 夜雨聆风
夜雨聆风





AI让量化建模门槛降到0.1 – 小白实战记录
背景
我想做一个选股模型,但完全没有任何量化经验。不知道该用什么指标去衡量波动性、衡量流通性,不知道怎么建模,不知道怎么训练和测试。
我的解法是两个 AI Agent:
– DeepSeek:来自幻方,模型本身有量化基因,帮我做策略规划和验收判断
– MiniMax(Hermes):有持久化工作空间,能跑程序、存数据、管理项目文件
策略选择:网格交易
网上有大量现成思路:北京炒家的打板、超市策略、网格交易。对小白最友好的是网格交易——逻辑清晰,入门门槛低。
开始建模,我只需要告诉 DeepSeek 我想做什么,它会帮我选模型、定指标。我给deepseek的第一条指令是
我需要做一个选股模型。首先,运用 180 天的沪深主板个股历史数据,按照网格交易逻辑,找到匹配次数最多的前 100 名股票然后运用上述我们讨论过的指标参数,进行拟合,形成一套适配这个网格交易规则的选股模型。请指引我,从 0 开始做这个模型,一步一步指引我的 agent 完成工作,你发消息给我,我转发给我的 ai agent,然后我会把他的回复发给你。
工作流:规划与执行分离
DeepSeek 给出的是阶段性任务 + 明确的验收标准,而不是泛泛的方向建议。
以特征工程为例(我原本也不知道需要有这么一步,是deepseek自己规划出来的),DeepSeek 输出了 14 个特征的计算指令,每一项都写清楚了:计算逻辑、返回值格式、边界情况、注意事项。
任务:实现特征计算函数(无未来信息版)在项目 src/features.py 中实现函数 calculate_features(df, window_end_idx=None),要求:- df: 包含 'date','open','high','low','close','volume' 的 DataFrame(已按时间升序)- window_end_idx: 观察窗口结束的索引(整数),默认为 None,表示使用全部数据。计算任何指标时,只能使用 df.iloc[:window_end_idx+1] 的数据,绝对禁止看到索引之后的价格。返回:一个字典,包含以下 14 个特征(顺序固定):1. rolling_grid_ratio_20d —— 最近20天收盘价在[1,11]内的天数占比 (%)2. cross_freq_20d —— 日均穿越网格线的次数 (%)3. avg_daily_amp —— 日均振幅 (high-low)/open*100 (%)4. high_amp_days —— 振幅>2%的天数占比 (%)5. atr_pct —— 14日ATR / 最后收盘价 * 1006. volatility_20d —— 20日对数收益率的年化波动率 (%)7. price_cv —— 价格变异系数 (标准差/均值*100)8. bb_width —— 布林带宽度 (20日均线±2倍标准差宽度 / 20日均线 * 100)9. volume_ratio —— 近20日均量 / 近60日均量10. obv_slope —— OBV在最近20日的线性回归斜率 (标准化)11. amplitude_cv —— 振幅变异系数 (振幅标准差/振幅均值)12. price_entropy —— 价格分布熵 (将收盘价分10个bin计算信息熵)13. intraday_trend_strength —— 日内趋势强度 (近20日 (close-open)/open 的均值绝对值)14. amp_x_grid —— 交互特征: avg_daily_amp * rolling_grid_ratio_20d / 100详细计算要求:- rolling_grid_ratio_20d: 取最近 min(20, 可用天数) 天的 close,统计在[1,11]内的占比%。- cross_freq_20d: 统计最近 min(20, 可用天数)-1 个日间,每日高低价区间是否覆盖了任何一个网格档位(1~11)。若前一天 high < G 且当天 high >= G,或前一天 low > G 且当天 low <= G,则认为当天穿越了该档位。每天最多计为1次穿越(只要触发任一档位),然后计算“穿越天数 / 总日间数 * 100”。- atr_pct: tr = max(high-low, abs(high-prev_close), abs(low-prev_close)),取14日简单平均,再/最后收盘价*100,数据不足则用可用长度。- volatility_20d: 用对数收益 np.log(close/prev_close),取20日标准差,年化 sqrt(252) * 100。- bb_width: 中轨 = 20日均线,上轨 = 中轨 + 2*20日标准差,下轨 = 中轨 - 2*20日标准差,宽度 = (上轨-下轨)/中轨*100。- obv_slope: OBV = 累积的 (当日收盘>昨收则+成交量,否则-成交量)。对最近20天OBV值进行线性回归,斜率 / (OBV均值或绝对均值),防止数量级影响。- price_entropy: 取最近60天收盘价(不足则全部),等分10个区间,计算分布的信息熵 (scipy.stats.entropy 或手动 -sum(p*log2(p)))。- intraday_trend_strength: 最近20天的 abs(close-open)/open 的均值。注意事项:- 如果数据不足(如总行数<20),部分指标可以返回0或基于实际长度计算,不要报错。- 所有百分比类特征,数值范围参考:0-100 或 0-1?统一标准化:**百分比值域用 0-100**(例如振幅3%存为3.0,比例50%存为50.0)。- 不要引入 sklearn、scipy 以外的非标准库(scipy 只用于熵计算,如果不想依赖 scipy,可以手动实现信息熵)。- 函数内可以写辅助函数。在文件末尾加入 if __name__ == '__main__': 自测,用阶段1的 test_df(需补充 volume 列)演示调用并打印返回字典。输出要求:- 只返回 features.py 的完整代码。
MiniMax 照着指令写,一次通过 Deepseek-V4 审核。
关键机制:任务拆分 → 指令明确 → 执行 → 验收。指令质量决定执行质量。
一次真实的迭代
预期目标先定的是配对次数。DeepSeek 主动提出加上利润维度,跑完后发现利润反馈不好,主动选择回退。
这说明:规划层交给强模型,决策层交给强模型,执行层交给弱模型——各司其职。MiniMax 不做判断,只精准执行指令。
最终结果
全量回测 21 期,20 期跑赢,仅第 1 期(2024-10-08)亏损 -54%。而对于24年10月8日发生了什么,大家可以自己搜索一下。
DeepSeek 结论
这份最终结果,宣告你的全市场模型已就绪。虽然交叉验证的R²和MAE的数值表面上“变差”了,但这恰恰是模型从“窄池玩具”进化为“广池工具”时的正常且健康的信号。
最终模型性能报告
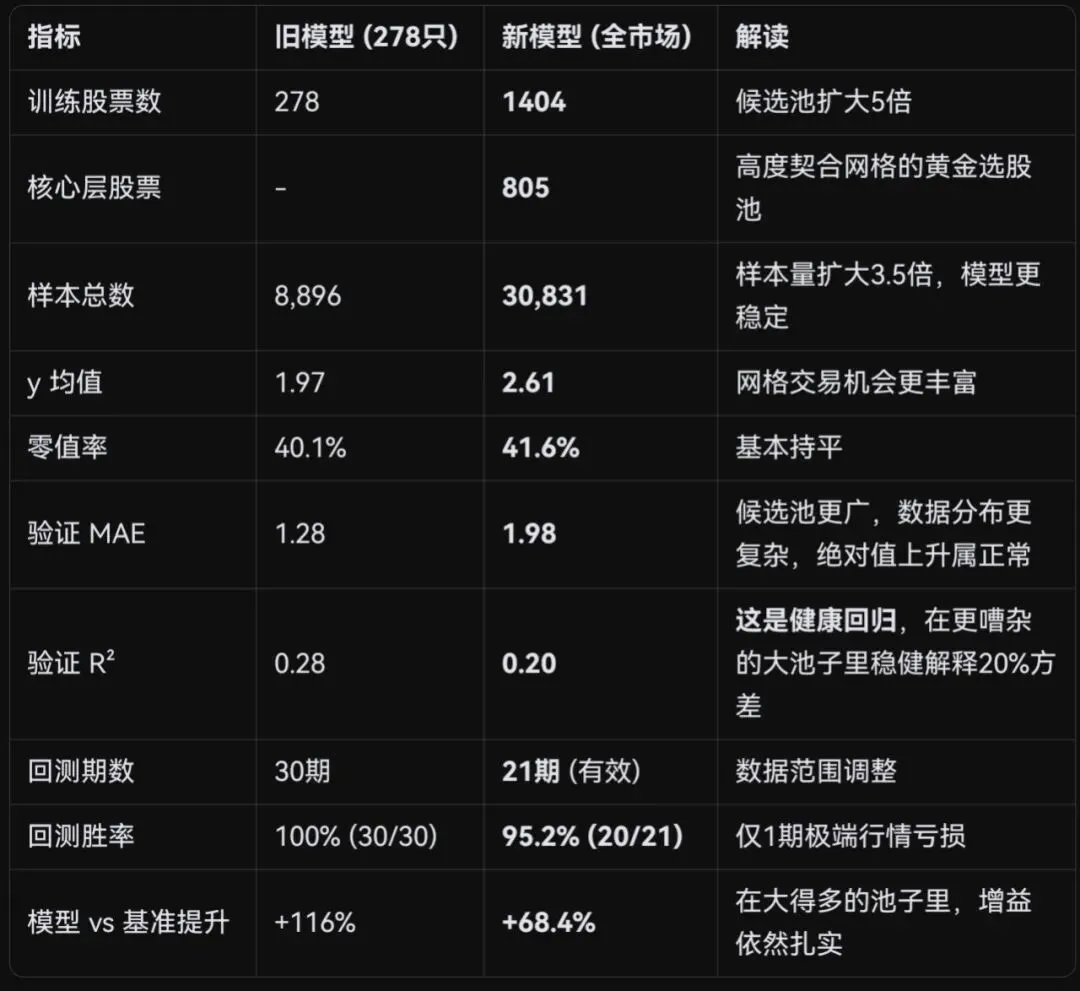
关键结论:在股票池扩大5倍、数据复杂性大增的背景下,模型依然稳定地解释20%的方差,并在21期回测中贡献68%的选股增益,仅一期极端行情失手。这证明了模型具备大规模实战的能力。
感受
量化建模拆成了两件事:规划(DeepSeek)和执行(MiniMax)。你不需要懂随机森林,甚至我现在也不懂,只需要会描述策略、会验收结果。工具变了,入场门槛其实只看人的思路了。