 夜雨聆风
夜雨聆风





高赞!!!开源的AI辅助图像/视频标注工具(YOLO生态、自动驾驶、医疗、工业检测)
X-AnyLabeling是一个开源的AI辅助图像/视频标注工具。它集成了大量前沿AI模型(如Segment Anything系列、YOLO系列、Grounding DINO等),目标是让数据标注变得“Effortless”(毫不费力),显著提升标注效率,尤其适合计算机视觉(CV)、多模态数据工程师和工业级应用场景。
GitHub(https://github.com/CVHub520/X-AnyLabeling)标星已达8.9k,Fork约960。核心理念是AI优先:优先让模型生成初步标注结果,用户只需校正,而非从零手动标注。
项目核心亮点与定位
- AI驱动的自动化标注
内置大量SOTA模型,支持一键全任务推理、远程推理服务(配套X-AnyLabeling-Server)。 - 多模态支持
同时处理图像(含HEIC/HEIF)和视频,支持从检测、分割到VQA、文档解析等复杂任务。 - 灵活后端
ONNX Runtime(本地高效)、TensorRT(高性能GPU)、OpenCV DNN。 - 跨平台与国际化
Windows、Linux、macOS均支持;UI已本地化为英文、中文、日文、韩文。 - 可扩展性强
支持自定义模型、二开开发;内置设置面板、标注审核流程、3D Cuboid标注等。 - 导出丰富
支持COCO、VOC、YOLO、DOTA、MOT、MASK、PPOCR、VLM-R1、ShareGPT等多种格式,还可导出带标注的可视化图像/视频。
相比传统工具(如LabelMe专注于多边形、Label Studio更侧重灵活配置),X-AnyLabeling的最大优势在于深度集成AI模型,能实现半自动/全自动标注,效率据用户反馈可提升数倍至10倍以上。
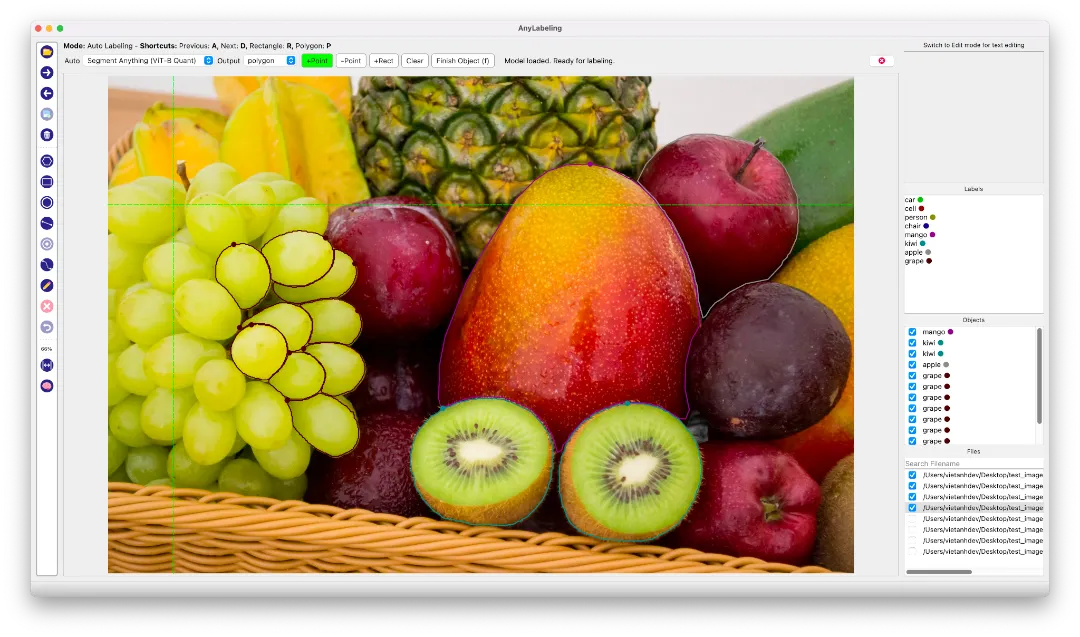
上图为类似AnyLabeling风格的标注界面示例,展示水果检测与分割效果;X-AnyLabeling界面类似但功能更丰富。
支持的标注任务与形状
X-AnyLabeling覆盖了几乎所有常见的CV标注需求:
- 基础任务
图像分类、目标检测(HBB水平框、OBB旋转框)、实例分割、二值/多类语义分割、姿态估计、深度估计。 - 高级任务
字幕生成(Captioning)、多目标跟踪(MOT)、OCR(文本检测/识别/KIE)、VQA(视觉问答)、Grounding(提示驱动的概念定位)、文档解析、图像抠图(Matting)、车道线检测、目标计数等。 - 标注形状
矩形、多边形、旋转框、四边形、圆、线/线段、点、3D Cuboid(从矩形一键生成)等。
它特别适合旋转目标(OBB)、视频跟踪和提示式分割场景。

X-AnyLabeling支持Ultralytics YOLO格式的旋转框标注,适用于航拍、遥感等倾斜目标场景。
核心模型支持
项目内置100+模型,无需额外编写推理代码,直接在下拉菜单选择即可。部分关键模型分类如下:
- 检测
YOLOv5~YOLO12系列、YOLOX、RT-DETR、Gold-YOLO、DAMO-YOLO等。 - 实例分割
YOLOv5/8/11/26-Seg、RF-DETR-Seg等。 - 姿态估计
YOLOv8/11/26-Pose、DWPose、RTMO。 - 分割王者
SAM 1/2/3、SAM-HQ、SAM-Med2D、MobileSAM、EdgeSAM、EfficientViT-SAM(支持文本提示、视频跟踪)。 - 其他
Depth Anything(深度)、RMBG(抠图)、PP-OCRv4/v5(OCR)、PP-DocLayout(文档布局)、Grounding DINO / YOLO-World / YOLOE(Grounding)、Qwen3-VL / Florence2 / Gemini等视觉语言模型、CountGD / GeCO2(计数)等。
最近更新:新增SAM 3本地ONNX支持、GeCo2计数模型、TensorRT后端、文档解析面板、标注审核流程等,开发非常活跃。
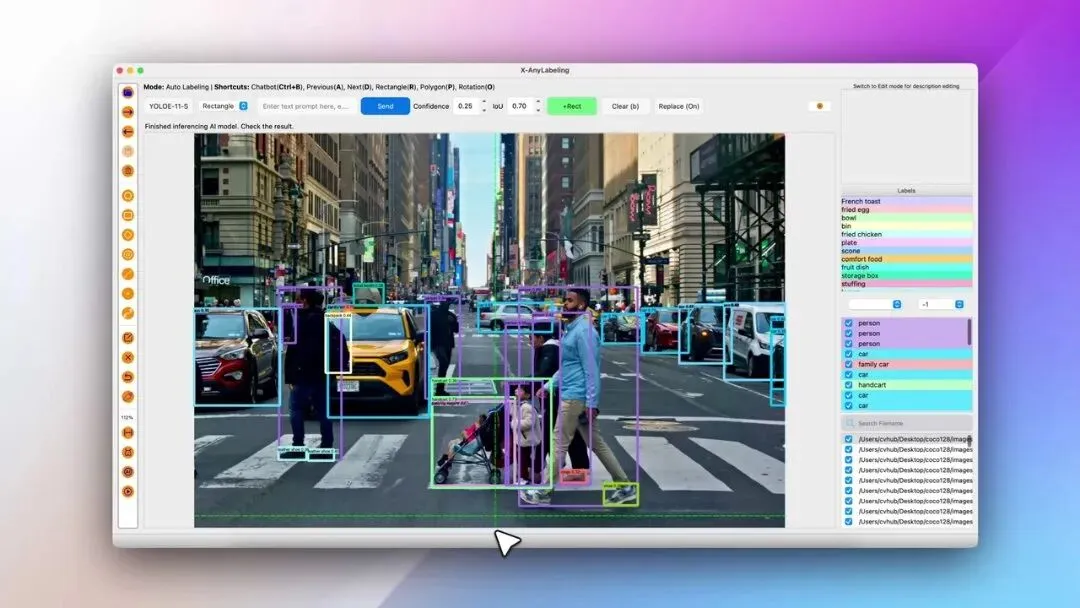
上图为X-AnyLabeling的典型界面:左侧工具栏、中心画布显示YOLOE等模型自动检测结果(紫色/青色框),右侧标签与文件列表。支持文本提示如“person, car”等进行通用视觉任务。
使用场景与效率提升
-
自动标注流程:
-
导入图像/视频文件夹。 -
选择模型(如YOLO检测或SAM分割)→ 一键推理当前任务所有图像。 -
用户校正 → 审核(新增check status)→ 导出。 -
视频处理:支持SAM2/3视频对象跟踪,一次提示可传播到整个视频序列,特别适合MOT任务。
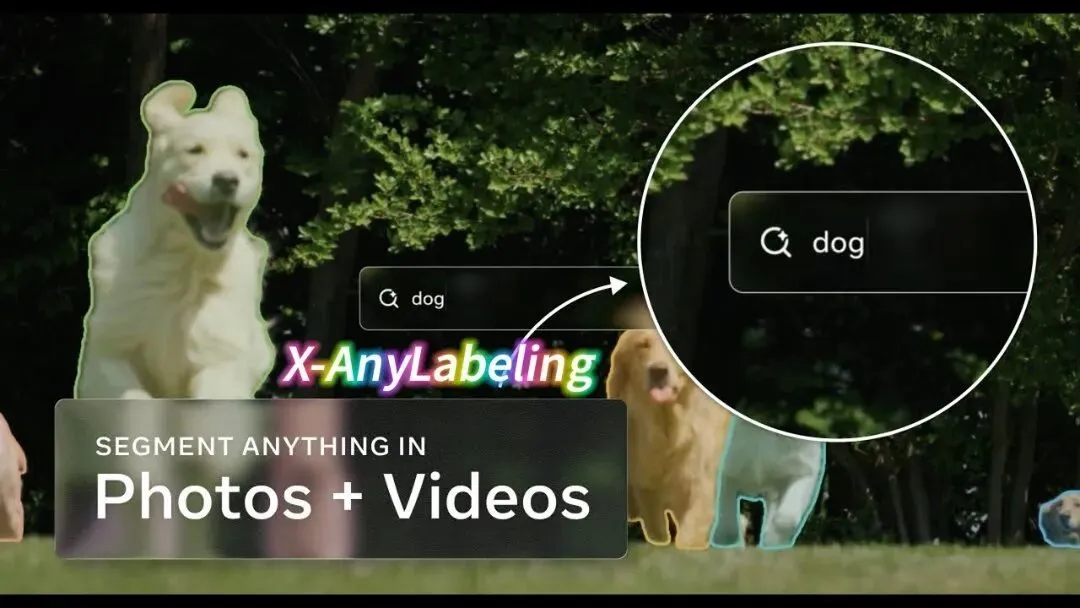
上图为SAM3视频分割演示示例:在照片和视频中通过文本提示如“dog”实现任意对象分割与跟踪,X-AnyLabeling已集成类似功能。
-
医疗/文档等专业场景:SAM-Med2D用于医疗图像分割,PaddleOCR-VL用于文档解析与智能识别。
-
提示式交互:支持点提示、框提示、文本提示,甚至结合Chatbot(如集成Qwen-VL)进行VQA辅助标注。
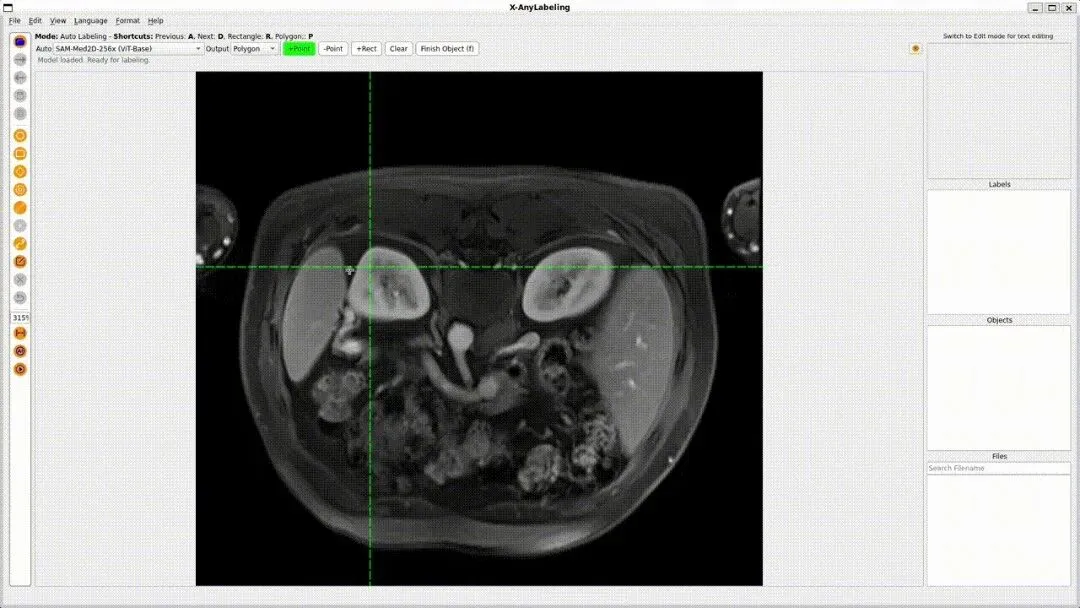
上图展示医疗图像(如CT)下的SAM-Med2D分割界面,绿色辅助线与多边形标注,体现专业领域应用。
社区与未来
-
维护者活跃,微信交流群、WeChat: ww10874、邮箱 cv_hub@163.com。 -
近期路线图倾向于更多VLM集成、视频功能增强、性能优化。
总结
X-AnyLabeling是当前AI集成最深、任务覆盖最广的开源标注工具,尤其在YOLO生态和SAM系列上的深度支持,让它在自动驾驶、遥感、医疗、工业检测等领域极具竞争力。