 夜雨聆风
夜雨聆风





Nature子刊:AI分不清虎和猫?像婴儿那样学习,才能重塑AI视觉逻辑
这篇发表在《自然·机器智能》上的论文揭示了一个反直觉的发现:教给AI婴儿时期的学习方法,可能比单纯增加数据量重要得多。
出品|Omni实验室

最近,德国奥斯纳布吕克大学和柏林自由大学的研究团队在Nature子刊《Nature Machine Intelligence》发表了一项在AI视觉学习方面有很意思的研究。
论文标题:
“Adopting a human developmental visual diet yields robust, shape-based AI vision”
先说下论文结论:
有悖于传统通过增大数据量来进行AI视觉模型训练的方法,团队认为怎么学比学多少更重要。
研究发现通过引导训练过程而非单纯增加数据量,AI视觉系统可以达到更高的效率和更好的表现。
如果让AI像人类婴儿一样去学习,先经历视觉模糊的阶段,再逐渐变清晰,它反而能学得更好
——更依赖形状判断物体,更能抗图像干扰,甚至在对抗攻击下也表现出了更强的韧性。
在“看到”面前,AI和人的差异在哪里?
研究人员先给出了一组诊断。
现在的计算机视觉模型,尤其是卷积神经网络,绝大多数是在高精度的静态图像上训练出来的。
这就存在一个问题:模型学到的东西和人类不一样。
人类识别一个物体,靠的是形状,比如椅子的轮廓、猫的身形比例、车的整体结构。
其中纹理、颜色、图案变化一般不会影响你的判断~
即使给你家可爱的小猫染成粉色你仍然会认为它是一只猫咪~
但AI不太一样~
它在训练中需要依赖纹理特征~
比如把猫的毛色换成斑马的条纹,它可能就会判定为这是只斑马。
论文中明确指出,AI视觉系统“严重依赖纹理特征而非形状信息”~
而且“对图像失真缺乏稳健性,极易受到对抗性攻击,难以识别复杂背景中的简单抽象形状”。
还有一个根本性差异,就是训练方式~
AI从一开始就被放进高分辨率的真实图像里,直接面对成年人才能分清的视觉复杂度。
而人类的视觉成熟过程不同,是一个缓慢的过程,这个过程正好就是我们的人类的视觉学习优势。
人类视觉是如何发育的?
研究人员总结了多年心理物理学和神经生理学的研究,将新生儿到成年人的视觉成熟曲线完整量化。
发现曲线有几个关键维度:视觉敏锐度、对比敏感度和色彩感知。
新生儿的视力大约只有成年人的1/30,他们眼中的世界是一片模糊的明暗对比。
这种情况会持续数周到数月,随后逐步提升。
但认知科学的研究表明,这个看不清的阶段刚好起到了关键的结构性作用
少量的输入使大脑先抓取形态轮廓这种全局信息,把更精细的纹理和色彩处理放在后期。
同时这个结论也跟婴儿先天性白内障术后恢复的临床证据一样:
——即使患者术后能看清,但他们仍会存在一段时期的构型识别困难,这也说明早期视觉输入的受限并不是缺陷,而是发育过程中不可或缺的结构条件。
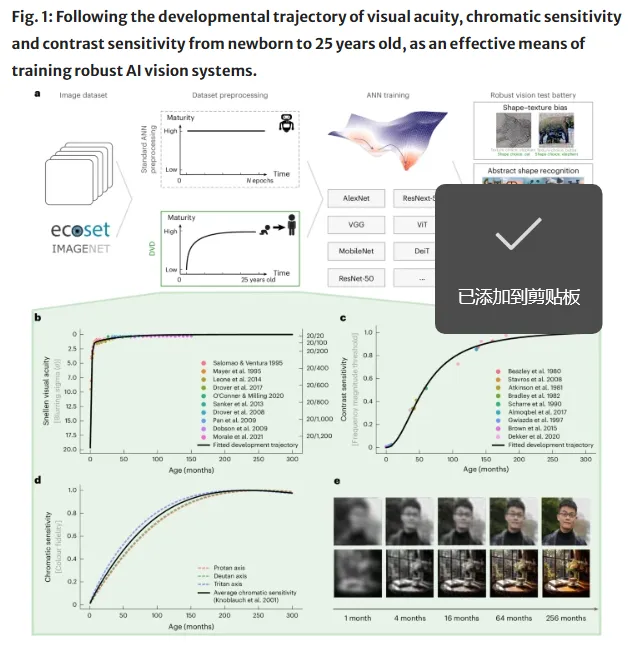
研究团队从这个规律出发,设计了一套训练框架,称为“发育性视觉食谱”(Developmental Visual Diet, DVD),全程模拟人类视觉成熟的参数变化。
DVD的核心方法:阶梯进度的参数控制
为了让AI模型跟人类婴儿的视觉发育尽可能一致,研究者直接干预训练中每一阶段的样本呈现质量,具体做法如下:
早期阶段:输入图像被大幅过滤,抛弃色彩和纹理细节,只保留最基础的轮廓和形状。同时,通过高斯模糊和平滑,模拟新生儿低敏锐度的视觉内核。
中期阶段:逐步适度降低模糊度,恢复部分高对比度细节,同时引入有限的色彩信息,模拟儿童在学步和学龄前阶段的视觉基础。
后期阶段:完全恢复真实的纹理、分辨率与彩色输入,模型最终与传统训练方案在视觉信号的保真度上没有本质差异。
不同发育阶段的时长也被精确控制:
早期视觉受限的持续时长根据人类新生儿时期的经验数据来设定。
后期逐步过渡的数据是用一个参数化的曲线来描述从新生儿到25岁成年人的所有中间状态,以此来驱动模型训练。
让每一步的视觉复杂度都处于当时的生理限制之下。
实验结果:四方面的显著提升
研究者评估了DVD模型在形状识别、抗噪声、对抗攻击等多方面的表现,测试结果相当明确:
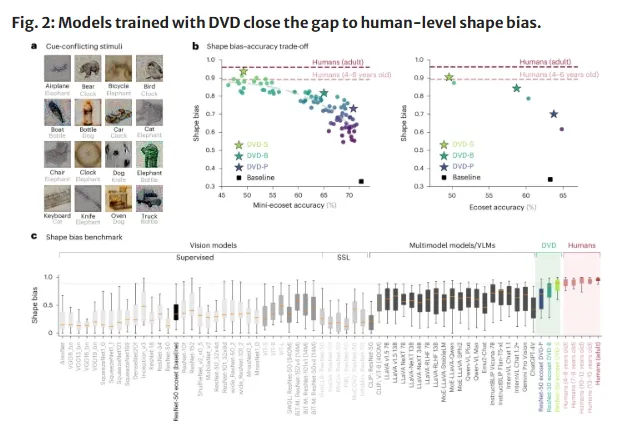
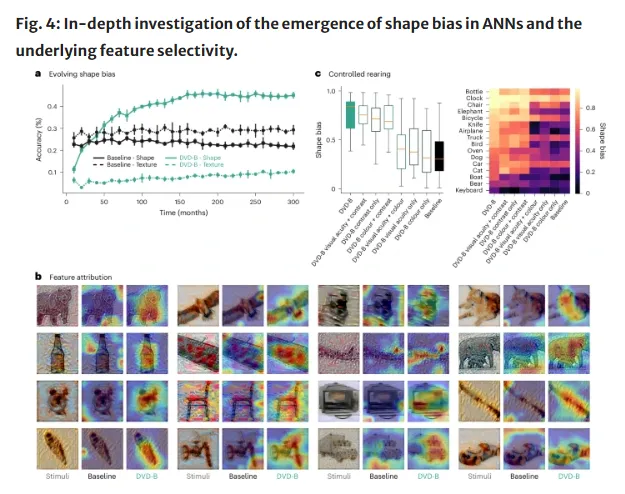
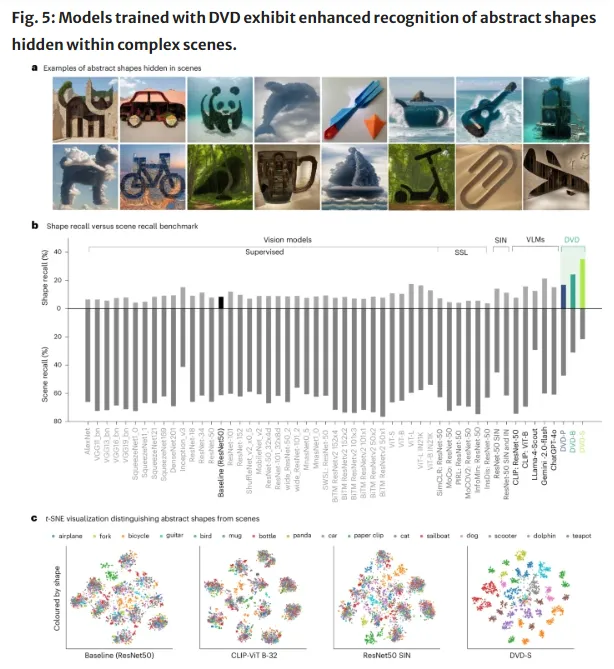
第一,AI的形状偏好显著提升。这也是整个实验最核心的改善,采用DVD方案训练的模型不再依赖物体表面的纹理特质做判断,而是优先用几何轮廓来识别事物。
论文还明确写道,这是迄今为止最强的形状信息依赖性。
第二,抽象形状识别能力超过现有最优水平。传统模型难以应对那些轮廓简单但背景复杂或类内差异大的抽象图形,而DVD模型在这类任务中的表现出超越了当前最优水平。
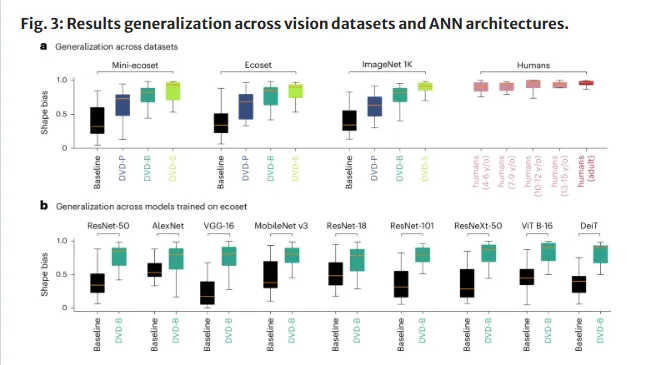
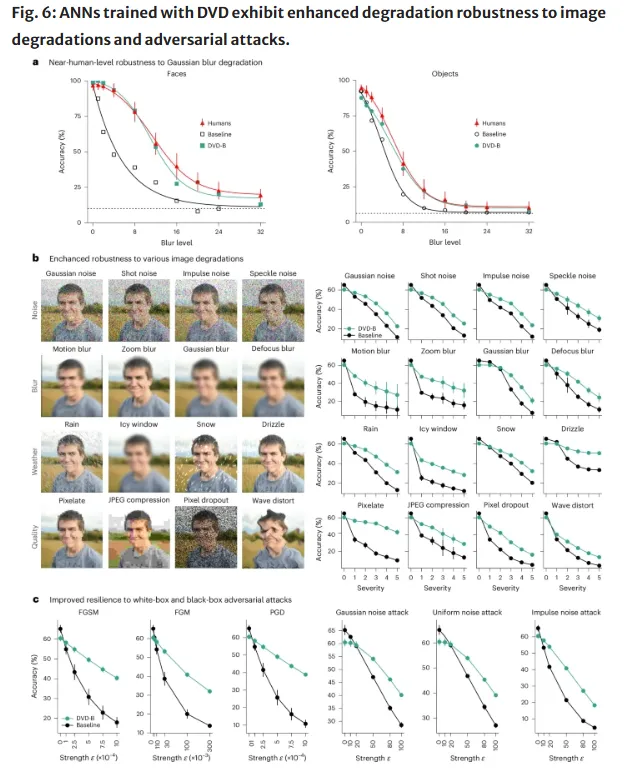
第三,对图像干扰的稳健性显著提高。各类图像质量下降、噪声、光线变化或部分遮挡等场景中,DVD模型的识别准确率均高于基线。这项性能覆盖了所有被测试的稳健性指标。
第四,对抗性攻击的抵抗能力更强。传统模型在面临对抗攻击时极易被欺骗,而DVD模型的表现明显更为稳定。
指导“如何学”可能比“学多少”更值得关注
这项研究的结论可以看作对一个行业的假设性修正。
过去的主流趋势一直是“越大越好”:
模型参数越多、训练数据越多,表现就越好。
但研究团队给出了一个不同的方向,引导学习过程本身,比单纯堆数据更具价值。
也直白地点出了一个被参数掩盖的事实:
那就是训练策略的设计权重可能真的不低于单纯规模的放大~
部分图集
创作:Omni实验室 / 审核:Omni实验室、Richard
哇,你竟然看到了最后,如果文章对您有帮助,欢迎点赞转发,如果标⭐️那就更好啦!