 夜雨聆风
夜雨聆风





OpenClaw压缩术:为什么越聪明的AI越需要学会遗忘?
当对话越来越长, AI 如何记住关键信息又不被细节淹没?本文深入拆解 OpenClaw 压缩模块的完整执行原理,带你理解 AI 记忆管理的底层逻辑。
引言: AI 也会”记不住”吗?
想象一下这个场景:你和一位助手连续聊了三天三夜,从工作计划聊到人生哲学,从代码 bug 聊到晚饭吃什么。现在,你突然问它:”我昨天说的那个项目方案,最后决定用哪个版本?”
如果这位助手是人,他可能需要翻翻聊天记录、回忆一下上下文,才能给出准确答案。但如果这位助手是 AI ,它面临的挑战比人类更大——它的”记忆容量”是有限的。
在大型语言模型( LLM )的世界里,这个限制叫做上下文窗口( Context Window )。就像人的短期记忆容量有限一样, AI 一次能”记住”的对话长度也有上限。当对话超出这个上限, AI 就会”遗忘”最早的信息,甚至可能出现混乱。
你可能有过这样的体验:和一个 AI 助手聊了很久,突然它开始重复之前说过的话,或者忘记了你们之前达成的重要约定。这不是 AI”笨”,而是它的底层架构决定的——每一次对话, AI 都要把之前的所有内容重新”读”一遍。这意味着,对话越长, AI 需要处理的文本就越多,直到达到它的能力极限。
那么,如何让 AI 在超长对话中依然保持”记忆力”?答案就是——上下文压缩( Compaction )。
今天,我们将深入拆解 OpenClaw 系统中压缩模块的完整执行原理,带你理解这项让 AI 越聊越聪明的”记忆压缩术”。这不仅是技术解析,更是对 AI 记忆管理未来发展趋势的深度思考。
第一部分:什么是上下文压缩?
1.1 核心概念:把长对话变成”精华笔记”
上下文压缩( Compaction ),简单来说,就是将冗长的对话历史压缩成一份结构化的摘要,从而释放 AI 的上下文窗口空间。
这就像你在听一场三小时的讲座,不可能把每句话都记下来。聪明的做法是:记下关键决策、待办事项、重要约束和核心结论。压缩模块做的就是这件事——它把对话历史提炼成一份”精华笔记”,让 AI 在有限的记忆空间里保留最有价值的信息。
但这里有一个关键问题:什么才是”有价值的信息”?
不同的人、不同的场景,对”有价值”的定义完全不同。程序员可能需要保留代码片段和错误日志,产品经理需要保留需求变更和决策记录,而作家可能需要保留创意灵感和情节构思。
OpenClaw 的设计思路是:不追求”记住所有”,而是追求”记住重要的”。通过结构化的五章节摘要格式(决策、待办、约束、用户问题、标识符),系统确保了无论什么场景,关键信息都不会丢失。
这种设计理念值得所有 AI 系统学习——在信息爆炸的时代,筛选能力比记忆能力更重要。
关键术语速查 – Compaction (压缩):将长对话历史压缩为结构化摘要的过程 – Safeguard (安全守卫):带质量审计的增强压缩路径,确保摘要结构完整 – Provider:可插拔的摘要生成提供者,替代内置 LLM 管线 – Split Turn (分割轮次):压缩时对话被分割为摘要部分和原文部分
1.2 架构全景:四层协作的精密系统
压缩不是简单的”删减文字”,而是一个多层协作的精密系统。我们可以把它想象成一家”记忆加工厂”:
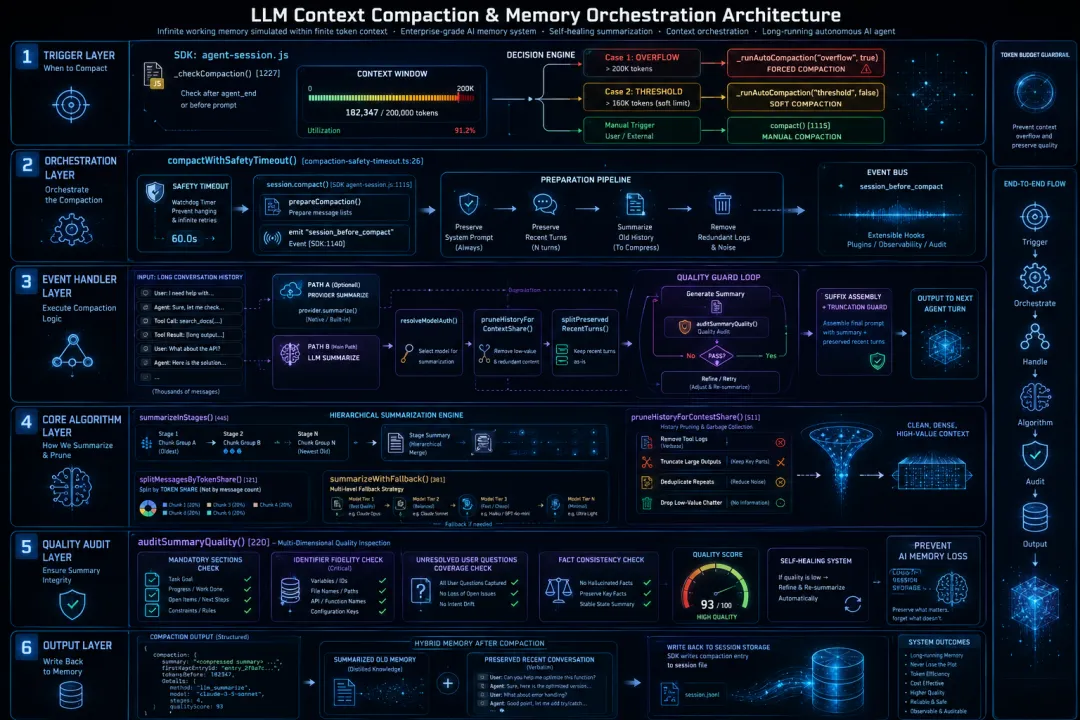
对话记忆压缩系统:六层架构
-
触发层 (Trigger Layer)
-
核心问题:“什么时候该压缩?”
-
功能职责:监控对话长度,决定压缩启动的最佳时机。
-
编排层 (Orchestration Layer)
-
核心问题:“怎么组织压缩流程?”
-
功能职责:协调整个系统的各个组件,准备待处理的消息队列。
-
事件处理层 (Event Handler Layer)
-
核心问题:“用哪种方式压缩?”
-
功能职责:智能选择压缩路径(如调用特定 Provider 或 LLM 大模型),并执行初步的质量守卫。
-
核心算法层 (Core Algorithm Layer)
-
核心问题:“如何切分和摘要?”
-
功能职责:实施具体的压缩算法,包括消息合理分块、生成渐进式摘要以及历史裁剪。
-
质量审计层 (Quality Audit Layer)
-
核心问题:“压缩质量合格吗?”
-
功能职责:充当质检员,严格检查压缩结果是否包含必需章节、关键标识符以及是否覆盖了用户的原始问题。
-
输出层 (Output Layer)
-
核心问题:“输出最终结果”
-
功能职责:将最终审核通过的压缩条目写入记忆库,并更新整个会话的状态。
这六层结构各司其职,共同完成从”检测”到”输出”的完整流程。接下来,我们逐层拆解。
第二部分:压缩的触发机制——什么时候该压缩?
2.1 四种触发方式
压缩不是随时都在进行的,系统会根据对话状态智能判断。主要有四种触发方式:
|
|
|
|
|---|---|---|
| 阈值触发 |
|
|
| 溢出触发 |
|
|
| 手动触发 |
|
|
| 抢占式触发 |
|
|
2.2 阈值触发:预防性压缩的主力
触发公式:
contextTokens > contextWindow - reserveTokens 这个公式的意思是:当已使用的 Token 数超过”上下文窗口大小”减去”预留空间”时,触发压缩。
contextTokens:当前对话已消耗的 Token 数量contextWindow:模型的最大上下文窗口(如 200,000 )reserveTokens:默认16,384,预留给未来对话的空间举个通俗的例子: 假设你的 AI 上下文窗口是一个容量为 200 升的水箱,预留空间是 16 升。当水量达到 184 升时,系统就会启动”排水压缩”程序,把旧水提炼成浓缩液,腾出空间继续接新水。
为什么需要预留空间? 这是一个非常重要的设计决策。如果不预留空间, AI 会在刚好满的时候才触发压缩,但压缩本身需要时间,而且在压缩完成之前,用户可能已经发送了新的消息。预留空间就像高速公路上的”安全车距”,给系统留出缓冲时间,避免因为突发情况导致”追尾”(上下文溢出)。
实际调优建议: – 如果你的用户经常发送长消息,可以适当增大reserveTokens – 如果对话节奏较慢,可以减小reserveTokens以提高内存利用率 – 但无论如何,不要设置为 0——没有安全边际的系统是脆弱的
2.3 溢出触发:紧急救援机制
当 AI 遇到上下文溢出时(比如模型返回错误,或实际输入超出窗口),系统会立即启动溢出恢复:
reason="overflow")这就像手机存储空间满了,系统自动清理缓存,然后让你继续正常使用。
2.4 抢占式触发:未雨绸缪的智慧
在发送新 prompt 之前,系统会预估:
estimatedPromptTokens > contextWindow - effectiveReserveTokens 如果预估新内容会导致溢出,系统会提前压缩,而不是等到溢出发生再补救。这种”未雨绸缪”的策略大大提高了系统的稳定性。
路由决策逻辑: – 如果溢出且没有可截断的工具结果 → 仅压缩 – 如果溢出但工具结果可截断 → 仅截断工具结果 – 如果溢出但截断不够 → 先压缩再截断 – 如果未溢出 → 正常执行
第三部分:压缩的核心逻辑——如何聪明地压缩?
3.1 消息分块策略:切蛋糕的艺术
压缩的第一步是把长对话切成合适的块。这里有三种核心策略:
策略一:按 Token 份额分割( splitMessagesByTokenShare )
核心原则: tool_call 和对应的 tool_result 必须在同一个 chunk ,不可拆分。
算法流程: 1. 计算目标 Token 数:targetTokens = totalTokens / parts 2. 遍历消息,累积 Token 3. 超过目标且无 pending tool_call → 切分 4. assistant 发出 tool_call → 记录 pendingToolCallIds 5. toolResult 匹配 → 从 pending 中移除 6. 全部闭合后超量 → 在边界处切开
这就像切蛋糕时,必须保证每块蛋糕上的”奶油和水果”是完整的,不能把一颗草莓切成两半分给两块蛋糕。
策略二:按上限切分( chunkMessagesByMaxTokens )
安全边际设计:
effectiveMax = maxTokens / 1.2 // 20%缓冲 为什么要留 20%的缓冲?因为 Token 估算可能存在误差。这就像你 packing 行李箱时,不会把每一寸空间都塞满,总要留点余地应对意外。
策略三:自适应比例( computeAdaptiveChunkRatio )
当平均消息占上下文超过 10%时,系统会自动降低分块比例:
avgRatio > 0.1 → reduction = min(avgRatio * 2, 0.25) 返回 max(0.15, 0.4 - reduction) 这意味着:对话越长、单条消息越大,分块就越精细。这是一种动态调整的自适应策略。
3.2 渐进式摘要管线:分阶段提炼
压缩的核心是生成摘要,但不是一次性完成,而是分阶段进行:
Stage 0 :前置判断
Stage 1 :分割 + 并行摘要
summarizeWithFallback())Stage 2 :合并摘要
MERGE_SUMMARIES_INSTRUCTIONS指令合并3.3 三级回退机制:确保万无一失
摘要生成不是一条路走到底,而是有三级回退保障:
Level 1: 完整摘要 → summarizeChunks(allMessages) ↓ 失败 Level 2: 部分摘要 → 排除超大消息(>50% context)再试 ↓ 失败 Level 3: 最终兜底 → 返回统计信息 想起以前数学考试时的答题策略:时间不够就挑重点答,实在不行至少写上关键公式拿步骤分…
3.4 安全裁剪:保护敏感信息
在压缩过程中,系统会进行两项安全裁剪:
裁剪一:移除 工具调用 的 details 字段 – 移除:原始输出、 stderr 、 exit code 等详细信息 – 保留:文本摘要、 toolCallId 、 toolName
原因:防止敏感信息泄露给摘要 LLM 。
裁剪二:移除运行时上下文 – 移除role === "custom" && customType === "openclaw.runtime-context"的消息 – 这些是系统内部消息,对摘要没有价值
3.5 历史修剪:丢弃最旧的,保留最有价值的
当历史消息超出预算时,系统会执行pruneHistoryForContextShare():
budgetTokens = contextWindow × maxHistoryShare(默认0.5)while token总量 > budgetTokens:分块 → 丢弃最旧 chunkrepairToolUseResultPairing() → 修复孤立 tool_result被丢弃消息单独摘要为 droppedSummary
第四部分:质量审计——如何确保压缩不丢关键信息?
4.1 三维度检查体系
压缩不是随便总结,而是要通过严格的质量审计。系统从三个维度检查摘要质量:
检查项一:必需 5 个章节 摘要必须包含以下五个章节: 1. Decisions(已做决策) 2. Open TODOs(待办事项) 3. Constraints/Rules(约束规则) 4. Pending user asks(用户待回答问题) 5. Exact identifiers(精确标识符)
这五个章节确保了摘要的结构完整性,就像一份合格的会议纪要必须包含决议、待办、约束等核心要素。
为什么是这五个章节?这背后有深刻的设计逻辑: – Decisions:记录已经做出的决定,避免重复讨论 – Open TODOs:追踪未完成的任务,确保工作不中断 – Constraints/Rules:保存用户设定的规则和限制,确保后续行为符合预期 – Pending user asks:记住用户提出但尚未得到回答的问题,避免用户重复提问 – Exact identifiers:保留精确的文件名、变量名、 URL 等,确保技术场景下的准确性
这五个章节覆盖了 AI 对话中最容易丢失、也最重要的信息类型。这是一种基于”遗忘成本”的设计——最容易忘记且忘记后代价最大的信息,必须强制保留。
检查项二:标识符存在性( strict 模式) 提取的标识符(如文件名、变量名、 URL 等)必须出现在摘要中。这是为了确保关键引用不丢失。
在编程场景中,一个变量名写错就可能导致代码无法运行。在文档处理中,一个文件名错误就可能导致找不到目标文件。 identifierPolicy=”strict”正是为了解决这个问题——它强制摘要必须包含所有关键标识符。
检查项三:用户问题覆盖 最新提问的关键词必须有 token 重叠。这是为了确保用户最关心的问题被摘要覆盖。
想象一下:你刚刚问了一个很重要的问题,结果 AI 因为压缩把这个问题”忘”了,这会有多糟糕?这个检查项就是为了避免这种尴尬情况的发生。
4.2 不合格处理:反馈重试机制
如果摘要质量不合格,系统会: 1. 注入 feedback instruction (反馈指令) 2. 重新生成摘要 3. 最多重试 3 次
第五部分:场景示例——真实工作流拆解
示例 1 :阈值触发流程
配置:contextWindow = 200,000, reserveTokens = 16,384触发阈值:200,000 - 16,384 = 183,616 tokens当前 contextTokens = 190,000 > 183,616 → 触发压缩处理步骤:1. _checkCompaction() → shouldCompact() 返回 true2. prepareCompaction() 计算 cut-point(keepRecentTokens = 20,000)3. safeguard 处理器:a. splitPreservedRecentTurns() 保留最近 3 轮b. computeAdaptiveChunkRatio() → 自适应分块c. summarizeViaLLM() → 生成摘要 (~3K tokens)4. 组装后缀 + 截断保护结果:上下文从 190K 降至 ~23K(摘要 + 保留轮次)
解读:一次典型的预防性压缩,将 190K 的上下文压缩到 23K ,压缩率约 88%,同时保留了最近 3 轮对话的原文,确保 AI 不会”断片”。
示例 2 :溢出恢复流程
场景:模型调用失败,返回 context overflow 错误处理步骤:1. isContextOverflow() 检测到溢出2. 移除错误消息3. 触发压缩(reason="overflow")4. 如果新内容占比过高:a. pruneHistoryForContextShare() 丢弃旧 chunkb. droppedSummary 整合历史5. 重试成功结果:摘要更紧凑,确保下次调用成功
解读:这是系统的”自救”机制。当溢出发生时,不直接报错,而是先压缩再重试,大大提高了系统的鲁棒性。
示例 3 :分块摘要合并流程
消息:40 条,80,000 tokensmaxChunkTokens = 65,904 (自适应计算)步骤 1:80K > 65K → 需分阶段步骤 2:splitMessagesByTokenShare(2) → 两 chunk(各 ~40K)步骤 3:chunk1 → partial1 (~2K), chunk2 → partial2 (~2K)步骤 4:partialSummaries 转为 user 消息步骤 5:MERGE_SUMMARIES_INSTRUCTIONS → 合并摘要 (~3K)结果:单次摘要无法处理的量大消息,通过分块合并成功压缩
解读:当对话量超出单次处理能力时,系统采用”分而治之”的策略,先分段摘要,再合并,最终生成一份高质量的结构化摘要。
第六部分:配置与优化——OpenClaw调参指南
6.1 核心配置参数
|
|
|
|
|
|---|---|---|---|
reserveTokens |
|
|
|
keepRecentTokens |
|
|
|
maxHistoryShare |
|
|
|
recentTurnsPreserve |
|
|
|
identifierPolicy |
|
|
|
qualityGuard.enabled |
|
|
|
timeoutSeconds |
|
|
|
6.2 关键常量解析
|
|
|
|
|---|---|---|
SAFETY_MARGIN |
|
|
BASE_CHUNK_RATIO |
|
|
MIN_CHUNK_RATIO |
|
|
SUMMARIZATION_OVERHEAD_TOKENS |
|
|
MAX_COMPACTION_SUMMARY_CHARS |
|
|
6.3 提示词构建四层指令体系
压缩质量的好坏,很大程度上取决于提示词的设计。系统采用四层指令体系:
Layer 1: SDK 系统提示词 (SUMMARIZATION_SYSTEM_PROMPT)"You are a context summarization assistant..."Layer 2: SDK 核心提示词 (SUMMARIZATION_PROMPT / UPDATE_SUMMARIZATION_PROMPT)初始摘要 vs 更新已有摘要Layer 3: Safeguard 结构指令 (buildCompactionStructureInstructions)5 个必填 section + 标识符保留 + re-distillLayer 4: OpenClaw 自定义指令 (buildCompactionSummarizationInstructions)"Additional focus: ..." + IDENTIFIER_PRESERVATION_INSTRUCTIONS
这种分层设计使得提示词既有通用性,又有灵活性,能够适应不同的压缩场景。
第七部分:摘要生成流程——从原始对话到结构化摘要
7.1 消息序列化格式
在压缩之前,系统会将对话消息序列化为特定格式:
[User]: 用户输入的实际文本内容[Assistant thinking]: 思维链内容[Assistant]: 文本回复内容[Assistant tool calls]: toolName(arg1="val1", arg2="val2")[Tool result (toolName)]: 工具返回的文本内容[non-text content: image x2, toolCall] -- 非文本占位符
这种格式清晰地标记了每类消息的来源和类型,便于摘要 LLM 理解上下文结构。
7.2 PreviousSummary 双机制
当已有摘要需要更新时,系统采用两种机制:
|
|
|
|
|---|---|---|
|
|
<previous-summary>
|
UPDATE_SUMMARIZATION_PROMPT
|
|
|
|
SUMMARIZATION_PROMPT
|
Re-distill 的含义:以旧摘要为参考,重新提炼,可删除过时内容,而非简单保留。这就像修订维基百科词条:保留有效信息,更新过时内容,删除冗余描述。
7.3 摘要截断保护
capCompactionSummaryPreservingSuffix()确保截断时后缀不被丢失: – 后缀内容: splitTurn + preservedTurns + toolFailures + fileOps + workspaceContext – 先截断 body ,保留完整 suffix
这保证了即使摘要被截断,关键的上下文信息(如保留的对话轮次、工具调用状态等)仍然完整。
结语: AI 记忆管理的未来趋势
为什么压缩技术如此重要?
在 AI Agent 日益普及的今天,上下文压缩已经不是一项”可有可无”的优化,而是AI 系统能够持续运行的基础设施。
没有压缩技术,许多场景都会因为上下文溢出而中断,AI 也会忘记刚才做了什么。有了压缩技术, AI 才能像人类专家一样,在长期工作中保持”记忆连续性”。
但压缩技术面临的挑战远不止于此。
首先,压缩本质上是一种信息损失。无论算法多么精妙,摘要永远无法 100%还原原始对话。这意味着系统设计者必须在”记忆容量”和”信息保真度”之间做出权衡。
其次,不同场景对压缩的需求差异巨大。代码审查需要保留精确的技术细节,而创意讨论可能更需要保留灵感和方向。一刀切的压缩策略无法满足所有需求。
最后,压缩质量难以客观评估。什么是”好的摘要”?这本身就是一个主观问题。系统只能通过结构化检查和关键词匹配来近似评估,但真正的质量往往需要人类来判断。
给开发者的启示
OpenClaw 的压缩模块展示了一个成熟 AI 系统的工程素养:不追求完美,但追求可靠。通过阈值触发、自适应分块、三级回退、质量审计等一系列设计,系统在各种异常场景下都能保持稳定运行。
这给我们几个重要启示:
第一,好的系统不是不犯错,而是犯错后能快速恢复。 三级回退机制和溢出恢复设计告诉我们:与其追求 100%的成功率,不如设计优雅的降级方案。
第二,安全边际不是浪费,而是保险。 预留 Token 、 20%缓冲、超时限制……这些看似”浪费”的设计,实际上避免了最糟糕的情况发生。
第三,结构化是可靠性的基础。 五章节摘要格式、标识符检查、用户问题覆盖……这些结构化约束确保了压缩质量的下限。
第四,可配置性是适应性的关键。 通过参数调节,同一个压缩系统可以适应不同场景的需求。不要试图用一个固定配置解决所有问题。
写在最后
下一次当你和 AI 进行长对话时,不妨想想:在后台,正有一套精密的系统在默默地为你”整理笔记”,确保 AI 不会忘记你们聊过的每一个重要决定。
压缩技术的终极目标,不是让 AI”记住更多”,而是让 AI”记住对的”。 在这个信息过载的时代,这或许比单纯的记忆容量扩展更有价值。
人工智能的未来,不在于它能处理多少数据,而在于它能否像人类一样,在海量信息中识别出真正重要的东西。上下文压缩,正是朝着这个方向迈出的重要一步。