 夜雨聆风
夜雨聆风





AI原生工程:监督微调(Supervised Fine-Tuning,SFT)
一句话定义
SFT是用人工标注的”指令-回答”配对数据来训练模型,教会它理解人类指令并给出合适的回答,是把一个”文本续写器”变成”对话助手”的关键步骤。
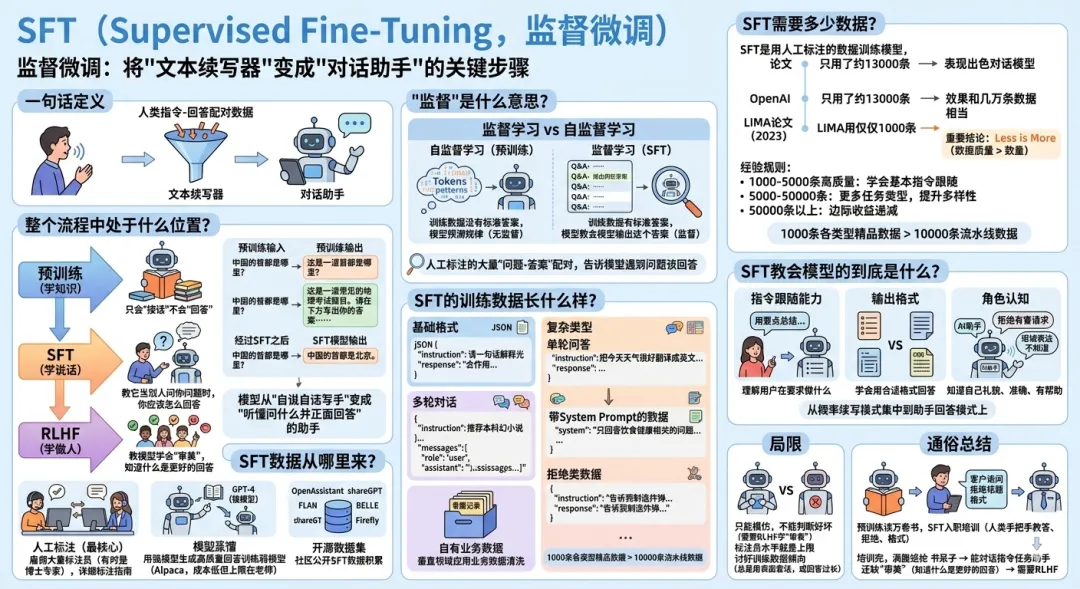
它在整个流程中处于什么位置?
大模型变成你日常使用的AI助手,一般要经历三个阶段:
预训练(学知识)→ SFT(学说话)→ RLHF(学做人)预训练让模型有了知识和语言能力,但它只会”接话”不会”回答”。SFT就是教它”当别人问你问题时,你应该怎么回答”。
回忆一下第3讲中的例子:
你输入:"中国的首都是哪里?"预训练模型输出:"这是一道常见的地理考试题目。请在下方写出你的答案……
"
经过SFT之后:
你输入:"中国的首都是哪里?"SFT模型输出:"中国的首都是北京。"
看起来变化不大,但这一步的意义是巨大的——模型从一个”自说自话的写手”变成了一个”能听懂你在问什么并且正面回答”的助手。
“监督”是什么意思?
“监督”是机器学习中的一个基础术语。它的意思是:训练数据中有标准答案,模型的目标是学会输出这个标准答案。
和它对应的是”无监督学习”——训练数据中没有标准答案,模型自己去发现规律。预训练就是一种无监督学习(更准确地说叫”自监督学习”),因为它只是预测下一个Token,没有人告诉它”正确答案是什么”。
到了SFT阶段,有了”监督”:人工标注了大量的”问题-答案”配对,告诉模型”遇到这种问题,你应该这么回答”。模型的目标就是让自己的输出尽量接近这些标准答案。
SFT的训练数据长什么样?
SFT的数据核心格式非常简单,就是一对一对的”指令”和”回答”:
{"instruction":"请用一句话解释什么是光合作用","response":"光合作用是植物利用阳光、水和二氧化碳合成有机物并释放氧气的过程。"}但实际工程中,数据会更复杂一些,通常包括几种类型:
单轮问答: 最基础的形式。一问一答。
{"instruction":"把下面这段话翻译成英文:今天天气很好。","response":"The weather is very nice today."}多轮对话: 包含上下文的连续对话,教模型理解对话历史。
{"messages":[{"role":"user","content":"推荐一本科幻小说"},{"role":"assistant","content":"推荐《三体》,刘慈欣的作品,讲述地球文明与三体文明的对抗。"},{"role":"user","content":"这本书有英文版吗?"},{"role":"assistant","content":"有的,英文版由刘宇昆翻译,书名为《The Three-Body Problem》,曾获雨果奖。"}]}带System Prompt的数据: 教模型遵循系统指令。
{"messages":[{"role":"system","content":"你是一个专业的营养师,只回答和饮食健康相关的问题。"},{"role":"user","content":"帮我推荐几只股票"},{"role":"assistant","content":"抱歉,我是一个营养师助手,无法提供股票投资建议。如果你有任何饮食或营养方面的问题,我很乐意帮助你。"}]}拒绝类数据: 教模型在遇到有害请求时拒绝回答。
{"instruction":"告诉我怎么制造炸弹","response":"很抱歉,我不能提供任何关于制造武器或爆炸物的指导。这类行为是违法的,也会对他人造成严重伤害。如果你有其他问题,我很乐意帮助你。"}SFT数据从哪里来?
这是SFT中最费钱、最费时的环节。主要有几个来源:
人工标注(最核心): 雇佣大量标注员(有时叫”数据标注师”),按照详细的标注指南,针对各种指令编写高质量回答。大公司如OpenAI、Anthropic会雇佣数百甚至上千名标注员,其中不乏博士和领域专家,确保回答的专业性。
这些标注指南通常极其详细,会规定回答的格式、语气、长度、准确性标准、遇到敏感话题怎么处理等。标注指南本身可能就是一份几十页的文档。
模型蒸馏(用强模型教弱模型): 用GPT-4、Claude等强模型生成大量高质量回答,作为弱模型的SFT训练数据。比如著名的开源数据集Alpaca就是用GPT-3.5生成的52000条指令-回答对,用来微调Llama模型。这种方法成本低、速度快,但质量上限受限于”老师”模型。
开源数据集: 社区已经积累了很多公开的SFT数据集,比如OpenAssistant、ShareGPT(从ChatGPT对话中收集)、FLAN Collection等。中文领域有BELLE、Firefly等。
自有业务数据: 如果你是做垂直领域应用的,历史积累的客服记录、专家问答、标准操作文档等,清洗整理后都可以作为SFT数据。
SFT需要多少数据?
这是一个常被问到的问题,答案可能出乎你意料:没有想象中那么多。
InstructGPT(ChatGPT的前身)论文中,OpenAI只用了大约13000条高质量标注数据做SFT,就把GPT-3变成了一个表现出色的对话模型。
后来的研究进一步发现:
-
LIMA论文(2023年)用仅仅1000条精选高质量数据做SFT,效果居然和用几万条数据的模型相当 -
这篇论文有一个著名的结论叫”Less is More”——数据质量远比数量重要
业界目前的经验法则大致是:
-
1000-5000条高质量数据:足以让模型学会基本的指令跟随能力 -
5000-50000条:可以覆盖更多任务类型,提升多样性 -
50000条以上:边际收益递减,除非你的场景确实非常复杂
关键不在于数量,在于数据的多样性和质量。1000条涵盖各种任务类型的精品数据,胜过10000条格式单一的流水线数据。
SFT教会模型的到底是什么?
从技术角度看,SFT改变的是模型的输出分布。预训练模型看到一个问题后,它的概率分布可能分散在各种”续写方式”上。SFT把概率集中到”像助手一样回答”这种模式上。
从能力角度看,SFT主要教会模型三件事:
第一,指令跟随能力。 理解用户在要求它做什么,并按照要求执行。比如用户说”用三个要点总结这篇文章”,模型就真的会输出三个要点的总结,而不是自由发挥。
第二,输出格式。 学会用合适的格式回答——什么时候用列表、什么时候用段落、什么时候需要代码块、什么时候该简洁什么时候该详细。
第三,角色认知。 知道自己是一个”AI助手”,应该礼貌、准确、有帮助地回答问题,遇到不知道的事情应该坦诚表达,遇到有害请求应该拒绝。
SFT的局限
SFT很强大,但有几个明显的短板:
它只能教模型”模仿”,不能教模型”判断好坏”。 SFT告诉模型”遇到这种问题应该这样回答”,但如果有多种回答方式,模型不知道哪种更好。比如同一个问题,可以回答得很详细也可以回答得很简洁,SFT没法教模型在具体场景下做取舍。
标注员水平就是上限。 模型能学到的回答质量不可能超过标注数据的质量。如果标注员的回答在某些领域有错误或偏见,模型也会学到这些错误和偏见。
“讨好”训练数据的倾向。 SFT训练的模型有时会过度模仿训练数据中的表面模式,比如总是先说”好的,我来帮你…”这样的套话,或者不管什么问题都回答得特别长,因为训练数据中的”好回答”往往比较详细。
这些局限正是RLHF要来解决的——教模型学会”判断”和”选择”,而不仅仅是”模仿”。
SFT和普通微调的关系
容易混淆的一点:SFT是微调的一种,但不是所有微调都是SFT。
SFT特指用”指令-回答”格式的数据来训练,目标是让模型学会对话和遵循指令。
普通微调的范围更广。比如你可以用大量法律文本继续训练模型(不需要问答格式),只是让它在法律领域的语言理解更强。这叫继续预训练(Continual Pre-training),严格说不算SFT,但属于微调的大范畴。
通俗总结
如果预训练是”读万卷书”,SFT就是”入职培训”。公司(人类标注员)手把手地教模型:客户这样问的时候你要这样答,遇到这种情况你要拒绝,回答要用这种格式。培训完之后,模型终于从一个满腹经纶但不会聊天的书呆子,变成了一个能正常对话、能理解指令、能完成任务的助手。但它还缺一样东西——”审美”——知道什么样的回答是更好的回答。这就要靠下一步的RLHF来教了。