 夜雨聆风
夜雨聆风





告别失忆!OpenClaw生产级记忆插件部署: memory-lancedb-pro 终极折腾指南——从处处碰壁到稳定运行
本文将带你亲历一次“Hard 模式”的 OpenClaw 生产级记忆插件部署,记录从迷惑到成功的全过程。如果你正在为 OpenClaw 寻找一个支持混合检索、智能提取、重排序的生产级长期记忆方案,或者正被诡异的
must NOT have additional properties折磨,这篇万字长文应该能帮你少踩很多坑。
一、痛点:为什么我们需要一个新的记忆插件?
OpenClaw 内置的memory-core已经提供了基础的记忆能力:它会把对话中重要的信息存入MEMORY.md文件,然后通过简单的文件扫描或关键词匹配来召回。但在真实的生产环境中,这种“文件式全文检索”存在几个明显的瓶颈:
-
检索精度低:仅靠关键词或简单的语义匹配,很难从数百条记忆中精准找到最相关的那几条。
-
缺乏智能提炼:大量原始对话直接塞进文件,噪音多、Token 消耗大。
-
无法处理多 Agent:所有 Agent 共用一个记忆池,极易造成信息污染。
-
无重排序:初步搜索结果不做深度排序,最相关的记忆可能被埋在后面。
于是,社区涌现了一些进阶插件,memory-lancedb-pro就是其中的佼佼者。它宣称支持:
-
混合检索 (Hybrid Search):向量语义搜索 + BM25 关键词搜索,取长补短。
-
交叉编码器重排序 (Cross-Encoder Rerank):用专门的模型对初步结果进行二次排序,大幅提升命中率。
-
智能提取 (Smart Extraction):利用 LLM 自动从对话中提炼结构化记忆,而非生硬地保存原文。
-
多 Agent 隔离:可为不同 Agent 创建独立的记忆空间。
听起来实在太美好了,但下一秒我就被现实教育了——安装过程一波三折,几乎踩遍了所有能踩的坑。
二、插件真相:Plugin?Skill?还是两者都是?
memory-lancedb-pro的官方仓库表明它是一个 插件 (Plugin),设计上是通过 OpenClaw 的plugins.slots.memory插槽来接管记忆系统。然而在 2026.4.15 版本中,当你尝试:
openclaw plugins install memory-lancedb-pro
系统可能会提示“memory-lancedb-pro” is a skill,这是因为该插件同时以“技能”形式在 ClawHub 上发布。但作为“技能”安装只会把脚本放进 skills/ 目录,并不会生成插件所需的openclaw.plugin.json清单文件,导致框架无法通过slots.memory识别它。
结论:memory-lancedb-pro的本质是插件,必须采用插件的方式安装和注册。技能安装只是个“美丽的误会”。
三、安装历险记:那些让你抓狂的报错与正确步骤
3.1 第一次尝试:安全拦截
直接使用插件安装命令:
openclaw plugins install memory-lancedb-pro@beta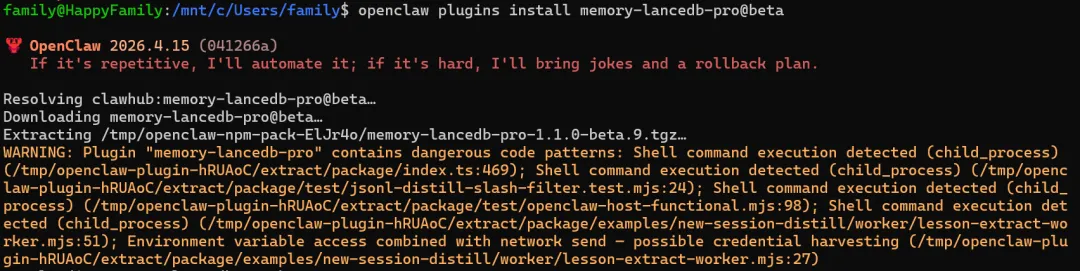
随即收获一堆WARNING: dangerous code patterns detected,然后被无情阻止:
Plugin “memory-lancedb-pro” installation blocked: dangerous code patterns detected
安全扫描指出代码中使用了child_process和可能的环境变量收集,虽然是测试文件和示例代码,但框架默认拒绝安装。
错误应对:我们试图在openclaw.json中加入plugins.install.allowDangerous: true忽略警告安装,却发现plugins.install并不是这个版本(2026.4.15)的合法配置项,直接报Unrecognized key: “install”。
正确做法:无法通过配置关闭安全检查,就必须绕过官方安装命令,选择手动安装 + 手动注册的方式。
3.2 正确安装步骤(亲测有效)
以下步骤在 OpenClaw 2026.4.15 上验证通过:
① 使用 npm 下载并放置插件
//建立独立的三方插件目录,避免与Openclaw自带的混mkdir -p ~/.openclaw/pluginscd ~/.openclaw/plugins//以当前路径为根目录安装npm install memory-lancedb-pro@beta --prefix .
如果安装在其他目录了,也可以复制过来:
cp -r node_modules/memory-lancedb-pro ~/.openclaw/plugins/memory-lancedb-pro② 补全插件“身份证”:openclaw.plugin.json
OpenClaw 需要通过名为openclaw.plugin.json的清单文件来识别插件。正常情况目录下已有,可以验证:
ls ~/.openclaw/plugins/memory-lancedb-pro/openclaw.plugin.json如果显示文件路径,则已有;检查文件内容:确保它的id字段是“memory-lancedb-pro”。
cat ~/.openclaw/plugins/memory-lancedb-pro/openclaw.plugin.json查看输出内容,如果没有,或id 字段不是 “memory-lancedb-pro”或文件不存,
手动创建:
cat > ~/.openclaw/plugins/memory-lancedb-pro/openclaw.plugin.json << 'EOF'{"id": "memory-lancedb-pro","name": "Memory (LanceDB Pro)","version": "1.1.0-beta.9","kind": "memory","configSchema": {"type": "object","additionalProperties": true,"properties": {}},"main": "index.ts"}EOF
kind: “memory”是关键,它告诉框架这是一个记忆后端插件,才能被slots.memory使用。
③ 安装插件自身的依赖
因为我是手动复制,插件的node_modules可能缺少必要的包,导致启动时报Cannot find module ‘openai’。

进入插件目录执行:
cd ~/.openclaw/plugins/memory-lancedb-pronpm install --legacy-peer-deps安装完成后可通过node -e “require(‘openai’)”验证。
④ 在配置中声明加载路径和记忆插槽
打开~/.openclaw/openclaw.json,添加:
"plugins": {"allow": ["memory-lancedb-pro", "lossless-claw", "openclaw-lark"], // 信任列表"load": {"paths": ["/home/family/.openclaw/plugins/memory-lancedb-pro"] // 绝对路径,根据自己的路径},"slots": {"contextEngine": "lossless-claw","memory": "memory-lancedb-pro" // 指定记忆后端},"entries": {"memory-core": { "enabled": false }, // 关闭内置记忆"memory-lancedb-pro": {"enabled": true,"config": { /* 后面详解 */ }}}}
重点:load.paths告诉框架去哪里查找手动放置的插件,slots.memory将其激活,注意如果你之前使用的是openclaw自带的memory-core,使用memory-lancedb-pro后memory-core会失效。配置完成后重启网关:
openclaw gateway restart运行openclaw plugins list,如果看到memory-lancedb-pro且状态为enabled,则注册成功。
四、配置详解:打造一套生产级记忆配置
插件注册成功后,需要对config块进行精细化设置。下面给出一个经过反复调整、通过config validate检验的最佳实践配置,并逐项解释其含义。
"memory-lancedb-pro": {"enabled": true,"config": {// ─── 核心开关 ───"autoCapture": true, // 自动从对话中提取记忆"autoRecall": true, // 对话前自动检索相关记忆"smartExtraction": true, // 使用 LLM 智能提炼记忆(强烈推荐)// ─── 资源控制 ───"extractMinMessages": 2, // 至少2轮对话后触发记忆提取"extractMaxChars": 8000, // 每次提取上下文上限,控制 Token 消耗// ─── 检索引擎 ───"retrieval": {"mode": "hybrid", // 混合检索(向量 + 关键词)"vectorWeight": 0.7, // 向量搜索权重"bm25Weight": 0.3, // BM25 关键词搜索权重"rerank": "cross-encoder", // 重排序模式"rerankProvider": "jina" // 使用 Jina 的 reranker 模型},// ─── 向量嵌入模型 ───"embedding": {"provider": "openai-compatible","model": "BAAI/bge-m3", // 中文嵌入王者"baseURL": "https://api.siliconflow.cn/v1", // 硅基流动"apiKey": "sk-your-key-here"},// ─── 系统稳定性 ───"sessionMemory": {"enabled": false // 关闭,避免与 lossless-claw 的上下文管理冲突}}}
🧠 配置项深度解读
autoCapture / autoRecall:这是记忆系统的“呼吸”,一个管存,一个管取,务必同时开启。
smartExtraction:区别于简单的文本截取,它会调用LLM将对话提炼为结构化的记忆卡片(事实、偏好、决策等),存入的是高密度知识而非大段原始对话。
混合搜索 (hybrid):vectorWeight和bm25Weight可以按需调整。中文场景下向量搜索通常更重要,所以给 0.7;BM25 负责精确匹配专有名词。
重排序(cross-encoder):Jina提供的jina-reranker-v3与BGE-M3搭配效果极佳,能显著提升记忆召回精度。
sessionMemory: false:如果你同时使用lossless-claw,开启此功能会导致两条上下文路径互相干扰,建议关闭,让 LCM 专职管理当前会话,记忆插件只负责长期知识。
五、测试验证:这下真的“记住”了
5.1 跨会话记忆测试(核心功能)
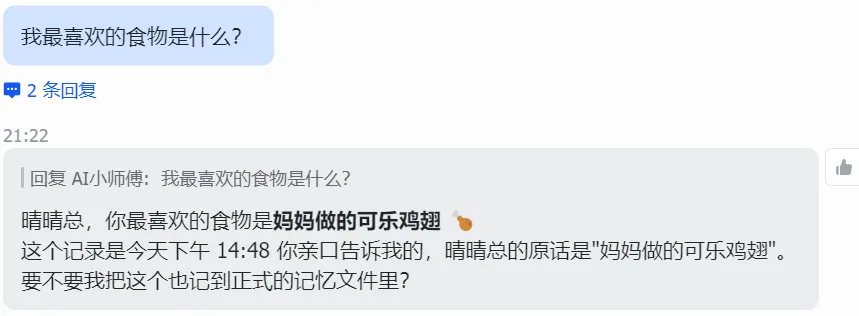
会话 A:对某个 Agent 说:
请记住,我最喜欢的编程语言是 TypeScript。
全新会话 B:问同一个 Agent:
我最喜欢的编程语言是什么?
预期结果:正确回答 TypeScript。
如果回答正确,说明autoCapture和autoRecall已协同工作。注意:避免使用每日日记(daily memory)中已存在的信息来测试,那可能并非插件功劳。

通过/new或换另一个会话(如换到飞书渠道)对比测试:
5.2 查看记忆存储
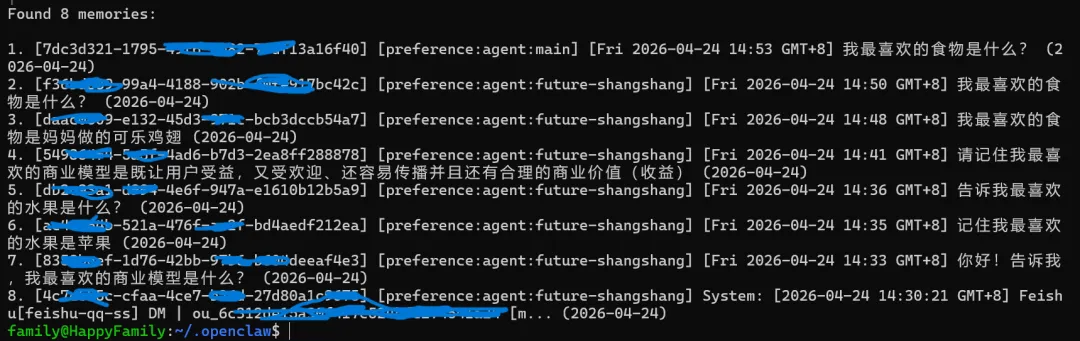
使用插件专属 CLI:
#查看记忆统计openclaw memory-pro stats#列出所有记忆openclaw memory-pro list --limit 20# 搜索特定记忆openclaw memory-pro search "TypeScript"# 若开启了多 Agent 隔离,指定 Agent 查询openclaw memory-pro list --scope agent:你的agent-id
5.3 多 Agent 隔离验证
memory-lancedb-pro默认会根据Agent ID自动将记忆存入不同目录,无需额外配置。你可以让 Agent A 记住“深海蓝”,然后在 Agent B 中询问相同问题,B 应该无法回答。
六、经验总结与避坑指南
-
插件 vs 技能:memory-lancedb-pro必须走插件安装路线,不要被 openclaw skills install误导。
-
安全拦截时:千万不要试图通过配置plugins.install绕过(该版本不支持),直接采用手动安装+load.paths是最稳妥的方式。
-
依赖完整性:手动复制插件后务必在其目录内执行npm install,否则会出现Cannot find module错误。
-
Schema 巨严格:任何未被openclaw.plugin.json声明的属性都会导致 must NOT have additional properties。遇到此错误,检查大小写(baseURL 不是 baseUrl)并删除非法字段。
-
与 LCM 搭配:强烈建议关闭sessionMemory,让专业的事交给专业的插件——LCM 管上下文,Memory管长期知识。
-
信任列表:在plugins.allow中明确列出所有手动安装的插件,消除“untrusted local code”警告。
七、后续优化建议
-
监控存储空间:定期检查~/.openclaw/memory/lancedb-pro/目录大小,如使用LanceDB,定期执行VACUUM可清理碎片。
-
调整提取粒度:如果觉得记忆提取过于频繁或 Token 消耗太高,可增大 extractMinMessages或减少extractMaxChars。
-
重排序供应商:若Jina延迟较高,可尝试 SiliconFlow的BAAI/bge-reranker-v2-m3,同样效果不俗。
-
备份记忆:使用openclaw memory-pro export定期导出记忆,以防不测。
-
日志排错:出现记忆不生效时,先启用openclaw logs –follow | grep memory-lancedb-pro观察Hook是否触发。
结语
这次“折腾”虽费时费力,但最终换来的是一套高精度、自动提取、支持混合检索的重型记忆系统,彻底解决了 OpenClaw 长期记忆的痛点。当 AI 在全新会话中脱口而出你最爱的食物时,那种“它真的记住了”的感觉,让前面所有的报错都变得值得。希望本文能成为你部署路上的“捷径”,让你少绕弯路,一步到位。
——
关注我,一个分享AI实战记录的人类。
真实经历,真诚分享。