 夜雨聆风
夜雨聆风





我如何用 OpenClaw 搭建自动化工作流:踩坑实录与实战经验
这不是一篇安装教程。这是一篇用真金白银的时间换来的踩坑总结——连续跑了 20 多天,中间崩溃过无数次,现在终于稳定了。
先说结果:我在做什么
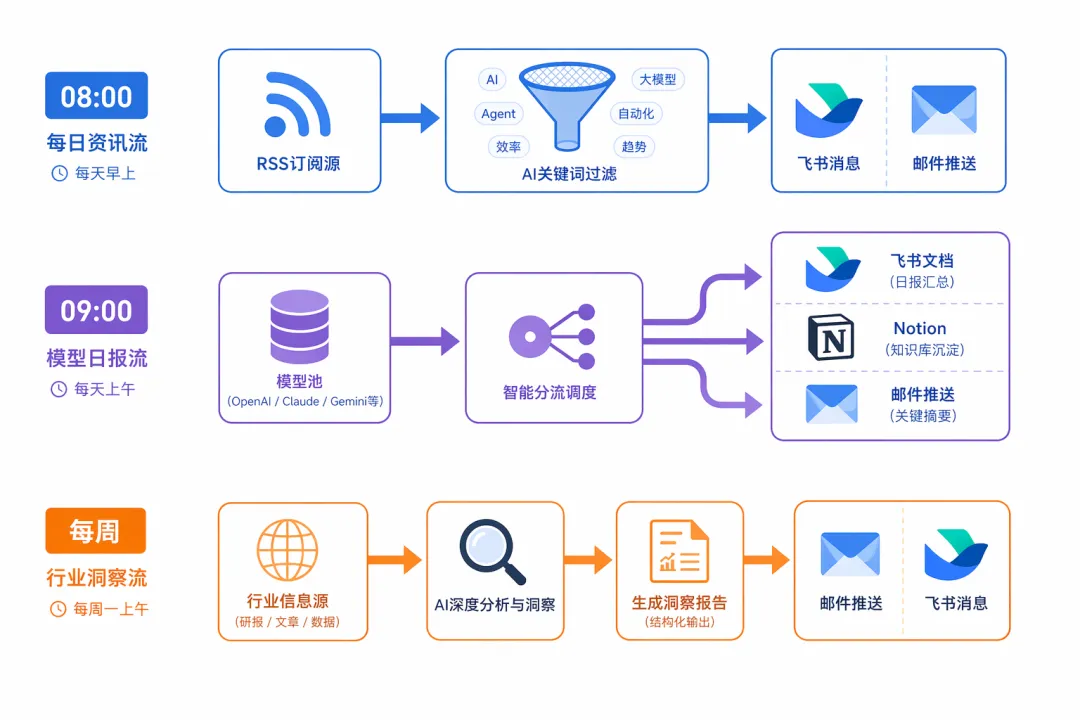
每天早上 8 点,我会在飞书收到一份 AI 资讯日报,10 条新闻 + 深度洞察。
每天早上 9 点,我会在飞书收到 3 个思维模型,每个包含核心洞察、定义、实践方法和经典案例,推送飞书多维表格管理内容素材库,所有数据自动同步更新。
每周,我会自动生成一份家服务行业的深度研究报告,发送到邮箱。
…
所有这些,都是自动运行的。我只负责确认质量,不需要手动操作任何一步。
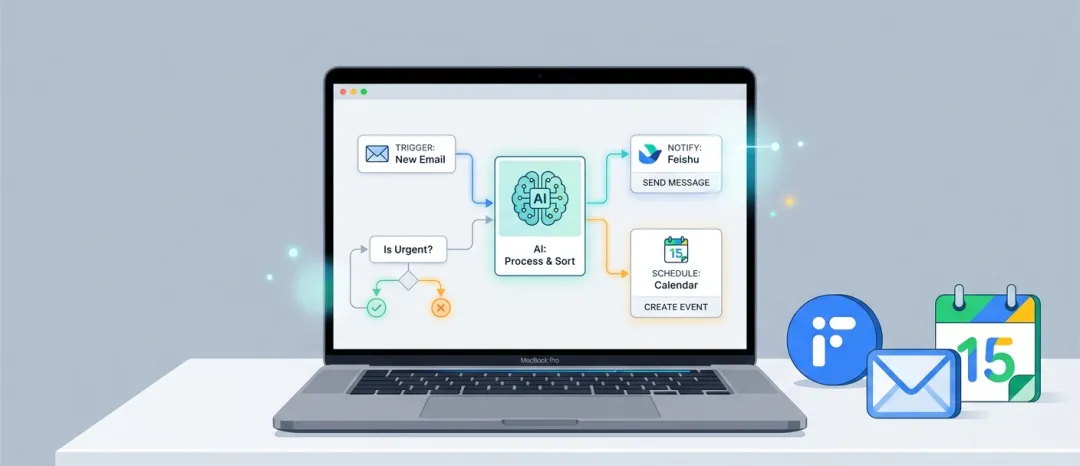
踩坑实录:7 个让我浪费两天的真实问题
坑1:Python 环境不一致,脚本集体罢工
症状:所有定时任务突然全部失败,日志里只有一行:
env: node: No such file or directory原因:系统默认的 Python 3.9 有 SSL/LibreSSL 握手问题,Cron 环境下 PATH 变量不完整,Node 和 Python 都找不到。
解决:在脚本里用绝对路径指定 Python 3.13:
# 错误写法:依赖系统 PATHsubprocess.run(["python3", "script.py"])# 正确写法:绝对路径subprocess.run(["/usr/local/bin/python3.13", "script.py"])教训:Cron 任务一定要用绝对路径,永远不要依赖
which python或环境变量 PATH。
坑2:飞书 API “Invalid request URL” —— 查了半天是 JSON 编码问题
症状:
Invalid request URL错误,但 API 地址明明是对的。原因:Python 把中文内容转成 JSON 时,中文字符被 Unicode 转义成了
\uXXXX格式,某些 HTTP 客户端处理异常导致 URL 构建失败。解决:用 bash + curl 代替 Python 调用 API:
curl -X POST "https://api.notion.com/v1/databases/..." \-H "Authorization: Bearer $NOTION_KEY" \-H "Content-Type: application/json" \-d "$(cat << 'JSONEOF'{"properties": {"名称": {"title": [{"text": {"content": "系统思维"}}]}}}JSONEOF)"教训:API 调试优先用 curl 直接测,能拿到原始错误信息再写 Python。Python 的 JSON 编码问题很难排查。
坑3:Notion 推送失败 4 小时,根因是字段类型不匹配
症状:Notion 数据库 schema 里有一个
链接字段,类型是 URL,但传空字符串""时报错:body.properties.链接.title should be defined
排查过程:
先怀疑数据库 ID 错了
又怀疑 API Key 有问题
最后才发现是空 URL 字符串导致 schema 校验失败——Notion 把空字符串当成 title 类型处理了
解决:空字段直接省略不传,不要传空字符串:
properties = {"名称": {"title": [{"text": {"content": model_name}}]},}# 链接字段:空就不传,不要传 ""if link_url:properties["链接"] = {"url": link_url}教训:第三方 API 的 schema 校验很严格,
null和""是两回事。
坑4:RSS 源有时效,但抓回来发现内容空了
症状:RSS feed 显示有更新,但抓回来只有几十个字。
原因:RSS 的
<description>字段经常只是摘要,不是正文。有些 feed 干脆只有标题。解决:建立双重验证机制——抓回来的内容少于 100 字就触发补充抓取:
[2026-04-21 08:46:03] ⚠️ 热力学第二定律.why 内容偏短(31字),尝试补充...[2026-04-21 08:46:45] ✅ 热力学第二定律 - 创建成功
教训:内容质量不能只看「是否成功抓取」,要验证「是否抓到了实质内容」。
坑5:并发抓取被目标网站 rate limit
症状:连续几天大量超时,Wikipedia 返回 503。
原因:用 ThreadPoolExecutor 并发 10 个线程抓取,触发了网站的防爬机制。
解决:三招组合:
限制并发数(最多 3 个线程)
加上随机延迟(
time.sleep(random.uniform(1, 3)))设置单请求超时(15 秒)
with ThreadPoolExecutor(max_workers=3) as executor:futures = {executor.submit(fetch_content, url): url for url in urls}for future in as_completed(futures, timeout=15):try:result = future.result()except TimeoutError:print(f"⚠️ 超时: {futures[future]}")教训:爬虫要讲武德,并发太高容易被封,礼貌比速度重要。
坑6:Cron 定时任务重复触发
症状:一天收到了两份思维模型日报,时间只差 10 分钟。
原因:手动触发了一次脚本,同时 Cron 定时任务也触发了,两个进程同时运行。
解决:加进程文件锁——同一时间只有一个实例能跑:
import fcntllock_file = open("/tmp/daily_task.lock", "w")try:# macOS 需要 LOCK_NB,否则会阻塞导致死锁fcntl.flock(lock_file.fileno(), fcntl.LOCK_EX | fcntl.LOCK_NB)except (IOError, OSError):print("另一个实例正在运行,退出")exit(0)教训:Cron + 手动触发容易重叠,进程锁是最后一道防线。
坑7:模型池耗尽导致定时任务空转
症状:Cron 任务每天都触发,但模型越推越少,最后连续好几天推送的模型是重复的。
原因:模型池只有 16 个,每天 3 个,不到一周就用完了。脚本没有自动补充机制。
解决:设置池容量阈值,低于阈值时触发自动扩充:
POOL_LOW_THRESHOLD = 9def check_and_expand_pool():available = get_unpushed_models(pool)iflen(available) < POOL_LOW_THRESHOLD:expand_pool_from_sources()扩充来源:Farnam Street Mental Models 索引页,自动解析模型名并加入池中。
教训:自动化任务必须有自我维护机制,不能只消费不补充。
现在的稳定架构
每天 08:00(Cron)→ AI资讯日报(ai-news-daily.py)→ 抓取 8 个 RSS 源(36kr / TechCrunch / VentureBeat / MIT / 机器之心 / 虎嗅 / Reddit / Product Hunt)→ AI关键词双重过滤(AI / 大模型 / Agent / 算力 / 芯片)→ 生成 10 条新闻 + 2 条洞察→ 发送邮件到 **@yeah.net→ 上传飞书文档每天 09:00(Cron)→ 思维模型日报(daily-thinking-models-v2.py)→ 从模型池选 3 个未推送的(不同领域)→ 每个模型:飞书文档 + Notion页面 + 邮箱→ 合并成一封邮件发送→ 自动刷新飞书目录导航页每周→ 行业研究报告(home-appliance-research.py)→ 抓取 8+ 个 RSS 源(Field Service News / Intercom Blog / IT之家 / 雷锋网)→ 生成深度行业报告→ 发送邮件 + 上传飞书知识库
飞书多维表格:用数据库的思维管理内容
我用
lark-baseSkill 操作飞书多维表格,作为结构化内容管理数据库:思维模型库:模型字段包括名称 / 领域 / 来源 / WHY / WHAT / HOW / EXAMPLE / 飞书URL / NotionURL
内容素材库:选题方向 / 标题草稿 / 素材链接 / 状态(待写/撰写中/已完成)
每次 AI 生成内容后,自动写入表格,人只需要在表格里审核和标注。表格就是 CMS,AI 是写入端,人是审核端。
工作区结构决定 AI 的表现
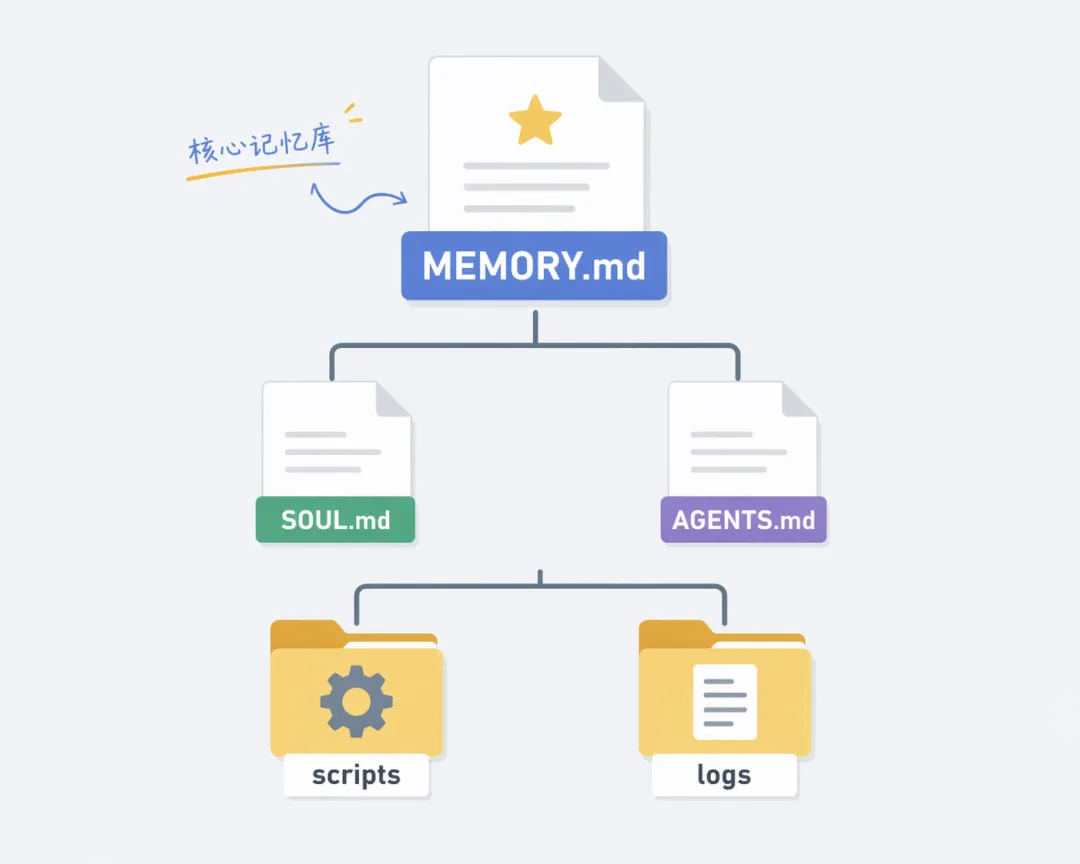
~/.openclaw/workspace/├── MEMORY.md # 长期记忆:用户偏好、项目状态、重要链接├── SOUL.md # AI 人设:高效精准、偶尔幽默、不废话├── AGENTS.md # 工作区规范:回复风格、禁止事项├── TOOLS.md # 本地工具配置:API Keys、路径、SMTP 配置├── scripts/ # 全部定时脚本(绝对路径调用)├── logs/ # 所有日志(追踪问题、复盘必备)└── temp/ # 临时文件,自动清理MEMORY.md 是最重要的文件。每次新会话,AI 先读这个。里面记录了飞书云盘重要文件夹、AI资讯日报的 RSS 来源、Notion 数据库 ID、当前出口 IP……
有了 MEMORY.md,AI 才能真正做到「认识你」,而不是每次都是从零开始。
如果重头来,我会怎么做
第一,先把工作区结构设计好
正确顺序:
设计工作区目录结构
写 MEMORY.md(记录用户信息)
写 SOUL.md(定人设)
写 AGENTS.md(定规范)
最后才安装 Skill
第二,先跑通最小闭环,再迭代
第一个版本只做一件事:每天早上给我发一条「今天有什么安排」。
跑通之后才逐步加:天气 → 日历 → 资讯日报 → 思维模型 → 行业报告。
第三,日志要有三级
我现在每个脚本都有三级日志:
-
✅:正常运行完成 -
⚠️:可恢复异常(内容偏短、超时) -
❌:需要人工介入的失败

总结:OpenClaw 适合什么人
适合你,如果:
-
每天重复性信息收集/整理工作超过 30 分钟
-
使用多个 IM 工具(飞书 / 微信 / Telegram / Discord)
-
有一定技术动手能力,能写简单脚本
-
对数据隐私有要求,不想把所有东西交给第三方平台
不适合你,如果:
-
只需要一个 AI 对话工具(直接用 ChatGPT / Claude)
-
没有时间折腾,期望开箱即用
-
技术完全小白,改个配置都会出错
搭 OpenClaw 的成本:大约 3-5 小时初始配置 + 持续调优。
真正值钱的不是 AI 能做什么,而是你把它接进了多少自动化流程。