 夜雨聆风
夜雨聆风





医疗AI Agent太笨?OpenAI:别骂“笨”,先补这三样东西
你会骂AI Agent笨吗?
当你的AI Agent又一次给出离谱的回答时,你的第一反应是什么?
我坦白:我骂它“笨”。😳

图:上周我刚刚骂完好笨
直到我看到OpenAI Codex团队的做法:
“When the agent struggles, we treat it as a signal: identify what is missing — tools, guardrails, documentation — and feed it back into the repository, always by having Codex itself write the fix.”
他们不责怪模型,不急着调参数。他们把每一次“卡住”当作一个信号——然后去检查:工具箱里少了什么?是工具不全,护栏没装,还是使用说明没写清?
那一刻我意识到:我变成了小孩子小时候最怕的那种父母——孩子考试不及格,劈头盖脸一句“你怎么这么笨”。却不去看看:是不是试卷超纲了?这个知识点我教过吗?他昨晚没睡好?还是压根没吃饱?
模型不会委屈,但它会持续犯错。而我们,会持续错过真正的问题。
我们为什么总想骂“笨”?
因为“归因于能力”最简单
当事情不如意时,人类大脑天生倾向性格归因(他不行),而非情境归因(环境不支持)。骂模型“笨”只需要1秒,而检查工具链、复盘流程可能要1小时。懒惰的大脑选前者。
因为“笨”这个词很解气,但毫无用处
骂孩子“笨”不会让他下次考好;骂模型“笨”不会让它自动学会新技能。真正有效的动作永远是:补上缺失的环节。Codex团队把它拆解为三类:
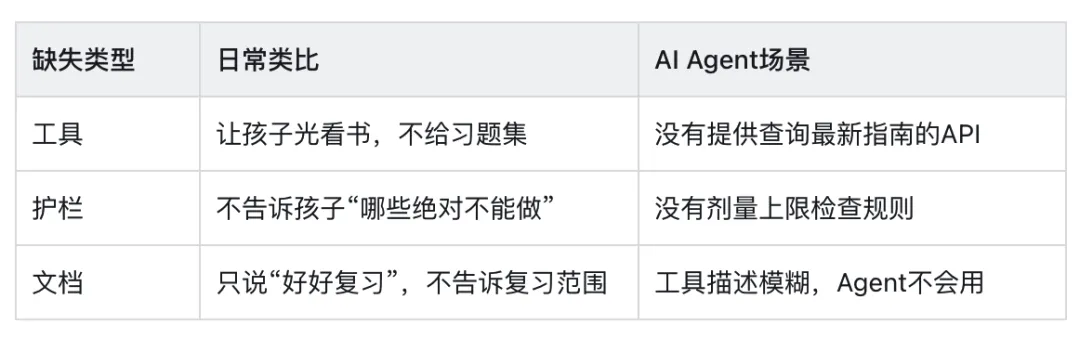
因为“骂笨”会掩盖系统的真正缺陷
医疗场景下,这个代价是致命的。一个分诊Agent漏掉心梗患者——我们可以骂它“笨”,然后花两周重新训练模型。但真正原因可能只是:它取不到心电图数据(缺工具),或者没有强制转急诊的规则(缺护栏)。改这两个,两小时。
深度洞见:我们骂模型“笨”,其实是在逃避自己的懒惰——懒得去理解系统,懒得去补漏洞。
为什么医疗AI尤其不能“骂笨”?
因为医疗的“错误”不是扣分,是生命
考试考砸了可以补考。但一个胰岛素剂量建议出错,可能是低血糖昏迷;一个过敏史忽略,可能是过敏性休克。骂一句“笨”很容易,但那个错误已经发生了。
因为医疗场景天然有“三缺”
医疗领域的AI Agent面临三个普遍缺失,任何一个都足以让它看起来“笨”:
1、缺工具
医院信息系统是孤岛,EMR、LIS、PACS互相不通。Agent想查个检验结果,要爬五个接口——还不一定爬得到。
2、缺护栏
临床路径复杂多变,同一症状可能是普通感冒,也可能是主动脉夹层。没有硬性护栏,Agent就会在低概率高风险的地方栽跟头。
3、缺文档
医疗知识更新快,指南年年变。Agent的“知识”停留在训练数据截止日,而真实世界每天都在变化。
一个真实案例:心梗分诊的“笨”是怎么来的
我在某个博主的文章评论区看到,某基层医院AI分诊Agent总是分错,例如频繁把急性心梗患者分流到普通内科。
1、传统归因:
模型太笨了,对心梗的心电图特征理解不足 → 重新标注1000份病历,两周后上线。
2、信号思维归因(Codex式三步检查):
(1)查工具
发现Agent根本拿不到心电图结论字段(接口未授权)→ 只能依赖医生输入的“症状描述”,而很多心梗早期只有胃痛、肩痛。
补工具:开通心电图读取API。
(2)查护栏
发现没有“高危胸痛强制升级”规则。哪怕Agent低置信度输出“普通内科”,也应该被拦截。
补护栏:增加一条硬规则:胸痛+出汗/恶心/放射痛 → 直接触发急诊警报。
(3)查文档
工具说明里没写“心电图优先级高于症状描述”。
补文档:明确调用顺序。
结果:三个低成本改动,无需重训模型。两周变成两小时。
这个案例的深度启示:模型从未变“聪明”过,它只是被提供了正确的“脚手架”。过去它看起来“笨”,是因为我们让它在一个残缺的环境里做事。
那什么样的人/团队,才能不骂“笨”?
他们有一种“工程耐心”
Codex团队的口号是:“优先使用无聊技术”。
什么意思?选择API稳定的、训练数据里高频出现的技术栈。不追新,不炫技。因为Agent对“无聊技术”更熟,犯错更少。

深度洞见:这种“无聊”不是保守,而是对复杂性的敬畏。知道什么会变、什么不该变,把稳定性建立在不变的基石上。
他们有一种“系统视角”
不骂模型“笨”的人,本质上持有一种系统思维:个体(模型/孩子)的行为 = 系统(工具/环境/规则)的输出。要改变输出,不改造个体,改造系统。
这跟现代医院安全管理如出一辙:“坏制度让好人做坏事,好制度让坏人也没机会。”
医疗不良事件的根本原因分析(RCA)从来不问“谁错了”,而是问“流程哪里有问题”。AI Agent也一样。
他们还有一种“成长型心智”
斯坦福心理学家卡罗尔·德韦克提出:固定型心智的人相信能力是固定的,失败意味着“我不行”;成长型心智的人相信能力可以通过努力和策略提升,失败只是“方法不对”。
骂模型“笨”是固定型心智——你认定它天生不行。
Codex团队是成长型心智——每次失败都是信号,告诉我们缺什么,然后补上。
这对医疗AI的启示:部署AI不是“一定要买一个最聪明的脑子”,而是建设一个让模型能持续表现良好的系统。系统需要迭代,而不是模型需要被骂。
落地:不骂“笨”之后,我们该做什么?
给所有医疗AI负责人、工程师、甚至管理者一份故障排查清单,按顺序走。
第一步:查工具
1、Agent能调取完成任务所需的所有数据/服务吗?
2、工具的输入输出格式,Agent理解对吗?(比如剂量单位是mg还是g?)
3、有没有外部依赖超时或变更?
第二步:查护栏
1、有没有应该被拦截却输出了的内容?(翻最近10条异常)
2、护栏规则覆盖了科室自定义的禁忌项吗?
3、有没有“低置信度→强制转人工”的兜底?
第三步:查文档
1、工具描述有没有写明“何时用、何时不用”?
2、有没有给出临床路径的步骤指引(而不是“请协助诊疗”这种废话)?
3、失败时有没有后备指令(如“查不到就请用户提供照片”)?
第四步:查技术栈
1、最近有没有引入未经充分验证的新模型/库?
2、能否用更成熟、文档更全的组件替换?
3、全链路日志能不能满足事后审计?
结语:从“责怪个体”到“完善系统”
写到这里,我想起一句话:
“如果一条鱼游得不好,不要教它爬树,先检查水是不是脏了。”
医疗AI的“水”,就是工具、护栏和文档。鱼游不好,不是鱼笨;Agent做不好,不一定是模型笨。
Codex团队的哲学,本质上是一种成熟的工程智慧:把失败当作信息,而不是耻辱。用系统补丁替代个人指责。
聪明的家长不会骂孩子笨,他会检查试卷难度、知识点漏洞、学习环境、营养状况。 成熟的医疗AI团队不会责怪模型,他们会平静地问:
“这次卡住,是在告诉我们缺什么?工具?护栏?还是文档?”
当我们停止骂“笨”的那一刻,我们才真正开始解决问题。
