 夜雨聆风
夜雨聆风





当我用AI三天开发出一个数据资产管理平台,我开始思考:整个软件产业的规则,是不是该重写了?
用三天时间,借助AI工具,独立开发了一个完整的企业级数据资产管理平台。
这不是什么概念验证,也不是简单的Demo。它包含数据血缘追踪、元数据管理、资产目录、权限控制——这些原本需要一个成熟团队耗费数月才能交付的功能
(文章末尾有部分过程版截图展示)
当我向一位在软件行业摸爬滚打多年的老友展示这个成果时,他的表情从惊讶到困惑,最后定格在一种复杂的沉默。
“这不可能。”他说。
但它是真的。
这个”不可能”的实验,让我开始思考一个更深层的问题:当AI让个体的开发能力趋近于一个团队,当传统的技术门槛被迅速拉平,整个软件产业的底层逻辑,是不是正在发生根本性的改变?
一、冲击波第一重:能力平权,个体与团队的边界正在消失
让我们坦诚一点。
在AI出现之前,软件开发是一个高度依赖”人月神话”的行业。
一个产品的背后,往往是数十人乃至数百人的协作:产品经理画原型、架构师做设计、前端写界面、后端写逻辑、测试找Bug、运维管部署。每一个环节都需要特定的技能,每一个角色都需要时间的积累。
这套体系的底层假设是:高质量软件的产出,必然与投入的人力成正比。
但现在,这个假设正在被打破。
AI的能力不是”辅助”,而是”替代”——替代的是那些原本需要数年积累才能掌握的中阶技能。
举个例子:在过去,要独立开发一个数据资产管理平台的后端,你需要精通数据库设计、熟悉RESTful API开发、了解鉴权机制、掌握缓存策略……每一个环节都可能卡住一个初学者数月之久。
但现在,AI可以在几秒钟内生成可运行的代码框架,在几分钟内完成一个模块的初版实现。它不需要休息,不会疲惫,不会抱怨需求变更。
这不是”工具提升了效率”,这是”生产要素的重新定义”。
当个体借助AI可以产出原本需要一个团队才能交付的成果时,软件公司的人力成本结构、项目估算模型、甚至组织架构,都将面临根本性的冲击。
那些依赖”堆人头”来赢得项目的外包公司,那些以”规模大、人员多”为核心竞争力的传统软件企业,将最先感受到寒意。
因为AI带来的不是局部优化,而是范式转移。
二、冲击波第二重:知识产权的困局——AI生成的代码,归谁所有?
如果说能力平权带来的是产业结构的冲击,那么接下来这个问题,则可能触及法律体系的根基。
用AI生成的代码,版权归谁?
这个问题看似简单,实则牵扯出了一系列复杂的法律困境。
困境一:著作权法意义上的”作者”是谁?
传统的著作权法建立在”人类创作”的前提之上。一部作品的版权归属于创作它的人。
但当AI成为实际的”创作者”时,这个逻辑链条就断裂了。
如果AI生成的代码具有足够的原创性,那么著作权应该归属于:
-
开发AI模型的公司? -
提供训练数据的公司? -
输入提示词、发起生成请求的用户? -
还是……没有人拥有版权,因为它属于”机器的产物”?
各国的司法实践正在给出不同的答案。美国版权局明确表示,完全由AI生成的作品不受版权保护;而中国和英国的判例则倾向于认为,人类在AI生成过程中的”选择和安排”可以构成独创性表达。
但这个”选择和安排”的边界在哪里?提示词的编写算不算?后期的人工修改算不算?如果是,多少程度的干预才算”足够”?
法律的天平正在摇摆,而产业的车轮不会停下等待。
困境二:专利保护的”三性”标准如何适用?
如果说著作权的问题是”归谁所有”,那么专利的问题则是”能不能保护”。
专利法要求发明必须具备新颖性、创造性和实用性才能获得保护。
但当AI成为发明的主体时,这套标准面临着严峻的挑战:
新颖性判断: 如果AI是在学习了海量现有技术之后生成的方案,它是否真的”前所未有”?还是说它只是对已有知识的重新组合?
创造性判断: 专利法通常以”本领域普通技术人员”作为创造性判断的基准。但如果AI的能力远超”普通技术人员”,这个基准是否还成立?
更根本的问题: 如果一项发明的核心构思来自于AI的”涌现”能力,而非人类发明者的逻辑思维,这项发明还能否被视为专利法意义上的”发明创造”?
这些问题没有标准答案。全球的专利局、法院和立法机构正在艰难地摸索。
但有一点是确定的:在答案明晰之前,企业和个人都将在法律的灰色地带中前行。
困境三:开源协议与商业利益的冲突
除了上述法律层面的困境,AI生成代码还带来了一个更实际的问题:开源生态的协议冲突。
许多AI模型在训练时使用了大量的开源代码作为语料。这些代码往往附带各种开源协议——GPL、MIT、Apache……
当AI生成的代码与训练数据中的某些代码片段相似时,这是否构成了对原代码的”衍生”?如果是,生成代码的使用者是否需要遵守原代码的开源协议?
举个例子:如果AI生成的代码中包含了一段与GPL协议下某个函数库逻辑相似的实现,那么使用这段生成代码的商业软件,是否也必须按照GPL协议开源其全部代码?
这个问题目前还没有明确的司法判例。但可以预见的是,随着AI生成代码在商业项目中的广泛应用,围绕开源协议的争议和诉讼将不可避免地增多。
知识产权的困局,本质上是技术变革速度超越了法律演进速度的一个缩影。
在这个过渡时期,企业和个人能做的,或许只有在充分理解风险的前提下,谨慎前行。
三、冲击波第三重:产业重构——传统软件厂商的护城河在哪里?
当我们把目光从法律层面拉回到产业层面,一个更宏观的问题浮现出来:
当AI让软件开发的能力门槛大幅降低,传统软件厂商的核心竞争力——护城河——在哪里?
这是一个关乎生死存亡的问题。
回顾软件产业的发展史,企业的护城河大致可以归纳为以下几种:
- 技术壁垒:
拥有他人难以复制的核心技术或专利。 - 规模优势:
庞大的客户基础、成熟的产品线和完善的生态。 - 品牌信任:
多年积累的市场口碑和客户忠诚度。 - 网络效应:
产品价值随用户数量增加而指数级增长。 - 转换成本:
客户一旦使用,迁移到竞品的代价极高。
但在AI时代,这些传统的护城河正在受到不同程度的侵蚀。
侵蚀一:技术壁垒的”平权化”
过去,掌握复杂算法、精通底层架构的工程师是企业最宝贵的资产。他们的知识积累和经验沉淀,构成了企业难以逾越的技术壁垒。
但现在,AI正在将这种个人经验转化为可规模化的能力。
一个中级工程师借助AI,可以在短时间内产出原本需要高级专家才能完成的代码。
这意味着什么?
意味着技术壁垒正在从”人的壁垒”转变为”工具的壁垒”。谁更好地掌握和运用AI工具,谁就能在技术上获得优势。
但对于大多数软件企业来说,AI工具是公开的、可购买的。当所有人都能获得类似的AI能力时,单纯依靠技术本身构建的护城河,其深度正在迅速变浅。
侵蚀二:规模优势的”重构”
传统观念认为,大公司在软件行业具有天然的规模优势。它们拥有更多的客户、更完善的产品线、更成熟的交付体系。
这种规模优势在很大程度上确实难以撼动——直到AI开始改变软件生产本身的成本结构。
在过去,开发一个新功能、维护一个老客户、拓展一个新市场,都需要相应的人力投入。规模的增长与成本的增加大致成正比。
但当AI可以替代大量的人力工作时,规模经济的逻辑开始发生变化。
小团队借助AI,可能以极低的边际成本提供原本只有大公司才能交付的产品和服务。
这不是说大公司会消失——它们的客户基础、品牌认知、行业经验仍然是巨大的资产。
但规模优势的”护城河”深度确实在被削弱。大公司需要重新思考,如何在AI时代重新定义和构建自己的竞争优势。
侵蚀三:客户关系的”再定义”
长期以来,软件企业与客户之间的关系,很大程度上建立在”服务提供方”与”服务购买方”的二元结构之上。
企业卖软件、卖服务、卖解决方案;客户买单、使用、(有时)抱怨。
但AI正在模糊这种边界。
当客户自己也拥有强大的AI能力时,他们对软件企业的期望会发生根本性的改变。
他们不再满足于购买一个”成品”,而是希望获得可组合、可定制、可持续演进的能力。
他们不再仅仅需要”技术支持”,而是需要共创伙伴——能够理解他们业务、与他们一起用AI解决问题的合作者。
这对软件企业意味着什么?
意味着单纯的”交付能力”正在贬值,而”共创能力”正在升值。
那些能够快速理解客户业务、灵活组合AI能力、与客户一起迭代创新的企业,将在新的竞争格局中占据优势。
而那些仍然固守”我开发、你使用”传统模式的企业,可能会发现自己的客户正在流失到更灵活、更懂AI的竞争对手那里。
护城河的转移:从”技术”到”洞察”,从”交付”到”共创”
综合以上分析,我们可以看到一个清晰的趋势:
AI时代,软件企业传统的护城河——技术壁垒、规模优势、客户关系——正在发生深刻的转移。
新的护城河正在围绕以下几个核心能力构建:
- 深度业务洞察:
真正理解客户所在行业的痛点、规律和趋势,成为客户不可或缺的”业务伙伴”,而不仅仅是”技术供应商”。 - AI原生能力:
不仅会用AI工具,更要能构建AI驱动的产品和流程,让AI成为企业DNA的一部分,而不仅仅是效率工具。 - 敏捷创新文化:
建立快速试错、持续迭代、拥抱变化的组织能力,在AI加速的时代保持进化的速度。 - 生态构建能力:
不仅卖产品,更要构建平台、连接伙伴、培育生态,形成网络效应,让客户、伙伴和自己共同生长。
这些新的护城河,不再仅仅依赖技术本身,而是更多地依赖于组织的能力、文化的深度、生态的广度。
对于传统软件企业来说,这意味着一场深刻的转型。
对于那些能够成功构建新护城河的企业,AI时代将是一个巨大的机遇窗口。
而对于那些固守旧模式、无法适应新变化的企业,AI可能不是赋能的工具,而是颠覆的力量。
四、结语:在变革的十字路口,我们该如何前行?
写到这里,我想起开头提到的那个”疯狂实验”。
三天时间,一个人,一个数据资产管理平台。
这个实验的结果,让我既兴奋又忐忑。
兴奋的是,AI赋予了个体前所未有的创造能力。一个普通开发者,借助AI,可以触及曾经只有大型团队才能触及的高度。
这是技术的民主化,是创造力的解放。
忐忑的是,这种解放背后,是整个产业秩序的剧烈震荡。能力平权冲击着传统的组织形态,知识产权的困境拷问着法律体系的根基,产业重构的压力倒逼着每一家企业重新思考自己的生存之道。
这是变革的阵痛,是旧秩序瓦解、新秩序尚未成形的过渡期。
面对这样的时代,我们每个人、每家企业,都需要做出自己的选择。
对于个人而言, 拥抱AI不是选择,而是必须。但拥抱的方式很重要——不是把AI当成偷懒的工具,而是把它当成能力的放大器。学习如何与AI协作,如何让AI补充自己的短板、放大自己的长板,将成为未来职场最核心的竞争力。
对于企业而言, 转型的窗口期正在收窄。那些能够快速调整战略、重构组织能力、建立新护城河的企业,将在AI时代获得巨大的竞争优势。而那些固守旧模式、反应迟缓的企业,可能很快会发现,自己熟悉的游戏规则已经失效。
对于整个社会而言, 我们需要加速构建适应AI时代的制度框架。知识产权法律需要更新,教育体系需要改革,社会保障需要完善。技术发展的速度已经超越了制度演进的速度,这种错配带来的摩擦成本,需要全社会共同承担和化解。
站在2026年的春天,回望过去几年AI的狂飙突进,展望即将到来的更大变革,我有一个强烈的感受:
我们正处在一个历史性的转折点。
就像当年印刷术的发明打破了知识垄断、工业革命的到来重塑了社会结构一样,AI正在从根本上改变人类的生产方式和组织形态。
这个过程不会一帆风顺,必然会伴随着迷茫、焦虑、甚至是阵痛。但历史的车轮不会倒退,技术的进步不会停滞。
我们能做的,不是抗拒变革,而是主动拥抱它;不是被动等待,而是积极行动。
“当我发现自己一个人能抵一个团队的时候,我意识到,改变的不仅仅是我自己的工作方式,而是整个行业的游戏规则。”
这个游戏规则正在重写。
而每一个读到这里的你,都是这场变革的亲历者、参与者、塑造者。
未来已来,只是尚未均匀分布。
你,准备好了吗?
写在最后:
这篇文章源于一个真实的个人实验,也源于对AI时代产业变革的深度思考。如果你也有类似的思考或经历,欢迎在评论区分享。在这个快速变化的时代,我们或许更需要彼此的声音,来确认自己并不孤单。
你觉得,AI能力平权会给你的行业带来什么改变?
本文由微信公众号「数智时代先锋」原创发布
未经授权禁止转载
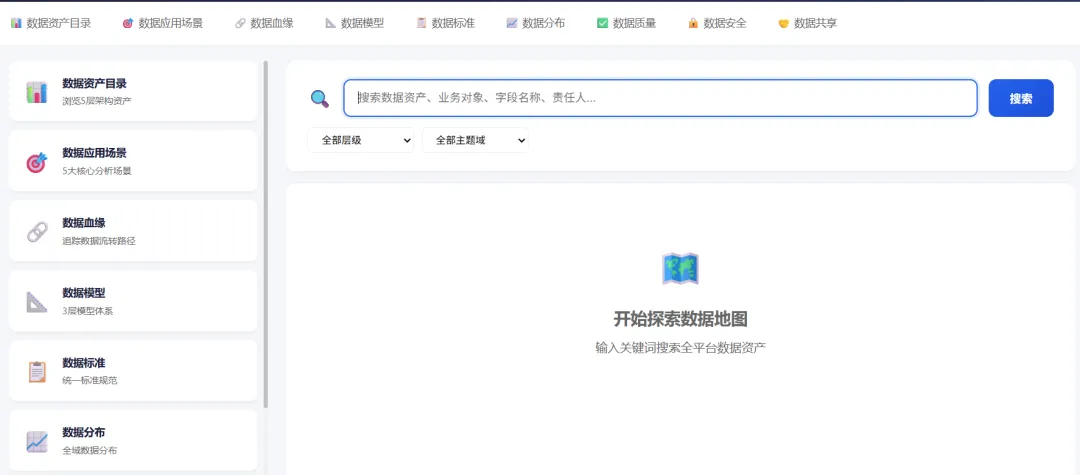
数据地图页:能实现真正搜索跳转
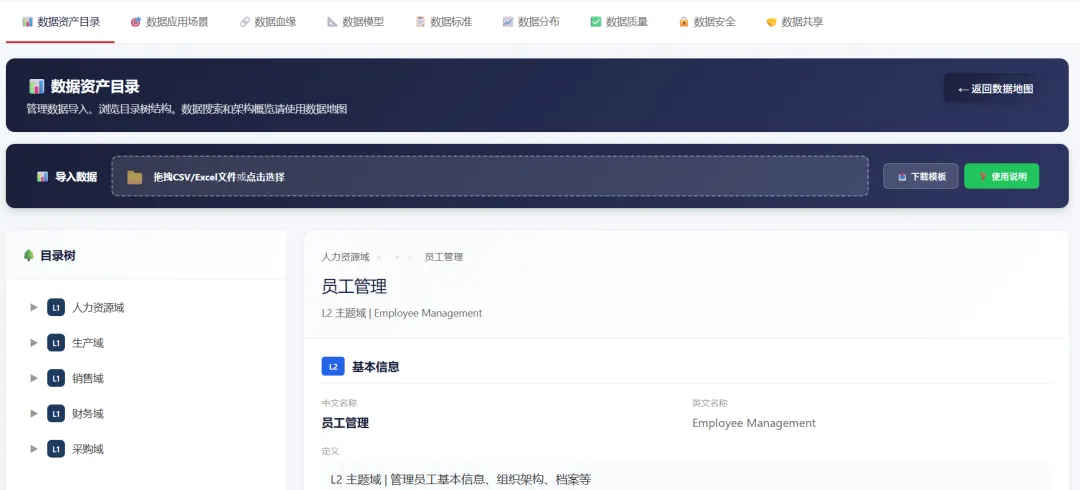
数据资产目录页:能实现目录树下钻,右侧点击查看属性,联动到源系统物理字段
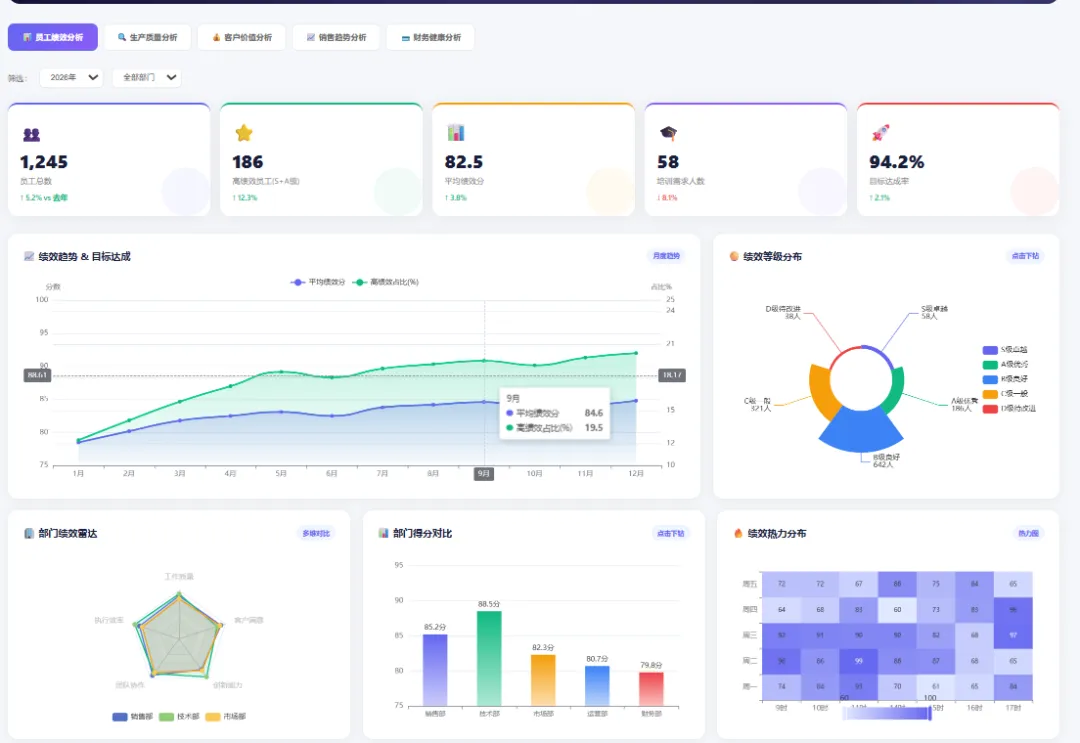
数据应用场景:数据可下钻
注:以上为本人与小龙虾实际交流自行开发,无商业意图,其他转载使用需经过本人同意。