 夜雨聆风
夜雨聆风





我研究了 20+ 个插件后,总结出 Obsidian 数据可视化的 4 种方法

很多人用Obsidian一段时间之后,都会遇到一个问题,笔记越来越多,但越来越难看到全局。
每天可能会记录很多内容:
-
每日日记
-
阅读记录
-
学习时间
-
运动数据
-
内容输出
-
… …
时间一长,几十篇、几百篇笔记散落在不同页面。你知道自己记录了很多东西,但很难回答一个简单的问题:
最近一个月,我到底发生了什么变化?
这是很多笔记系统都会遇到的瓶颈。信息越来越多,但洞察越来越少。而解决这个问题最有效的方法,其实只有一个:数据可视化。
当数据被画成趋势图、统计表、热力图的时候,很多变化会变得非常直观。作为一名数据分析师,我对这种事情几乎是本能敏感。所以在使用 Obsidian 的过程中,我几乎忍不住去研究各种表格统计或者可视化统计插件。
过去一年,我前后尝试过 20多个相关插件,做过很多不同的实验。最后慢慢发现一个事实:
Obsidian 的数据可视化,其实只需要理解 4种核心方式。
理解了这四种方式,你基本就掌握了 Obsidian 数据系统的核心逻辑。
第一种:Dataview —— 让笔记开始“结构化”
如果你刚开始探索数据可视化,第一个一定会遇到的插件就是 Dataview。很多人第一次用 Obsidian,记录的数据要么是直接记录在笔记主体内容中,像这样的:
今天体重 72kg今天阅读 30分钟今天写了一篇文章
这些信息都存在不同的笔记里。要么是学会通过obsidian的属性字段来记录相关数据,如:
rank: 28两种方式都是记录,但是都没有进行汇总,而 Dataview 做的事情,就是把这些零散信息整理出来。最后通过表格的形式展现出来:
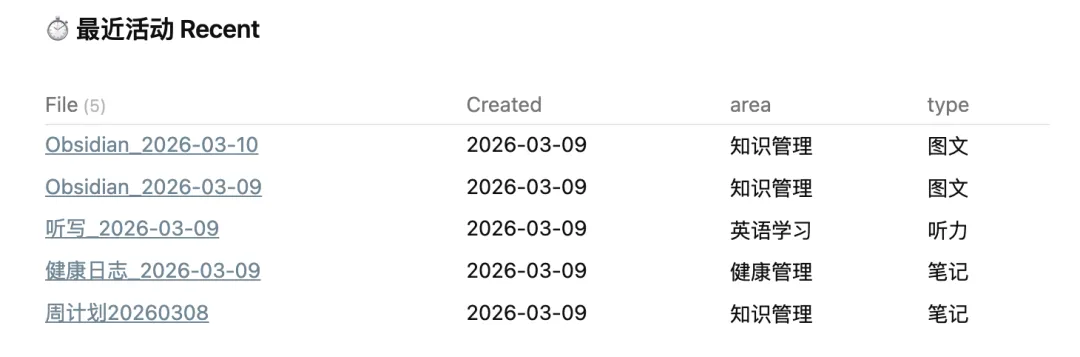
可以,按照你自己的标签或者维度,自动整理出来。
所以从系统角度来看:Dataview 并不是可视化工具,而是数据整理工具。 如果没有 Dataview,后面很多可视化其实也很难实现。
第二种:Tracker —— 最适合做趋势监控
当数据被整理出来之后,很多人下一步就会想做一件事情:看趋势。
例如:
-
体重是在下降还是上升
-
阅读时间有没有增加
-
写作频率是否稳定
这时候就轮到 Tracker 插件发挥作用了。
Tracker 可以把笔记中的数字,自动生成趋势图。比如每天记录:体重: 72
Tracker 就会自动生成一条体重变化曲线。
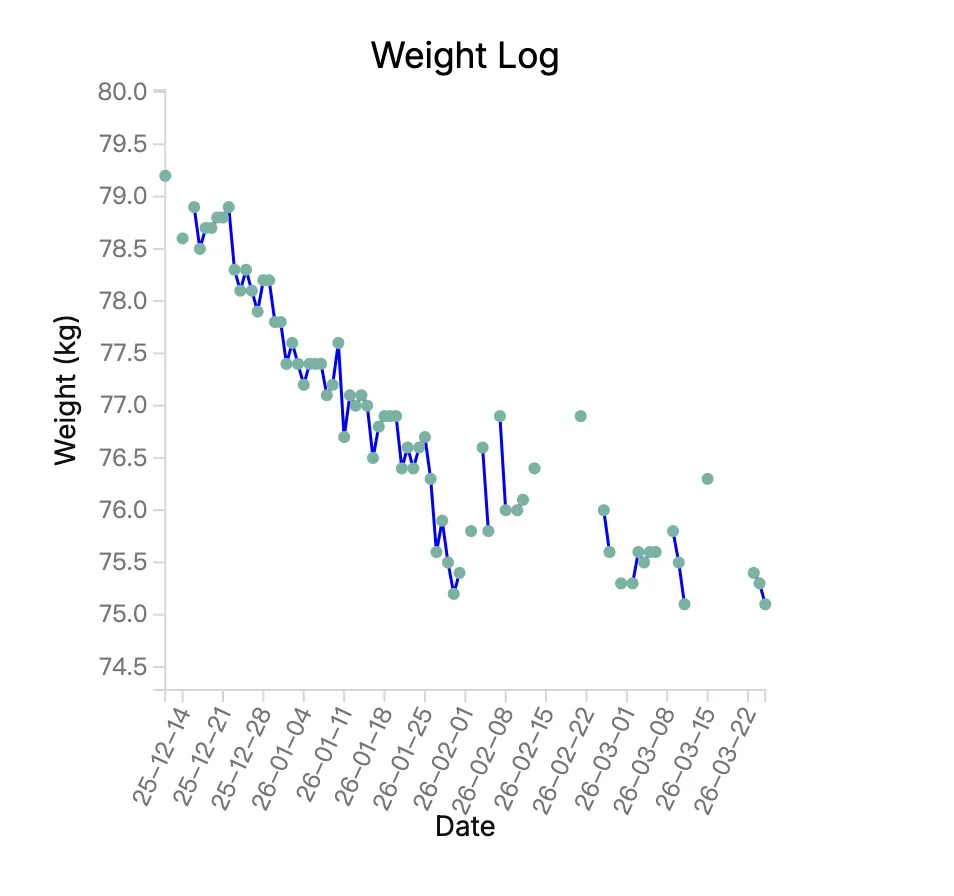
我自己目前就在用 Tracker 做一个非常简单的个人健康面板,比如:
-
体重趋势
-
BMI趋势
-
体脂趋势
-
体能趋势
有兴趣可以看文章:《我用 Obsidian 管理健康:只记录这几项健康数据》,当这些数据被画成图表之后,你会发现一件很有意思的事情:很多变化,其实一眼就能看出来。有时候一个简单的折线图,比几十条笔记更有意义。
第三种:热力图 —— 让习惯一眼可见
还有一种可视化方式,是热力图。如果你用过 GitHub,应该见过那种提交记录日历。每天提交代码,日历上就会出现一个绿色方块。坚持越久,这张图就越壮观。这种可视化方式其实非常适合习惯记录。在 Obsidian 中,很多人会用热力图来记录:
-
写作天数
-
阅读天数
-
学习打卡
-
运动记录
它最大的价值不是看趋势,而是看连续性。当你看到一整个月都被颜色填满的时候,其实是一种很强的心理激励。很多人会把热力图放在 Obsidian 首页,当作一种习惯提醒。但是也要结合自己的性格和偏好进行选择,我个人就更喜欢更详细的可视化数据,因此,没有过多的使用热力图。
第四种:DataviewJS —— 无限可能的进阶玩法
如果你继续深入探索,很可能会遇到一个更高级的玩法:DataviewJS。 简单来说,它是在 Dataview 的基础上,允许你用 JavaScript 自定义数据逻辑。很多高手会用 DataviewJS 做出非常复杂的页面,比如:
-
阅读统计面板
-
项目管理仪表盘
-
内容创作监控系统
甚至可以做出类似 Notion Dashboard 的页面。不过说实话,这种玩法更适合技术能力比较强的人。因为一旦进入 DataviewJS 的世界,你会发现:自由度很高,但复杂度也会明显提高。 如果只是做个人记录,其实完全不一定需要走到这一步。
对于我个人只是用来统计我听写的英语素材覆盖了多少词汇,参考代码如下:
// 获取所有带 #book 标签的笔记const pages = dv.pages("#听写");// 合并所有笔记内容let allWords = [];for (let page of pages) {const content = await dv.io.load(page.file.path);const words = content.toLowerCase().match(/\b[a-z'-]+\b/g) || [];allWords.push(...words);}// 去重统计const uniqueWords = [...new Set(allWords)];// 输出结果dv.el("p", `**听写覆盖单词去重词汇量**: ${uniqueWords.length} (来自 ${pages.length} 篇笔记)`);

总的来说
在折腾了这么多插件之后,我反而越来越克制。因为我慢慢意识到一件事情:Obsidian 的数据系统,其实不需要太复杂。 大多数情况下,只要两个工具就够了:
-
Dataview:Dataview 负责整理数据。
-
Tracker:Tracker 负责展示趋势。
这两者组合在一起,其实已经可以搭建一个非常完整的个人数据系统。而像 DataviewJS、Charts 这些插件,更像是进阶玩法。如果一开始就研究这些高级功能,很容易陷入一种状态:花很多时间搭建系统,却很少真正记录数据。
但从数据分析的角度来看,最重要的一件事情其实是:持续的数据输入。 如果没有数据积累,再漂亮的图表也只是空壳。所以现在我的原则其实非常简单:
先记录,再可视化。当数据积累到一定程度之后,你会发现一件很有趣的事情。你的 Obsidian,已经不只是一个笔记软件。它慢慢变成了一个属于你自己的:人生数据仪表盘。