以金融为镜,铸军工之剑– JG软件工厂建设范式参考
写给 2026 年军工软件工厂技术决策者的范式参考——看清差异、找到镜鉴、落到自有体系 2026 年 1 月 1 日新《网络安全法》施行 + GJB 5000B 全面落地 + 国产化工具链成熟,三条压力线同时到了临界点——观望窗口正在关闭。 金融 DevSecOps 十个维度里,5 项可借鉴 / 4 项需审慎改造 / 3 项不可照搬(见图 1)——学什么、不学什么,决定了我们是在进步还是在变形。 美军(2025 年起更名 Department of War)2025 年发布 FY25–26 实施计划、2026 年 1 月发布新版 AI 战略,正在发动「AI-First」的第三轮加速;但我们离他们差的主要不是技术,是制度配套:合规模式、软件工厂建制、采购预算节奏——三件事全是「制度课」(见图 2)。 一家研究所把功能模块平均交付周期从23 天压到 9 天、缺陷密度下降 46%、合规取证从 3 周缩到 5 个工作日——速度上去了,缺陷没飞起来,合规反而更轻。 体系的内核是四句话:合规即代码、证据即产物、国产即底线、智能即延伸。一张矩阵图给出落地节奏——横轴 9 道工序(需求 → 设计 → 编码 → 构建 → 测试 → 发布 → 部署 → 运营 → 监控)、纵轴 3 期(筑基 / 强化 / 跃迁)、顶部三条横向轨道(安全 / 合规 / AI 贯穿全周期);AI 不是第五层,而是贯穿四层的第五根梁。 平台搭得起来,人跟不上一样落不了地。平台 / 安全 / MLOps 三类新岗位,不要新设三个新部门;考核分阶段(跑通 → 复用 → 数据);留住关键人比招到关键人更重要。——代码工厂是 DevSecOps 的上半场,模型工厂是下半场。 一个典型的工作日:某型号总体单位正在开一场持续两天的软件评审会,七类文档轮番会签,会议室里的总师已经喝掉了第四杯茶。同一天,某头部证券公司的交易系统完成了当日的第三次生产发布,两次灰度、一次全量,全程二十三分钟,工程师在屏幕前只做了最后一次点击。而就在同一天,一家互联网公司的代码仓里,由大模型生成的代码提交量已经超过人类工程师——它们,正在进入某条不知名的软件供应链。 三个场景,三种节奏,却并不属于三个不同的世界。它们之间的距离,正被监管、技术、人才的多条力线同时拉近。 一个问题也因此变得比以往任何时候都更紧迫:在涉密与国产化的双重约束下,我们院所的软件研制体系,是否到了重新审视的时候? 这个问题不是今天才有。但 2026 年,答案不能再拖。 如果说过去几年军工院所的软件研制体系还有「观望窗口」,那么 2026 年,这个窗口正在快速关闭。至少有三条压力线,在此刻交汇。 监管的压力线正在加码。2026 年 1 月 1 日,新修订的《网络安全法》正式施行,这是该法 2016 年立法以来的首次重大修订。关键信息基础设施运营者的违规处罚上限从 100 万元大幅提高到 1000 万元;人工智能治理首次正式入法,训练数据、算力设施、算法伦理、风险监测全部纳入监管视野。同日施行的还有《个人信息出境认证办法》。军工虽然不是「金融+互联网」意义上的典型关基运营者,但涉外协作、装备外贸、联合研制一旦触及数据出境,这些新规都是必须应对的现实约束。 行业内部的压力线来自标准升级的一线反馈。GJB 5000B 自 2024 年 3 月全面替代 5000A 之后,过程域要求更加细化,一线常见反馈是:「标准更严了,但工具支撑跟不上,评审负担反而加重了。」与此同时,新一代型号对软件定义能力的要求在快速上升——软件定义武器装备已是行业共识,但很多院所的软件交付模式还停留在「软件附属于硬件型号」的老路上,节奏完全跟不上顶层设计的变化。 技术可行性的压力线则在悄悄解锁。2025 年前后,国产化工具链的成熟度出现了实质性跨越:鲲鹏、飞腾、麒麟、达梦、东方通,加上若干国产 DevSecOps 平台,已经具备了企业级乃至型号级的可用性。换句话说,过去想做但做不了的事,现在第一次有了做成的基础条件。 压力不是从天而降,而是多条线同时到了临界点。在这样的时点上,继续沿用过去的软件研制节奏,不是「稳」,而是「欠账」。 国际坐标可以作为参照。美国国防部(2025 年正式更名为「Department of War / 战争部」,本文后续仍按中文惯例称「美国国防部」)从 2019 年发布《DoD Enterprise DevSecOps Reference Design》以来已迭代多版,2025 年 5 月发布《Software Modernization Implementation Plan FY25–26》,把「软件工厂 + 企业云 + 流程改革」做成两年期实施计划;2026 年 1 月又发布《Artificial Intelligence Strategy for the Department of War》——这是 4 年内第三份 AI 加速战略,核心信号是从「治理使能」转向「纪律性交付」,把 AI 作为「Wartime Speed」的第一块试验田。他们走过的弯路、踩过的坑,本质上回答的是和我们一样的问题:在强约束、强对抗、长生命周期的环境里,软件如何既快又稳。所以这件事不只是「中国军工要不要升级」,而是「全球军工都在升级,而且节奏在加快——我们升到第几代」。
双重镜像:金融经验 + 美军实践——两面镜子怎么照
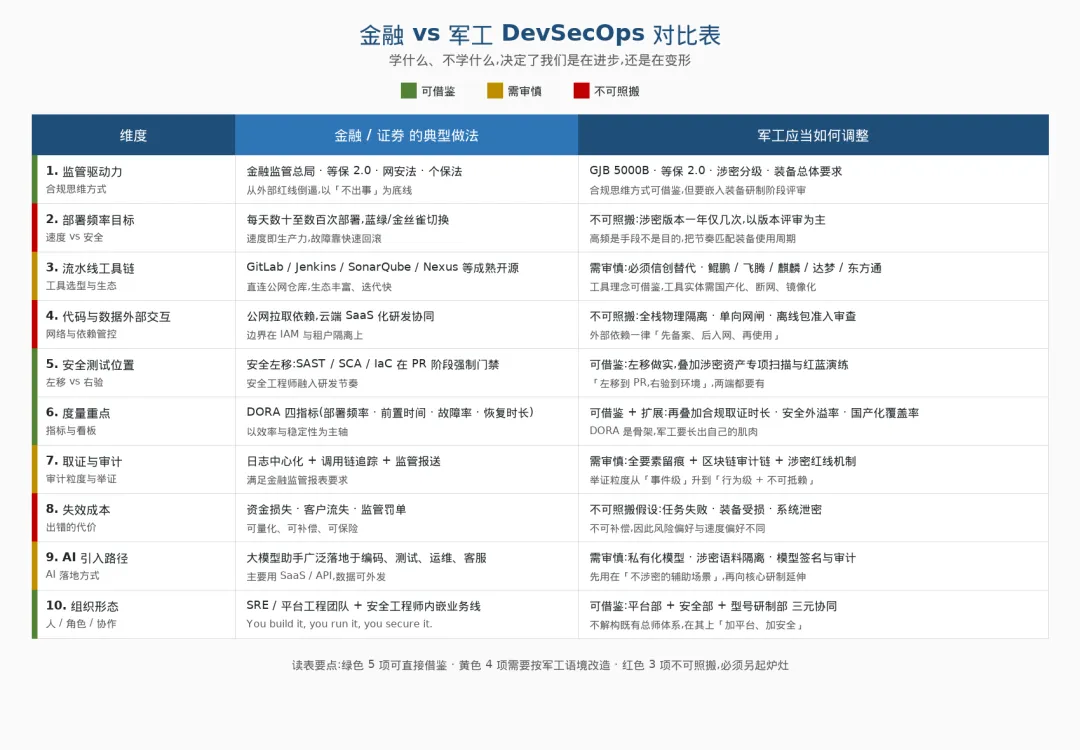
谈金融 DevSecOps,不是要让军工去「学券商」。但作为一个同样受强监管约束、同样追求高可靠性、同样经历了工具链国产化演进的行业,它的一些实践值得我们清醒地分类吸收。 可以明确分成三类:可借鉴的、需审慎改造的、不可照搬的。下面这张对比表把十个关键维度逐项分类,可以先看图再读正文,也可以直接截屏收藏。 图 1 · 金融 vs 军工 DevSecOps 十维对比:绿色 5 项可借鉴,黄色 4 项需审慎改造,红色 3 项不可照搬 一是流水线自动化与证据自动采集。头部金融机构已把 SAST、SCA、制品管控做成流水线默认动作,研发提交代码后,合规证据近乎「顺手」产生。军工的 GJB 过程域证据本来也是「必须要有」的,完全可以从「人工整理」转为「自动留存」,这对减轻评审负担是立竿见影的改变。 二是度量驱动的研发治理。金融头部用 DORA 四项指标(部署频率、前置时间、变更失败率、恢复时间)做持续改进,军工完全可以在自己的语境下建立「交付周期、缺陷密度、评审效率、证据完备性」的度量体系。 三是合规即代码的思想。把标准条款转化为可执行的检查规则,这不是金融的专利,而是一种方法论,军工用来承载 GJB 过程域的自动化落地同样有效。 一是持续部署。金融头部能做到小时级发布,军工型号软件不可能也不必要这么激进,但「持续集成」这一半是可行的,而且价值很大。 二是灰度与蓝绿发布。在涉密环境下几乎无法按互联网式实施,但「多型号、多版本并行测试」的思路是可以迁移的,这对新老型号并存的院所特别有用。 三是开源工具链。金融用的思路可以学,但具体产品必须替换为国产自主可控版本,选型标准要比金融更严——数据不出境、源码可审计、厂商可控,这三条不能让步。 一是生产环境直连开发。军工装备的「生产环境」是战场或装备平台,不存在也不允许互联网式的在线热更新。 二是开源优先策略。金融可以「严审基础上大量用」,军工必须坚持白名单和源代码审查,不能「拿来就用」。 三是工程师文化的高流动与外包。金融乐见人才流动和外协,军工必须守住人员稳定性与保密红线,这是一条底线,不是一个变量。 把同一张表放到 DoD 软件工厂(Platform One / Kessel Run / Black Pearl 等)的语境下重新填,会出现一些值得我们留意的差异。「可借鉴」的部分高度重合——SBOM 强制化、容器签名(Cosign / Sigstore)、SAST / DAST 默认化、DORA 度量,他们走在前面但思路同向,我们直接借鉴成本最低。「需审慎」与「不可照搬」的边界,他们划得更宽。比如「公网拉取依赖」,他们用 Iron Bank 镜像化的方式归到「需审慎」类——通过硬化容器仓库 + 持续 CVE 处置,把风险约束在平台一层;而我们目前只能整体归到「不可照搬」。再比如开源策略,他们是「严审基础上大量用」,我们则坚持白名单——这个差距背后不是技术问题,而是「合规闸门是不是已经做进体系」。 凡是他们敢「需审慎」的地方,往往说明他们已经把对应的合规闸门做成了平台默认能力,而不是靠每个项目人审守门。下面把美军这一面镜子展开看,先看他们建了什么(六类核心能力),再看哪些是真正决定他们「跑得动」的体制性安排,最后看清楚我们目前到底差在哪。 把 DoD 公开的体系文件——DoD Software Modernization Strategy(2022)与DoD Enterprise DevSecOps Reference Design v2.x——以及 Platform One / Kessel Run / Black Pearl 等头部软件工厂的公开实践拆开看,他们重点投资的能力可以归为六类。 这是 DoD 软件工厂区别于一般 DevSecOps 的标志性能力,核心是cATO(Continuous Authorization to Operate,持续 ATO):把传统 6—18 个月的一次性授权拆解为流水线持续证据 + 持续监控(ConMon)的动态过程,做到「代码合并即重新评估,无需重新申报」。配套的Authorization Inheritance(授权继承)机制——以 Platform One 的 “Party Bus” 为代表——让上线应用自动继承平台级控制项(约 70%—80%),应用团队只需自证剩下的 20%—30%。这条路对应到中国军工,就是把「三级评审 / GJB 5000B 评价 / 涉密评审」从事件驱动改成数据驱动,把「每个型号自证 100%」改成「平台继承 + 应用自证」。 三件套是Iron Bank(硬化容器镜像仓库)+Repo One(镜像源码仓库)+Big Bang(Kubernetes-based DevSecOps 技术栈),所有镜像必须从 Iron Bank 拉取,每个 CVE 必须有处置说明(remediated / mitigated / accepted)。多密级流水线则覆盖 IL2(公开)/ IL4(CUI)/ IL5(秘密)/ IL6(机密)四级隔离,工具链与流水线模板在四个等级里同构运行,跨级别通过 Cross-Domain Solutions(CDS)做单向流动。这套基础设施背后,是一个不断扩张的软件工厂网络:截至 2025 年公开材料,DoD 全军已有约 50 个软件工厂在运行,Air Force 的 Kessel Run / Platform One / BESPIN / LevelUP、Navy 的 Black Pearl、Army 的 Software Factory at Austin 是其中头部代表。 SBOM 强制化(EO 14028 之后所有联邦交付软件必须附 SPDX/CycloneDX 格式 SBOM)、Cosign / Sigstore 容器与制品签名默认开启、生产环境 admission controller 拒绝未签名镜像、Zero Trust 运行时(身份 + 设备态势 + 微分段三者共同验证,而不是「在内网就放行」)。 ConMon(Continuous Monitoring)是 RMF Step 6 的自动化版本,实时采集控制项偏差并向 ATO 决策机构上报。指标层面除了 DORA,DoD 强调 Mission Outcome 指标——任务可用率、平均修复时间、对手识别延迟——和工程指标分层管理,不互相替代。这是值得我们直接借鉴的:DORA 是工程质量,不能替代装备效能,两者必须分两层看。 Software Acquisition Pathway(SWP,2020 年生效)允许把软件项目从传统 DOD 5000.02 武器系统采购流程里剥离,以季度为单位做需求与预算调整;专职软件工厂建制——Air Force 的 Kessel Run / Platform One / BESPIN / LevelUP,Navy 的 Black Pearl,Army 的 Software Factory at Austin——都是有番号、有预算、有 200—500 人专职团队的常设组织,而不是项目化的临时编组。 这一块在 2024—2026 年的迭代速度最快,值得单独记几个时间点:CDAO(2022)把 AI 治理升格为部级一级单位,推出Responsible AI Toolkit(RAI);Task Force Lima(2023—2024)阶段性收尾后,2024 年 12 月成立AI Rapid Capabilities Cell(AI RCC),首期投入 1 亿美元,角色从「研究 AI 边界」切换为「把前沿 AI 作为能力快速交付到作战单位」;2026 年 1 月发布的《Artificial Intelligence Strategy for the Department of War》进一步给出三个明确信号——七个 Pace-Setting Projects(节奏设定项目)作为旗舰试验田、30 天的模型集成节奏(新模型 30 天内进入生产环境)、DoD Data Decrees(数据法令)强制打通跨军种数据资产;企业级生成式 AI 平台GenAI.mil也已经面向 10 万级用户铺开,形成统一入口。这一系列动作的核心信号是:AI 治理不再只挂在一个研究部门,而是「办公室 + 平台 + 数据令 + 节奏」四件套同时驱动。AI 这一块的细节会在第五节展开,这里只点出建制——它本身就是一个还在快速演进的「制度地基」。 把六类清单合上,真正决定 DoD 软件工厂跑得动的,不是上面任何一个工具,而是三个体制性安排——它们恰恰是中国军工目前最薄弱的: 这件事在工程上不算难,真正难的是配套的「监管接收」——能不能让上级评审与评价机构愿意接受平台级证据继承,而不是要求每个应用各自递交一摞文档。这是合规模式从「文档驱动」切换到「数据驱动」的最关键一跃,也是 DoD 把交付周期压短的最大杠杆。 Kessel Run 是有番号的中校级单位,Platform One 是 Air Force 信息主管(SAF/CN)直管的项目,Black Pearl 是 NIWC 太平洋的常设组织——这意味着软件工厂不是「项目化、临时编组」,而是和导弹研究院、雷达研究所一样,是一个能沉淀知识资产、能跨型号复用的常设建制。反观我们,大多数院所还把 DevSecOps 当作「信息化处的一个改造项目」,这种定位决定了它无法真正沉淀平台资产。 通过 Software Acquisition Pathway,DoD 把软件项目从「武器系统五年规划」里剥离出来,改用「能力包 + 滚动预算」的方式管理,需求与预算季度级调整。我们的装备采购体制不能照搬,但其中「分层授权 / 滚动预算 / 阶段性验收」的思想,可以在型号层面找一两个非核心项目先做试点。 图 2 · DoD vs 中国军工三大制度差距:合规模式 / 软件工厂建制 / 采购与预算节奏——三件事全是「制度课」 到 2026 年,中国国产化工具链的成熟度——鲲鹏 / 飞腾 / 麒麟 / 达梦 / 东方通 + 国产 DevSecOps 平台——已经接近世界水平,在某些细分能力上甚至追平。真正的差距,落在三件事上—— 第一,合规模式没有切换。GJB 5000B 仍然以文档评审为主线,cATO 类的「持续授权」机制尚未成型;评审周期 vs 软件迭代节奏的剪刀差越拉越大,而且会随着型号节奏加快而进一步放大。值得关注的最新信号是:DoD 在 2025 年 FY25–26 实施计划里把「合规接收速度」直接写成了 KPI——cATO 覆盖率、Authorization Inheritance 复用比例、首次授权到部署的时长——这意味着「合规快」本身就是一项交付绩效,而不再只是「不出事」的底线。我们目前还停留在「合规等同于不出事」的阶段,把合规速度作为 KPI 来管理,是制度课里下一步可以试点的方向。 第二,软件工厂没有建制化。既有的院所信息化处、软件中心、CMMI 推进组等等,功能都不完整,职责也都偏窄,没有一个对「软件工厂能力」整体负责的常设建制。这是知识资产沉淀不下来的根本原因。 第三,采购与预算节奏与软件迭代不匹配。装备采购体制以年计,软件迭代以周计;预算线、合同线、研制节点线三者错位,导致软件团队即便有能力做持续交付,也没有制度激励去做。 这三件事补课成本不低,但比补技术课难得多。它们不能由信息化处一家推得动,需要总师体系、采购口、人事口共同参与——这也意味着,第六节给出的三期路线图,只能解决「技术课」那部分,制度课的解题需要更高层级的统筹。 对标 DoD 软件工厂的国产一站式研发协作平台已经在浮现。以Gitee为代表的几家国产厂商,已经把 DoD 软件工厂的「平台与基础设施 + 安全左移 + 度量治理」三层能力做成可商用的一体化平台:从代码托管、制品仓库、流水线编排,到代码扫描、测试管理、跨项目度量,再到协同知识库、云端开发环境,基本对齐了 DoD 软件工厂(Platform One / Iron Bank / Big Bang)在工具底盘层的核心组件;并且在代码评审等环节主动嵌入了 AI 助手能力,正好对应文章 AI 章节里「AI 作为生产工具」的非核心试点起手式。 这意味着前面那张 DoD 能力清单,底层工具不再是要不要造的问题,而是要不要选的问题。它也是第六节三期路线图里「第一期端到端国产化流水线跑通」可以直接站在巨人肩膀上的现成底盘——而不必从代码仓、制品库、流水线一砖一瓦地自己堆。 但要把这类通用平台真正用进军工场景,有三处缺口必须由院所与厂商共同补齐——它们恰好对应 DoD 软件工厂里最特殊的三类能力: 一是多密级分级流水线 + 跨域单向同步。对应 DoD 的 IL2/IL4/IL5/IL6 + Cross-Domain Solutions——这是军工最特殊的需求,通用一体化平台原生不带,需要按院所密级体系做项目化定制,本质上是「平台 + 涉密侧定制层」两层叠加。 二是 SBOM 强制化 + 容器/制品签名 + 准入拒绝。对应 DoD 的 Cosign / Sigstore + admission controller——这是供应链安全的关键合规能力。国内通用平台目前多数能做到「能扫描、能记录」,但「未签名镜像直接拒绝部署」这种强制策略,往往要专门配置和加固,而不是开箱即用。 三是 MLOps 模型工厂 + AI 安全闸门。对应 DoD 的 JCF + RAI Toolkit——这是「AI 作为装备软件下一代形态」那条线的工具底盘。国内主流 DevSecOps 平台当前都尚未完整覆盖,院所要么等生态补齐,要么主动外接专用 MLOps 平台,在采购环节就把这块能力作为独立模块规划。 这三处缺口反过来告诉我们一件事:即便选了一体化国产平台,「软件工厂」的最后一公里仍要院所自己打——涉密分级、SBOM 强制策略、模型治理,这些都和「型号怎么管」「证据上级如何接收」紧密耦合,通用产品替代不了。工具能把技术课做到 80 分,剩下的 20 分技术课和 100 分制度课,只能靠院所自己接上去。 一是公有云式合规云。JWCC(Joint Warfighting Cloud Capability)依赖商业云厂商提供 IL5/IL6 级别的合规承载,我们不存在等价的市场结构,只能走「物理隔离 + 信创云」路径。 二是依赖美国生态的工具链。GitLab Premium、Anchore、Twistlock、Fortify 等都是 DoD 软件工厂的实际依赖项,这条供应链对我们既不安全也不可获得,国产替代没有任何「先借用再切换」的空间。 三是人员高流动 + 短期合同的承包文化。Kessel Run 大量使用 18F / 数字服务局背景的短期合同工程师,这与我们「岗位稳定 + 保密期限 + 老带新」的工程师生态不可能同构,也不应同构。 两面镜子合在一起的结论是:学什么、不学什么,决定了我们是在进步还是在变形;平台思维 + 制度配套,决定了我们是真落地还是只画在 PPT 上。
主案例:某型号研制单位的 DevSecOps 实践
这家研究所的转型前状态,许多院所并不陌生:型号多、版本多,研发人员约 40% 的时间花在配置管理、评审材料整理和跨型号沟通上;代码合并冲突频发,经验难以跨型号复用;青年工程师对「高强度评审 + 低可见度产出」的耐受度持续下降。 关键决策的节点出现在 2024 年末。该所选择以国产 DevSecOps 平台为基础,搭建覆盖多型号的统一代码仓与流水线,将 GJB 5000B 过程域要求转化为流水线中的自动化检查项,证据自动进入不可篡改的审计链。工具链坚持全栈国产化,操作系统、数据库、中间件分别采用麒麟、达梦、东方通,涉密网与非涉密网之间通过可审计的摆渡通道实现受控同步。 遇到的阻力——这一段其实最值得说清楚——主要有四类:老员工对「不开会评审就放行」的不安全感,尤其是在试点初期;不同型号组对「统一流水线」的抵触,担心被「一刀切」管控;涉密网与非涉密网的双环境同步在初期延迟较大,影响开发节奏;信创工具链联调前后用了约 3 个月,比预期长了一倍。面对这些阻力,该所采用的做法是「评审形式瘦身 + 证据自动补足」——人工评审不取消,但只评「流水线已自动把关之外」的部分,大幅降低了会议时长。 结果是可以量化的。公开数据显示:(1)功能模块平均交付周期从 23 天压缩到 9 天(节省约 60%);(2)代码缺陷密度下降 46%;(3)合规取证时长从平均 3 周缩到 5 个工作日以内——以前评审季临时整理的事情,现在是流水线日常副产物;(4)流水线构建成功率稳定在 95% 以上,信创工具链覆盖率从最初的 0 拉到 100%;(5)安全外溢率(安全问题从研发阶段漏到测试或更晚阶段的比例)同比下降近六成。进入 2026 年后,基于历史版本智能推荐的合并冲突预计可再降低约 35%,测试工作量预计可降低约 28%。同时,零信任架构嵌入版本管理,按任务上下文动态授权;代码变更审计链采用区块链技术,让每一次涉密代码的变动都可追溯、不可否认。 需要强调的是,这些数字单看任何一个,意义都有限。真正值得参考的是它们的「连同看」——速度上去了,缺陷没飞起来,合规反而更轻。这才是 DevSecOps 体系的应有之义。任何只在单一维度上「做出成绩」的做法,放在 GJB 5000B 评价或装备总体审视里,都站不住脚。 某大型国有商业银行在过去两年把监管条款(反洗钱、数据安全、个人信息保护等)映射为流水线中的自动化检查项,把合规从「事后审计」变成「事中卡点」——一旦触发红线,流水线直接阻断,等待人工介入。这一做法让其在 2025 年金融监管总局针对科技合规的专项检查中整改项大幅减少。 某头部证券公司建立了「研发—运维—安全」三方共用的度量看板,核心指标统一、权限统一、责任共担。过去不同部门互相「甩锅」的问题,通过共同的指标显著缓解。 这两点启发,并不依赖金融业态,完全可以在军工受控环境下落地。
注:为保护研制单位,具体型号信息已脱敏;主案例数据来自该单位 2025 年公开技术交流材料,2026 年的部分指标为基于历史趋势的预测。 他们的答案不能直接是我们的答案,但他们的问题和我们一样。
如果这篇文章有一个值得被截图保存的部分,那应该是这一节。 图 3 · 四层模型 + 一根贯穿全栈的 AI 之梁:第一层是地基,第四层是治理,AI 不是第五层,而是横穿四层的第五根梁 这一层先要厘清一对容易混淆的概念:「要建设的能力」和「要满足的标准」不是一回事。能力是落地动作——涉密分级、国密算法、区块链审计链、全要素留痕、自动化合规证据生成,都是在工厂里要建出来的东西;标准是服务对象——GJB 5000B 过程域、等保 2.0、新《网络安全法》(2026),是工厂建成熟之后要满足的合规目标,而不是「第一期就要堆出来的组件」。把这两件事分开,后面的路线图才不会被「五千把要求当五千件交付物」拖垮。 具体到能力建设上,核心做法是把标准条款拆解为机器可读的检查规则库,工具链在日常运行过程中自动产出合规证据——提交记录、评审日志、测试报告、扫描结果、度量数据——全部写入不可篡改的审计链。这层对应 GJB 5000B 中的配置管理(CM)、度量与分析(MA)、过程与产品质量保证(PPQA)等过程域。这一层解决的问题是「体检报告自动生成」,过去评价时要临时整理的东西,现在是日常副产物;到三期完成时,GJB 5000B 自评估、等保 2.0 与新网安法的合规证据,自然会作为副产品长出来。 对应需求开发(RD)、技术解决(TS)、产品集成(PI)、验证(VER)、确认(VAL)。全国产化的代码仓、制品库、CI/CD 工具构成主干,涉密网与开发网双环境通过可审计的摆渡通道同步。流水线设置分级门禁:基础检查自动通过、中级问题告警并记录、高级问题强制阻断并触发人工介入。这一层解决的问题是「让流水线本身成为一道合规关卡」——合规不靠会议拦,靠流水线拦。 对应风险管理(RSKM)、因果分析与决策(CAR)。除了通用的 SAST、SCA、IAST,军工场景需要特别增强几类能力:开源组件白名单管控(与信创生态联动)、后门与恶意代码深度检测、涉密信息泄露扫描(硬编码口令、敏感字段、涉密注释)、AI 生成代码的可溯源性与审查。这一层解决的问题是「把风险拦在评审之前」——不让问题带进评审会,评审效率才能真正提上来。 对应组织过程定义(OPD)、组织过程焦点(OPF)、组织培训(OT)。建立型号级与院所级双层度量看板,核心指标建议包括:平均交付周期、缺陷密度、评审一次性通过率、证据完备性、工具链国产化覆盖率、人员相关培训证书持有率。这一层解决的问题是「让改进有数据、让汇报有证据」。 体系不是工具的堆叠,而是标准、工具、流程、人的结构化对齐。这四层,从下到上每一层都有明确的「服务对象」:第一层服务合规,第二层服务交付,第三层服务质量,第四层服务治理。每一层都能独立增量建设,又都能对上一层提供支撑。
AI:既是装备软件的下一代形态,也是工厂的生产工具
AI 在军工软件工厂里同时扮演两个角色——它既是装备软件的下一代交付物,也是研制装备软件的这一代生产工具。前者决定我们交付什么,后者决定我们怎么交付。新《网络安全法》已把 AI 治理写入国家法律,这意味着两重身份都已经从「技术议题」升级为「合规议题」,必须分别处理。 到目前为止,我们讨论的 DevSecOps,其交付物仍然是「代码」。但 2026 年,这个前提本身正在动摇——下一代装备软件的核心能力,不再主要来自代码,而是来自模型。「软件定义武器装备」已经写了十年,「AI 定义下一代装备软件」是它的下一站,两者的差异远比名字看上去要大。 传统装备软件里,能力的载体是确定性逻辑——需求可规约、代码可审阅、测试可穷举(或接近穷举)。但从智能感知、智能火控、认知电子战到集群自主协同,下一代装备软件的核心能力越来越多地由训练出来的模型承载。这一次变化带来的,是交付物形态本身的重构。 过去,研制单位交付的是「代码 + 文档」。未来,交付的是「代码 + 模型 + 数据集 + 算力基线 + 再训练规程」。 过去,装备软件「完工即定型」。未来,模型需要根据新威胁、新任务持续更新,装备软件的生命周期从「一次性交付」变为「持续演进」。 过去,可靠性的定义是「零缺陷」。未来,可靠性的定义变成了「鲁棒性 + 可解释性 + 边界可控」——模型在对抗样本、域外数据、战场干扰下的表现,和在测试集上的表现同等重要。 版本管理对象变了。过去用 Git 管代码,未来必须同时管代码、模型、数据集、训练脚本、评估报告。版本、血缘、可复现性的要求比代码更严——同一份代码可能因为训练数据版本不同而产生完全不同的模型。 流水线维度变了。CI/CD 要扩展为CI/CD/CT(Continuous Training)。训练流水线、评估流水线、模型准入流水线,都要成为体系的有机组成部分。流水线的「门禁」也要加新维度:不只是代码质量,还有模型性能、对抗鲁棒性、解释性指标、公平性与偏差。 安全威胁面变了。代码漏洞还在,但新威胁正在浮现:对抗样本攻击、模型投毒、后门触发、模型反演与提取、推理时的侧信道泄漏。安全左移引擎必须覆盖模型本身。 合规体系不够用了。GJB 5000B 是为传统软件研制设计的,它的过程域能覆盖一部分但不能覆盖全部。训练数据的采集合规、模型评估的充分性、再训练的版本管控、模型退役与替换的规则——这些需要一套专门的、在 GJB 框架之外补上的模型研制规范。国内目前正处在这套规范从行业标准向国军标演进的早期阶段。 与民用 MLOps 相比,军工的模型工厂有两条不能让步的硬约束:可解释性不是可选项——装备决策必须可审计可追溯,黑箱模型作为建议者或可,作为决策主体几乎不可接受;人在回路是底线——尤其涉及打击决策的场景,这是伦理、法律与国际认同三重底线。此外,数据本身是双面刃——既是涉密资产,又是模型不可或缺的输入,如何在涉密约束下聚合足够训练数据(联邦学习、合成数据、脱敏训练、院所级共享),是比代码管理更难的工程问题。 不必等到「AI 定义装备软件」全面到来才开始准备,可以从三件小事入手:
在代码仓之外建立模型仓与数据集仓,即使当前只有一个小模型,也要先把版本和血缘管理建起来
把 GJB 5000B 过程域思想映射到模型研制——哪些可沿用(配置管理 / 度量与分析)、哪些要扩展(验证 / 确认)、哪些要新增(数据管理 / 模型治理),院所内部先形成白皮书,再推动对上的标准工作
把「人在回路」作为所有 AI 装备软件的默认架构,在设计阶段就预留人工干预接口——这一条比任何单点技术都重要
凡是能改变交付物的技术,通常先改变生产工具——AI 也不例外。它作为工具的这一重身份,比作为交付物落地更早、争议也更具体:它在 2026 年已经在发生,问题只是我们要不要、怎样把它「做对」。对军工院所来说,AI 既是让现有体系加速的增量引擎,也是一张全新的风险面——两者必须同时看清楚。
AI 辅助编码 。类 Copilot 能力在金融头部已广泛使用,但军工院所必须先回答一连串前置问题:使用本地部署的国产大模型还是云端?训练语料是否包含涉密代码?生成的代码是否保留溯源信息?目前比较稳妥的做法是选用可私有化部署的国产代码大模型,配合严格的涉密信息扫描,在非涉密环境先行试点,再考虑向更敏感的型号环境延伸。
AI 驱动的安全检测 。大模型擅长的不是替代传统 SAST,而是在传统工具误报率高、覆盖不足的地方做补充——识别复杂业务逻辑漏洞、发现异常提交行为、检测大模型生成代码中的潜在后门。这类能力在 2026 年已经开始在头部金融机构和少数军工单位投入使用。
AI 智能测试 。基于历史缺陷数据的测试用例生成、缺陷预测、优先级排序,能显著降低测试工作量。某型号研制单位的公开数据显示,引入智能化测试辅助后,测试工作量预计可降约 28%。
AI 评审与文档助手 。对评审负担最重的军工院所而言,这可能是最有落地价值的方向——自动检查文档一致性、生成评审摘要、预测评审风险、把会议纪要自动结构化并写入审计链。这不是为了减少评审本身,而是为了减少评审前后的重复劳动。
AI 驱动的知识与过程管理 。把多年积累的型号研制经验、评审意见、缺陷数据做成可检索的知识图谱,用大模型做自然语言问答。新型号立项时,历史经验不再只在老工程师的脑子里。
训练数据的涉密泄漏。把涉密代码或评审材料作为训练、微调数据,一旦模型外流或被反向推断,后果无法挽回。红线只有一条:任何涉密数据不进入可能对外的训练链路。 提示词注入与越狱。攻击者通过精心构造的注释或文档,让 AI 助手输出攻击者预期的内容。金融场景下的后果是数据泄漏,军工场景下的后果可能是研制机密外流。 生成代码的责任归属。GJB 5000B 下,每一行代码都应有明确的责任主体。AI 生成的代码谁负责?研制记录怎么写?行业层面的答案尚不明确,但院所级制度应当先一步定义,不要等出了问题再补。 大模型供应链投毒。开源模型、第三方微调模型、外部 API,都可能是被污染的入口。军工使用 AI 的最低要求是模型链路可溯、可审计、可控。 与金融的「先用起来再治理」路径不同,军工应当走「先围控再放开」的路径,三条原则:
先非核心、后核心。AI 能力优先在文档、测试、知识管理等非研制主链路落地,验证安全性后再向代码生成、评审辅助延伸。
先审计、后使用。无论哪个 AI 能力,必须先建立使用日志、溯源链、责任归属机制,再开放给研发人员。
先国产、后融合。底层模型坚持国产化、私有化部署,涉密环境不连接境外 API,必要时建立院所级或行业级的专用大模型。
图 4 · 美军 AI 路线两阶段切换:阶段一(2022—2024 治理使能)→ 转向时点(2024.12,Task Force Lima 收尾、AI RCC 接棒)→ 阶段二(2025—2026 纪律性交付) 第一阶段(2022—2024)是治理框架建立期。2022 年成立的CDAO(Chief Digital and Artificial Intelligence Office)把 AI 治理升格为部级一级单位,直接向国防部副部长汇报;Responsible AI Toolkit(RAI)把对抗鲁棒性、数据偏见、可解释性做成军用 AI 的强制前置评估;Joint Common Foundation(JCF)提供受控的模型训练与部署环境(可以理解为「军工版 MLOps 平台」);2023 年设立的Task Force Lima专门研究生成式 AI 在 DoD 的应用边界与红线。这一阶段的关键词是「治理使能」——先把红线划清楚,再决定开多大的口子。 第二阶段(2024 年底至今)是纪律性交付期。2024 年 12 月,Task Force Lima 阶段性收尾,AI Rapid Capabilities Cell(AI RCC)接棒成立,首期投入 1 亿美元;2025 年夏季,DoD 与 OpenAI、Anthropic、Google、xAI 各自签订规模约 2 亿美元、上限 200 美元/账户/年的企业 AI 合同;2026 年 1 月发布的《Artificial Intelligence Strategy for the Department of War》给出三个具体抓手——
七个 Pace-Setting Projects(节奏设定项目)。把 AI 应用绑定到具体作战与决策场景(如指挥决策、人才管理、采办加速等),作为「先把节奏跑出来」的旗舰试验田;
30 天模型集成节奏。要求新模型从准入评估到进入生产环境不超过 30 天,把模型迭代频率拉到与软件交付同一个量级;
DoD Data Decrees(数据法令)。用强制令的方式打通跨军种数据资产,正面解决「数据孤岛阻碍 AI 落地」这个老问题。
与此同时,GenAI.mil这一企业级生成式 AI 平台已经面向 10 万级用户铺开,形成统一入口、统一审计、统一合规配置;部级层面也完成了一次更具象征意味的更名——2025 年 9 月 Department of Defense 更名为Department of War,与「Wartime Speed」的话语体系互为表里。 对我们最有借鉴意义的不是工具,而是这次切换本身蕴含的三条经验。 第一,AI 治理与 AI 交付,要分两个阶段、两套节奏。美军用 2—3 年时间先把红线、评估框架、平台底座打出来,再切到「以月计的交付节奏」。直接学第二阶段的 30 天节奏,会跳过红线建设——但也不能停在第一阶段反复研究边界,等到时间窗关闭。 第二,AI 不应只挂在某个「治理部门」,需要「办公室 + 平台 + 数据令 + 节奏」四件套同时存在。CDAO 是办公室、GenAI.mil 是平台、Data Decrees 是数据令、30 天节奏是交付纪律——四件少一件,系统就跑不起来。我们目前在「办公室」和「平台」上各有动作,但「数据令」与「节奏」尚未明确,这是下一步制度课里值得补的缺口。 第三,「人在回路」要做成默认架构,而不是事后加上去的开关。美军 2026 年 AI 战略反复强调的并不是「让 AI 替代决策」,而是「让 AI 加速决策、保留人类否决权」——七个 Pace-Setting Projects 几乎都明确人类作为最终决策方。这一点和军工伦理底线天然契合,值得在体系设计阶段就写死,而不是留作可调参数。 代码工厂是 DevSecOps 的上半场,模型工厂是下半场。AI 不是体系的第五层,而是贯穿四层的第五根梁——每一层都因为它加速,每一层也都因为它多了一类风险。 图 5 · 全生命周期 × 三期 矩阵:横轴 9 道工序定义工厂边界,纵轴 3 期定义建设节奏;顶部三条横向轨道是贯穿全周期的安全 / 合规 / AI;GJB 5000B、等保 2.0、新网安法是「成熟态要满足的标准」,而不是「一期要堆出来的组件」 信息化基础较好的院所,建议「单倍速」节奏推进三期。三期之间用「过渡判据」收尾,而不是日历时间;每一期的核心心法、覆盖动作、过渡判据都不一样,下面分期说。
第一期(0 → 1 · 筑基,约 6—9 个月)——先求深、不求广
挑一个「有真实交付压力但容错度中等」的非核心试点型号,把编码 / 构建 / 发布这三段最容易自动化的主干在它身上跑通;需求 / 设计 / 测试 / 部署四道工序做”试点级”的支撑(基础需求登记、设计文档协同、基础自动化测试、涉密 / 非涉密双环境切分 + 单向网闸);运营 / 监控这一期可以先不上。同时,合规证据自动留存接入审计链,模型仓和数据集仓也在这一期就埋下最小版本(版本管理 + 血缘),为后两期的 AI 化省一次重做。 过渡判据是:试点型号已完成 ≥ 1 次完整版本交付、证据自动留存稳定运行 ≥ 3 个月——满足这两条,才算从 0 → 1。
第二期(1 → N · 强化,约 9—12 个月)——先求广、再求严
把第一期跑通的主干横向铺到全部 9 道工序,所有工序进入”默认开启”状态;同时把流水线沉淀为「型号 × 平台」模板库,横向复制到 3—5 个型号。SAST / SCA / IaC 默认开启,SBOM 自动生成 + 签名 + 准入拒绝形成默认动作,威胁建模和漏洞修复 SLA 接入研发流程。AI 助手在这一期可以试点,但只用于「不涉密的辅助场景」(文档生成、单元测试),不进核心研制。 过渡判据是:≥ 3 个型号在统一模板下稳定交付 ≥ 6 个月、安全闸门误报率收敛到研发可接受——这两条不达,不进第三期。
第三期(N → N+1 · 跃迁,约 12 个月起,持续运营)——从「堆能力」转向「数据驱动 + AI 嵌入」
前端工序(需求 / 设计 / 编码 / 构建 / 测试)叠加 AI 增强,后端工序(运营 / 监控)进入”默认开启”+ AI 异常检测;工程效能 + 安全 + 合规三类指标看板上线,DORA 四指标 + Mission Outcome 分层管理,「合规接收速度」纳入 KPI。红蓝对抗常态化做对抗性验证,模型工厂 MVP(CI / CD / CT)上线,AI 安全闸门 + 模型签名作为模型上线的强制环节,私有化大模型在核心辅助场景落地。到这一期结束,GJB 5000B 符合性自评估、等保 2.0 与新网安法的合规证据,自然作为体系副产品达成,而不是被单独立项「补」出来。 信息化基础一般的院所,建议「双倍速」节奏推进三期。三期的次序不能改,但每一期的跨度可以拉长一倍。第一期把”编码 / 构建 / 发布”三段主干跑通——优先让「单试点型号能在新流水线上跑出一次完整版本」这个 0 → 1 立起来,其他工序的覆盖都可以延后到第二期。第二期再让 9 道工序整体进入”默认开启”,把安全左移、强制门禁、模板化复用沉淀下来。第三期再叠 AI 增强与度量看板。不必追求与头部院所同步——节奏合适比追风口更重要,跨期之间的「过渡判据」(关键产出 + 硬指标 + 稳定运行时长)比日历时间更值得守。 下面八条按风险高低排序——前三条是深坑(即使做了,也容易做歪的失败模式,需要解法),后五条是雷区(直接做错,需要先警示)。
左移过度 。把所有安全门禁堆到 PR 阶段,看上去很「左」,实际后果是研发瘫痪、绕过门禁成为新常态——一旦研发觉得规则不合理,他们的第一反应是想办法绕过,而不是遵守。解法是把扫描结果分级为「阻断 / 警告 / 收集」三档,只对高危项阻断,其余记录归档,定期复盘。
度量异化 。DORA 四指标本是用来辅助持续改进的,但一旦写进 KPI,就极易演化为「数字内卷」——为了部署频率好看,频繁切版甚至空切版;为了恢复时长好看,把故障定级压低。解法是任何单维提升都不算成绩,四个指标必须连同看;同时建立反向核查机制,让审计部门每季度抽查一次指标真实性。
AI 形式化 。在 AI 安全闸门上常见的失败模式是「人工审批 + 一键放行」——审批理由写成「无异常」三个字,等于没审。解法是把审批理由结构化为标签(数据合规、模型可溯、对抗鲁棒、人在回路 …),并将这些标签接入审计链可追溯。形式审批的代价,要让审批人本人承担。
不要先上 AI 功能再补基座 。没有证据链和流水线做底盘,任何智能化都是空中楼阁,评审一查就现形。
不要让试点变成演示专用 。不少院所的 DevOps 平台只跑「PPT 型号」,一旦对接真实型号就水土不服,这种试点等于没做。
不要忽视老员工的评审文化惯性 。制度变化快于心理预期,必然引发抵触。同步推进「渐进式评审轻量化」的培训与复盘,比硬推制度更有效。
不要在证据链完备性未达标前扩大覆盖面 。先深再广,深度不够就扩面,等 GJB 评价一来,全盘露底。
不要低估信创工具链联调周期 。中间件、数据库、CI/CD 平台三方联调的坑,过来人都踩过。项目计划中至少预留 20%—30% 的缓冲,不然一定延期。
新增三类岗位,但不要新设三个新部门。平台工程师(负责流水线和工具链)、安全工程师(负责左移引擎和威胁建模)、MLOps 工程师(负责模型工厂)是这套体系真正的「三个新角色」。但不建议为他们新设独立部门——更稳的做法是在现有的信息化部 / 软件研发中心 / 总体设计部框架下增设岗位序列,让新角色在熟悉的组织血脉里长出来,既减小阻力,也避免与既有总师体系产生不必要的张力。 考核要分层、分类、分阶段。试点期看「跑通」(单条流水线、单个型号);推广期看「复用」(几个型号共用一套流水线模板);稳态期看「数据」(看板上四个核心指标和三个安全指标都达标)。同一岗位在不同阶段考核重点不同,避免用稳态期的指标去要求试点期的人——这是很多体系建设半途而废的真正原因。 留住关键人,比招到关键人重要。这套体系建成后最大的资产不是平台,而是懂你们型号、又懂工程效能与安全的复合型工程师。他们一旦流失,体系会迅速退化为「文档体系」。建议在职级、保密津贴、技术专家评聘上同步设计,让他们在院所里有清晰的职业天花板。
判断一 · 2026 年的关键问题不是技术课,是制度课
国产化工具链已经接近世界水平,真正卡脖子的是合规模式没切换、软件工厂没建制化、采购预算节奏与软件迭代不匹配——三件事都不在 IT 部门的权限内,需要总师体系、采购口、人事口共同参与。
判断二 · 学美军学的不是工具清单,是「分两阶段、四件套同步」
治理使能阶段先把红线和平台底座打出来,再切到以月计的纪律性交付节奏;CDAO + GenAI.mil + Data Decrees + 30 天节奏四件少一件,系统就跑不起来。先看清楚切换的逻辑,再看具体工具。 它既是装备软件的下一代形态(交付物),也是软件工厂的这一代生产工具(生产工具)。前者要把「人在回路」做成默认架构,后者要走「先围控再放开」。两件事混在一起谈,只会得到都做不好的结果。
动作一 · 选一个「有真实交付压力、但容错度中等」的非核心型号,把第一期筑基跑出来
不从最核心的型号下手,也不选纯演示型项目;前者动不了,后者数据没说服力。试点选对,后面才能往外复制。
动作二 · 把「合规接收速度」作为下一年的 KPI 提出来
不必一步到位实现 cATO,但可以先把评审周期、证据准备时长、流水线门禁通过率做成季度看板——把合规速度从「不出事的底线」改成「可考核的指标」,是制度课里最容易先动的一步。
动作三 · 现在就建模型仓与数据集仓,即使只有一个小模型
AI 落地的瓶颈往往不在模型本身,而在「能不能管住版本、血缘、再训练流程」。这件事越早开始,后期付出的代价越小。 军工需要的不是另一个版本的金融 DevSecOps,也不是中国版的 Platform One,而是属于自己的新范式。它的内核仍是那四句话:合规即代码、证据即产物、国产即底线、智能即延伸。 我们不是要变成金融,也不是要变成美军——我们要变成更强的自己。2026 年的窗口期,真正稀缺的不是工具与技术,是动手的决心与节奏。
 夜雨聆风
夜雨聆风