 夜雨聆风
夜雨聆风





商标代理笔记与AI共事——把商标驳回复审做成一条流水线

做商标驳回复审的同行多多少少都干过这些事,因为客户给的号码末位写错,把申请号反复输入八遍。
引证商标的注册人是个食品公司,审定公告期号、专用期限、类似群、已删商品、待删商品散落在驳回通知书里,要一格一格抄。
第 10 条第 1 款第 8 项的逐项排除(审查指南§3.8.1—§3.8.3.12),写一遍要查 12 个子项。
客户最关心的从来不是法条,而是”成功率多少”、”花多少钱”、”什么时候出结果”——这三个问题的答案,都得从一堆不那么结构化的事实里推出来;
这些事,重要、重复、需要专注、又最容易出错。是律师工作里典型的”高级文员活”。
我断断续续花了一个月时间,把曾经处理过的近百份驳回通知书、驳回复审理由归类、整理,然后把这套流程做成了一个 AI 工作流。

这不是一个对话窗口里临时写的提示词,而是一套结构化的系统:七个 Agent(你可以理解成七个不同分工的 AI 律师)、十几条规则文档、四个填写模板、一个完整的演示案件、一个内部先例库。
拿到一份驳回通知书,从解析到出复审申请书草稿和客户意见书草稿——理论上 30–45 分钟。
这套东西现在装在一个文件夹里,理论上可以整个复制给任何人,在自己电脑上 5 分钟就能跑起来。
接下来要讲的,就是这个文件夹里到底装了什么、它怎么工作、新人怎么上手。
一、它把驳回复审拆成了七个工序
流水线不是抽象概念。把商标驳回复审的代理工作拆成了七个工序,每个工序由一个 Agent 负责,干净利落,互不越界。
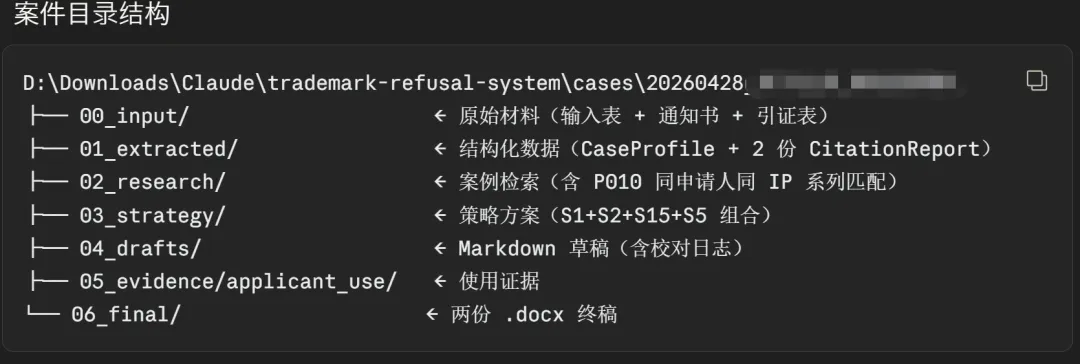
NOTICE_ANALYZER(通知书解析)——读通知书。把法条、申请号、引证商标、被驳回的商品/服务、复审截止日期,从一份扫描件里提炼成结构化数据。能识别多类别、多引证、HTML 表格、机关名称等这些常见异常。
CITATION_ANALYZER(引证商标分析)——查引证商标。这个 Agent 不是简单看一眼”还在不在”,它会做”权利人全景分析”:注册人名下还有没有别的近似商标(防止”撤掉一个,备胎上位”)、被攻击历史、市场共存生态。
RESEARCHER(案例检索)——找可比案例。先查机构内部沉淀的先例库,再查外部权威数据库。先内部、后外部这个顺序很重要——同行的实战经验比公开案例的论证价值往往更高。
STRATEGIST(策略制定)——制定策略。穷尽式评估 15 种策略组合(S1 正面论证不近似、S2 撤三、S3 无效宣告、S4 共存同意书、S5 使用证据……一直到 S15 中止审查),分乐观、中性、保守三档给出成功率,禁止使用”有一定希望”、”不好说”这类模糊措辞。
WRITER(复审申请书起草)——这是最重的一环。背后有一套”强制写作规程”:第 11 条第 1 款案件要逐项比照《商标审查审理指南》§3.1—§3.4 全部 16 项情形,第 10 条第 1 款第 7 项要逐项比照 §3.7.1.1—§3.7.3,不得省略。每个案件按驳回理由的具体类型选择论证模块,不会用同一套通用模板敷衍。
ADVISOR(客户意见书起草)——起草客户分析意见书,含日文摘要。客户能看到的是成功率三档评估、方案选项、费用明细、时限提醒、需要客户确认的事项清单——而不是一堆法条。日文摘要会调用专门的日文翻译技能(cn-to-jp-legal-translation),译出来的不是机翻味,是符合日本弁理士、商标代理人专业语感的措辞。
POSTMORTEM(案件复盘)——这是第七层,独立于主流水线。复审决定下达后,代理人填一份复盘表,POSTMORTEM 会把案件结果、有效论点、新论证标签自动写回内部先例库。先例库随用而长——这是机构经验沉淀最关键的一环。
七个工序,前六层处理”接到一份新案件”,第七层处理”完成一份老案件”。前者面对未来,后者沉淀过去。
二、三道门禁,让 AI 不会”自己写飞”
用过大语言模型写作的人都知道一件事:它什么都能写,包括它不知道的东西。
案号能编,法条号能错,机构名能写错,引证商标号能凭空蹦出来。
这套工作流装了三道门禁,专门防止这件事。
第一道:使用证据输入门禁。WRITER 进入终稿撰写之前,必须确认申请人的使用证据已交付,或者客户书面确认无证据,或者代理人明确指示”先出待补证据版”。三个条件都不满足,WRITER 不动笔,只输出一份”使用证据待补清单”,按驳回理由类型给出定制化的证据清单(相对理由要哪些、第 11 条要哪些、第 10 条第 7/8 项要哪些)。
为什么要装这道门禁——因为代理人都知道,使用证据是驳回复审论证质量的关键支柱。证据没到位就动笔,等证据到了又得改一遍,反而慢。节奏对了,事情就快了。
第二道:终稿校对输出门禁。Markdown 草稿转 .docx 之前,强制调用 legal-fact-checker 跑一遍七类核查:
1.法条引用(条款项是否准确)
2.案号格式(是否编造或拼错)
3.机构名称(旧称”国家工商行政管理总局商标评审委员会”必须改成现行机构)
4.申请号、注册号位数(一般 8 位)
5.商标名称在文书首部、正文、结论中是否完全一致
6.法律术语(”近似”vs”相同”、”驳回复审”vs”不服复审”等表述是否统一)
7.错别字与标点
校对结果存到一份独立日志(factcheck_log.md),存疑项标注后等代理人确认才放行。
第三道:先例库写回脱敏门禁。POSTMORTEM 把案件写回先例库时,会自动脱敏申请人名、内部代理文号、第三方个人姓名、身份证号片段,并自动去重、自动同步检索索引。
一头一尾,加一道归档把关。这是给”零虚构”原则装的三个安全锁。
三、怎么用?三步走
工具再好,跑不起来也是摆设。
这套系统的使用门槛被压到了”会复制粘贴文件夹”的程度——
第一步:把整个文件夹放到电脑上。
Windows 用户放在 D:\Downloads\Claude\(这是我的设置目录,可修改),Mac 用户放在桌面也行。系统不挑位置。打开 INSTALL.md,按里面的清单装一下 Python 库(一行命令)、确认仿宋/楷体字体(生成 docx 用),就可以了。整个准备过程不超过 10 分钟。
第二步:复制一个案件目录。
文件夹里有一个 cases/_TEMPLATE/ 目录——把它整个复制粘贴一份,改成 20260101_你的商标名_你的申请号 这样的名字。然后把驳回通知书(PDF、图片、Word 都行)丢到 00_input/original_files/ 里。
一点小建议,可以把驳回通知书、引证商标信息等转换成md格式(在线工具转换https://mineru.net/),AI处理起来省token。
第三步:告诉系统一句话。
在 Cowork(或者其他 Claude 客户端)里说一句:
“请处理 D:/Downloads/Claude/trademark-refusal-system/cases/[你的目录名] 这个案件,按完整模式。”
然后等。系统会按七个工序依次走。每一步走完会暂停,让代理人确认信息再往下走。你不会被关在黑箱外面——每个节点你都看得见、改得动。



大约 30–45 分钟之后,06_final/ 目录里会出现两份 .docx——一份复审申请书、一份客户意见书。

我特别为这套流程准备了一个完整的 DEMO 案件——虚构脱敏的”晨曦星语”驳回案,从输入表到复盘报告,全套产物 13 个文件齐全。新同事第一次用这套系统时,可以先跑一遍 DEMO,看看每一步出来的东西长什么样。


真的就这么简单。
四、它真正改变了什么
做这个工作流的初衷真正想解决的是——律师的时间,到底应该花在哪里?
一份驳回复审里,真正需要”律师判断力”的,其实只有几件事:
第一,引证商标的可攻击性预判(撤三胜算多大?);
第二,策略组合的取舍(撤三 + 中止 vs 共存同意 vs 不近似论证,配比多少?);
第三,给客户的诚实成功率区间(不是”有可能”,是 45%—60%);
第四,关键论点的策略表达(同样的事实,先打哪一刀?);
第五,客户决策的引导(要不要重新设计?要不要谈判?)。
这些事,AI 替代不了。也不应该替代。
但围绕这些”判断”的所有”准备工作”——通知书结构化解析、引证商标全景检索、可比案例查找、文书框架搭建、法条逐项比照、案号格式核对——这些事 AI 比律师快 10 倍,错得还更少。
用这套系统跑过手工做过的老案件,节省的时间大致是 70%。
更重要的是节省的”心智带宽”。从前接到驳回通知书,第一反应是”又来活了”;现在第一反应是”AI 把基础工作做完之后,重点看哪几个判断点”。
这是从”打字工”到”判断者”的角色升级。

五、写在最后
这套系统是开放的,不是黑盒子。所有规则都写在 markdown 里——SOUL(系统理念)、AGENTS(七层架构)、SCHEMAS(数据格式)、WORKFLOW(流程说明)、INSTALL(安装说明),加起来约 30 份文档。任何同行拿到都可以按自己机构的实际经验改写——比如换掉先例库里的样本、调整成功率评估系数、增加自己擅长的策略组合。
一个建议:先跑一遍 DEMO,再用一个真实老案件跑一遍对照——你会很快看出 AI 在哪几步是真正帮你节省时间,哪几步是给你提供新视角,哪几步还需要代理人的判断力补位。
从事商标工作这些年,深知这一行的”重要但重复”的工作占了多大比例。也曾试过各种自动化工具(Excel 模板、Notion、Word 宏),但都解决不了”判断+写作”这两件事——直到大语言模型成熟。
这套工作流是多年实务经验沉淀的一部分。不完美,但能跑起来、能扩展、能让经验真正变成可传递的资产。
如果你正在考虑怎么让团队的经验沉淀下来,希望它能给你一种思路——经验不是写在脑子里,是写在结构化的工作流里。
心已出发,永远不晚。