 夜雨聆风
夜雨聆风





一个把任意文档转成干净 Markdown 的桌面工具,专门省大模型的 Token
MDFlux 是一个 Windows 桌面应用,能将 PDF、Office 文档、扫描件等各类文件转换为结构清晰的 AI-ready Markdown 格式,内置 OCR、批量处理和可选清理功能,比用视觉模型喂图节省约 2 到 6 倍的 token。
它不依赖命令行,下载解压就能跑。首次启动会自动配好本地 Python 环境,之后全程离线。你要做的就是拖一个文件或一个文件夹进去,点一下转换,它就会输出干净的 Markdown——标题还是标题,表格还在表格里。
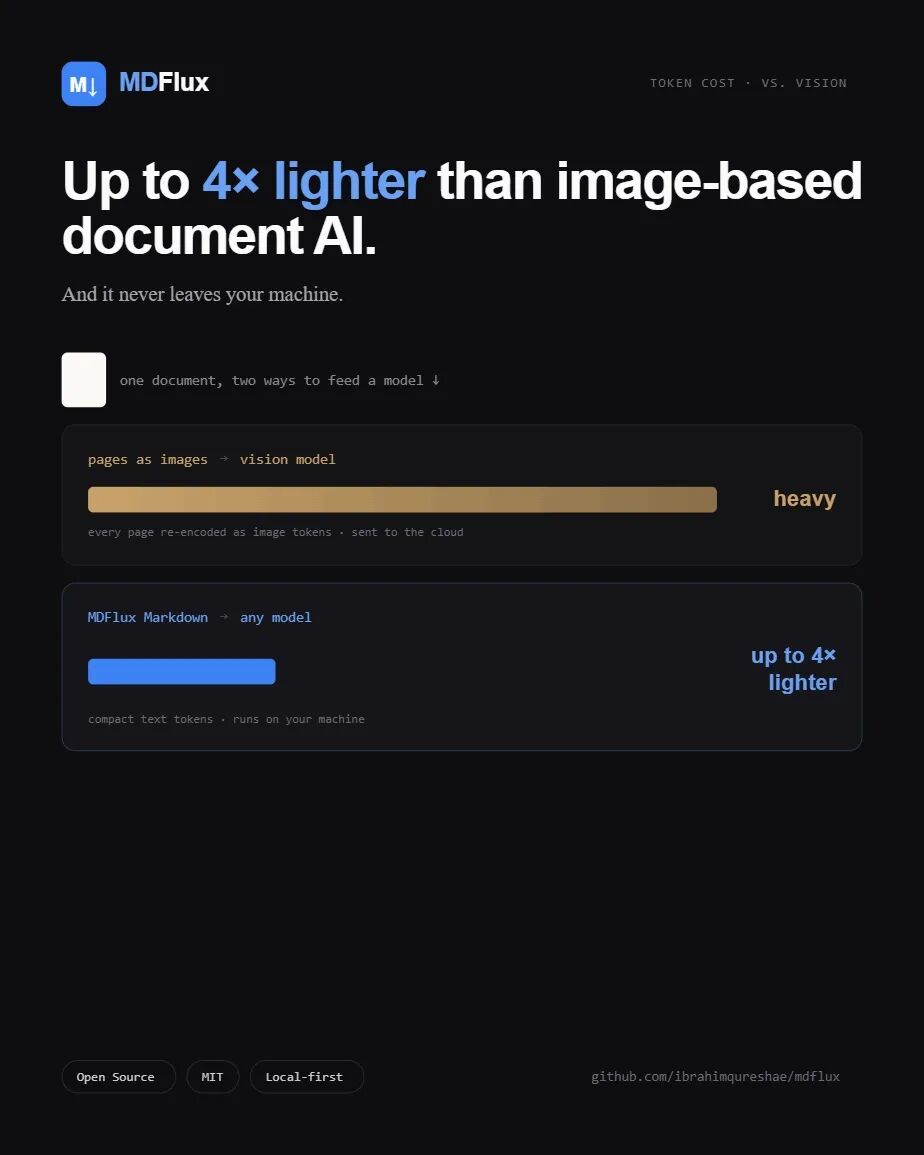
最拿得出手的是 token 开销。
现在很多人喂文档给 LLM 的方式是把页面截成图片丢给视觉模型。图片的 token 成本是固定的,不管页面上只有三行字还是三百行,视觉模型都得按一整页图像来算。MDFlux 走的是纯文本路线,输出的是结构化的 Markdown,没有图像数据,没有 base64 的冗余,token 量直接降下来。
根据项目给出的一组实测对比:
-
普通文档,MDFlux 输出的 Markdown 大约是视觉模型方案的四分之一 -
扫描件差距更大,同一个文件视觉模型用了 10,731 token,MDFlux 用了 1,893,省了大概 5.7 倍
而且这个节省不是一次性的。你每一次让 LLM 读这个文档都在省钱,如果是批量处理或者搭建 RAG 流水线,省下来的 token 会叠加。
扫描件这块值得单独说。
很多办公场景里,PDF 其实是图片叠出来的。普通提取器面对这种文件直接哑火,返回零个可用字符。视觉模型倒是能读,但你得把整页当图发出去,隐私先放一边,成本也不低。
MDFlux 内置了 OCR 能力,能把那些”空白”页面里的文字重新读出来。而且如上面那组数字所示,就算加了 OCR 这一层,最终输出的 token 量仍然比视觉模型低得多。
隐私是它默认就做好的事。
所有转换过程都在本地完成,不需要 API Key,不需要注册账号,文件不会离开你的机器。可选的 AI 清理模式也支持调用本地模型,不是非要把数据送到云端。
项目底层用的是微软开源的 MarkItDown 转换库。MDFlux 没有另起炉灶,而是在这个引擎外面加上了一整套让普通人能用的东西:OCR、桌面界面、批量转文件夹、进度条和取消按钮、诊断面板、多级清理模式。
用过 MarkItDown 命令行的人应该能理解,前面这些补齐的东西才是日常真正需要的。
支持的格式:PDF(含扫描件)、DOCX、PPTX、XLSX、EPUB、HTML、CSV、JSON、XML、图片和音频文件都能转。批量处理文件夹时,每个文件的转换状态和诊断信息都会显示出来。

项目由开发者 ibrahimqureshae 用 Tauri 2 加 Rust 构建,目前只有 Windows 版本,macOS 在路线图上,MIT 协议开源。
项目地址:https://github.com/ibrahimqureshae/mdflux