 夜雨聆风
夜雨聆风





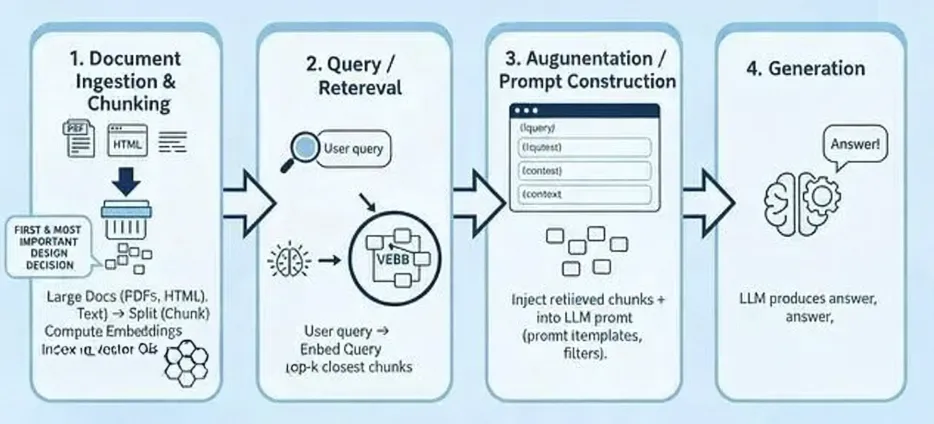
RAG知识库实战:让AI读懂你的内部文档
装好跑了一周。内部政策问题牛头不对马嘴,项目文档说找不到。
第一反应是PDF没识别好。加了两天OCR,没改善。
💡根子不在PDF,在整个pipeline——从切分到检索排序,每个环节都有窟窿。
以下是两个月里我实际做的事、测的数据、踩的坑。
────────────────────
PDF转了Markdown,手动修了一天
500页PDF,按规范文档结构有标题、表格、代码块、条款编号。
先用工具转Markdown。出来的东西:表格对不上,代码块截断,有些标题混进正文。不是转一下就能用的。
手动修:每条标题对一遍层级,表格补上缺失列,截断的代码块翻PDF原文重截。搞了一天。
这一步没捷径。后面检索质量全靠文档预处理。预处理脏,后面怎么调都没用。
────────────────────
怎么切文档——我测了五种
试试固定长度。512字符一刀。有结构的文档切完每一块前半段是上一段的尾巴,后半段是下一段的头。拿这种块去检索,搜出来的东西前言不搭后语。
然后试递归——段落切完再句子再字符。文字干净的时候还行。碰到标题断在两个块中间、表的行被劈半,检索出来的东西还是对不上。
|
切分方式 |
怎么切的 |
出了什么问题 |
|
固定长度 |
512字符一刀 |
概念的边界被切烂,查出来的块答非所问 |
|
递归 |
段落→句子→字符逐级 |
层级识别不准时,整个文档结构都塌 |
|
结构化 |
按标题/章节/条款边界 |
文档里写的层级不统一,切出来的块大小差太多 |
|
语义 |
句子相似度低于阈值就切 |
慢,且没比固定长度好多少 |
|
父子 |
大块包小块,小块搜大块回 |
多了一套映射关系要维护 |
最后用的结构化+父子。
按章节边界切父块,800-1000字一个。每个父块下面切成子块,200-300字。
搜的时候搜子块,返回带父块。
────────────────────
嵌入模型–三个跑了一轮实测
不写概念。直接说数据。
同一个测试集,三组模型的结果:
|
模型 |
通用文档查准率 |
这500页规范文档的查准率 |
|
通用模型 |
70-80% |
40-50% |
|
BGE-M3 |
75-85% |
60-70% |
|
我自己标的领域数据+SFT |
80-85% |
75-85% |
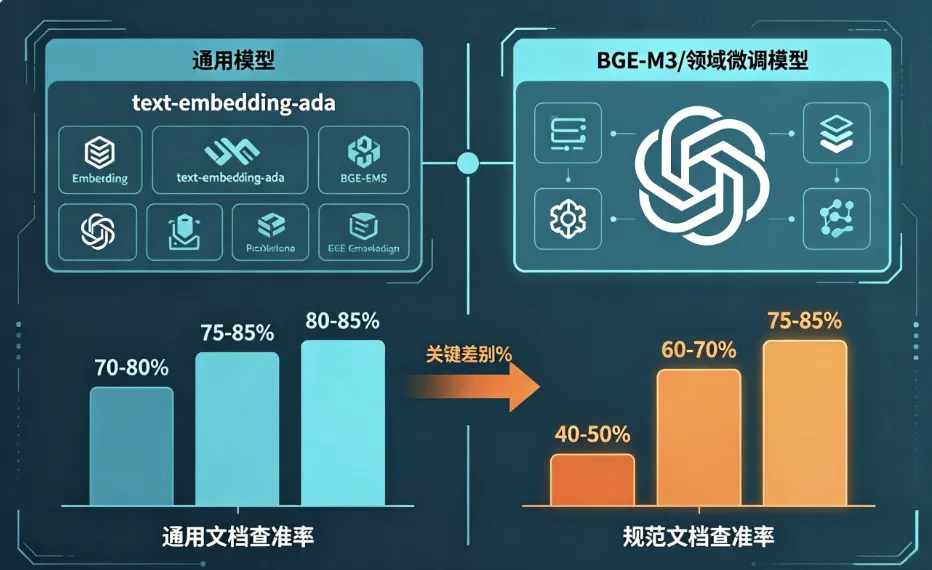
这个项目用的BGE-M3。
微调那次是另一个项目。标了七天数据,规范化技术条款+表格+公式那种专业文本。检索准确率从60-70%拉到75-85%,提升很明显。但这个项目没上,时间不够。
────────────────────
检索的几个参数–跑配置跑出来的
top_k、相似度阈值、重排。每个都改了多次。
|
参数 |
我设的值 |
怎么定的 |
|
top_k |
6 |
设3查不全,设8噪音太多,6刚好 |
|
相似度阈值 |
0.65 |
低于0.6假结果太多,高于0.7有不少漏检 |
|
重排 |
BGE Reranker V2 |
开了之后查准率提了一大截 |
────────────────────
四种配置跑完的数据
同一批测试问题,四种配置跑出来的命中率和噪音:
|
配置 |
命中率 |
噪音率 |
|
固定长度+通用模型+没开重排 |
55% |
40% |
|
结构化分块+通用模型+开重排 |
70% |
20% |
|
结构化分块+BGE-M3+开重排 |
88% |
12% |
|
父子分块+BGE-M3+开重排 |
92% |
8% |

向量库用的Milvus。
────────────────────
翻车三次
💡第一次:忘了加重排。跑一周感觉不对,回头查——重排没开。加上当场命中率涨十几个点。
第二次是更新知识库的时候没删旧chunk。新版本文档上传了,旧版本的向量数据还躺在库里。用户搜同一个问题,新旧内容混在一起返回——旧答案有些已经被新规范废止了。
从那以后每次更新文档的步骤固定成:删旧chunk → 重新嵌入 → 重新索引。顺序不能错。
第三次是PDF里的表格。规范文档里有几十张技术参数表。工具转Markdown的时候把多列并成了一列,表头丢了。检查的时候没发现,上线之后有用户搜参数搜出牛头不对马嘴的数据。后来每一张表单独检查一遍——花了大半天。
────────────────────
四种场景,我实际用过的配置
不是推荐,是我在不同项目里搭过的。
客户团队FAQ不到1000条那个,全是一问一答。FAQ自己结构就够均匀了,固定长度512切出来块都差不多。通用嵌入够用,没上BGE-M3。top_k设5,返回五条用户自己翻。跑了一个月没人说搜不到东西,就没再调。
500页规范文档,结构化分块+父子索引+BGE-M3+重排。前面四轮配置跑分就是它。上线后用户搜政策条款,首条命中。偶尔搜不到的是那种跨章节引用的内容——A章引了B章某条款,分块的时候A和B不在同一个父块里。后面对这部分单独补了交叉引用索引。
多部门共享知识库那次,三个部门,文档结构完全不一样。
产品部是需求文档,技术部是API文档,运维是故障手册。
先按部门拆——每个部门建一个向量库。检索的时候先判断这问题更像哪个部门的,再去对应库里搜。混在一起搜过一轮,产品的问题搜出技术文档来,查准率掉了十几个点。
技术文档混代码的,一个开发团队的项目。切之前先扫一遍,把所有代码块的位置标出来。切的时候代码块不跨边界。不然检索返回一段代码头从上一块、尾漏到下一块,没法看。标完之后每个块返回的代码都是完整的。