 夜雨聆风
夜雨聆风





质谱研究|光谱AI大一统:SpectrumWorld如何成为化学分子的“读谱大师”
光谱AI大一统:SpectrumWorld如何成为化学分子的“读谱大师”
从红外到核磁,从信号识别到分子生成——上海AI实验室等机构发布SpectrumLab与SpectrumBench,首次用多模态大模型系统性挑战光谱学全任务。
📌 亮点速览
- 首个光谱学AI统一平台
—— SpectrumLab 覆盖数据处理、标注、评估全流程。 - 14项任务 × 10+种光谱
—— SpectrumBench 成为迄今最全面的光谱基准。 - 23款多模态大模型对决
—— Gemini-2.5-pro 综合封王,但生成任务仍是“滑铁卢”。 - 自动标注引擎 SpectrumAnnotator
从少量种子数据中自动生成高质量题目。 - 揭示模型“偏科”真相
:基础识别接近90%准确率,分子生成却暴跌至6.41%。 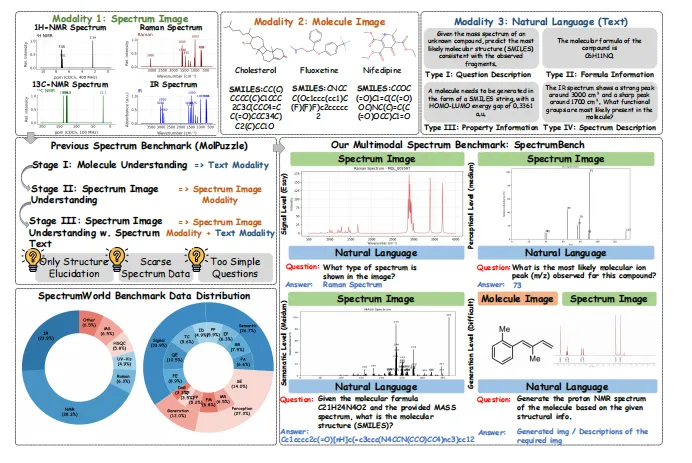
【图1】 SpectrumBench 总览图涵盖信号、感知、语义、生成四大层级,10余种光谱类型。
1. 当深度学习遇见光谱学:困境与破局
光谱学通过电磁辐射与物质的相互作用揭示分子结构,但长期以来面临数据稀缺、模态异构、基准缺失三大痛点。上海人工智能实验室联合多所高校推出SpectrumWorld (光谱世界),其核心包含两个组件:
- SpectrumLab
:模块化平台,集成Python库、数据标注器、评估器和公开排行榜。 - SpectrumBench
:多层基准套件,14个任务,超过120万种化学物质的光谱数据。
这是首次将多模态大语言模型(MLLM)系统性引入光谱学学习,试图弥合实验光谱与计算光谱之间的鸿沟。

【图2】 现有光谱ML方法分布按光谱类型(纵轴左)与模型架构(纵轴右)分类,多数方法仅聚焦单一模态。
2. SpectrumBench:四层递进的光谱“闯关”体系
研究团队仿照化学家分析光谱的真实思维链,设计了信号 → 感知 → 语义 → 生成四个层级,共14个子任务。
🔹 信号层 (Signal Level)
处理原始光谱数据的基础操作:光谱类型分类、质量评估、基本特征提取、杂质峰检测。例如判断一张谱图是红外还是核磁,或识别局部噪声。
🔹 感知层 (Perception Level)
从信号中识别化学模式:官能团识别、元素组成预测、峰归属、基本性质预测。比如根据红外吸收峰推断羟基或羰基。
🔹 语义层 (Semantic Level)
高级推理与跨模态融合:分子结构解析、多光谱模态融合、多模态分子推理。该层要求模型结合图谱与分子式等信息综合判断。
🔹 生成层 (Generation Level)
最具挑战的创造性任务:正向问题(分子→光谱)、逆向问题(光谱→分子)、从头生成。模型需要输出光谱图像或分子结构。
|
|
|
|
|---|---|---|
| 信号 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 感知 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 语义 |
|
|
|
|
|
|
|
|
|
|
| 生成 |
|
|
|
|
|
|
|
|
|
表2:任务类别与数据量统计。
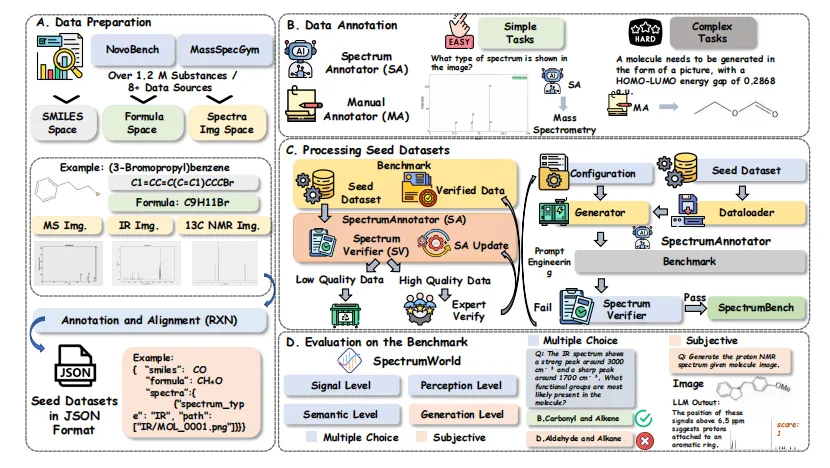
【图3】 数据策展管线从实验数据、公共库、文献挖掘到种子数据,经SpectrumAnnotator自动标注与人工审核。
3. SpectrumAnnotator:自动出题的“AI考官”
传统基准构建费时费力。SpectrumAnnotator 利用先进MLLM的零样本/少样本能力,基于种子数据自动生成多模态选择题和开放题。对于复杂任务,再由人类专家手动校准。随后通过 SpectrumVerifier 自动过滤低质数据,形成高质量闭环。
4. SpectrumLab 平台架构
SpectrumLab 提供三大模块:
- Benchmark Group 抽象
:灵活组合任务子集。 - 模型集成接口
:标准化API,支持云端/本地模型即插即用。 - 双评估器
:Choice Evaluator 用于选择题,Open Evaluator 用于生成题(由GPT-4o等评分)。
平台已集成23+主流MLLM,并公开排行榜。
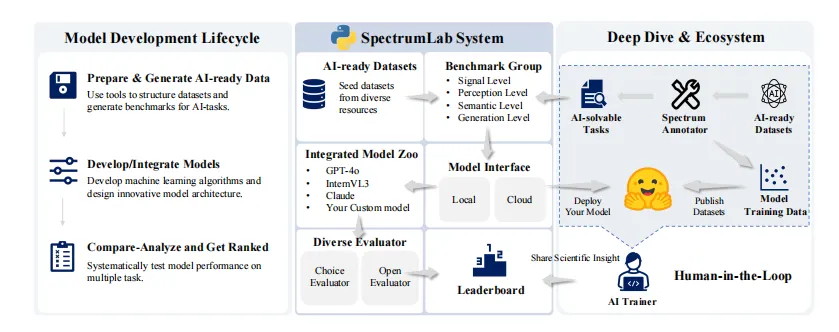
【图4】 SpectrumLab 模块化设计可扩展接入更多光谱模态与多模态大模型。
5. 23款大模型终极对决:谁是最强“光谱师”?
🏆 综合榜单
🥇Gemini-2.5-pro 以 67.81% 平均准确率登顶,在6/14任务中进入前二。🥈InternVL3.5-241B (65.50%) 与 InternS1-think (65.37%) 紧追其后,开源模型差距迅速缩小。

💡 关键发现一:任务越深,模型越“菜”
模型在信号/感知层表现稳健,但在质量评估(QE)中频繁翻车(均分仅30.65%),生成层更是集体“摆烂”。正向问题(FP)平均20.29%,逆向问题(IP)仅3.50%——模型能勉强从分子推光谱,但几乎无法从光谱反推分子。
🧠 关键发现二:“思维链”是生成任务的解药
Doubao-1.5-Vision-Pro-Thinking 在正向问题中砍下66.67%准确率,远超第二名Gemini-2.5-pro的50%。启用“思考模式”的模型(如InternS1-think)普遍优于其基础版,证明深度推理对跨模态科学任务至关重要。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表4/5:温度与Top-p采样对模型性能影响。小模型喜低温,大模型需高温释放能力。
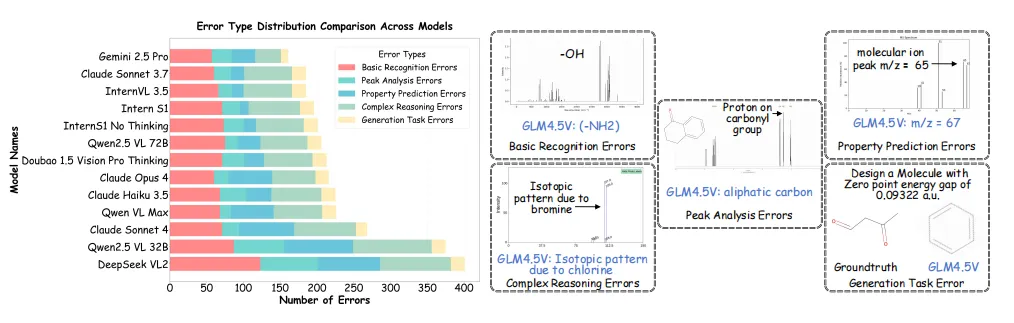
【图5】 错误类型分布基础识别与跨模态推理是两大主要瓶颈。
6. 错误深度剖析:模型到底错在哪?
研究团队将错误归为两大“家族”:
- 低级光谱感知失误
:无法区分局部噪声与真实信号,或对官能团特征峰张冠李戴(例如把羰基认成羟基)。 - 多步符号整合失败
:在融合分子式与多张谱图时推理链脆弱,尤其缺乏化学先验知识(如同位素峰比例、化学位移规则)。
🧪【图15/16/17】 典型错误案例左:官能团识别错误;中:峰归属混淆;右:多模态融合推理失败。
7. 成本与效率:跑完一轮基准要花多少钱?
完整运行SpectrumBench约需122万输入token,4.1万输出token。成本从Claude-3.5-Haiku的0.94美元到Claude-4-Opus的24美元不等,开源模型InternVL3-78B耗时120分钟但无API费用。
8. 展望:迈向光谱基础模型
SpectrumWorld 为AI光谱学设立了首个标准化竞技场,但其局限性亦很明显:目前仅支持选择题和少量开放式问题,且缺失XRD、荧光光谱等重要模态。团队呼吁社区共同扩展任务类型与评估指标。
“我们希望 SpectrumLab 能成为光谱学机器学习的关键基础设施,就像 ImageNet 之于计算机视觉。”
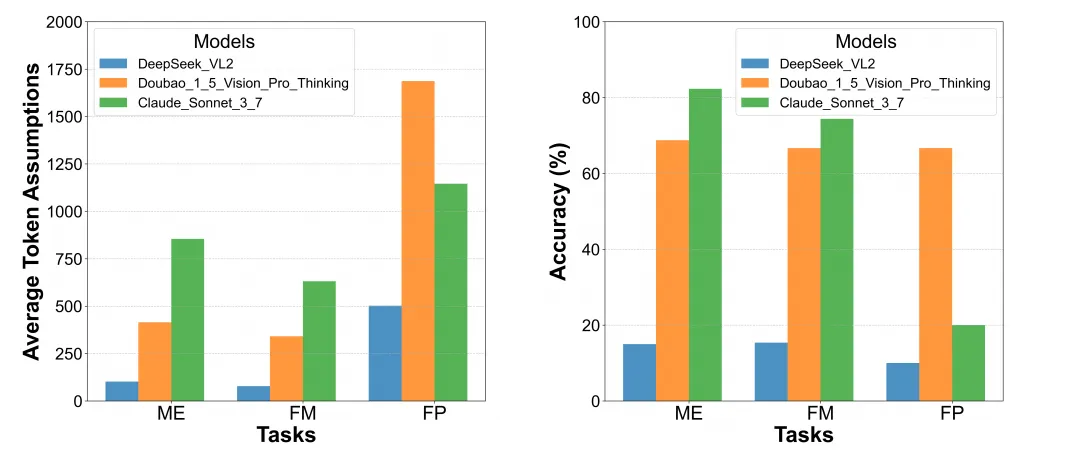
【图18】 模型准确率与推理token量关系更长推理链带来更高准确率,但也面临效率权衡。
论文地址:arXiv:2508.01188 代码:github.com/littled/SpectrumLab
点击蓝字
关注我们
科研猫猫猫

微信号丨x17585577064
可私信合作
扫码私信我进学术交流讨论群
关注我,分子网络/代谢组学不迷路!