 夜雨聆风
夜雨聆风





博士后利用 OpenClaw+Claude Code 3 天完成遥感大数据分析与论文,直接登上 Nature 封面,影响因子 54.8!
📚 课程一:面向真实科研场景,构建由Codex、Claude Code、OpenClaw、Hermes四位”AI研究员”组成的可迭代、可迁移的科研协作团队实战培训班
📚 课程三:前沿AI-Agent2.0工具链深度科研应用系统教学方案:贯通LLM、Claude Code、codex、OpenClaw、Hermes-meta、人机协同实现从文献挖掘到成果产出的科研效率革命
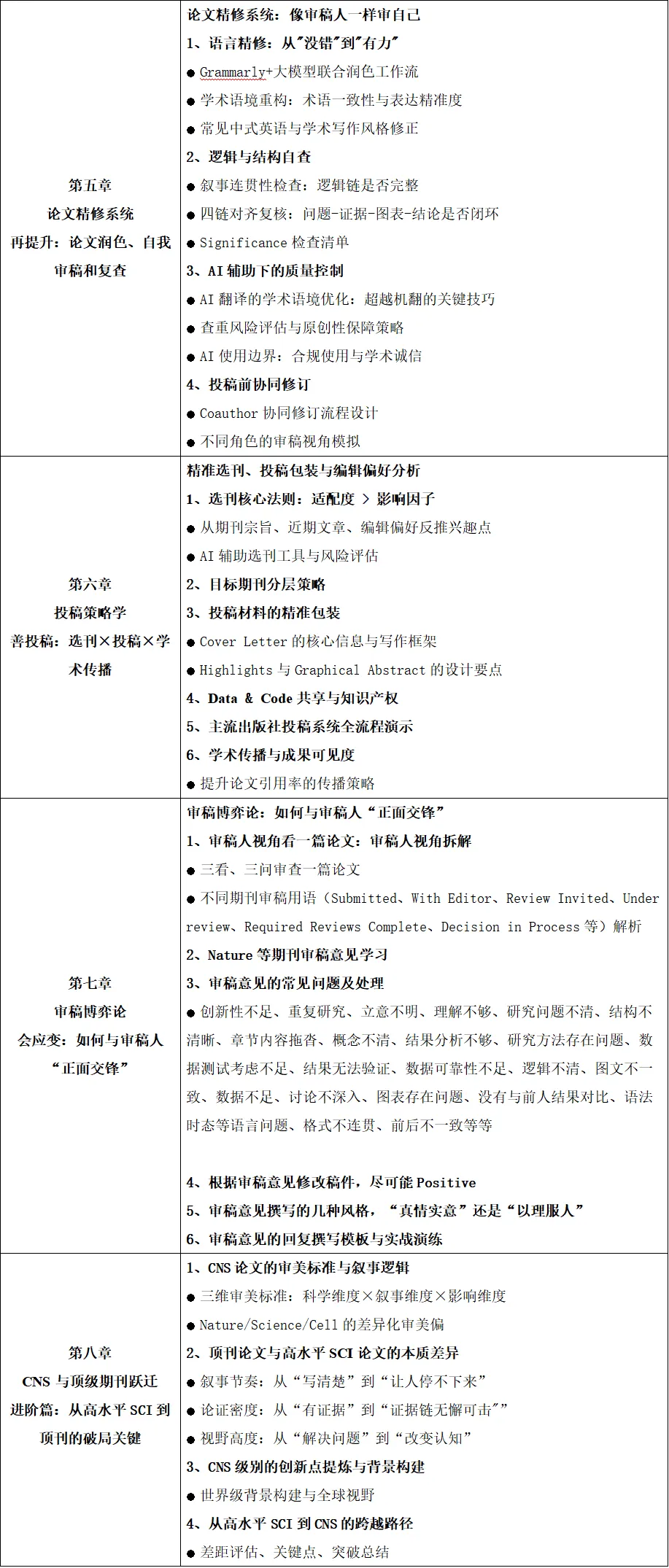
📚 课程四:高水平学术论文写作的“破局”之道暨AI赋能下前沿选题、智能写作、科研可视化、精准选刊与投稿、审稿博弈策略及CNS顶刊跃迁进阶全链路实践培训班
📚 课程五:2027年国自然与省级基金项目申报全链条实战升级暨AI人机协同撰写、立项依据精修、关键科学问题凝练、技术路线图设计、评审逻辑深度拆解、申报复盘经验融入与高质量本子打磨高级培训班
李莎:158-3333-2534(微信同步 ) QQ咨询:422573623


课程的深层价值在于“逐章增厚”的进化机制——随着Codex、Claude Code、OpenClaw、Hermes四Agent的协同推进,文献管理、数据提取、分析建模、科研图示、材料组织与成果传播被逐一串联为一条完整的科研工作流,每一章的产出都通过Command指令包和Hook日志回写至Obsidian项目知识库。随着课程推进,您的助手不断积累能力、记忆与工作范式,最终形成一套跨学科通用、可直接迁移至个人课题的完整资产包:包含项目目录结构、四Agent分工配置、可复用Command指令集、Skill/MCP连接方案、复核清单与质量控制流程。无论您的研究方向如何,这套系统都将成为您长期科研道路上的智能协作基础设施。应广大科研学者需求,AI尚研修特举办此次培训,现通知如下:
【适合这样的科研工作者】:
希望将AI系统性地融入科研流程、为自己或课题组搭建可复用科研助手的高校教师、科研人员。不限学科方向,所有涉及公开数据、统计建模与科研产出的领域均可适用。【学习收获】:
1.专属的AI科研团队——掌握Codex、Claude Code、OpenClaw、Hermes四Agent协同分工与部署配置,拥有24小时在线、各司其职的科研协作伙伴。
2.贯通的科研自动化链路——从文献线索归档、PDF深度提取、数据分析与建模,到科研图示生成、Meta分析、论文材料组织与成果传播,全流程跑通。
3.持续进化的项目知识库——通过逐章回写Obsidian,积累Command指令、Skill技能、Hook日志与Memory记忆,让助手随您的研究不断”增厚”。
4.跨学科复用的科研资产包——项目目录模板、复核清单、质量控制流程、成果迁移模板,可直接用于个人课题或团队项目。
5.高效的科研工作范式——建立“Agent执行、人工复核、参数留痕、版本管理”的规范习惯,让重复性工作交给AI,您聚焦学术洞察与创新思考。
6.长期陪伴的科研伙伴——与来自不同学科的学员共同探讨四Agent在科研中的应用经验。
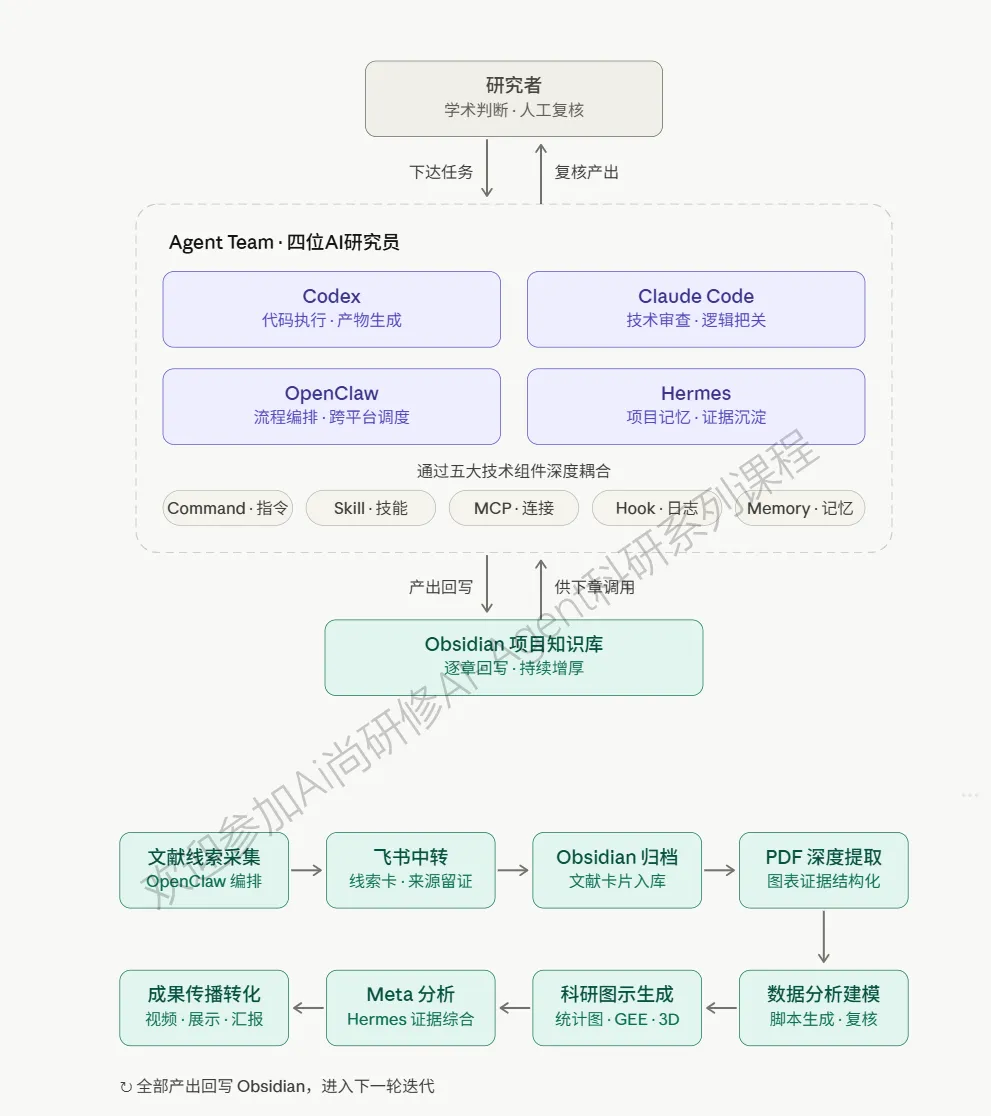
专题一 智能科研基础设施:四Agent部署安装与科研工作台搭建
1.Codex、Claude Code、OpenClaw、Hermes的定位、入口、账号与权限检查
2.Python、Git、VS Code、Obsidian、飞书、项目目录和脚本环境配置
3.四Agent分工:Codex执行产物,Claude Code复核代码,OpenClaw编排流程,Hermes积累项目记忆
4. 个人或课题组科研工作台目录:data、scripts、outputs、figures、notes、review
5. 首个可运行脚本、复核清单和项目模板初始化
6.Agent实现:用CLAUDE.md/Memory定义项目规则,搭建四Agent Team,建立Command目录、基础Skill清单、MCP连接测试和Hook日志
案例与产出:
案例:以一个学员自带研究问题建立科研工作台
产出:四Agent安装检查表、项目目录模板、工具分工图和首个可运行脚本
Agent产出:四Agent Team配置表、Command指令包、Skill/MCP/Hook/Memory检查表
回写助手仓库:本章产出的项目目录、CLAUDE.md、Command目录和Skill/MCP/Hook清单全部回写助手仓库,作为后续各章的初始状态。
专题二 科研流程智能解构:科研痛点诊断、任务拆解与四Agent协同路径
1.科研链路中的高频痛点:选题、文献、数据、脚本、图表、解释、交付与复核(其中选题不在本课程单独展开,而是承接第四章PDF提取出的可迁移Idea,逐步收敛为研究问题)
2.把研究问题拆成“资料—数据—方法—脚本—图表—表达—交付”任务链
3.Codex、Claude Code、OpenClaw、Hermes在不同环节的进入方式
4.system/messages上下文、Command、Hook、Memory和Sub Agent分工模板
5.人工复核点、版本记录、参数留痕和材料归档要求
6.Agent实现:把研究问题写成system目标与messages任务链,由OpenClaw编排Sub Agent,Hook记录复核节点,Memory保存项目决策
案例与产出:
案例:城市热风险、公共健康或科研机构项目任务拆解
产出:科研场景任务单、四Agent介入路径图和人工复核清单
Agent产出:任务链Command、Sub Agent分工表、Hook复核节点和Memory记录
回写助手仓库:本章的任务链Command、Sub Agent分工表和Memory决策回写Obsidian与助手仓库,助手首次“变厚”。
专题三 智能文献管理:多平台文献线索采集与OpenClaw文献管理工作流
1.公众号、抖音、小红书文献线索的入口设计、线索采集、截图留证和来源记录
2.OpenClaw编排多平台线索进入飞书,再同步到Obsidian文献库
3.文献卡片字段:标题、作者、DOI/链接、来源平台、发布时间、截图证据、研究问题和下一步任务
4.MCP连接、Hook记录、Command复用、权限设置、异常处理和资料归档规范
5.让手机端碎片化文献线索从一次性收藏转为可检索、可复用、可复核的文献管理流程
6.Agent实现:OpenClaw编排公众号/抖音/小红书/飞书/Obsidian MCP与手机线索Hook,Command复用文献归档流程
案例与产出:
案例:OpenClaw编排公众号、抖音、小红书文献线索进入飞书和Obsidian
产出:多平台文献线索采集表、Obsidian文献卡片字段、资料归档规范、归档Command和复核清单
Agent产出:多平台线索MCP场景、线索Hook、归档Command和复核模板
回写助手仓库:本章的文献卡片、归档Command和线索Hook回写Obsidian文献库与助手仓库,供后续章节直接调用。
专题四 自动化内容深度提取:PDF论文图片资料提取与证据整理
1.承接第三章归档的文献线索,对其中的PDF论文全文做深度提取:研究问题、样本范围、变量指标、方法参数、表格、图片、图注和补充材料
2.论文图片、机制图、流程图、结果图、表格截图和数据线索的结构化整理
3.DOI、数据来源、开放许可、图注和可复现实验线索核验
4.把PDF论文图片资料转成结构化提取表、数据线索清单、图片证据库和缺失信息清单
5.Hermes/Obsidian 保存文献卡片,Claude Code复核表格逻辑和证据边界
6.Agent实现:封装PDF/图片/表格提取Skill,调用文献/文件MCP,使用多模态messages处理截图、图表,Hermes Memory保存文献卡片
案例与产出:
案例:使用公开论文或学员自带论文完成PDF论文图片资料提取
产出:PDF论文图片资料提取表、图表证据库、数据线索清单、缺失信息清单和复核记录
Agent产出:PDF图片提取Skill卡、文献Memory模板和复核Command
回写助手仓库:本章的提取表、证据库、可迁移Idea卡片和提取Skill回写Obsidian与助手仓库,接第二章的选题线索。
专题五 数据自动化工程:自动化检索、下载、处理分析与可视化案例
1.Google Dataset Search、Kaggle、Google Trends、GEE等公开数据入口的使用边界
2.公开数据下载流程:关键词检索、数据筛选、许可核验、字段说明和本地缓存
3.CSV/Excel/API数据下载后的目录管理、版本留痕和质量控制
4.GEE 遥感与空间数据:区域选择、时间窗口、图层加载、导出成果图
5.用Codex 生成数据处理脚本,用Claude Code复核下载逻辑和字段含义
6.Agent实现:配置公开数据检索Skill和下载Command,MCP连接数据入口,Hook留存许可、字段和版本,messages记录检索依据
7.四Agent在场:Codex生成脚本、Claude Code复核,本章产物由OpenClaw串入文献—数据流水线、由Hermes记忆沉淀。
案例与产出:
案例:经济趋势、公共卫生风险或GEE空间制图
产出:公开数据下载清单、数据字典、许可复核表、Python处理脚本、GEE脚本和成果图
Agent产出:数据检索Skill、下载Command、MCP入口清单和许可Hook日志
回写助手仓库:本章的数据字典、许可Hook、检索Skill和下载Command回写Obsidian与助手仓库。
专题六 科研自动化建模:统计分析、机器学习与Transformer应用案例
1.CSV、Excel、API数据读取,字段清洗、缺失值处理和数据字典整理
2.pandas、plotly/matplotlib、scikit-learn在科研表格、时序和空间数据中的使用
3.回归、分类、聚类、降维等机器学习基线模型与结果解释
4.Transformer 在论文文本、舆情文本、时间序列或复杂特征提取中的入门演示
5.Claude Code 对脚本、指标、误差来源和解释边界进行复核
6.Agent实现:建立Python建模Skill与评估Command,Hook记录参数、usage和stop_reason,Claude Code Sub Agent复核Transformer脚本
7.四Agent在场:Codex建模、Claude Code复核,本章脚本与评估结果由OpenClaw串入流水线、由Hermes记忆沉淀。
案例与产出:
案例:公共健康、城市热风险或科研机构项目数据分析
产出:Python脚本包、机器学习基线结果、Transformer演示脚本、模型评估图和复核清单
Agent产出:建模Skill、评估Command、参数Hook日志和复核记录
回写助手仓库:本章的脚本包、评估图、参数Hook和建模Skill回写Obsidian与助手仓库。
专题七 三维智能制图:Codex CLI驱动Blender科研3D可视化
1.科研3D图的适用场景:机制路径、实验装置、器官结构、空间过程和成果展示对象
2.Codex 生成 Blender Python 脚本、CLI运行命令、对象清单、材质灯光、相机角度和标注层
3.从文字机制描述到3D场景草图、渲染图和图注说明
4.科研论文、基金申报、项目汇报中的3D图示复核要求
5.把Blender CLI脚本、运行命令、渲染图和参数记录保存为可复用图示资产
6.Agent实现:Codex作为Blender CLI Sub Agent生成脚本和运行命令,用3D图示Skill、渲染Command和Hook保存场景参数
7.四Agent在场:Codex生成图示、Claude Code复核,本章渲染图与参数由OpenClaw串入流水线、由Hermes记忆沉淀。
案例与产出:
案例:污染暴露—人体器官—健康结局机制图或农田遥感监测三维场景
产出:Codex使用CLI方式控制Blender提示词模板、Blender CLI脚本、运行命令、渲染图、图注和资产目录。
Agent产出:Blender CLI Skill、渲染Command、场景参数Hook和批量导出记录
回写助手仓库:本章的Blender CLI脚本、渲染图、场景参数Hook和图示Skill回写Obsidian与助手仓库。
专题八 科研材料智能组织:Claude Code生成论文-基金-专利Visio流程图与科研材料组织
1.把数据结果、文献证据、项目记忆和图表解释转成论文、基金和专利材料
2.论文结果段、图注、基金立项依据、研究内容、技术路线和专利实施例整理
3.Claude Code生成并复核论文、基金、专利所需的Visio技术路线图、研究框架图、实施流程图和证据链图
4.Claude Code 复核脚本目录、引用来源、证据链、相似专利和流程图节点逻辑
5.材料生成后的署名、伦理、知识产权和人工复核边界
6.Agent实现:Claude Code作为材料复核Sub Agent,用Visio流程图Skill和材料Command生成流程,Hook记录证据链和人工确认
案例与产出:
案例:围绕第五、六章数据图表生成论文/基金/专利材料草稿
产出:论文-基金-专利流水线模板、Claude Code生成论文基金专利Visio流程图模板、材料生成检查表和证据核验清单
Agent产出:材料Command、Visio Skill、证据链Hook和Claude Code复核记录
回写助手仓库:本章的Visio流程图、材料Command和证据链Hook回写Obsidian与助手仓库,供论文基金专利反复调用。
专题九 循证研究自动化:Hermes Meta分析与证据综合实战
1.Meta分析完整流程:PICO/PECO、检索词、纳排标准、筛选表、数据抽取表和偏倚风险评价
2.Hermes管理证据记忆和研究上下文,Codex生成统计脚本,Claude Code复核逻辑与代码
3.森林图、漏斗图、敏感性分析、异质性解释和证据复核流程
4.把检索、筛选、抽取、统计、复核和写作串成可检查的证据综合流水线
5.Meta分析结果如何进入论文、基金、项目汇报和成果转化材料
6.Agent实现:Codex、Claude Code、Hermes组成Meta分析Agent Team,Sub Agent分管筛选、抽取和统计,messages记录证据状态
案例与产出
案例:公共健康、临床研究或数字化干预主题Meta分析
产出:Hermes Meta分析启动包、PICO/PECO表、纳排标准、统计脚本、森林图和证据复核流程
Agent产出:Meta分析Agent Team配置、筛选Command、统计Skill和证据Memory
回写助手仓库:本章的筛选Command、统计Skill和证据Memory回写Obsidian与助手仓库。
专题十 科研成果智能传播:科研成果传播与成果转化素材制作
1.把科研图表、GEE成果图、Blender 3D图、交互展示页面和研究说明转成成果传播素材
2.3D展示网站:机制路径、实验装置、空间过程、器官结构或遥感场景的交互式展示
3.HyperFrames科研传播视频:问题引入、数据来源、方法步骤、关键图表、结论提示和应用价值
4.成果转化材料:项目汇报、科普展示、申报路演、技术路线、项目一页纸和成果展示材料
5.教学或培训材料只作为可选延展,用一小节说明如何从科研传播素材改写,不单独展开
6.Agent实现:Codex生成展示页面、分镜、配音、字幕轨道和HyperFrames工程;Claude Code复核旁白、时间轴、素材引用、版权边界和导出配置;Hook记录素材来源和导出参数
案例与产出
案例:围绕GEE成果图、3D科研图或公开数据分析结果制作科研传播材料
产出:3D展示原型、科研宣传视频工程、字幕JSON/SRT、项目一页纸、成果转化展示材料和Claude Code复核清单
Agent产出:展示生成Command、视频分镜Command、字幕Skill、音频字幕Hook日志、Claude Code复核Command和素材清单
回写助手仓库:本章的展示生成Command、视频分镜Command、字幕Skill和素材清单回写Obsidian与助手仓库,形成可持续迭代的闭环。
结课综合项目(核心):专题十一:四Agent科研助手闭环项目实战
综合以上能力融合完整闭环项目实战:四Agent协同跑通”多平台文献线索—飞书—Obsidian—PDF提取—数据分析—科研图示—Meta—成果转化”完整链路,AI科研助手最终成型。
1.多平台文献线索进入飞书
任务:OpenClaw编排公众号、抖音、小红书文献线索、群消息或截图进入飞书,保留来源平台、时间、原文链接、截图证据和初步标签。
产出:飞书线索卡、来源记录、线索Hook日志
2. Obsidian自动整理并触发
任务:OpenClaw将飞书线索写入Obsidian文献库;Obsidian模板自动生成字段,新增卡片触发后续PDF论文图片资料提取、数据线索整理和Command/Hook。
产出:Obsidian文献卡片、标签字段、触发Command
3. PDF论文图片资料提取与Idea整理
任务:Codex提取论文PDF中的研究问题、变量、样本、方法、表格、图片、图注、可复现数据线索和可迁移Idea;Claude Code复核证据边界。
产出:PDF论文图片资料提取表、数据线索表、Idea卡片、待核查清单
4.分析处理数据并生成科研图片
任务:Codex完成公开数据读取、清洗、建模和可视化;需要三维表达时用CLI方式控制Blender生成科研图。
产出:Python脚本、统计图、GEE成果图、Blender CLI渲染图
5A.论文初稿路径
任务:Codex生成方法段、结果段、图表说明和讨论框架;Claude Code复核逻辑、术语、引用边界和人工确认点,并按第八章流程生成论文/基金/专利所需的Visio技术路线图。
产出:论文初稿、图表说明、Visio技术路线图、人工复核清单
5B.Hermes Meta分析路径(从第3步文献证据分叉,主要消费文献而非第4步原始数据)
任务:Hermes把第3步提取的文献纳入Meta分析候选库,管理PICO/PECO、纳排状态、证据记忆;Codex生成统计脚本,Claude Code复核。
产出:Meta分析初稿、筛选表、森林图脚本、证据记忆
6.科研传播与成果转化路径
任务:Codex生成HyperFrames分镜、配音、字幕和视频工程;Claude Code复核旁白、字幕时间轴、素材引用和导出配置;把科研图表、3D图和视频素材转为科普展示、项目汇报和成果申报材料。
产出:科研宣传视频工程、字幕JSON/SRT、导出配置、项目一页纸和成果转化材料
7.回写知识库与下轮迭代
任务:所有结果回写Obsidian项目库,保留Command、Hook日志、复核清单和下次调用上下文。
产出:项目知识库、成果索引、下一轮任务清单
最终项目成果:1个自动化AI科研助手原型、1个Obsidian项目库、1份PDF论文图片资料提取表、1份数据与Idea提取表、1组科研图片、1篇论文初稿或Meta分析初稿、1个科研宣传视频、1套成果转化展示材料。

【课程定位】:
目标学员:所有以数据为基础的定量研究方向均适用,只要你能整理出数据+分析脚本+统计结果+图表+核心结论,流程就能迁移。覆盖理工、农林、地学、环境、生态、医学、公共卫生、药学、心理、社科定量、经管、教育、信息等领域的研究生、博士生、博士后、青年教师及科研人员。
前置要求:有科学上网条件、课前完成环境预装(提供详细指南和助教支持)核心工具:Claude Code + OpenAI Codex CLI + VS Code。
教学数据:讲师演示使用一份通用公开数据集——用”通用数据”跑出”科研实战”:完整走通 数据获取→清洗→统计→图表→论文初稿→双AI审稿→投稿材料包全流程。方法完全通用,学员可直接替换为自己领域的数据(CSV/Excel/JSON/Parquet/SQL/NetCDF/HDF等格式均支持);
课程产出:一篇经过多轮AI交叉审稿、具备投稿前内部打磨基础的论文草稿(Markdown + DOCX),含符合主流期刊投稿格式的图表、Cover Letter、citations_todo、claim 校准报告与完整审稿轨迹。
|
|
【范式转移】每次开新项目都要从头跟AI解释一遍课题背景→把课题背景沉淀进项目配置,AI在第一轮回复中就能用上你课题的术语、数据约束和目标期刊。
1、Claude Code + Codex CLI双工具安装与模型选型(Opus / Sonnet / Haiku 的成本与能力权衡)
产出:可用的双AI环境(claude –version + codex –version通过)
2、CLAUDE.md:把研究问题、数据来源、方法学约束、目标期刊写成 AI 永久可读的项目配置
产出:项目专属CLAUDE.md
3、Memory系统:跨对话保持研究上下文(research question/data/ findings)
产出:Memory配置
4、项目骨架:my-paper/{data, figures, runs, submission}
产出:完整科研项目骨架
验收标准:claude–version + codex –version输出有效版本号;CLAUDE.md含研究问题/数据/方法/期刊四项;my-paper/下data、figures、runs、submission四个目录全部存在;同样的提问,有CLAUDE.md与无 CLAUDE.md的两个回答质量肉眼可分。
【范式转移】下载/清洗/统计脚本写3天、bug反复改→自然语言描述假设,AI输出可运行脚本+字段齐全的统计结果JSON(每个数字都可追溯到来源脚本)。
1、用Claude Code生成数据下载脚本(API/FTP/Web多种方式)
产出:下载脚本
2、数据清洗:缺失值、异常值、格式转换(CSV / Excel / JSON / Parquet / SQL)
产出:清洗脚本
3、自然语言→分析脚本:描述研究假设,Claude Code 协作设计分析方案(作者最终决定方法学选型)
产出:200+行Python脚本
4、统计严谨度全套:Bootstrap CI、Cohen’s d效应量、多重比较校正、精确p值
产出:analysis_results.json(论文的”写作依据文件”)
验收标准:analysis_results.json中每个主要结果必含estimate/ ci_low /ci_high/n/test/p_exact/script_path七个字段;脚本可在干净环境复跑、结果可复现。
【范式转移】图表是写完文字后再补的”装饰”→图表先于文字成型,每张图作为一个claim的数据载体(图表即论证结构的一部分)。
1、符合主流期刊投稿格式的图表标准(字体/DPI/配色/error bars/ colorblind-safe)
产出:matplotlib模板
2、常见图表类型实操:scatter、heatmap、bar+CI、时间序列、forest plot
产出:3-4张图
3、多panel组合图:gridspec布局与统一配色
产出:组合figure(fig1_*.pdf + .png)
4、每张图 ↔一个claim的强绑定(参考顶刊论文图组组织方式)
产出:figures/投稿可用图表目录
验收标准:每张图配caption并标注对应的claim id;error bars/单位/ colorblind-safe三项自查通过;figure与analysis_results.json字段对应可追溯。
1、论文结构按 Title→Abstract(broad significance)→Intro→Results→Discussion→Methods拆解
产出:论文大纲
2、Results:AI读JSON,自动嵌入effect size + 95% CI + n + 检验方法+精确p
产出:Results初稿
3、Discussion:机制解释+文献对比+局限性(不过度解释、不overclaim)
产出:Discussion初稿
4、Introduction:broad significance+知识空白+本文贡献
产出:draft.md完整初稿v1
关键技巧:让AI引用真实数字而非编造;用Memory防止长文写作中上下文丢失
验收标准:draft.md中每个核心数字都标注JSON来源字段(如[from: aod_trend.estimate]);Discussion每段对应一个claim id;无 [NUMBER_NEEDED] 占位符遗留;引用全部为 [CITATION_NEEDED: 主题] 占位(不允许AI编造DOI)。
1、主流期刊AI使用政策(Nature/Science/Elsevier/AC /AGU最新规定)+各期刊披露模板
2、贯穿式质控钩子:M1留CLAUDE.md/Memory配置;M2留 analysis_results.json + script_path;M4留prompt日志;M6/M7留review_round_N.md + revisions_log;M9留citations_todo.md + DOI核验状态
3、引用核验规则:AI生成的引用一律标记[CITATION_NEEDED],DOI / PMID /原文核验状态写入citations_todo.md,签字前100%人工核验
产出:ai_disclosure.md+数据上传红线清单+全程审计档案目录
验收标准:每条AI输出都能在runs/目录追溯到对应prompt +模型版本+时间戳;ai_disclosure.md含披露段+数据上传红线清单+引用核验状态字段。
|
第二天:阶段③压力测试(M7-M9)+阶段④投稿封装(M10-M11) 产出:3轮审稿轨迹 + score_history.json + claim_calibration.md + manuscript.docx + cover_letter.md +学员自己课题的端到端样例 |
【范式转移】写完只能等同事或导师挑刺,反馈慢、面子薄、不彻底→内部AI压力测试审稿人,按高水平综合期刊常见叙事标准做投稿前自查,不带情绪、不顾忌面子,按文件交付审稿报告。
1、Codex CLI配置+进程隔离验证(Codex在独立子进程运行,看不到 Claude 的system prompt,是真正独立的第二个AI)
产出:可用的Codex环境
2、把draft.md发给Codex:要求打分、列弱点、找overclaim
产出:review_round_1.md(典型4-5/10——低分是故意保留涨分空间)
3、解读首次审稿报告:overclaim/missing citation/statistical gaps/ 图表不支撑结论
产出:问题清单
学员关键时刻:”论文被打低分=看见涨分空间”——比让同事帮看更彻底、更可追溯
验收标准:review_round_1.md包含总分+问题分类(overclaim/stats/ citations/figures/structure)+具体修改建议;每条建议可对应 draft.md中的具体段落。
【范式转移】审稿意见看一遍就大改特改、越改越乱 → 一轮只修一类问题、每轮独立打分、分数曲线作为质量信号。
1、Round 1:措辞收敛(proves→is consistent with;rules out→argues against)
Codex重打分,预期变化+1~2分
2、Round 2:补引用+加统计检验+完善limitations
Codex再次审稿,预期变化+1分
Round 3:针对性修复剩余弱点→进入可继续打磨的内部初稿状态
3、核心能力:
科研措辞分寸:从”proves”到”is consistent with”(observation ≠ causation)
引文补充:用Claude Code的WebSearch查找缺失引用
每轮改进对照记录(revisions_log + score_history.json)
验收标准:score_history.json记录每轮总分与各维度分变化;revisions_log_round_N.md列出每轮修改前后对照;每轮针对一类问题修复且修改可对照(分数趋势作为参考,引入更严格标准时短暂回调正常)。
【范式转移】自己拍脑袋决定 claim强度,要么过强要么过弱→两个AI用同一把尺子独立打分,分歧暴露后由作者拍板。
1、/claim-check双盲打分流程:Claude和Codex看同一份claims.yaml,各打各的分
产出:双方评分对比表
2、分歧聚焦:哪些claim双方都打低分?哪些只有一方打低?为什么?
产出:claim_calibration.md
3、调整claim强度落地到正文:从过强/过弱拉回到数据支撑区间
产出:校准后的措辞清单(科研合规的最后一道把关)
验收标准:每个claim在claim_calibration.md中获得support_level: strong/moderate/weak/unsupported;分歧claim(两AI分差≥2)单独列出并附作者裁决理由。
【范式转移】投稿前1周突击拼凑cover letter、改图、补引用,焦头烂额→/finalize按核验清单组装投稿材料初版,作者按核验清单逐项定稿。
1、Codex审图:标签、单位、配色、可读性、colorblind-safe
产出:审图报告
2、修图:去夸张标题、加error bars、统一字体大小
产出:终版图表
3、Claude Code生成manuscript.docx初版(嵌入图表)——作者最终决定是否定稿
产出:submission/manuscript.docx
4、引用格式化(按目标期刊:Nature-style/APA/国标)+DOI/PMID人工核验清单
产出:submission/citations_todo.md(每条引用一行:DOI、核验人、核验状态)
5、Cover Letter初版生成+novelty陈述+推荐审稿人草拟——作者改写定稿
产出:submission/cover_letter.md
验收标准:manuscript.docx + cover_letter.md + citations_todo.md三件齐全;citations_todo.md中所有引用核验状态非空;AI披露段已写入正文;作者签字确认。
【范式转移】学完只会复用讲师那个示例→现场把整条科研生产线按”数据形态”翻译成你自己学科的版本:同一条SOP,跑出N个不同学科的论文。这一节不是”加餐”,而是验证你能否独立把课程方法迁移到下一个、下下一个课题。
1、学科映射四件套:把通用流水线翻译成”我的学科版”
数据形态映射:你的研究数据长什么样?时空遥感/临床随访/实验测量/调查问卷/模型输出/文本与日志/多模态影像
统计标准映射:你领域Reporting怎么写?effect size + 95% CI / OR +95% CI /β+ SE / Bayesian credible interval/Hazard Ratio
claim模式映射:你领域的claim粒度是什么?因果/相关/机理/关联/预测/探索性
目标期刊映射:你目标期刊偏好哪种结构?S/N broad significance/ IMRaD/CONSORT-style/工程基准+消融/注册报告
2、迁移实操:用自己学科的CLAUDE.md模板搭建my-paper/+跑通最小闭环
把学科特化的CLAUDE.md放进my-paper/,写入研究问题/数据约束/方法学习惯/目标期刊
跑通”一段数据→一张图→一个claim→Codex审一轮”最小闭环
产出:my-paper/自己领域版项目骨 + fig + claim + review_round_1.md
3、迁移难点集中答疑(20min)
数据合规:未发表/临床/涉密/企业合作数据怎么本地化跑
统计习惯:自己领域常用统计与课程示例的差异怎么改prompt
期刊政策:目标期刊的AI披露要求怎么写进ai_disclosure.md
产出:自己领域版CLAUDE.md模板+ my-paper/项目骨架+端到端样例+持续路径清单
验收标准:
学员的CLAUDE.md包含自己学科的报告标准/数据合规边界/目标期刊政策三项
端到端样例已跑通:data→figure→claim→review_round_1.md完整链路
结课前能给出”下周我把这条流水线推到[具体课题]的第一步动作”
能用自己的话回答:”这套流水线最难迁移的一环是哪一环?我打算怎么解决?”
【课前准备】课前请准备一份小样本数据(CSV/Excel/JSON均可,建议 ≤ 100行示例);

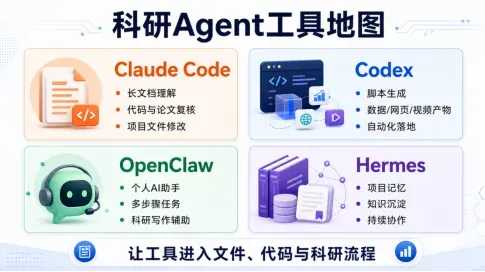
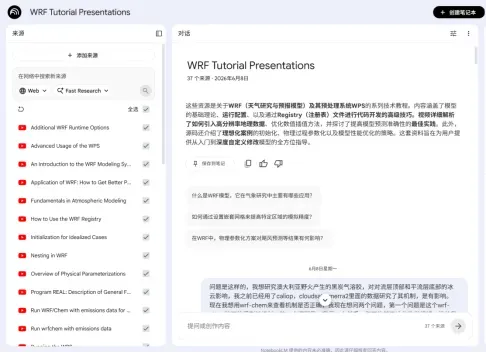
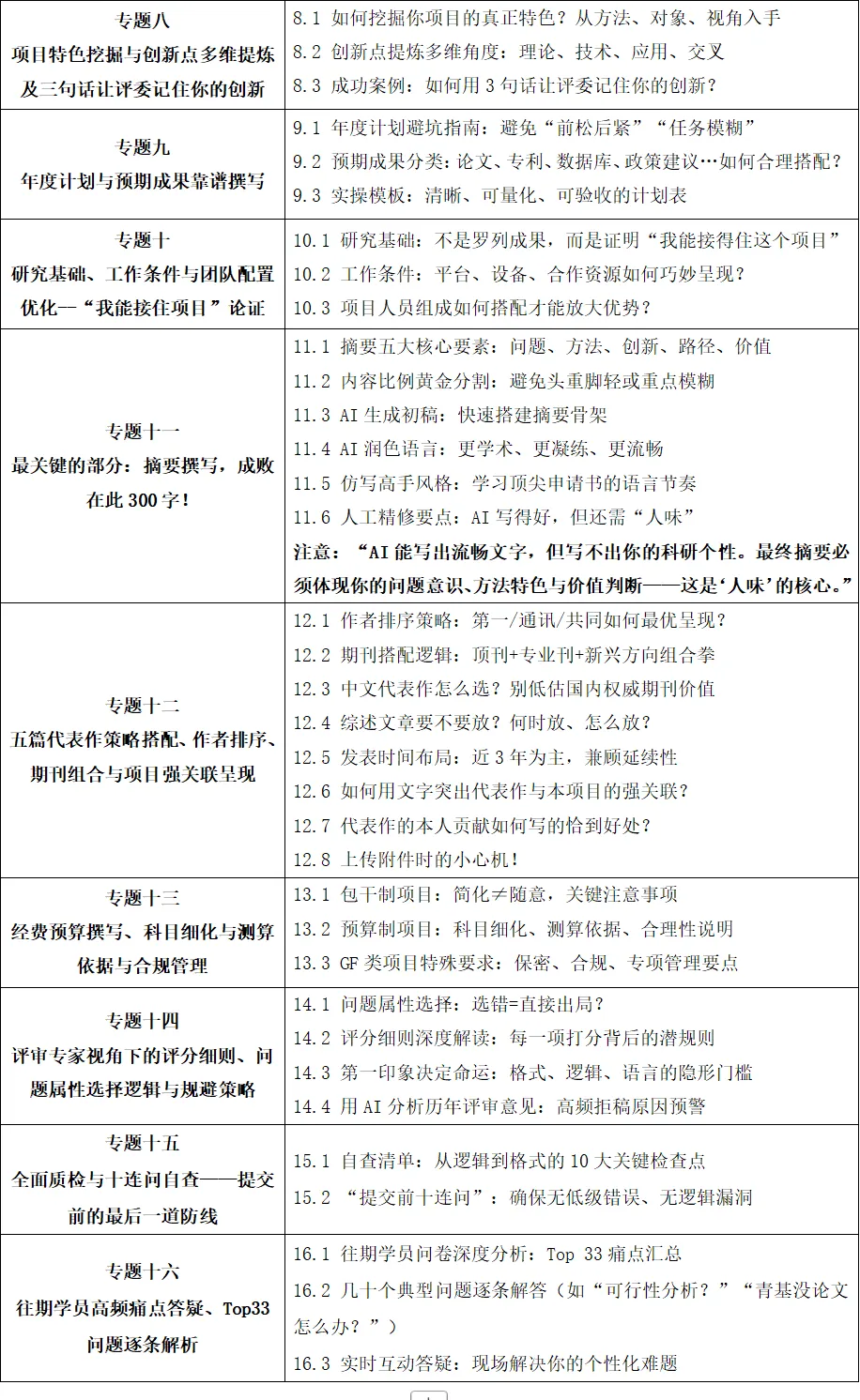
第一章 LLM与Agent(Claude Code、Codex、OpenClaw、Hermes)、NotebookLM的能力边界与科研场景选型策略
真正理解不同LLM与知识增强型AI(NotebookLM)的能力边界,学会在科研和高端工作中“因任务选模型,因资料选工具”
核心内容:
1.主流大模型能力拆解
ChatGPT(科研写作、逻辑推理、通用科研助理)
Claude(长文档处理、论文润色、风格一致性)
Gemini/Nano Banana(多模态、图像/视频/API调用)
DeepSeek(数学推理、代码、开源与本地部署)
2.科研工具型Agent快速对比与轻量使用
Claude Code:代码、文档、项目文件与论文材料修改
Codex:代码生成、网页/数据/视频工程化产物生成
OpenClaw:个人AI助手、多步骤任务编排与科研写作辅助
Hermes:研究、写作和项目任务中的记忆化助手与技能化封装入口
通用LLM vs 工具型Agent:一个更擅长回答和构思,一个更擅长进入文件、代码和流程
本章讲工具入口、适合场景和上手方式。
3.NotebookLM:以“你的资料”为核心的科研AI
NotebookLM的设计理念:
不是生成答案,而是“基于你提供的材料进行推理”
NotebookLM与通用LLM的本质区别
为什么NotebookLM特别适合科研与严肃写作
所有结论可溯源
自动标注引用来源
避免“无根据幻觉”
典型科研使用场景
多篇论文联合分析
项目材料/课题资料整合
论文写作中的“证据驱动型推理”
4.大模型“智能”从何而来
Transformer的直观理解
Token、上下文窗口、推理链
为什么通用LLM会“幻觉”,而NotebookLM更“克制”
Prompt提示词的使用和收藏(通过LLM举一反三生成Prompt提示词)
5.科研与工作的模型选型策略
写论文vs想IDEA
画图vs数据分析
自由发散型思考(ChatGPT/Claude)vs基于资料的严谨推理(NotebookLM)
什么时候该“问模型”,什么时候该“喂资料”
案例1:
1)同一篇论文IDEA,分别使用:
ChatGPT(自由生成摘要)
Claude(润色与结构优化)
DeepSeek、Qwen(方法与数学逻辑)
NotebookLM(基于真实文献生成可溯源摘要)
2)对比:
逻辑严谨性
创新点来源
引用可信度
幻觉风险差异
结课成果
一份《科研任务×大模型×NotebookLM选型指南》
3)明确你的科研工作中:
谁负责“想”
谁负责“写”
谁负责“证据与可信推理”

第二章 LLM+Excel科研数据分析、洗浄与统计结果自动解读实战
用自然语言“操控”Excel,让Excel成为科研数据分析助手
核心内容:
1.LLM自动生成复杂公式
2.科研数据清洗与异常检测
3.统计结果自动解读与文字化
4.Excel→论文结果段落自动生成
5.生成python语言绘图excel相关数据
6.LLM分析数据质量是否能用于科研
案例2:
1)上传实验数据→LLM自动完成:
统计分析
图表生成思路
2)结课成果:
一套「Excel+LLM数据分析模板」
通过大语言模型生成数据统计图

第三章 LLM × Python科研计算自动化与数据分析、机器学习与科研级可视化
让不会写代码的人,也能把Python变成科研生产力
让会写代码的人,用LLM进入10×效率区间
核心内容:
1.Python是科研的“发动机”,LLM是科研的“驾驶系统”
你只负责:提出研究问题,判断结果是否合理
AI负责:写代码,改代码,查Bug,重构流程,核心内容
2.科研人员应该如何“正确使用Python”
3.为什么Excel只能解决30%的科研数据问题
4.哪些科研任务必须用Python
大规模数据
重复实验分析
复杂统计与建模(如何使用机器学习方法处理数据,包括分类和回归方向)
5.Python在科研中的真实定位:
不是“编程语言”,而是科研流程自动化工具
6.LLM自动生成科研级Python代码
7.结合Python编程,生成机器学习算法并处理高质量科研数据
包括:
1)用科研语言描述问题→自动生成:
数据读取、清洗、统计分析、可视化
从「实验设计描述」直接生成Python分析脚本
2)自动补全:
pandas
numpy
scipy
statsmodels
matplotlib/seaborn
案例3:
1)任务:上传一份真实实验数据(CSV/Excel)
2)系统自动完成:
LLM生成 Python分析脚本
自动完成统计分析
自动生成科研级图表
自动输出Results段落初稿
3)结课成果:
一个可复现Python脚本
一段可直接写进论文的结果描述
一张可直接用于论文的图(结合LLM生成可用于全球统计分布结果图)
第四章 Zotero+NotebookLM+LLM智能文献管理与证据驱动科研写作
从“存论文”升级为“以文献为证据核心的可推理科研系统”,让AI不再“凭空总结”,而是基于真实文献进行可溯源分析与写作
核心内容:
1.Zotero高效文献管理
批量PDF智能总结
Zotero的配置和安装
跨文献研究脉络分析
为论文写作提供引用建议
2.NotebookLM:文献级科研推理中枢
为什么NotebookLM是文献管理的“第二大脑”
所有分析基于你上传的PDF
每一个结论都可追溯到具体文献段落
NotebookLM的科研优势
自动跨文献对比观点
自动识别共识/分歧/演化路径
自动生成带引用标注的研究总结
与ChatGPT/Claude的根本差异

3.防止“AI文献幻觉”的系统方法
为什么“直接让 LLM 总结文献”是高风险行为
NotebookLM如何从机制上避免虚假引用
科研可信度的三层防线
原始PDF(事实层)
NotebookLM(推理层)
LLM(表达层)
案例4:
1)任务:导入20篇某研究领域核心论文
2)系统自动完成:
3)Zotero:文献分类与标注
4)NotebookLM 自动输出:
研究脉络(含引用出处)
主流方法对比表
当前研究空白(有证据支撑)
5)LLM(ChatGPT/Claude):
6)将分析结果转化为:
文献综述草稿
引言逻辑段
第五章 Overleaf + LLM全流程科研写作
把论文写作变成“流程”
核心内容:
1.Latex语言的应用
2.Overleaf科研写作规范
3.LLM生成论文结构
4.分章节生成论文初稿
5.Open AI Prism如何助力科研写作
案例5:
如何通过Open AI Prism实现全流程写作,快速处理数学公式,论文引用,如何通过GPT5.5大模型的多模态功能,将手写公式直接导入论文,避免复杂公式的时间消耗。


第六章 一张图胜千言——从论文示意图到学术汇报 Video
1.科研图像的设计逻辑
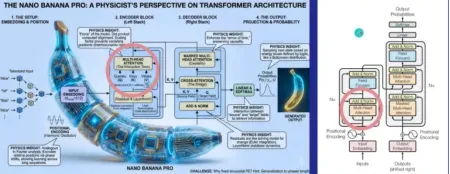
2.API调用Gemini/Nano Banana
3.如何通过Gemini/Nano Banana和NotebookLM生成系列的PPT和信息概念图,科研机制图。
4.如何通过Google Slide结合Nano banana处理AI生成科研图细节错误
5.当前Nature期刊表达AI生成的图不能放入论文中,我们有什么办法处理这个问题(通过Adobe Illustrate工具)
6.利用NotebookLM生成学术汇报级Video和音频文件
7.批量处理视频网页,结合Gemini的多模态系统,学习网上优质视频,自我成长
案例6:
1)Codex生成3D科研、教学图片
输入论文方法描述→自动生成:
通过Prompt提示词优化Nature和Science原图
批量生产高质量科研示意图
汇报用动画视频
2)结课成果:
一套论文插图+汇报Video
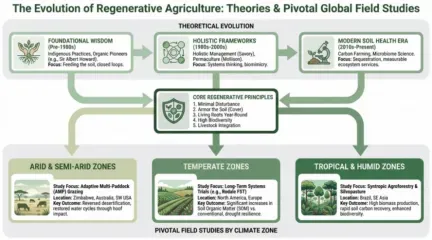
NotebookLM能根据相同的内容,不同提示词设计风格和颜色产生不同的概念图(下面两图为相同内容不同设计分割和颜色)
第七章 Odysseus+Ollama本地LLM部署、私有科研Agent构建与个人知识库搭建
保护科研IDEA,构建专属AI助手
核心内容:
1.Ollama部署LLAMA/DeepSeek
2.本地模型性能优化
3.RAG构建个人知识库
4.微调vs RAG的选择策略
5.Open WenUI本地部署,
6.如何结合Zotero和Open WenUI搭建本地知识系统
7.在本地环境里构建类似NotebookLM的科研生态系统(不需要科学上网,就能运行)
8.Odysseus本地ChatGPT工作台安装与配置:账号、模型端点、默认模型与浏览器访问
9.如何结合Zotero、PDF文献和Odysseus搭建本地知识系统
案例7:
1)本地部署DeepSeek→构建:
专属科研问答系统
私有文献分析Agent
2)结课成果:
一个私有科研AI Agent
第八章 多模型”圆桌会议”机制设计与AI创新科研头脑风暴
用AI进行真正的科研头脑风暴
核心内容:
1.多LLM分工机制
2.批判型/创新型Agent设计
3.自动迭代研究方案
4.模型的能力越强,Idea的创意更好
案例8:
1)ChatGPT+Claude→自动进行多轮讨论,生成创新研究方向。
2)结课成果:
一份「可投稿级研究IDEA说明书」
第九章 N8N × LLM 构建高效科研自动化与智能化工作流
实现“科研自动化”
核心内容:
1.N8N基础与部署
2.多软件自动联动
3.多模型优势整合
4.全流程科研自动化设计
5.整合Google工作系统流
案例9:
1)构建一个完整系统:
2)通过DeepSeek创建全自动科研文献搜索总结系统
3)结课成果:
一套可长期使用的科研文献搜索总结自动化系统
第十章 Open Claw与Agent Skill进阶:构建自主式写作智能体
实现自助式写作智能体
核心内容:
1.Open Claw核心机制
2.Claude Code的使用
3.Agent Skill技能封装
4.本地化环境搭建
5.写作指南 (Writing Guide) 建立
案例10:
1)构建自助式写作智能体
2)任务描述:根据相关数据和论文,由Agent Skill的智能体自动撰写一份科研文章。
3)结课成果:
自动化流水线:无需人工干预,系统自动运行。
高价值摘要:可结合知识库一起使用
论文稿件:根据数据生成文章,同时使用斯坦福的paper review Agent模仿审稿人提出意见,自动修改论文。

第十一章 Seedance 2.0×Codex/HyperFrames视频生产与代码化科普视频自动化制作流程
科研科普视频的“内容结构模板”
核心内容:
1.Seedance 2.0的“科研视频可控生成”关键概念
2.用 Seedance 2.0自动化生成科研科普视频:标准工作流
案例11:
1)输入:一篇论文(PDF)或一段科研报告
2)输出:一个60–90秒的竖屏科普视频(9:16),包含:
讲解员(可选)、机制动画
结果对比图、字幕 + 配音
3)实操流程:
资料准备:论文PDF+你自己写的5行要点(可选)
NotebookLM:提取“核心机制、方法、结果、限制”(可溯源)
LLM:把提取内容转成“8镜头分镜表 + 旁白稿”
Seedance 2.0:按分镜逐镜生成(每镜5秒)
Codex/HyperFrames代码化生成科研视频:标准工作流
Codex:根据论文内容自动生成脚本、分镜、字幕、旁白稿和素材清单
HyperFrames:将分镜写成HTML/GSAP时间线,自动完成排版检查、关键帧抽检与MP4渲染
Seedance + Codex/HyperFrames双路径:Seedance负责视觉镜头生成,Codex/HyperFrames负责可控剪辑、字幕、配音、转场与工程化复用
案例12:
1)输入论文PDF或项目汇报材料→自动生成60–90秒科研科普视频源工程和MP4成片
2)结课成果:
Codex/HyperFrames科研视频自动化模板


【教学特色】:



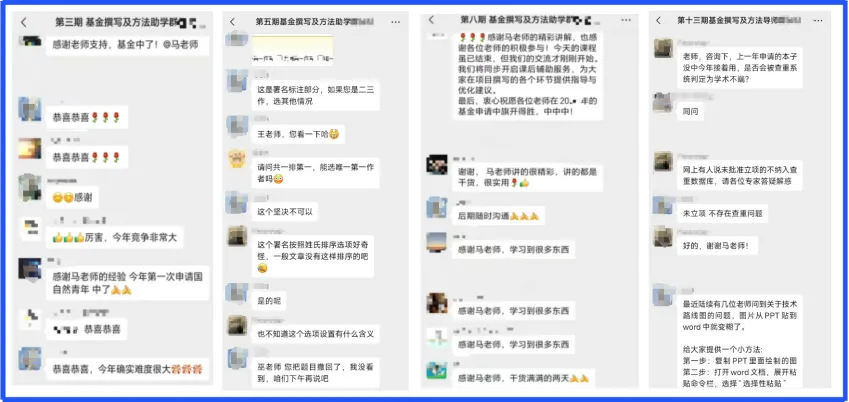
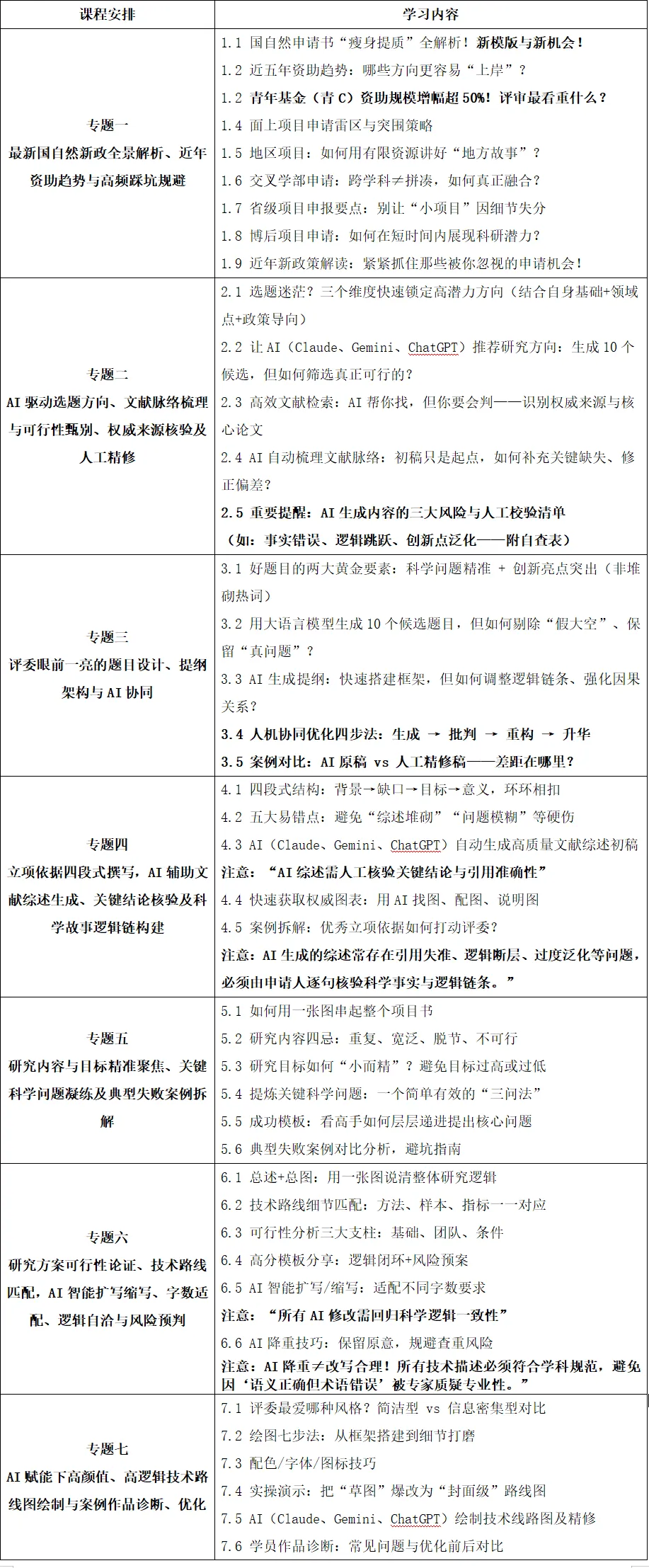
【往期答疑与好评】:

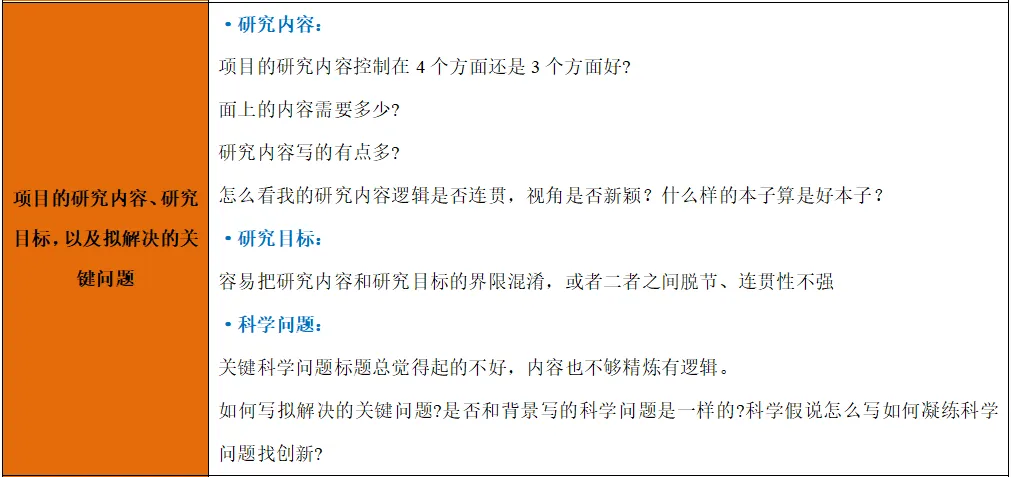


【培训方式】:网络直播+助学群辅助+导师面对面实践工作交流(报名后加入助学群、查阅会议流程)
【导师随行】:
1、建立导师助学交流群,长期进行答疑及经验分享,辅助学习及应用。
2、课程结束后不定期召开线上答疑交流,辅助学习巩固工作实践问题处理交流




END
Ai尚研修丨专注科研领域
技术推广,人才招聘推荐,科研活动服务
科研技术云导师,Easy Scientific Research