 夜雨聆风
夜雨聆风





永不掉线的AI:LiteLLM如何用故障转移为你的应用保驾护航
如果你的应用依赖大语言模型API,你一定经历过这样的时刻:深夜收到报警,用户无法使用AI功能,原因是某个模型服务商出现临时故障或触发了速率限制。对于依赖AI能力的关键业务来说,每一次API调用失败都可能意味着用户体验下降、商机流失。
LiteLLM的故障转移(Fallbacks)功能,正是为解决这一痛点而生。

故障转移的核心逻辑很简单:当一个模型调用失败时,自动切换到另一个备用模型继续提供服务。整个过程对用户完全透明,他们甚至感知不到背后发生了什么。
工作原理:智能降级,层层递进
LiteLLM的故障转移机制经过精心设计,确保在最短时间内找到可用的模型。其核心流程如下:
❖ 第一步:优先尝试主模型
系统首先使用你指定的主模型发起请求。
❖ 第二步:按顺序尝试备用模型
如果主模型失败(无论是因为限速、超时还是服务错误),LiteLLM会按照你设定的顺序,依次尝试备用模型,直到获得成功响应。
❖ 第三步:冷却机制保护不稳定模型
当一个模型调用失败后,LiteLLM会将其加入冷却名单,60秒内不再调用该模型,避免反复向一个已知故障节点发送请求。
❖ 第四步:45秒超时保护
整个故障转移过程有45秒的超时限制,确保不会无限等待。



LiteLLM提供了灵活多样的故障转移配置方式,满足不同场景的需求:
模型级故障转移
这是最常用的模式。当主模型失败时,自动切换到不同提供商的其他模型。
第一步:设置可靠性参数
这些参数共同决定了故障转移的”容错”和”自愈”行为。
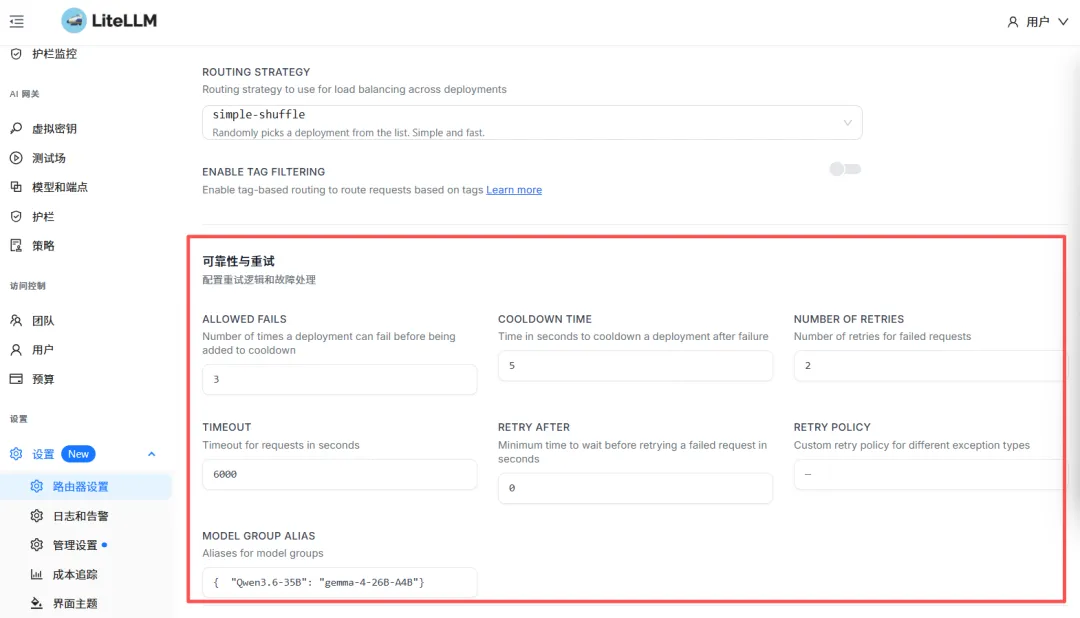
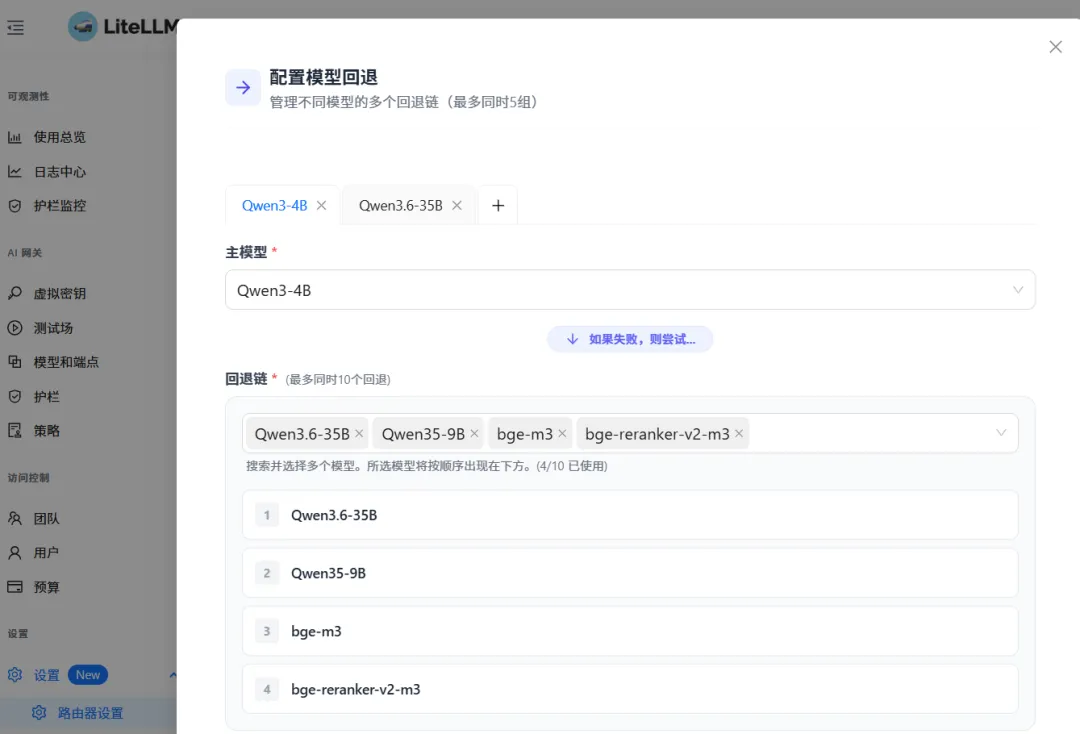
第二步:配置回退链
-
最多同时配置 5 组回退链(即可以为主模型配置 5 种不同的回退策略组合)
-
每组回退链最多包含 10 个备用模型
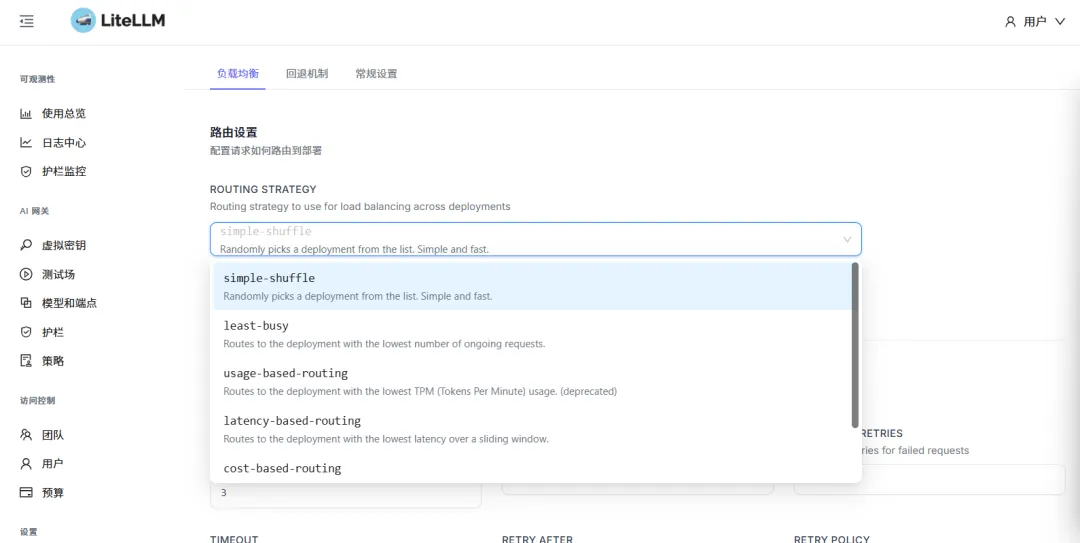
主动故障转移下的重试模式
LiteLLM 提供了多种灵活的负载均衡策略,能够将请求智能分发到多个后端部署,实现流量的均衡调度。同时,它采用主动请求级重试故障转移模式,该模式不依赖独立的健康检查机制,而是在请求失败后,立即根据配置的路由策略(如随机、最少负载、最低延迟、最低成本等),自动将请求重试到其他可用的部署实例,并通过可配置的重试次数来保障系统的高可用性。

电商高峰期:核心模型宕机
大促期间GPT-4宕机,LiteLLM自动切换到Claude 3、通义千问,文案生成、用户咨询不受影响,避免订单流失。
企业客服:模型速率受限
高峰期Azure OpenAI触发限速,自动路由到本地Ollama模型,客服响应不中断,配额恢复后自动切回。
政企合规:多模型冗余
公有云模型故障时,自动切换到本地模型,既保障服务连续,又满足数据私有化合规要求。

LiteLLM的故障转移能力已获得主流AI框架和工具的认可,广泛应用于各类生产场景,成为保障AI服务稳定的核心支撑:
-
Rasa对话式AI平台:在其3.11版本中集成了LiteLLM的路由与故障转移功能,用于多LLM部署之间的请求分发、负载均衡,同时依托故障转移机制,确保对话服务稳定不中断;
-
OpenClaw等工具:将LiteLLM推荐作为核心模型网关,核心利用其“主提供商不可用时自动故障转移”的能力,解决模型调用不稳定问题,大幅提升工具的可靠性和实用性。
4个实用建议,快速用对故障转移:

写在最后
在AI应用从”能用”走向”好用”的过程中,可靠性是绕不开的课题。LiteLLM的故障转移功能,通过简洁优雅的设计,为开发者提供了一套生产级的可用性保障方案。
正如Thoughtworks技术雷达所评价的:”我们的团队一直将LiteLLM用作AI网关,以实现企业级AI使用的标准化、安全管控和可见性。” 当你的AI应用需要真正的”永不掉线”时,不妨让LiteLLM为你保驾护航。
下期预告:LiteLLM,养虾人的AI好帮手

感谢观看,扫码关注