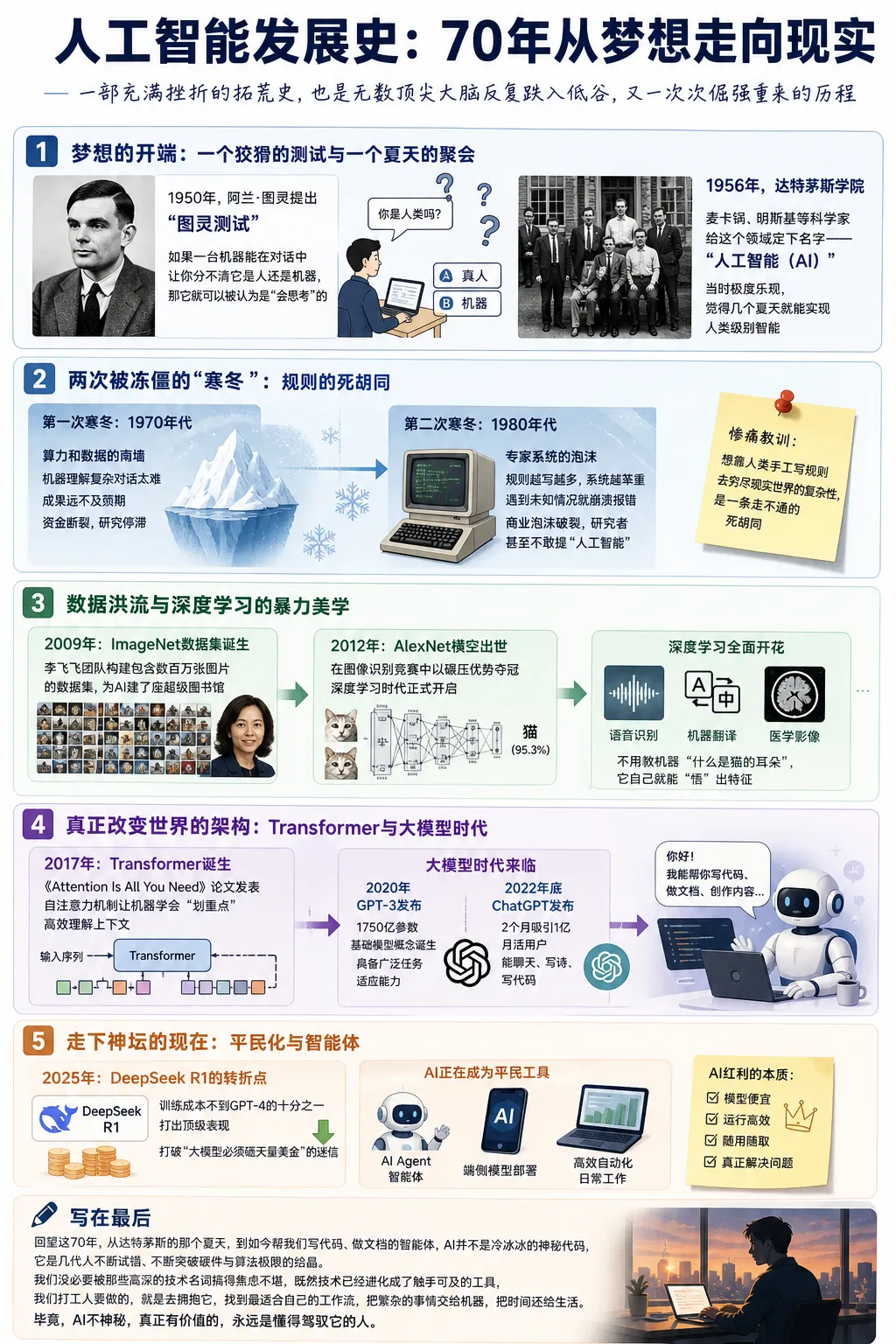
一切的起点要追溯到 1950 年。那个经历过二战的英国天才数学家阿兰·图灵,提出了一个狡猾又迷人的设想:如果一台机器能在对话中让你分不清它是人还是机器,那它就可以被认为是“会思考”的。这就是大名鼎鼎的“图灵测试”,它为后人划定了一个看得见的目标。
到了 1956 年的夏天,美国达特茅斯学院里聚了一群绝顶聪明的科学家(包括麦卡锡、明斯基等人)。他们雄心勃勃地给这个领域定下了名字——“人工智能(AI)”。当时大家极度乐观,觉得智能的每一个特征都可以被精确描述,只要几个夏天的时间,就能让机器拥有人类级别的智慧。
第一波热潮很快撞上了算力和数据的南墙。他们发现,写个能解数学题、下简单棋局的程序容易,但让机器理解一句稍微复杂的日常对话,简直比登天还难。到了 1970 年代,成果远不及预期,资金断裂,迎来了第一次“AI 寒冬”。
到了 1980 年代,大家换了个思路,搞出了“专家系统”——试图把人类专家的知识写成无数条规则输进电脑里。结果呢?规则越写越多,系统越来越笨重,稍微遇到点没见过的特殊情况就直接崩溃报错。随着台式机性能超越了昂贵的专用机器,商业泡沫破裂,第二次寒冬降临,很多研究者甚至为了避嫌,都不敢提“人工智能”这四个字。
这两次低谷其实留下了一个惨痛的教训:想靠人类手工写规则去穷尽现实世界的复杂性,是一条走不通的死胡同。
转折点出现在互联网时代。海量的数据成了 AI 最好的养料。
李飞飞团队在 2009 年搞出了包含数百万张图片的 ImageNet 数据集,这就像是给 AI 建了一座超级图书馆。紧接着,2012 年,一个叫 AlexNet 的深度学习网络在这个图像识别竞赛中以碾压的优势夺冠。
“深度学习”这四个字彻底火了。大家发现,不用费劲去教机器“什么是猫的耳朵”,只要给它看几万张猫的照片,它自己就能用多层神经网络“悟”出猫的特征。从此,AI 在语音识别、机器翻译、医学影像等领域全面开花。
4.真正改变世界的架构:Transformer与大模型时代
如果说深度学习是前菜,那 2017 年就是上主菜的时刻。
Google 的研究员发表了一篇神级论文《Attention Is All You Need》,提出了 Transformer 架构。这个基于“自注意力机制”的架构让机器学会了“划重点”,能极其高效地理解上下文。这也就是现在所有生成式 AI 模型里那个“T”的来源。
-
2020 年,OpenAI 搞出了 1750 亿参数的 GPT-3,“基础模型”的概念横空出世,机器具备了广泛的任务适应能力。
-
2022 年底,ChatGPT 发布,在短短两个月内吸引了 1 亿月活用户,创下了当时的消费级应用增长历史纪录。它不仅会聊天,还能写诗、写代码,让全世界都切身感受到了通用人工智能(AGI)的曙光。
再后来,大模型竞赛进入白热化。但最让我这种每天在业务线里摸爬滚打的人兴奋的,是 AI 正在从“烧钱的巨头游戏”变成“平民工具”。
2025 年发布的 DeepSeek R1 就是个典型的转折点。它用极低的训练成本(不到 GPT-4 的十分之一)打出了顶级的表现,彻底打破了“大模型必须砸天量美金”的迷信。
现在的技术圈,大家不再只盯着谁的参数大,而是都在探索 AI Agent(智能体) 的业务落地和端侧模型部署。不需要事事都求助云端巨无霸,让模型便宜、高效、能直接帮我们处理日常自动化工作,这才是真正属于普通人的 AI 红利。
回望这 70 年,从达特茅斯的那个夏天,到如今帮我们写代码、做文档的智能体,AI 并不是冷冰冰的神秘代码,它是几代人不断试错、不断突破硬件与算法极限的结晶。
我们没必要被那些高深的技术名词搞得焦虑不堪。既然技术已经进化成了触手可及的工具,那我们打工人要做的,就是去拥抱它,找到最适合自己的工作流,把繁杂的事情交给机器,把时间还给生活。
毕竟,AI 不神秘,真正有价值的,永远是懂得驾驭它的人。
 夜雨聆风
夜雨聆风