 夜雨聆风
夜雨聆风





砖家说AI-RAG 检索增强生成:让 AI 从"胡编"到"真懂"
AI 核心技术
RAG 检索增强生成:让 AI 从”胡编”到”真懂”
开卷考试机制如何将回答准确率从 70% 提升到 90% 以上
🚀扫读者快速通道2 分钟掌握本质

一句话定义

🔍审阅者深度解析12 分钟建立系统认知
为什么 AI 需要”开卷考试”?
大语言模型的知识在预训练时就冻结了——它不知道你公司刚更新的年假政策,不清楚你们产品的最新定价,也无法回答今天刚发布的财报数据。主流模型的幻觉率在10%-30%,意味着每回答 10 个问题,就有 1-3 个是编造的。
这在消费级聊天场景里尚可接受,但在企业场景里却是致命的:HR 机器人编造劳动法条款导致劳动仲裁,客服 AI 虚构退款政策引发投诉,医疗 AI 臆断药品禁忌害人性命——幻觉的代价,有时超出技术本身。
RAG 解决方案:在用户提问时,先从实时更新的知识库中检索相关文档,把这些真实材料作为上下文塞进 Prompt,让模型”看着证据说话”,而不是凭参数记忆编答案。
向量检索:RAG 的技术心脏
传统搜索依赖关键词匹配——用户搜”笔记本”,只返回包含”笔记本”三个字的结果,”Laptop”和”便携电脑”被完全忽略。RAG 不一样,它靠的是语义理解。
核心是Embedding(嵌入)技术:把文字转换成一段数字(向量),”意思相近的内容,转换后向量距离也近”。比如”如何申请年假”和”年假流程怎么走”,字面差异大,但向量距离近,检索时能正确匹配。
一个 1536 维的向量空间里,每个词、每个句子、每个文档都是空间中的一个点。语义相近的点聚在一起,检索变成”在向量空间里找最近邻”——一个纯粹的数学问题,但解决了语言理解的根本问题。
1RAG 完整工作流程
分为建库阶段(离线准备)和查询阶段(实时回答),两阶段相互独立又紧密衔接。
建库阶段(一次性,离线完成)
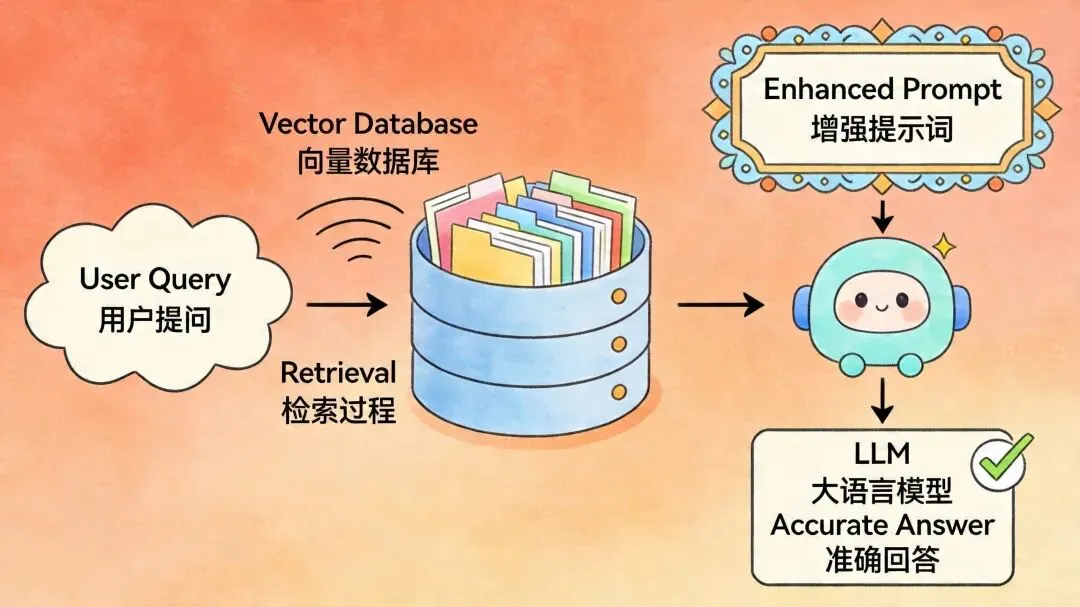
查询阶段(每次提问实时执行)
查询阶段全流程
2两个类比,彻底理解 RAG 本质
📝类比一:开卷考试
传统 AI 如同闭卷考试——全靠记忆,硬写答案,对不知道的内容就胡编。
RAG 引入”开卷”机制:允许翻参考书,先找证据,再给答案。

📚类比二:图书管理员
用户 = 提问者,管理员 = 检索器,书架 = 向量数据库。
管理员理解问题 → 书架上找相关书籍 → 把书页递给用户 → 用户基于真实内容回答。

管理员类比图
3RAG 的四大局限
●检索质量决定一切
●无法解决推理类问题
●实时性有物理瓶颈
●成本不可忽视
与其他技术方案横向对比

注:幻觉率数据来自多个企业场景实测均值,个体差异较大,表中为参考范围。
🛠实施者实操指南20 分钟掌握落地要点
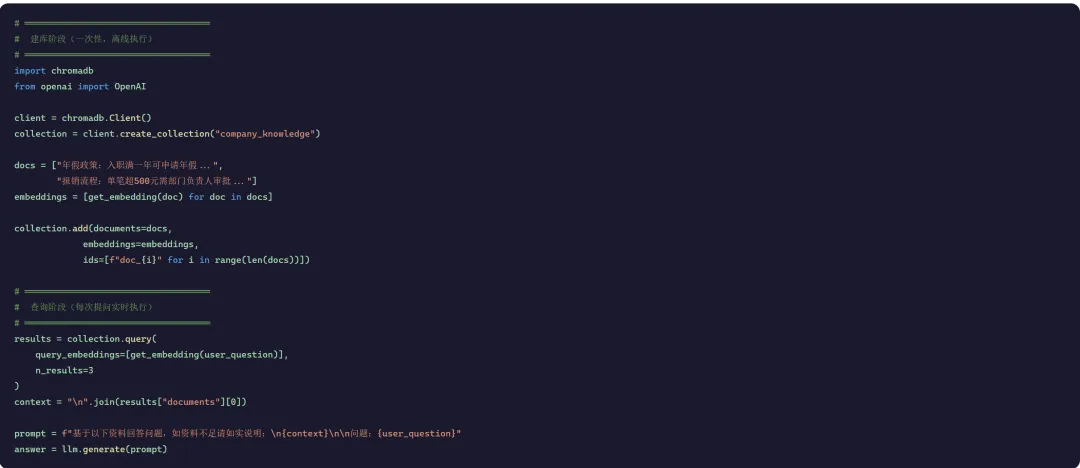
1案例:企业内部知识问答系统
⚠️ 常见陷阱(实施前必读)
分块过大 → 关键信息被稀释,检索精度下降,答案泛泛而谈
分块过小 → 丢失上下文,每块只言片语无法理解完整语义
忽略元数据 → 文档来源不清,无法溯源,答错了也不知道错在哪
只检索不验证 → 高风险场景(医疗、法律)仍需人工复核机制
使用过时 Embedding 模型 → 召回率低,建议使用最新版本
🗒️ RAG 项目评估清单(实施前自查)
□知识库覆盖率:现有文档能否覆盖 80% 以上的用户提问场景?
□内容质量:文档是否经过人工审核?是否存在过时政策、错误表述?
□Embedding 模型选型:是否选择了与语料匹配的 Embedding 模型(中文场景推荐 text-embedding-3-small 或对应中文模型)?
□分块策略:是否针对不同类型文档(制度类、流程类、FAQ 类)测试了不同分块大小?
□溯源机制:是否记录了每次回答引用的文档来源,支持人工抽查?
□成本测算:是否评估了日均调用量对应的向量检索成本 vs 纯 LLM 调用成本?
📚 延伸阅读
1《Building RAG Pipelines with ChromaDB》ChromaDB 官方文档 / Hands-On 教程,适合想动手实作 ChromaDB + LLM 流水线的开发者
2《Retriever-Augmented Generation: A Survey》学术综述论文,系统梳理 RAG 技术演进路线、评测方法与未来方向,适合想深入原理的读者
3《RAG vs Fine-tuning: Choosing the Right LLM Customization Strategy》Pinecone 技术博客,对比 RAG 与微调的适用场景、成本结构与效果差异,附决策树流程图
4《下一代 RAG 演进方向:多模态、主动检索、Self-RAG》技术博客,梳理 2024-2025 年 RAG 前沿进展:Self-RAG、Corrective-RAG、Multimodal RAG 等新范式
🎯 一句话总结
📌 本文基于公开资料整理,仅供技术科普用途