 夜雨聆风
夜雨聆风





聊天消息导出Excel,影刀 RPA 这样搞定发信人自动识别
你好呀
本篇文章分享使用影刀RPA搭建桌面软件自动化应用的一些难点及对应的解决思路。
由于桌面软件的懒加载机制,使用影刀RPA获取桌面软件展示的数据一般都会遇到以下几个问题:
-
交互展示不全:当要操作的元素(按钮、输入框等)未完全展示在可视区域时,对该元素操作可能无响应。
-
滚动控制困难:由于不同电脑的分辨率以及鼠标滚轮的速度存在差异,同一滚动操作其滚动的效果是不一样的,难以精确控制滚动范围。
-
数据重复采集:滚动操作难以精确控制滚动范围,容易导致同一个元素被多次识别和采集,造成数据冗余。
-
风控检测风险:若滚动操作的模式过于规律和机械,容易被系统判定为非人为操作,触发风控机制,出现一些机器人操作的警告或限制。
-
字段展示不统一:有值的字段展示在界面上,没值的字段就不展示。
-
发信人难识别:有些桌面软件在聊天界面不显示发信人的名称,或者显示了也获取不到,只能获取到消息内容文本,导致无法识别到发信人的名称,也无法识别消息是己方消息还是对方消息。
对于前5个问题的解决思路可以看我之前的文章:
通讯录导出 Excel:影刀 RPA 递归遍历 UI,精准提取文本数据
这篇文章,就以会话消息批量导出 Excel为真实场景,分享一套通用、稳定、可复用的解决思路:通过图像像素颜色分析判断气泡左右位置,实现自动识别对方/我方消息;通过图像OCR识别,实现自动识别发信人名称;彻底解决发信人难识别的采集痛点。
需求场景
使用影刀RPA自动化采集会话联系人的聊天消息内容,并将其结构化导出至本地 Excel 文件,具体如下:
数据采集:从会话联系人列表中,依次打开会话联系人的聊天窗口,自动提取消息内容。
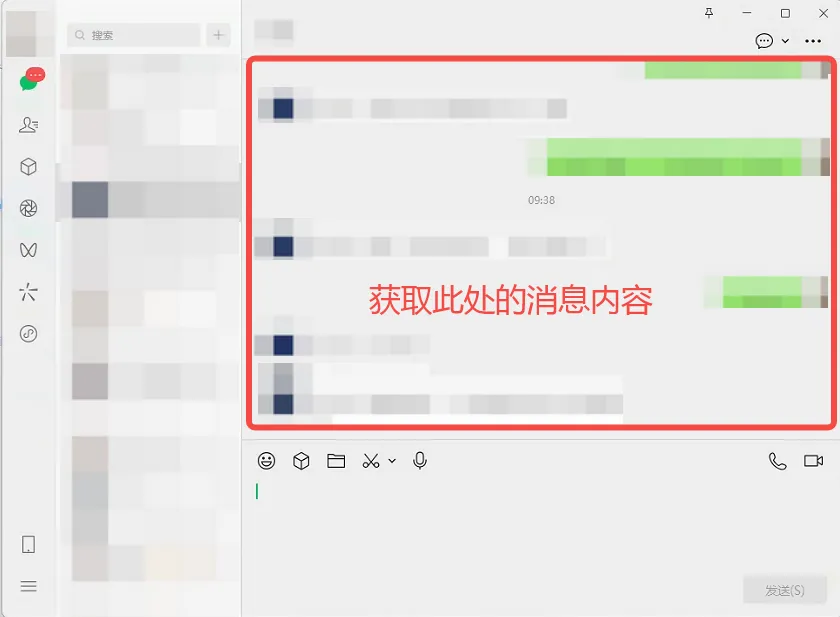
数据导出:将采集到的所有会话联系人消息内容,以清晰的表格形式导出并保存到本地 Excel 文件中,便于后续的数据统计、分析与归档。

应用分享
如果想体验一下,看看实现效果的话,可以直接通过下方链接获取完整的RPA应用。
https://api.winrobot360.com/redirect/robot/share?inviteKey=d4a6524e733f5ba1
如果没有安装影刀客户端,可以通过如下链接在官网下载安装:https://www.yingdao.com/client-download/
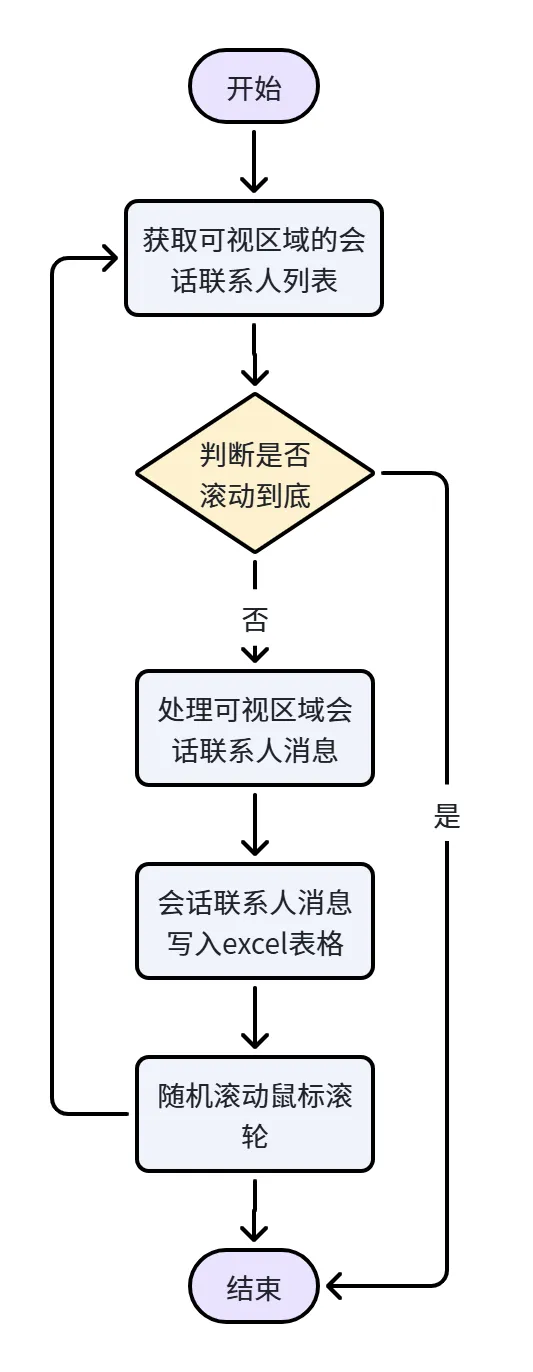
整体流程
-
从会话联系人中获取聊天消息内容,区分发信人并去重。
-
自动滚动会话联系人列表,避免重复采集
-
将去重后的会话联系人消息内容写入 Excel 文件存档
具体实现
这里的发信人难识别主要有两点:
一个是识别是对方发送的消息还是我方发送的消息
一个是识别消息发送人的名称
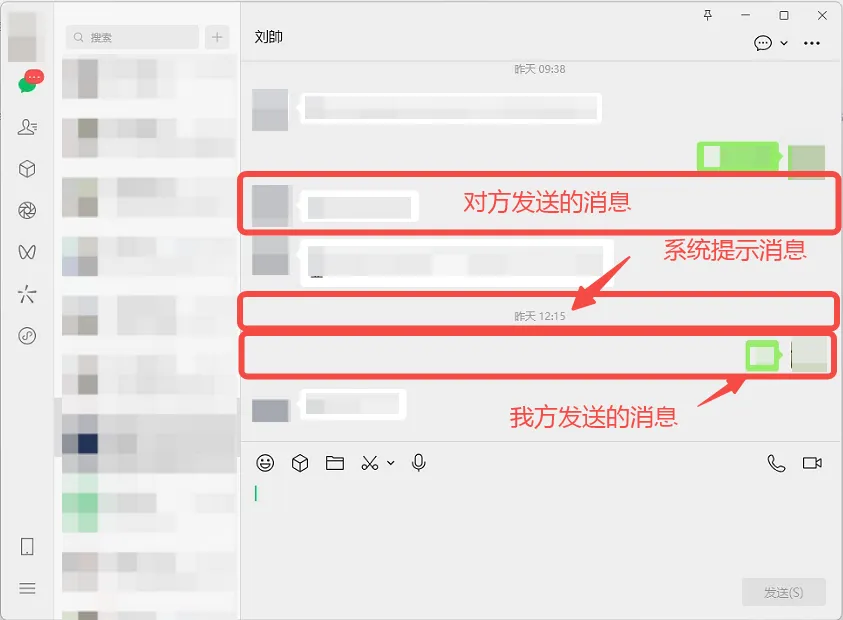
第一个难点:识别消息是对方发送的消息还是我方发送的消息
可以看到,在消息框,目前有三种类型的消息,靠左边是对方发送的消息,靠右边是己方发送的消息,靠中间是软件提示的日期消息。我们需要去识别这三种类型的消息,然后写入excel表格中。
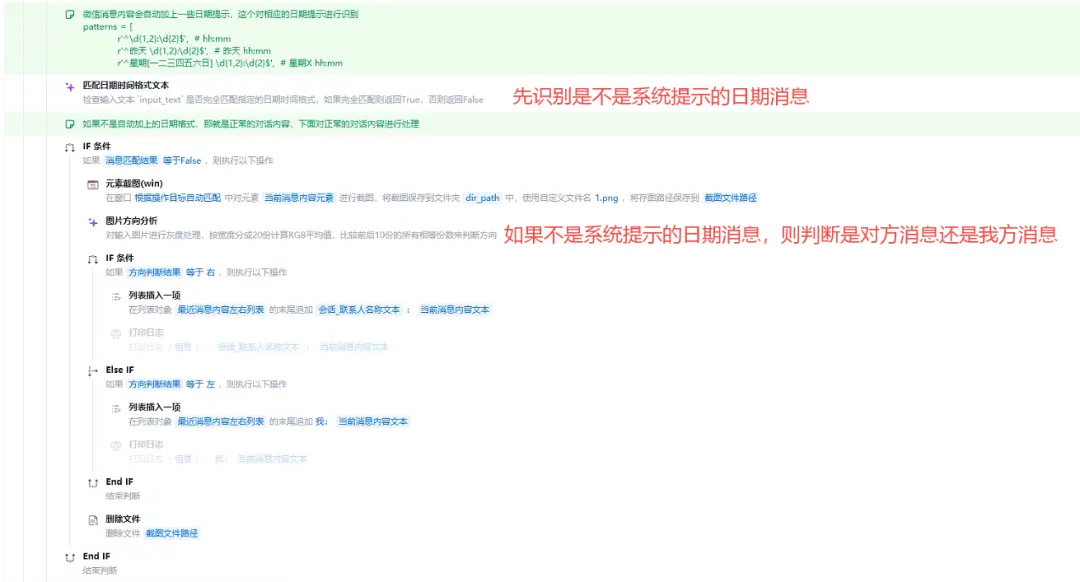
第一步:识别软件的日期提示消息(如“14:30”、“昨天 09:15”、“星期一 12:00”等)
定义了一组正则表达式(patterns),专门匹配这些日期格式。
patterns = [r'^\d{1,2}:\d{2}$', # hh:mmr'^昨天 \d{1,2}:\d{2}$', # 昨天 hh:mmr'^星期[一二三四五六日] \d{1,2}:\d{2}$', # 星期X hh:mmr'^\d{1,2}月\d{1,2}日 \d{1,2}:\d{2}$', # X月X日 hh:mmr'^\d{4}年\d{1,2}月\d{1,2}日 \d{1,2}:\d{2}$' # XXXX年X月X日 hh:mm]
第二步:区分消息归属(对方/我方)
元素截图:对当前聊天窗口的消息气泡进行截图,并保存到指定路径。
图片方向分析:

-
对截图进行灰度化处理,按宽度平均分成20份。
-
计算每一份的RGB平均值。
-
通过比较前10份和后10份的像素值,判断消息气泡是在屏幕左侧还是右侧。如果消息气泡在左边,则右边10份图像颜色相等的块比左边多。
第二个难点:识别对方发送消息
可以看到对方发送的消息显示了发送人名称,但是实际上通过捕获元素的方式不能直接获取到发送人名称文本。

这个时候可以通过OCR来对图片进行文字识别
本文使用是百度的paddleocr:https://aistudio.baidu.com/paddleocr
PP-OCRv5是PP-OCR新一代文字识别解决方案,该方案聚焦于多场景、多文字类型的文字识别。在文字类型方面,PP-OCRv5支持简体中文、中文拼音、繁体中文、英文、日文5大主流文字类型,在场景方面,PP-OCRv5升级了中英复杂手写体、竖排文本、生僻字等多种挑战性场景的识别能力。
python代码如下:
# 使用提醒:# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能# 3. 当此模块作为流程独立运行时执行main函数# 4. 可视化流程中可以通过"调用模块"的指令使用此模块import xbotfrom xbot import print, sleepfrom .import packagefrom .package import variables as glvfrom paddleocr import PaddleOCR#OCR识别def ocr_init():#ext_detection_model_name="PP-OCRv5_server_det",#text_recognition_model_name="PP-OCRv5_server_rec",# text_detection_model_name="PP-OCRv5_mobile_det",# text_recognition_model_name="PP-OCRv5_mobile_rec",ocr = PaddleOCR(ocr_version="PP-OCRv5",text_detection_model_name="PP-OCRv5_server_det",text_recognition_model_name="PP-OCRv5_server_rec",use_doc_orientation_classify=False,use_doc_unwarping=False,use_textline_orientation=False)return ocrdef ocr_text(image_path, ocr_instance):name = ''result = ocr_instance.predict(input=image_path)res = result[0]rec_texts_list = res['rec_texts']rec_scores_list = res['rec_scores']rec_boxes_list = res['rec_boxes']for i in range(0, len(rec_texts_list), 1):if rec_scores_list[i] > 0.7:# print(rec_texts_list[i])name = rec_texts_list[i]breakreturn namedef main(args):pass
RPA的处理逻辑如下:

以上就是本次影刀 RPA 桌面软件自动化实战的完整思路:
从聊天消息无法识别发件人的核心难题出发,通过正则表达式过滤系统日期消息,结合截图像素分析判断气泡左右位置,精准识别对方、己方与系统消息;通过图像OCR识别,提取发信人名称文本,最终实现聊天消息自动采集、归属区分、数据去重,并结构化导出至 Excel,为会话消息自动化归档与分析提供完整可落地的解决方案。