 夜雨聆风
夜雨聆风





字节食堂打饭,我问同事"文档全塞进 context,模型咋更蠢了",阿姨勺子一停:"窗口能装 100 万,不代表 100 万字都看得进去啊."
大家好,我是吴师兄。
继续来个段子。
昨天在字节食堂打饭,我端着餐盘跟同事吐槽:
“现在的模型不是号称 100 万 token 上下文了吗?我图省事,把整个项目的 12 个文档、5000 字的需求、外加三轮对话历史全塞进去了。结果你猜怎么着——它连我开头说的那个字段名都记错了。文档明明就在 context 里,它睁着眼睛瞎编。”
同事还没接话,排在我后面的打饭阿姨把勺子往汤桶边沿一磕,”当啷”一声:
“窗口能装 100 万,不代表它 100 万个字都看得进去啊。你往一个人脑子里一口气塞十本书,再问他第三本书第 47 页写了啥,他不也得懵?”
我端着餐盘愣在原地。
那一刻我突然意识到,我对”上下文窗口”这个东西的理解,从一开始就是错的。我一直以为 context window 是个仓库,只要东西塞进去了,模型就”拥有”了这些信息,需要的时候随时能取。但真相是,context 更像是模型的工作台,而不是仓库。东西堆得越多,它在上面找一支笔的时间越长,找错的概率也越高。塞满 100 万 token,不等于这 100 万 token 都在为你这次回答出力,很多时候它们只是在互相干扰。
这就是这一两年悄悄成为大模型工程里最值钱的一项能力,上下文工程(Context Engineering)。它不是”怎么把 prompt 写得花里胡哨”,而是”在模型有限的注意力预算里,怎么只放对的东西、在对的位置、用对的形式”。今天这一篇,我把”为什么塞得越多反而越蠢”这件事,从原理到工程解法全部拆开讲。
一、先破一个最大的误区:上下文窗口不是仓库,是注意力预算
几乎所有人第一次用大模型,都会被”上下文窗口”这个词误导。听起来它像内存条,16G 不够我换 64G,文档装不下我换个长窗口模型不就行了?
但你只要做过一次稍微长一点的对话就会发现:模型的表现并不随 context 长度线性变好,反而在某个点之后开始下滑。 这不是模型偷懒,是 Transformer 的注意力机制决定的。
模型每生成一个 token,都要在已有的所有 token 上做一次注意力计算——简单说就是”我现在该重点看前面哪些内容”。注意力的总量是有限且需要分配的,它在所有 token 之间是一种此消彼长的竞争关系。context 里有 1000 个 token 时,每个关键信息能分到的”注意力份额”还算充裕;context 里塞了 50 万 token 时,真正重要的那几句话,被淹没在几十万个不相关 token 的稀释里,分到的注意力份额被摊薄到几乎可以忽略。
这就是为什么我那个 case 里,模型会把明明在 context 里的字段名记错——不是它没”存”住,是那条信息的注意力权重,被我塞进去的另外几千条噪声给冲没了。
我后来用一个特别土的类比理解这件事:context window 是会议室的桌子,不是隔壁的档案室。 档案室能放一万份文件(那是模型的训练知识 + 外部知识库),但你这场会议真正摊在桌子上、大家盯着讨论的,只能是有限的几份。你把一万份全堆到会议桌上,结果不是”信息更全了”,而是”谁也找不到要讨论的那一份了”。
上下文工程的全部出发点,就是把 context 当成一种稀缺资源来经营,而不是当成一个能无限堆东西的筐。
二、Lost in the Middle:模型对 context 中间段几乎是”瞎”的
如果说注意力稀释是”量”的问题,那还有一个更反直觉的”位置”问题——同样的信息,放在 context 的不同位置,被模型用上的概率天差地别。
斯坦福那篇被反复引用的研究(”Lost in the Middle”)做了一个特别干净的实验:把同一条关键信息,分别放在一长串文档的开头、中间、结尾,然后问模型这条信息相关的问题。结果画出来是一条非常标志性的 U 形曲线——
信息放在最开头,模型答对率最高;放在最结尾,答对率次高;放在正中间,答对率断崖式下跌,有些设置下甚至比”根本不给这条信息”高不了多少。
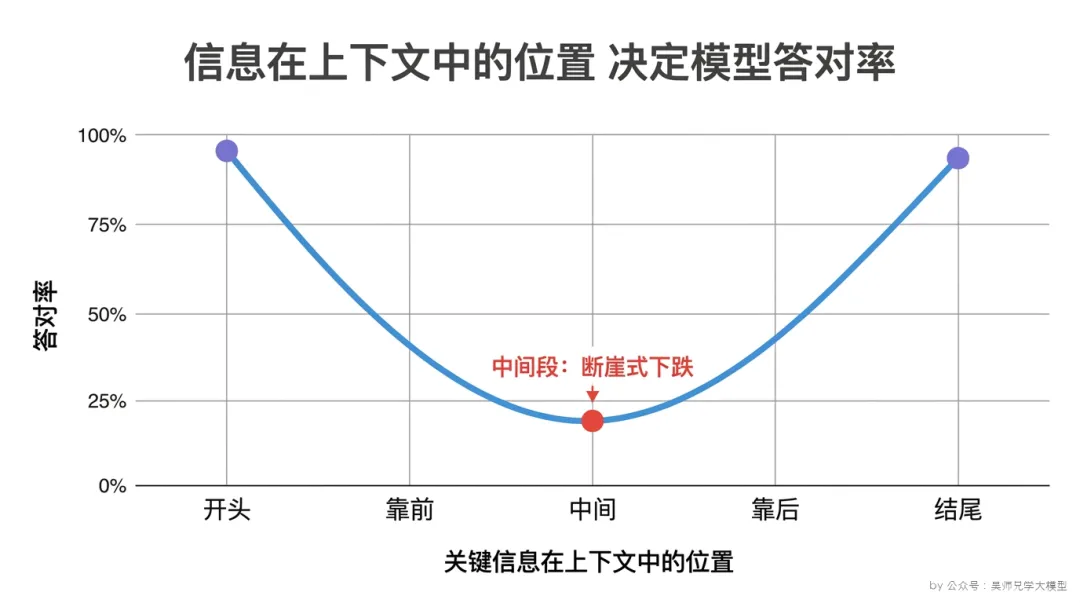
换句话说,模型读长 context,跟人考试前临时抱佛脚是一个德行——首因效应 + 近因效应,记得住开头和结尾,中间大段直接划水。你要是把最关键的那份合同条款、那个核心约束,恰好放在了一个 30 万 token 长 context 的正中央,那基本等于没放。
这件事对工程的杀伤力在于:它彻底否定了”反正窗口大,我按文档原始顺序一股脑灌进去”这种做法。文档的物理顺序,和”这条信息对当前问题有多重要”,是两件完全没关系的事。重要的信息如果落在了中间区,模型就是看不见。
在我们的金融保险 RAG 项目里,这个坑我们实打实踩过。早期版本检索回来 20 个 chunk,按相似度从高到低拼进 context。后来发现一个怪现象:明明 Top1 的 chunk 命中了答案,模型却用了排在第 8 位的一个错误 chunk 来回答。复盘下来就是——我们把 20 个 chunk 顺着拼,最关键的几个挤在了 context 中段的”盲区”里。后来我们改成把最相关的 chunk 放在最前和最后、次要的往中间塞,同一套检索结果,答案正确率直接抬了一截。没换模型、没改检索,只动了拼接顺序。
三、Context Rot:对话越长,模型越”上头”,越收不住
第三个现象,是做 Agent 和多轮对话的人最熟悉、也最头疼的——上下文腐烂(Context Rot)。
它说的是:随着对话/Agent 轨迹越来越长,context 里堆积了大量过期的、矛盾的、自我引用的内容,模型的输出质量会持续退化,而且会”越陷越深”。
最典型的场景,是一个跑了几十步的 Agent。它前面试过一个方案 A 失败了,把失败过程、报错、自己的反思全写进了 context;又试了方案 B 也失败了,同样全留在 context 里。等它走到第 30 步,回头看自己这一长串 context,里面全是”我刚才搞砸了”的痕迹。这时候模型很容易被自己之前的失败轨迹带跑——要么不断重复之前已经被证明无效的思路(因为那些思路在 context 里反复出现,注意力权重很高),要么被一堆中间状态搞得彻底找不着北。
我把它叫做”模型的精神内耗”。人 debug 到第三个小时会陷入”我是不是根本不会写代码”的自我怀疑,Agent 跑到第 30 步,context 里堆满自己的烂摊子,也会进入类似的状态——它不是在解决问题,它在反刍自己制造的垃圾。
Context rot 的根源,依然是前两节那两个机制的叠加:过期信息占用了注意力预算(稀释),而且这些过期信息往往体量很大、反复出现,权重不降反升(位置/频次)。解决它的关键不是”让模型更聪明地忽略垃圾”——你没法跟一个概率模型讲”这段你别当真”——而是从工程上根本不让垃圾在 context 里堆积。
这套上下文管理的完整工程实现,是我们训练营金融研报 Agent 项目里的核心模块。学员不只是学”上下文工程”这四个字怎么在面试里说,而是真的把一个会跑几十步的 Agent 从零写过一遍——从 context 的分层组织,到中间状态什么时候该写进去、什么时候该压缩成一句话摘要,每一个决策背后都有对应的 badcase 和调试记录。
四、四种工程解法:把 context 当稀缺资源来经营
讲完三个病因,来讲药方。上下文工程不是某一个技巧,而是一整套”如何经营有限注意力预算”的工程方法。我把它归成四类,从轻到重。
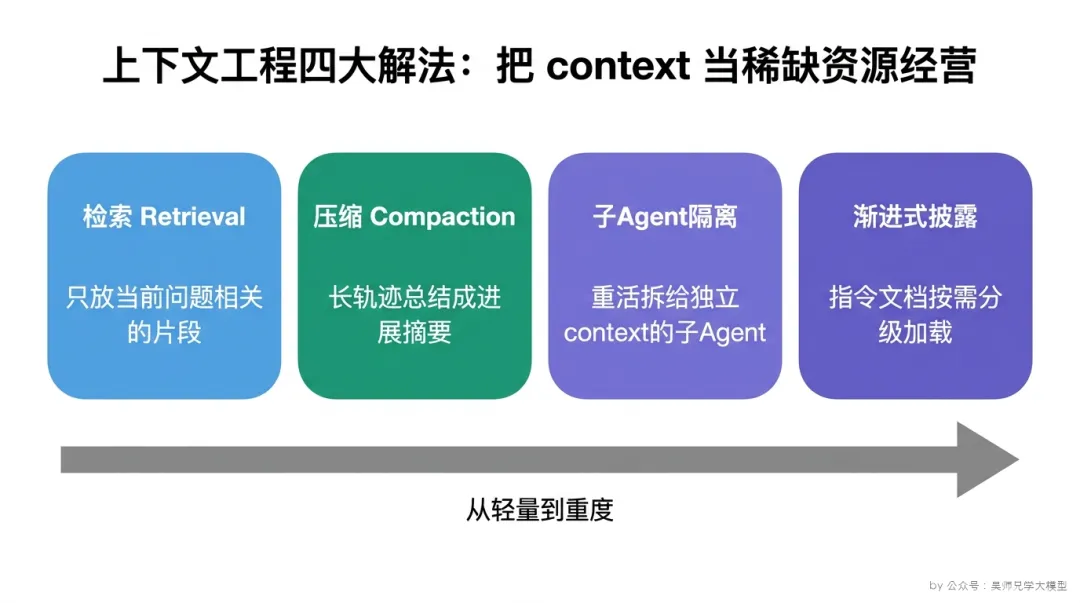
第一类:只放相关的——检索(Retrieval),而不是全量灌入。
这是 RAG 的核心思想,但它的本质其实就是上下文工程:与其把 5000 份文档全塞进去,不如先用检索找出当前这个问题真正需要的那 3-5 个片段,只把它们放进 context。这一步把”100 万 token 的噪声”压成”几千 token 的信号”,是性价比最高的一招。很多人以为 RAG 是”为了让模型能访问外部知识”,其实它更深层的价值是”为了让模型不必访问无关知识”。
第二类:放不下就压缩——摘要与状态压缩(Compaction)。
Agent 跑长了,历史轨迹一定会超。这时候不能简单粗暴地”砍掉最早的几步”(很可能砍掉关键约束),正确的做法是压缩:把前面 20 步的探索过程,用模型自己总结成一段结构化的”进展摘要”——做过什么、得到什么结论、当前卡在哪——然后用这段几百字的摘要替换掉原来几万 token 的原始轨迹。Claude Code 这类工具里的 context 自动压缩,干的就是这件事。压缩的艺术在于:留结论、留约束、留待办,扔掉过程噪声。
第三类:分而治之——子 Agent 隔离(Sub-agent Isolation)。
与其让一个 Agent 的 context 背负所有任务的全部细节,不如把一个大任务拆给多个子 Agent,每个子 Agent 有自己干净、独立的 context,只装它那一小块任务需要的信息。子 Agent 干完活,只把最终结论回传给主 Agent,中间那一大堆探索过程烂在它自己的 context 里、不污染主线。这就是为什么现在严肃的 Agent 系统都在往多 Agent 架构走——它表面是”分工”,底层是”context 隔离”。
第四类:用的时候再加载——渐进式披露(Progressive Disclosure)。
这是 Claude Skills 设计里最漂亮的一个思想,也是上下文工程的集大成。它不在一开始就把所有指令、所有文档全部塞进 context,而是分级按需加载:第一级只放一句话的元信息(让模型知道”有这么个能力、什么时候该用”);模型判断真要用了,才加载第二级的完整说明;需要某个具体文件了,才去读第三级。这样无论你背后挂了多少知识,任何一个时刻 context 里只有当前这一步真正用得上的那部分。我那天的错误——把 12 个文档一次性全灌进去——恰恰是渐进式披露的反面教材。
这四类不是互斥的,真实系统里是叠着用的:检索负责”只取相关”,压缩负责”长了就缩”,子 Agent 负责”重活隔离”,渐进式披露负责”按需加载”。四层下来,你才能在一个号称 100 万 token 的窗口里,始终维持一个”干净、聚焦、信号密度高”的有效 context。
五、一个反直觉的结论:有效上下文,往往比最大上下文更重要
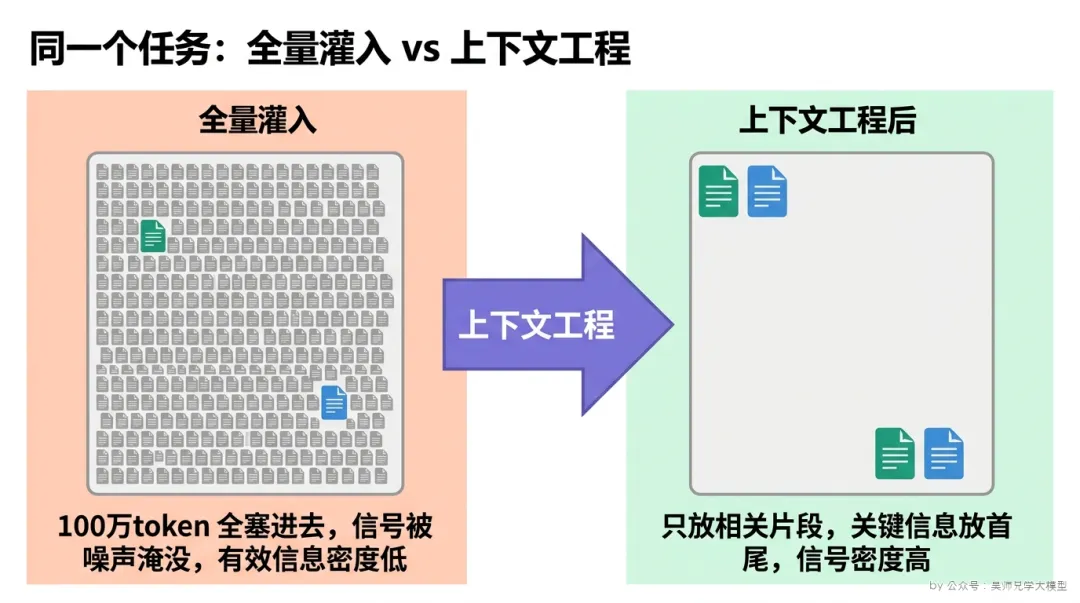
把上面四节串起来,会得到一个让很多人不舒服的结论:衡量一个上下文管理方案好不好,不看你能塞多少(最大上下文),看模型实际用上了多少(有效上下文)。
我见过太多人选型时第一句话就是”这个模型支持多长 context”,然后默认”越长越好”。但长窗口是一把双刃剑——它给了你”可以偷懒全塞进去”的能力,而这个能力恰恰是大多数人翻车的根源。真正成熟的做法反而是:哪怕我有 100 万 token 的窗口,我也要像只有 8000 token 一样去经营我的 context。 每放一段进去之前,先问一句——这段对当前这一步的回答,是信号还是噪声?
这也是为什么”上下文工程”这两年突然成了大厂面试的高频考点。它考的不是你背没背过某个名词,而是你有没有真正在长对话、长 Agent 轨迹上踩过坑——只有踩过的人,才会对”窗口大 ≠ 能力强”这件事有切肤之痛,才会本能地去管理 context,而不是无脑往里灌。
面试怎么答”为什么 context 越长,模型表现反而下降”?
如果面试官抛出这个问题,按这个框架答,能体现出你是真做过的:
先点破误区(30 秒)。 “上下文窗口不是仓库而是注意力预算。Transformer 的注意力是有限且需要分配的,context 越长,每条关键信息分到的注意力份额被稀释得越严重,所以塞得越多,重要信息越容易被噪声淹没。”
再讲位置效应(30 秒)。 “还有 Lost in the Middle 现象——同一条信息放在 context 开头和结尾命中率高,放在中间会断崖式下跌,呈 U 形曲线。所以不能按文档原始顺序硬灌,要把最关键的信息放在首尾位置。”
然后讲长程退化(20 秒)。 “多轮和长 Agent 轨迹里还有 context rot——过期、矛盾的中间状态堆积,会带着模型重复无效路径、越陷越深。”
最后给工程解法(40 秒)。 “解决靠四层叠加:检索只放相关片段、长轨迹做摘要压缩、重活拆给独立 context 的子 Agent、指令和文档用渐进式披露按需加载。核心原则就一句——哪怕窗口有 100 万 token,也要像只有 8000 一样经营 context,永远只放信号、不放噪声。”
写在最后
那天从食堂回到工位,我做的第一件事,是把那个一股脑塞了 12 份文档的 prompt 全删了,改成先检索、只拼最相关的三段、再把最关键的约束放在开头和结尾。同一个模型、同一道题,它一下就答对了。
我后来想,打饭阿姨那句”窗口能装 100 万,不代表它 100 万个字都看得进去”,其实是这个领域最朴素也最深刻的一句话。做大模型工程,很多时候不是在比谁喂得多,而是在比谁喂得准。 给模型的不是越多越好,是越对越好——这句话你可以带走。
今天这道题,只是大模型面试中上下文工程的一个切面。
真正的面试官不会只问这一问。他们会顺着你的回答追下去,追到你答不上来为止,判断的就是你到底做没做过这个系统。
背答案的人和真正做过的人,说话方式完全不一样。前者说”上下文太长就用 RAG 嘛”,后者说”我们金融文档场景实测过,同样 20 个检索 chunk,按相似度顺序硬拼,模型会用排第 8 的错误片段;把最相关的放到首尾、次要的塞中间,没换模型没改检索,答案正确率就抬上去了一截。”
面试官三句话就能听出来你是哪种人。
往期推荐
滴滴面试官摇头:”你 SKILL.md 全塞进 context 了?我刚翻完 Anthropic 文档,人家是按需加载的。” 我后背一凉
在字节食堂打饭,我问同事 “Agent 总是死循环怎么办”,打饭阿姨把勺子一放:”你给它设个 max_iterations 才几行代码的事你跟它讲道理?”