 夜雨聆风
夜雨聆风





AI落地生死局:烧钱容易赚钱难? ——揭秘企业AI落地的20个障碍(三)

越过“想不明白”的争论与“做不下去”的博弈,当企业真正着手构建AI系统时,面临的将是最硬核的挑战——技术与数据。本篇将直击那些阻碍企业AI系统“跑起来”的核心技术与数据问题。
引言
Foreword
上篇揭示了企业在AI落地过程中“做不下去”的难题——战术与执行障碍。但即便执行力足够,很多企业仍然“跑不动”。原因在于更深层的技术适配与数据根基。
数据是AI的核心要义,当数据处于孤岛、缺乏治理与安全保障时,任何先进的模型都难以发挥价值。与此同时,技术的角色尤为关键——它不仅是实现AI功能的工具,更是将其融入业务、持续释放价值的核心支撑。通过开放的软件平台与灵活的架构,企业能够降低开发门槛、适应业务变化,并推动个性化解决方案的快速迭代。将坚实的数据基础与强大的技术能力相结合,AI能真正走出实验室,转化为可持续的商业竞争力。
如果说执行力决定了计划能否落地,那么技术与数据决定了AI能走多远。本篇聚焦的是技术与数据层面的障碍,分析它们如何阻碍AI落地,并探讨可操作的应对策略。




11
障碍十一:
数据孤岛
Data Silo
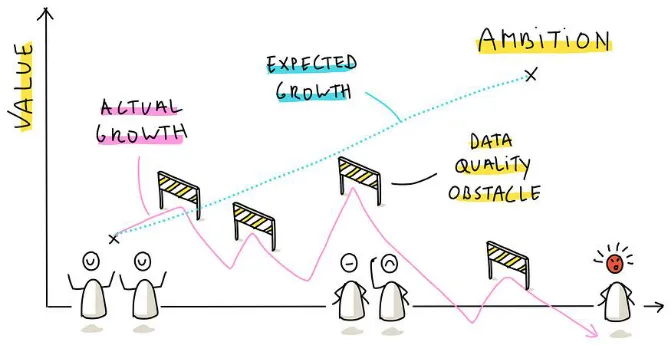
尽管许多企业大力投资AI团队,但在实际操作中,他们往往发现数据是一个痛点。数据往往分散在不同的数据库、应用或部门中,格式混乱、无法互通,甚至有些企业根本没有系统性的数据。如某零售企业,客户数据在CRM,订单数据和库存信息在ERP,财务部门用Excel管理,生产线的实时状态则被记录在MES。数据分散在多套系统,无法形成统一链路,使AI无法实时跟踪订单状态,供应链响应也随之受阻。

核心
企业缺乏统一的数据整合机制与跨部门数据共享能力,形成“数据孤岛”。
应对建议
在启动AI项目之前,企业应搭建统一的数据集成平台(如ESB、数据中台),集中管理数据流转,确保系统间数据自动同步。可从易得数据、共享价值高的环节入手(如订单管理、库存、财务),逐步扩展。同时,将数据共享纳入部门绩效考核,推动跨部门协作。
总结
启动项目前,首先要搞清楚:数据在哪里?能否在一个地方被完整看到?


12
障碍十二:
数据质量差
Poor Data Quality
数据质量差是真正实现AI驱动的最大障碍之一。许多企业在此基础环节存在严重缺失,问题根源贯穿数据生命周期:从人工录入的疏漏,到软件系统的错误,再到流程整合中的丢失。例如,某制造企业超过90%的生产数据依赖人工记录,格式混乱且错误频出。在此类低质量数据上,即便部署最先进的AI系统,也无法产出准确可信的结果,导致项目效益大打折扣。
数据质量差会给AI、商业智能和自动化带来障碍,限制组织充分利用数据的能力
核心
数据在录入、处理与整合的全链路中均存在缺陷,导致质量低下,无法为AI提供可靠的学习与决策基础。
应对建议
企业应着力构建数据质量管理的三道防线:一是在源头,在录入点部署自动化工具与强制校验规则;二是在流程,通过定期审计与即时告警确保数据在流动中的准确与完整;三是长效治理,设立专门的数据治理团队并将质量指标纳入部门绩效考核,确保持续优化。
总结
“垃圾进,垃圾出”是AI领域的铁律。筑牢从源头到终点的数据质量防线,能让AI的潜力得到真正释放。


13
障碍十三:
基础设施不足
Inadequate Infrastructure
AI基础设施以AI硬件设施、算法平台、数据平台以及开放创新平台等为主要载体。部分企业急于部署先进的AI功能,但忽视了其赖以生存的“地基”——基础设施。在没有建立集中的数据存储(如数据仓库/湖)、高效的数据处理管道、以及确保数据可被调用的管理平台和AI技术架构的基础上,直接推行AI技术,往往会导致实施困难。
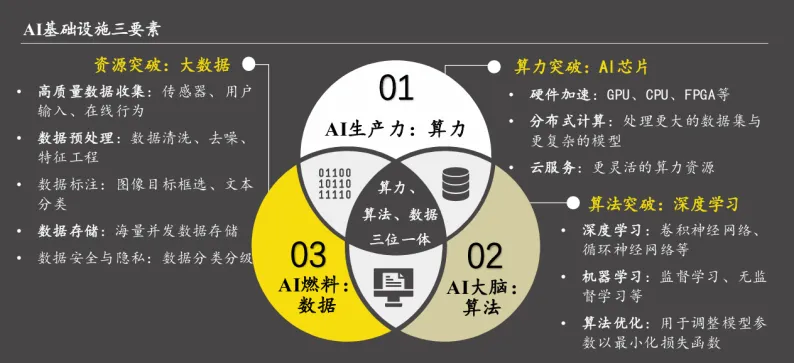

AI基础设施指以高质量网络为重要支持,以数据资源、算法框架和算力资源为核心要素,用于支撑AI应用的设计、部署和运行的基础架构,是确保系统正常运行并处理庞大数据和复杂计算任务的基石
核心
企业缺乏支撑AI所必需的、成熟的基础设施,导致AI模型无法在现实中有效运行。
应对建议
企业首要任务是任命首席数据官(CDO),主导数据战略和技术选型。在技术实施上,优先采用面向AI时代的湖仓一体化架构,以满足当前集中管理需求并支持未来AI应用。最后,将AI项目与业务价值紧密结合,通过快速交付高价值、小范围的MVP,验证路径并积累信心,为大规模投入奠定基础。
总结
AI是数据能力成熟后的自然演进。企业需先修好“道路”(基础设施),再购买“跑车”(AI)。


14
障碍十四:
AI模型缺乏可靠性
与可解释性
AI Models Lack Reliability
and Interpretability
AI的可靠性与可解释性是其从实验室走向产业应用的关键挑战,缺乏这两者一直是AI在企业侧落地过程中最大的阻碍之一。首先,算法不鲁棒严重影响其实际应用,如自动驾驶未能识别行人导致事故。其次,黑箱模型导致算法难以解释,对用户不透明,难以推广至医疗、金融等需要清晰决策依据的领域。此外,数据、模型和评估中的偏见可能导致不公平决策,如保险定价和犯罪预测中的歧视问题。最后,数据滥用和隐私泄露风险也是企业必须面对的重大问题。
项目的推进表面上热火朝天,实则陷入“高层要样子、中层保帽子、基层看热闹”的困境。高层追求战略宣示和公关亮点,却未将AI成果与核心业务指标强绑定;中层管理者因变革风险高、收益不明确且可能打破现有稳定运营,缺乏真正推动的动力,最终导致项目资源、人员错配,如指派不懂AI的项目经理管理算法工程师,最终做出了一个没人能用的智能助手;基层员工困于技能焦虑,抵触流程变革。

“黑箱”问题指AI模型的决策过程不透明,用户无法理解其判断依据。例如,AI模型能识别图像中的“猫”,但无法解释判断依据。这是由于AI模型的复杂性所致,而非设计缺陷
核心
AI可靠性的不足与决策过程的不可解释性,尤其在高风险领域和需要透明决策的行业中,造成了信任问题与公平性挑战。
应对建议
技术方面,可通过数据清洗、置信度阈值设置、持续监控训练与设立AI可靠性工程师角色来提升模型的可靠性,并积极采用可解释人工智能(XAI)。治理方面,可建立覆盖数据、模型与评估的全链路审计与偏见检测机制,确保公平性。隐私与安全方面,应部署隐私增强计算技术(如联邦学习)并制定严格的内部数据治理规范,从源头防范风险。
总结
AI的可靠性与可解释性不仅是技术难题,更是关乎信任与责任的系统性工程。


15
障碍十五:
AI模型选择复杂
Complexity in AI Model Selection
AI模型选型是AI项目开发及其驱动业务转型的关键决策,直接影响项目的开发周期、性能表现和未来的可维护性。许多企业因选错AI平台而陷入“投入百万却产出为零”的困境,选型过程面临多重挑战:首先,须根据应用场景选择合适模型,既满足性能要求,又要控制成本;其次,技术路线存在矛盾,如“预训练+微调”成本高、数据需求大,而“提示词工程+检索增强”灵活性高但复杂场景不稳定;同时,还需在开源模型的灵活性与闭源模型的成熟安全性之间做权衡。选型不当可能导致项目初期失败。

目前市场上AI模型种类繁多,如何根据自身需求选择
合适的模型具有一定难度
核心
如何在性能与成本之间做出合理平衡,选择适配企业需求的基础模型。
应对建议
企业需基于场景需求、数据可用性和成本约束,采取分阶段策略:先通过提示词工程等轻量方法快速验证,在关键场景或数据充足时考虑微调;同时,结合开源模型的灵活性进行定制开发,并在安全敏感领域引入闭源模型的成熟解决方案,通过迭代测试和性能监控动态优化选型。
总结
AI模型选型需以场景驱动、成本可控为原则,科学评估与灵活调整,为项目成功奠定基石。


数据与技术的挑战深植于系统底层,划定AI能力的真实边界。它们构成了企业AI落地的底层逻辑,既锁定了系统效能的上限,也奠定了其应用效果的下限。
系列未完,敬请期待……

<<< END >>>
《中科大AI商业架构师认证培训》第二期招募开启,培养AI顶层设计师,助力中国企业把握AI时代机遇!

