 夜雨聆风
夜雨聆风





跟我学 AI Agent : 第 6 课 — Tool Use: 让 Agent 拥有双手
模块: 模块二: 核心工作流模式 | 难度: ⭐⭐ | 预计时长: 2.5 小时参考: Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systemspi-mono API: Agent, AgentTool, tools[], beforeToolCall, afterToolCall
1. 开场引言
前几课我们一直在编排 Agent 内部的信息流 —— Chaining 串联、Routing 分流、Parallelization 并行。但 Agent 本身还只是一个「只会说话的大脑」。
一个只会说话的助手告诉你「伦敦现在是多云,15°C」—— 它怎么知道的?它并不知道。
大模型的训练数据在发布的那一刻就已经过时了,它无法获知实时天气情况。而Tool Use 就是给 Agent 装上「双手」,让它能真正与外部世界交互。
可以直白地说:
“Tool Use is what transforms a language model from a text generator into an agent capable of sensing, reasoning, and acting in the digital or physical world.”
💡 核心问题: 如何定义工具让 LLM 能理解?LLM 如何决定何时调用哪个工具?工具执行的完整生命周期是怎样的?
2. 核心概念
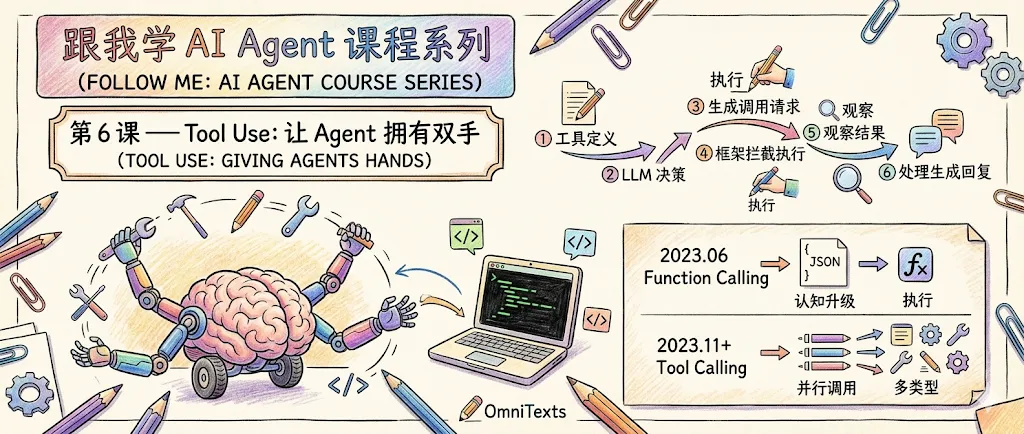
2.1 Tool Use 的六步生命周期
Tool Use 有一个清晰的六步流程,这是所有框架的共同基础:
① Tool Definition 定义工具:名称、描述、参数类型 ↓② LLM Decision LLM 分析请求 + 可用工具 → 决定是否需要调用工具 ↓③ Function Call Gen LLM 生成结构化调用请求(JSON:工具名 + 参数) ↓④ Tool Execution 框架拦截 → 执行实际的函数/API 调用 ↓⑤ Observation 工具返回结果给 Agent ↓⑥ LLM Processing LLM 结合工具结果生成最终回复(或决定继续调工具)关键洞察: LLM 本身不执行任何工具。它只是生成一个 JSON 说「我想调用 weather_api,参数是 location=London」。是框架/编排层负责真正执行函数并返回结果。
2.2 从 Function Calling 到 Tool Calling 的历史演进
今天我们说的 Tool Calling,并不是一天之内突然出现的,它最早是从 OpenAI 的一个具体 API 特性生长出来的。要真正理解它,必须回到时间线上去看。
第一阶段:Function Calling 的诞生(2023.06)
2023年6月,OpenAI 在 GPT-3.5 和 GPT-4 的 Chat Completions 接口中,首次引入了 Function Calling 能力。
当时的核心理念很朴素:
“让 LLM 生成结构化的 JSON,以便外部程序能可靠地调用预定义的函数。”
在这个阶段,API 的设计严格围绕「函数」这一概念:
-
• 定义方式:开发者通过 functions参数传入一个函数列表(名称、描述、parameters JSON Schema) -
• 调用方式:模型返回 function_call字段,包含name和arguments -
• 执行职责:模型只负责决定“要不要调用、调用哪个函数”,然后开发者必须在本地执行函数,并将返回值重新注入对话
这个时期的典型流程是:
用户请求 → LLM 判断需要调用函数 → LLM 返回 JSON(函数名 + 参数) → 开发者在本地执行函数 → 开发者将执行结果附加到上下文 → LLM 基于结果生成最终回复关键特征:
-
• 模型输出专门设计为函数调用的 JSON 格式 -
• API 参数名叫 functions,字段叫function_call -
• 功能定位是“让 LLM 可靠地输出 JSON 以调用函数”
这是整个 Tool Use 思想的技术起点。
第二阶段:从 Function 到 Tool 的范式转变(2023.11 — 至今)
2023年11月,OpenAI 在 DevDay 上推出了 Assistants API,随后在 Chat Completions 接口中正式引入 tools 参数,同时将旧的 functions 参数废弃并合并。
这个转变远不止是改了个名字,它在三个层面上完成了一次认知升级:
1. 从「调用函数」到「使用工具」的认知升级
原来的命名 functions 暗示模型的工作只是“决定调用哪个函数”。但在实际工程中,模型真正需要的是一个完整的外部能力生态:查询知识库、生成图像、浏览网页、操作数据库、调用其他 AI 服务……
几乎在同一时期,Anthropic 的 Claude 则从一开始就使用了 Tool Use 这个更宽泛的概念,并很快将其扩展为 Computer Use(计算机操控)、MCP(模型上下文协议)等更加通用的交互范式。
这些都远远超出了“调用函数”的语义范畴。把内部代码函数、外部 API、数据库查询、代码解释器、甚至另一个 AI Agent,统一抽象为「工具」,更准确地描述了 LLM 作为数字世界协调者的真实角色。
2. 从「单一工具调用」到「并行多工具调用」的能力扩展
tools 参数推出时,OpenAI 同时开放了 并行工具调用(Parallel Tool Calling) 能力。
当用户的问题涉及多个独立信息源时(例如“查一下苹果的股价和北京的天气”),模型不再需要串行地一个一个调工具,而是可以一次性发起多个调用请求,等它们全部返回后再整合生成最终回复。
这是一个质的飞跃:Agent 从简单的“请求-调用-返回”循环,直接跃升为具备并行协调能力的小型编排系统。
3. 从「API 特性」到「行业标准」的生态统一
随着 Anthropic、Google(Gemini API 中的 tools 参数)、以及 LangChain、CrewAI 等主流框架纷纷采用 Tool Calling 的命名和模式,它已经超越了某个厂商的接口定义,成为大语言模型与外部世界交互的事实行业标准。
今天各大平台的对应关系如下:
|
|
|
|
| OpenAI |
tools 参数 |
functions
tools 中的 type: "function" |
| Anthropic |
|
tools 概念 |
| Google Gemini |
tools 参数 + Function Declarations |
tools 作为统一入口 |
所以,它们到底是什么关系?
可以这样总结:
-
• Function Calling 是历史形态:它是 OpenAI 在 2023 年推出的原始 API 特性,文档中明确使用 functions参数名 -
• Tool Calling 是演进形态:它是行业在多模型、多平台实践中沉淀出的更通用的设计模式—— tools不仅是 API 参数,更代表了一整套架构思想
两者不是同一个东西,因为 Tool Calling 覆盖了 Function Calling 所不具备的并行调用、多类型工具统一调度、以模型为协调者的生态视角。但它们也不是两个完全无关的概念,因为 Tool Calling 正是在 Function Calling 的技术基础上生长出来的,是同一技术路径上的前后继承和发展。
概念辨析:两者在工程中的真实区别
如果回到工程视角重新做一次对比,今天的差异应该这样看:
|
|
|
|
| 出现时间 |
|
|
| API 命名 | functions
function_call 字段 |
tools
tool_calls 字段 |
| 核心理念 |
|
|
| 支持类型 |
|
|
| 调用模式 |
|
|
| 生态定位 |
|
|
| 相互关系 |
|
|
💡 这就是整个故事:Function Calling 给了 LLM 第一双「能动手的手」,而 Tool Calling 让它学会了同时使用工具箱里的所有工具、并且开始指挥整个车间。你现在在所有框架中看到的工具调用能力,都可以追溯到 2023 年 6 月那一个朴素的
functions参数。
2.3 工具的两层模型:元工具与扩展工具
在实际的 Agent 架构中,工具并非都是同一种层级。今天最先进的编码智能体(Claude Code)和通用智能体框架(OpenClaw)都采用了一个关键的设计原则:
只给 Agent 极少数的基础元工具,使其通过组合可以动态构建任何扩展工具。
什么是元工具?
元工具(Meta-tools)是 Agent 与底层计算环境交互的最小原语集合。它们不解决具体的业务问题,而是打开一层可编程的计算空间。Agent 可以在这层空间中自发编写、执行、读写、搜索、思考,从而按需生成任何新的工具。
Claude Code 的元工具集是典型例子(共 6 个核心工具):
-
• Bash:执行 shell 命令 → 无限扩展空间 -
• Read:读取文件 -
• Write:写入文件 -
• Edit:编辑文件 -
• Glob:搜索文件 -
• Think:内部推理空间
凭借这六个工具,Claude 可以自己编写 Python 脚本分析数据(业务工具 #3),通过 curl 调用外部 API(#1),操作数据库(#2),生成图像(#7),甚至动态安装 MCP 服务器来挂载新的扩展工具(#all)。
元工具的核心优势:
-
• 极低 Token 开销:仅传 6 个工具定义,而不是数百个,大幅节省上下文窗口 -
• 无限可扩展:Agent 可以自己构建它需要的任何工具,上限由计算环境而非工具列表决定 -
• 决策空间小:6 选 1 远比 100 选 1 容易,减少模型幻觉
什么是扩展工具?
扩展工具是预先定义的、面向具体业务场景的专业工具。如下是一些主要应用场景:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
它们是元工具的可组合产物。它们不是 Agent 的“内置能力”,而是通过元工具动态安装、调用或自行构建的外部能力。
这类工具通常通过以下方式提供:
-
• MCP(模型上下文协议):标准化工具接口,允许第三方提供任意专业工具(数据库、API、文件处理…) -
• Skills:预设的工具组合和工作流,用于完成特定领域的复杂任务
两层模型的协作关系
元工具 (bash, read, write, ...) │ ├─→ 直接完成基础操作(读文件、运行命令) │ └─→ 动态构建/调用扩展工具 ├─ 通过 bash + curl 调用外部 API ├─ 通过 bash + pip install 安装 MCP 客户端 ├─ 通过 write 生成 Python 脚本并执行 └─ 通过 Skills 工作流组合多个扩展工具💡 关键洞察:在本课程中的实例其实还是如何通过 API 中的 tools 以及 messages 中返回工具调用的信息,还是属于基础Tool Use的范畴,后续课程会包含MCP 以及Skills 的相关内容。
2.4 Tool Use 在 AI Agent 中的核心地位
到现在为止,我们已经从历史演进(2.2)和工具分层(2.3)两个角度把 Tool Use 的「是什么」「为什么」讲清楚了。这一节收束到一个更根本的问题上:
Tool Use 到底在 AI Agent 里扮演什么角色?
如果把 AI Agent 看作一个完整的智能体,那么:
-
• Prompt / 系统指令 是它的“人格与目标” -
• LLM 是它的“大脑”,负责理解与推理 -
• Memory 是它的“经验与状态” -
• Tool Use 是它的 “行动能力”——连接大脑与世界的唯一通道
没有 Tool Use,Agent 就只是一个会思考但无法做任何事的对话程序。有了 Tool Use,Agent 才能从「语言引擎」变成「行动引擎」。
Tool Use 与其他核心模式的关系
本模块的其他课程(Chaining、Routing、Parallelization)解决的是“任务怎么分解、怎么流转”的问题,但它们都建立在 Agent 能动手执行的基础上。所以:
-
• Tool Use 是 Agent 工作流模式(Routing、Parallelization 等)真正落地的物理层 -
• 没有工具,链式调用只是文本拼接;有了工具,每个节点才能调用外部服务 -
• 并行编排(Parallelization)的意义只有在工具可以同时执行时才成立
一句话:Tool Use 是让编排从纯文本游戏变成真实生产力的那一步。
设计核心:元工具优先
本章真正想传达的关键判断是——在一个成熟的 Agent 架构中,你不需要给 Agent 预先配备几十种业务工具。
你需要做的是:
-
1. 给 Agent 极少数精心定义的元工具(Shell、文件读写、搜索等),让它自己成为工具的构建者 -
2. 通过 MCP、Skills、AgentTool 等机制,按需挂载专业扩展工具 -
3. 让 Agent 自己决定什么时候构建、什么时候复用、什么时候组合
这样,Agent 的能力边界不再由你预先配置的工具列表决定,而是由元工具打开的计算环境自由度决定。这就是今天 Claude Code、OpenClaw 等一线系统验证过的最高效路径。
3. 架构图解
这个图解讲解 LLM 与框架(我们在测试中就是我们的应用程序,在Claude Code 或 OpenClaw 这样的工具就是它们的 Runtime)进行交互时的流程。
用户: "苹果股票现在多少钱?" │ ▼ ┌─────────────────────────────────────────┐ │ LLM (大脑) │ │ │ │ 输入: 用户问题 + 可用工具定义列表 │ │ │ │ 可用工具: │ │ ├─ search_information(query) → str │ │ ├─ get_stock_price(ticker) → float │ │ └─ send_email(to, subject, body) → ok │ │ │ │ 决策: "需要调用 get_stock_price('AAPL')" │ └──────────────┬──────────────────────────┘ │ 结构化调用: {name, args} ▼ ┌─────────────────────────────────────────┐ │ 编排层 (Framework) │ │ │ │ 解析 JSON → 找到函数 → 执行 │ │ result = get_stock_price("AAPL") │ │ result = 178.15 │ └──────────────┬──────────────────────────┘ │ 工具返回结果 ▼ ┌─────────────────────────────────────────┐ │ LLM (大脑) │ │ │ │ 收到工具结果: 178.15 │ │ 生成回复: "苹果股票(AAPL)当前价格 │ │ 为 $178.15" │ └─────────────────────────────────────────┘在这个流程中,LLM 作为大脑决定要使用哪些工具,框架 Runtime 按照 LLM 要求去 Use Tools,然后将工具执行的结果发还给 LLM ,让LLM 决定下一步继续做什么。
在一次调用中可能会涉及到多次这样的工具调用,这就是Agent 的核心 Loop Back。
多工具场景
Agent 同时面对多个查询(asyncio.gather 并行):Query 1: "法国首都是哪?" → LLM 决策: 调用 search_information("capital of france")Query 2: "伦敦天气如何?" → LLM 决策: 调用 search_information("weather in london")Query 3: "给我讲讲狗" → LLM 决策: 调用 search_information("dogs") → 触发 default具体情况可以参照下面的代码实例。
4. 代码实战
4.1 基础: 定义和使用工具
pi-mono 实现中,通过定义 tools 信息对工具进行定义:
import { Agent } from"@mariozechner/pi-agent-core";import { getModel } from"@mariozechner/pi-ai";import { Type } from"@mariozechner/pi-ai";// === 定义工具(search_information)===const tools = [ {name: "search_information",description:"提供关于给定主题的事实信息。用于回答诸如'法国首都'或'伦敦天气'等问题。",parameters: Type.Object({query: Type.String({ description: "搜索查询短语" }), }),execute: async (_id: string, params: { query: string }) => {console.log(`\n--- 🔧 工具被调用: search_information('${params.query}') ---`);// 模拟搜索(simulated_results)constresults: Record<string, string> = {"weather in london": "伦敦目前多云,气温15°C。","capital of france": "法国的首都是巴黎。","population of earth": "地球人口约80亿。","tallest mountain": "珠穆朗玛峰是海拔最高的山峰。", };const key = params.query.toLowerCase();const result = results[key] ??`模拟搜索 '${params.query}': 未找到具体信息,但这个话题很有趣。`;console.log(`--- 工具结果: ${result} ---`);return {content: [{ type: "text"asconst, text: result }], }; }, },];// === 创建 Agent ===const agent = newAgent({initialState: {systemPrompt: "你是一个有用的助手。使用提供的工具来回答问题。",model: getModel("minimax-cn", "MiniMax-M2.7"), tools,messages: [], },});agent.subscribe((event) => {if ( event.type === "message_update" && event.assistantMessageEvent.type === "text_delta" ) { process.stdout.write(event.assistantMessageEvent.delta); }});// === 运行(三个并行查询)===asyncfunctionrunQueries() {const queries = ["法国首都是哪里?","伦敦天气怎么样?","给我讲讲关于狗的事情。", ];for (const q of queries) {console.log(`\n--- 🏃 查询: '${q}' ---`);await agent.prompt(q);console.log("\n--- ✅ 完成 ---\n"); }}awaitrunQueries();4.2 进阶: 带错误处理的业务工具
返回结构化的错误信息,让 Agent 自己决定怎么处理:
// Raising a specific error is better than returning a string.// The agent is equipped to handle exceptions and can decide on the next action.const stockTools = [ {name: "get_stock_price",description:"获取给定股票代码的最新模拟股价。返回价格浮点数。" +"如果代码不存在则返回错误信息。",parameters: Type.Object({ticker: Type.String({ description: "股票代码,如 AAPL, GOOGL, MSFT" }), }),execute: async (_id: string, params: { ticker: string }) => {constprices: Record<string, number> = {AAPL: 178.15,GOOGL: 1750.3,MSFT: 425.5, };const price = prices[params.ticker.toUpperCase()];if (price !== undefined) {return {content: [{ type: "text"asconst, text: `股价: $${price}` }], }; } else {// 不抛出错误,而是返回错误信息让 Agent 决定如何处理return {content: [ {type: "text"asconst,text: `错误: 找不到代码 '${params.ticker.toUpperCase()}' 的模拟价格。`, }, ], }; } }, },];// financial_analyst_agentconst financialAgent = newAgent({initialState: {systemPrompt: `你是一名资深金融分析师。使用提供的工具查找股票信息,给出清晰、直接的答案。如果工具返回错误,请明确告知用户无法获取该股票价格。`,model: getModel("minimax-cn", "MiniMax-M2.7"),tools: stockTools,messages: [], },});financialAgent.subscribe((event) => {if ( event.type === "message_update" && event.assistantMessageEvent.type === "text_delta" ) { process.stdout.write(event.assistantMessageEvent.delta); }});// 测试成功和失败两种情况await financialAgent.prompt("苹果公司(AAPL)的模拟股价是多少?");// → "苹果公司(AAPL)的模拟股价为 $178.15"await financialAgent.prompt("特斯拉(TSLA)的模拟股价是多少?");// → "抱歉,无法获取 TSLA 的模拟价格。"4.3 高级: 工具钩子(pi-mono 独有能力)
pi-mono 提供 beforeToolCall 和 afterToolCall 钩子,通过Hook可以方便介入工具调用流程:
const agent = newAgent({initialState: {systemPrompt: "你是一个研究助手。",model: getModel("minimax-cn", "MiniMax-M2.7"),tools: [searchTool, stockTool, emailTool],messages: [], },// 工具执行前: 日志、参数校验、权限检查beforeToolCall: async (toolName, args) => {console.log(`[审计] 工具调用: ${toolName}(${JSON.stringify(args)})`);// 安全检查: 邮件工具需要确认if (toolName === "send_email") {console.log("⚠️ 邮件发送需要用户确认!");// 返回 false 可以阻止工具执行// return false; }// 参数转换/增强if (toolName === "get_stock_price") { args.ticker = args.ticker.toUpperCase(); }return args; // 返回修改后的参数 },// 工具执行后: 日志、缓存、结果转换afterToolCall: async (toolName, args, result) => {console.log(`[审计] 工具完成: ${toolName} → 成功`);// 可以修改结果再返回给 LLM// 例如: 格式化、脱敏、缓存return result; },});实用场景: 审计日志、参数校验、权限控制、结果缓存、敏感信息脱敏。
5. 要点总结
|
|
|
|
|
|
六步生命周期 |
|
|
|
LLM 不执行工具 |
|
|
|
Tool > Function |
|
|
|
工具描述是关键 |
|
|
|
错误处理交给 Agent |
|
|
|
六大应用场景 |
|
|
|
pi-mono 钩子增强 |
|
6. 动手练习
练习 1: 基础 (⭐)
运行 4.1 的代码。修改 simulated_results 字典,添加更多条目。观察 LLM 如何选择匹配的工具。
练习 2: 进阶 (⭐⭐)
实现 4.2 的股票查询 Agent。额外添加第二个工具 get_company_info(ticker),返回公司简介。测试 Agent 如何在一次查询中决定调用一个还是两个工具。
练习 3: 挑战 (⭐⭐⭐)
实现 4.3 的工具钩子系统。具体要求:
-
• beforeToolCall: 记录审计日志,如果工具是send_email则打印警告 -
• afterToolCall: 统计每个工具被调用的次数和平均耗时 -
• 运行 5 个不同查询后,输出工具使用统计报告
7. 延伸阅读
-
• 🔗 OpenAI Function Calling: https://platform.openai.com/docs/guides/function-calling -
• 🔗 LangChain Tools: https://python.langchain.com/docs/integrations/tools/ -
• 🔗 Google ADK Tools: https://google.github.io/adk-docs/tools/
-
本文为模块二(核心工作流模式)的最后一篇,整个模块二的内容如下: -
跟我学 AI Agent : 第 3 课 — Prompt Chaining: 串联分解复杂任务 -
跟我学 AI Agent : 第 4 课 — Routing: 条件路由与动态分流 -
跟我学 AI Agent : 第 5 课 — Parallelization: 并行加速独立任务 -
跟我学 AI Agent : 第 6 课 — Tool Use: 让 Agent 拥有双手