夜雨聆风
夜雨聆风





你的AI编程助手可能正在被攻击:Agent安全领域的15个项目和4条防御路线
当 AI Agent 拿到了文件读写、Shell 执行、API 调用的权限,它就同时拿到了被攻击的入口。过去一年,MCP 生态 60 天内爆出 30+ 个 CVE,OpenClaw 技能商店五分之一的包被确认为恶意软件,Claude Code 自己也被发现了两个高危漏洞。安全问题已经从”理论风险”变成了”正在发生的攻击”
传统 LLM 只是生成文本,最多输出一段有害内容。但 Agent 能执行代码、读写文件、发送网络请求、调用外部 API。攻击者不再需要骗用户点链接,只需要在 Agent 的上下文里注入一条恶意指令,Agent 就会自己执行
这个问题的核心在于 Agent 无法区分”用户的真实意图”和”上下文中被注入的指令”。一篇看起来正常的文档里嵌入一句白色小字体的指令,Agent 读取后就可能执行恶意操作。学术研究显示,针对编程 Agent 的 prompt 注入攻击成功率高达 84%,5 篇精心构造的文档就能 90% 概率操控 RAG 系统的输出
更严重的是供应链攻击。MCP 服务器的工具描述、第三方 Skill 的 SKILL.md 文件、甚至项目里的 .claude/settings.json 都可以成为注入点。你 clone 了一个看起来正常的 GitHub 仓库,打开 Claude Code 的瞬间就可能被 RCE
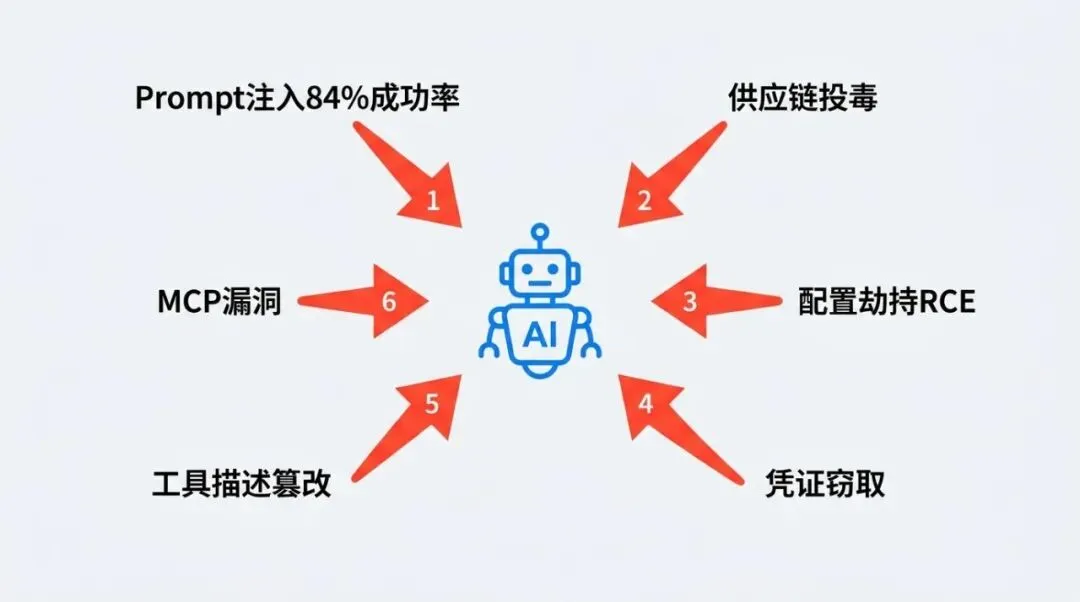
真实威胁:CVE、供应链投毒、大规模窃密
这些不是假设场景,全部是 2025-2026 年真实发生的事件
MCP 生态的 CVE 爆发。mcp-remote 包(43 万次下载)被发现 CVSS 9.6 的远程代码执行漏洞(CVE-2025-6514),攻击者通过恶意 authorization_endpoint 注入 OS 命令。调查显示 43% 的 MCP 服务器存在命令注入漏洞,43% 存在 OAuth 认证缺陷,33% 允许不受限的网络访问
OpenClaw 供应链危机。这是目前确认的最大规模 AI Agent 供应链攻击。OpenClaw 一天涨了 25000 个 GitHub star,三周后被发现一键 RCE 漏洞,13.5 万个暴露实例。技能商店 ClawHub 里 1184 个包被确认为恶意软件(每 5 个包里就有 1 个),通过 SKILL.md 注入、隐藏反向 Shell 脚本、Token 窃取等手段分发 macOS 窃密木马
Claude Code 自身的漏洞。CVE-2025-59536(CVSS 8.7)允许通过 .claude/settings.json 注入 Hooks 实现 RCE,开发者打开不受信任的仓库就中招。CVE-2026-21852 允许通过项目配置覆盖 ANTHROPIC_BASE_URL,把 API 流量(包括认证头)重定向到攻击者服务器
编码 Agent 的集体沦陷。GitHub Copilot(CVE-2025-53773,CVSS 9.6)、Cursor(CVE-2025-61590)、Roo Code(CVE-2025-58372)全部被发现类似的工作区配置劫持漏洞。DryRun Security 的审计发现 87% 的 AI 生成 PR 会引入安全漏洞

四条防御路线:从静态扫描到硬件隔离
目前社区的防御方案大致分四个方向
静态扫描是最容易部署的方案。Invariant 的 MCP-Scan(1100+ 星,已被 Snyk 收购)能检测工具描述中的 prompt 注入、跨源提权、rug pull 攻击。AgentSeal 给 8000+ 个 MCP 服务器做了安全评分,9 个分析器扫描发现了 4513 个深度问题,其中 1067 个为严重级别。Agent Audit 做了 49 条映射到 OWASP Agentic Top 10 的规则,支持跨工具边界的污点追踪。静态扫描的问题是只能发现已知模式,自适应攻击可以绕过
运行时拦截在 Agent 执行过程中实时监控和阻断。MCP-Scan 的代理模式可以拦截 MCP 通信流量并限制 Agent 能力。Lakera Guard 是商业化方案,基于 19.4 万次人类攻击尝试训练的实时检测引擎。ICSE 2026 的 AgentSpec 论文提出了用 DSL 定义运行时行为约束的方案。运行时拦截的问题是增加延迟,而且需要定义完整的安全策略
沙箱隔离在基础设施层面限制 Agent 的能力边界。Docker Sandboxes 用 MicroVM 给每个 Agent 独立的隔离环境,Agent 可以在沙箱内构建和运行 Docker 容器但无法触及宿主机。Firecracker 和 gVisor 提供更底层的内核级隔离。沙箱的问题是 Agent 需要访问文件系统和网络才能工作,权限开太大等于没隔离,开太小 Agent 功能受限
密码学验证是最前沿的方向。MCP Guardian 用 SHA-256 哈希钉住工具定义,工具描述被篡改后立即报警。Docker MCP Gateway 在镜像拉取时自动验证来源。这个方向目前最不成熟,缺少统一的签名标准和信任链

ClawKeeper:三层架构的整合尝试
ClawKeeper(464 星)是目前唯一把三个防御层级整合到一个框架里的项目,来自一篇 22 页的学术论文(arXiv: 2603.24414)
第一层 Skill:策略注入。通过结构化 Markdown 文档把安全策略直接注入 Agent 的上下文。不需要改代码,Agent 原生读取并遵循策略。目前提供了 Windows 安全指南和飞书安全指南两套模板,覆盖破坏性操作、认证篡改、凭证外泄、权限持久化、代码注入、供应链风险等场景。包含夜间自动安全审计和配置基线监控
第二层 Plugin:运行时拦截。内部运行时执行器,挂载到 Agent 的插件系统。11 个核心模块包括审计引擎、配置加固、第三方扫描器、配置漂移检测、动作拦截器、回滚能力。威胁检测覆盖网络网关、凭证、执行控制、访问限制、内存完整性、成本暴露、供应链、入侵指标等 10 个域
第三层 Watcher:独立监控中间件。架构最复杂的一层。一个与 Agent 解耦的系统级监控守护进程,独立运行。通过 HTTP 端点接收状态评估请求,可以阻止高风险操作或强制人工确认。支持本地和远程(云端)两种部署模式。包含用户审批层,实现人在回路
这个三层设计的思路是防御纵深:策略层告诉 Agent “什么不该做”,插件层在运行时”拦住不该做的”,Watcher 层在系统级”监控已经做了什么”。论文报告在 7 个安全任务类别、140 个对抗测试实例上达到了最优防御性能
现有方案的共同缺陷
把所有方案放在一起看,几个关键缺陷很明显
缺少统一的 Skill 签名和信任链。现在任何人都可以发布一个 Skill 或 MCP 服务器,没有身份验证、代码签名、也没有安全审计要求。SHA-256 钉住工具定义只能检测篡改,不能判断原始定义是否安全。OpenClaw 事件说明了商店审核机制的脆弱
Prompt 注入仍然没有根本解决方案。78 项研究的 meta 分析显示,使用自适应策略的攻击成功率超过 85%。所有检测方案都是概率性的,不存在 100% 防御。Prompt Armor 做到了 91.7% 的 F1 Score 和 27ms 延迟,但仍有近 10% 的漏检率
静态扫描和运行时监控存在矛盾。扫描太严会产生大量误报影响开发效率,太松会漏掉真正的威胁。AgentSeal 在 8000+ 服务器中发现了 4513 个问题,但多少是真正的安全隐患、多少是误报需要人工判断
沙箱的权限粒度不够。Agent 需要文件读写权限才能编辑代码,需要网络权限才能调用 API,需要 Shell 权限才能运行测试。目前的沙箱方案要么是全开(等于没有)要么是全关(Agent 没法工作),缺少按操作类型的细粒度权限控制
ClawKeeper 自身的局限。只有 15 次提交,零个 issue,零个 PR,更像是论文的 demo 代码。只支持 OpenClaw 平台,不支持 Claude Code、Cursor 等主流 Agent。学术味重,工程落地程度低

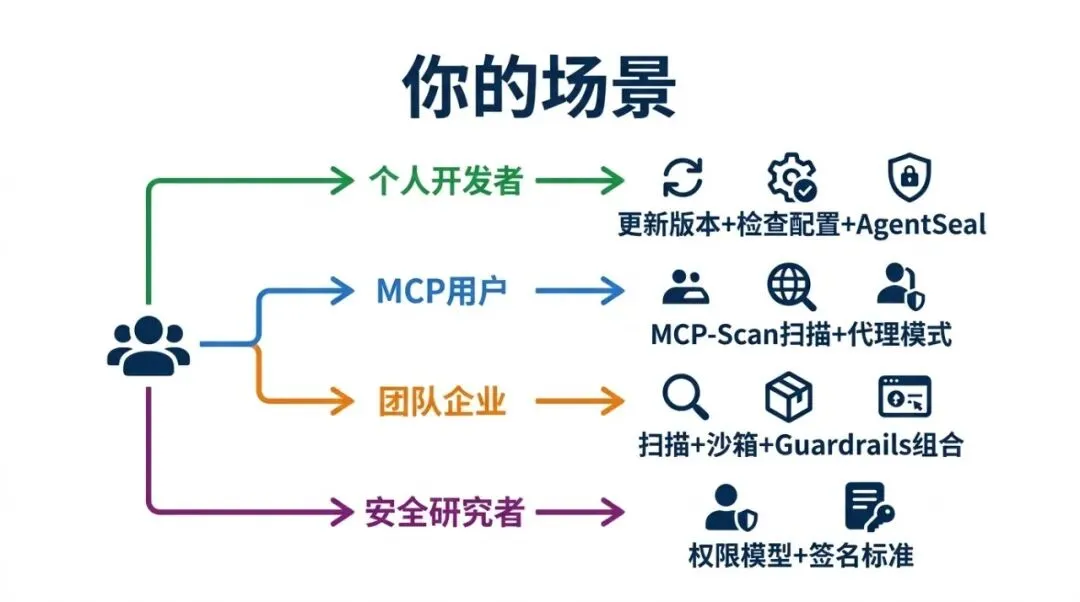
不同场景的安全方案选择
个人开发者用 Claude Code,最低成本的安全措施是:不随便 clone 不信任的仓库后直接跑 Claude Code,检查项目里有没有 .claude/ 目录下的可疑配置,保持 Claude Code 更新到最新版本(CVE-2025-59536 在 v1.0.111 修复)。如果想进一步,装 AgentSeal 扫描本地的 MCP 配置和 Skill
用 MCP 服务器的开发者,先用 MCP-Scan 扫描已安装的服务器。它能检测工具描述中的注入和 rug pull 攻击。代理模式可以在运行时拦截可疑操作。被 Snyk 收购说明这个工具的技术被主流安全公司认可
团队和企业,需要组合方案:MCP-Scan 做入口扫描 + Docker Sandboxes 做执行隔离 + NeMo Guardrails 或 Lakera Guard 做运行时防护。如果用 OpenClaw 生态就加上 ClawKeeper。关键是建立 Skill/MCP 服务器的引入审查流程,不能让开发者随意安装未审计的扩展
安全研究者和贡献者,这个领域最缺的是细粒度权限控制系统和统一的 Skill 签名标准。AgentSpec 的 DSL 约束方案和 MCP Guardian 的密码学验证方向都值得深入
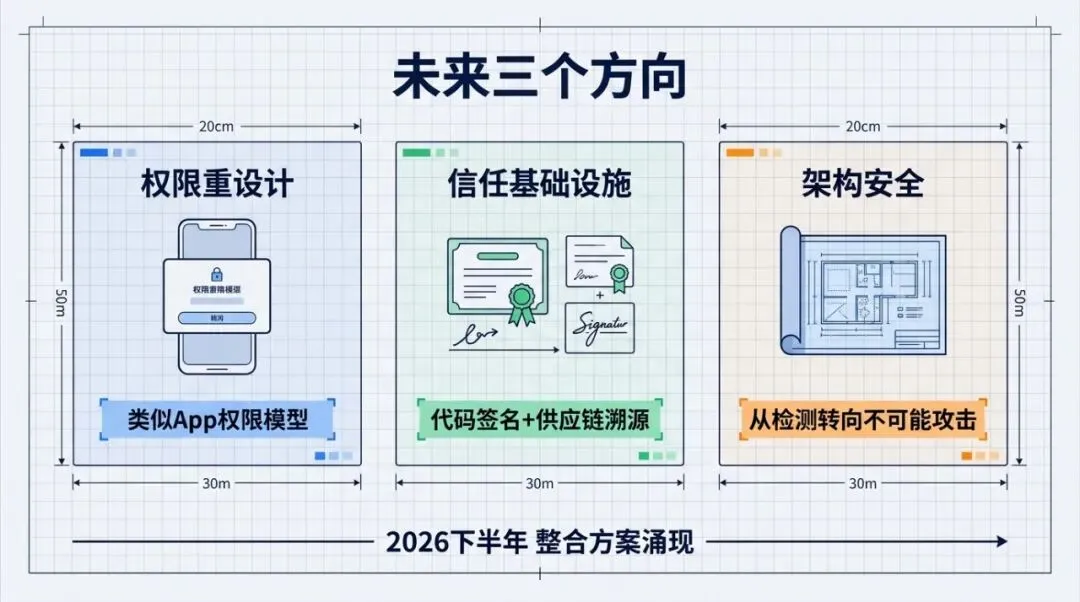
未来必须解决的三个问题
Agent 的权限模型需要重新设计。现在的 Agent 拿到的是全局权限:能读所有文件、能访问所有网络、能执行任意命令。未来需要类似移动端 App 的权限申请模型,每次访问敏感资源都要明确授权,而且要限制在最小必要范围。Deno 的显式权限声明是一个参考方向
需要建立 Skill/MCP 的信任基础设施。包括开发者身份认证、代码签名、安全审计认证、供应链溯源。类似 npm 的 provenance 特性和 Docker 的镜像签名。没有这套基础设施,Agent 的扩展生态永远是安全洼地
防御需要从检测转向架构安全。当前大部分方案是”检测并阻止已知攻击”,这是被动防御。未来的方向是在架构层面让攻击不可能发生:Agent 和工具之间的通信只能通过结构化的 schema,工具的输出不能包含可执行指令,Agent 的行为约束在系统层面强制执行。AgentSpec 的运行时约束 DSL 和 ClawKeeper 的 Watcher 独立监控是这个方向的早期探索
这个领域还很早期。ClawKeeper 的三层架构思路正确,但工程成熟度不够。MCP-Scan 被 Snyk 收购说明安全大厂已经入场。2026 下半年大概率会看到更多整合方案出现