 夜雨聆风
夜雨聆风





高校刮起“口试”风:AI时代,学生得能说出个所以然
一则美联社报道把美国高校正在发生的教育测评转型推向大众:
当学生的课后论文、代码、作业越来越“完美”,教师却在追问时发现学生讲不清思路,越来越多大学教师开始重新启用口试、面谈、现场答辩等古老的评价方式。
康奈尔大学生物医学工程课程要求学生在提交书面题集后参加20分钟左右的“口头答辩”;宾夕法尼亚大学有教师把书面论文和口试配套使用;纽约大学斯特恩商学院甚至尝试用语音AI代理开展个性化口试。

换句话说,AI时代的考试不只是“防作弊”,而是在追问一个更根本的问题:什么才算学生真正学会了?
一、“完美作业、空白眼神”:不是作弊问题,而是学习证据问题
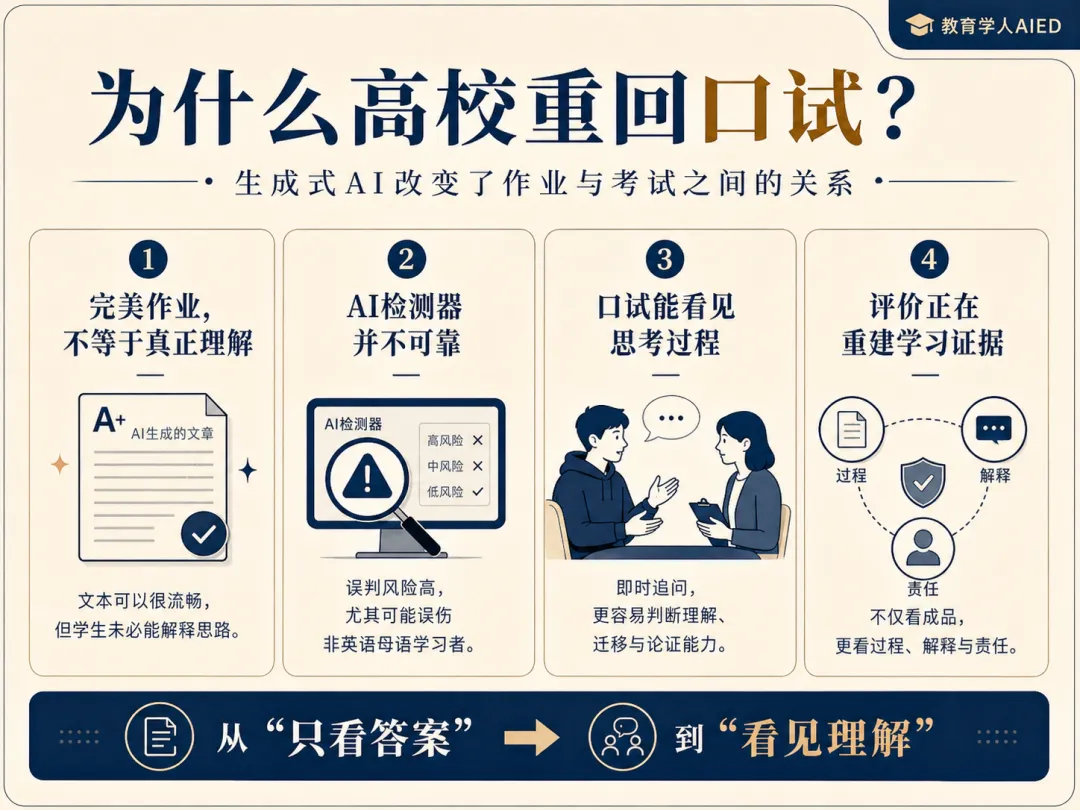
过去,教师常把一篇论文、一份作业、一段代码视为学生学习的主要证据。生成式AI打破了这个默认前提。
学生可以在几分钟内得到结构完整、语言流畅、格式规范的文本;但这份文本究竟来自学生的理解、学生与AI的协作,还是几乎完全由AI代写,单靠成品越来越难判断。

英国高等教育政策研究所与Kortext在2025年的调查显示,英国本科生中,报告使用过任何AI工具的比例从2024年的66%升至92%;使用生成式AI完成评估相关任务的比例从53%升至88%。
学生最常见的用途包括解释概念、总结文献、提出研究想法,同时也有学生直接把AI生成文本纳入作业。报告建议高校对所有评估进行“压力测试”,检查其是否能被AI轻易完成。
许多学校最初寄希望于AI检测器。但相关研究不断提醒我们:检测器并不能成为可靠的教育治理工具。

斯坦福HAI介绍的一项研究发现,七种AI检测器在非英语母语学生写作上存在明显误判风险,其中TOEFL作文样本有61.22%被判为AI生成;91篇TOEFL作文中,89篇至少被一种检测器标记。因此教育场景应谨慎依赖AI检测器。
更值得警惕的是,AI带来的不只是“抄袭风险”,还可能改变学生的学习努力结构。Bastani等人在一项近千名高中数学学生参与的田野实验中发现,使用类似ChatGPT-4的基础型AI助手能显著提高学生练习时的表现,但当AI帮助被拿走后,该组学生在测试中的表现反而低于没有使用AI的对照组;加入“不给直接答案、以提示引导”为特征的辅导型AI后,负面学习效应则得到缓解。
这个结果指向一个关键判断:AI可以帮助学习,也可以替代学习;关键在于任务设计是否让学生保留必要的认知努力。
二、为什么口试被重新提起?
口试并不新。博士答辩、医学面试、法律辩论、语言测试、牛津剑桥式导师制,都包含面对面阐释、追问和辩护。但在大规模现代本科教育中,口试因为耗时、评分一致性、学生焦虑等原因逐渐边缘化。AI的出现改变了权衡:当书面成品变得越来越容易外包,能够观察学生即时思考过程的评价方式重新变得重要。
口试的价值不在于“让学生紧张”,而在于它能让教师看到书面答案背后的理解质量。学生能不能解释为什么这样做?能不能在条件变化后迁移思路?能不能说出自己哪里不确定?能不能辨认AI给出的答案是否可靠?
这些问题很难从一篇作业论文中稳定判断,却可以在追问中暴露出来。
相关综述也支持这种判断。关于高等教育口头评价的一项系统综述指出,口试能够让考官与学生互动,从而区分表层知识与深层理解;在医学、护理、营销、金融等强调双向沟通的领域,口试也更接近真实工作场景。

该综述同时指出,口试可能带来焦虑、评分主观性、对内向学生或英语作为附加语言学生的不利影响,因此需要明确时长、统一问题、评分量规、评估者培训等设计来提升可靠性与公平性。
UC San Diego的工程教育研究提供了一个更具体的案例。研究团队在六门工程课程中让560名学生参加15分钟口试,并跟踪后续书面考试表现。

初步结果显示,教师主持口试组在第二次书面期中考试中的成绩提高14%,助教主持组提高3%,无口试组变化很小;70%的受访学生认为口试提升了学习动机。研究者认为,口试不仅能看出学生“会不会套公式”,还逼着他们不得不说明为什么在特定情境下使用某个知识。
三、口试不是“反AI复古”,而是“学习证据链”重构
把口试理解成“防AI作弊工具”,会低估它的教育意义。更准确地说,口试是把评价从“只看产出”转向“同时看过程、解释、迁移与责任归属”。

在AI时代,一份作业可以被拆成几类证据:
-
第一,学生提交的最终产品;
-
第二,学生生成这个产品的过程记录,包括资料检索、提示词、修改轨迹、同伴反馈;
-
第三,学生对AI使用的声明与反思;
-
第四,现场追问中呈现出的概念理解、推理路径与迁移能力。口试的作用,是把这些证据串起来,形成更可信的学习判断。
这也是当前国际高等教育评价改革的共同方向。TEQSA发布的“AI时代评估改革”资源指出,生成式AI加剧了高等教育原本存在的评价挑战,评估需要同时利用AI机会、管理AI风险;其后续资源进一步强调,机构要在保障学习成效的同时,支持学生负责任、合伦理地使用AI。

UNESCO关于生成式AI教育与研究的指南也强调,人本、伦理、安全、公平和有意义的使用,而不是简单禁用。
英国罗素大学集团的原则同样提出,高校应支持师生具备AI素养,调整教学与评价以纳入生成式AI的合伦理使用,同时维护学术严谨性与诚信。
因此,口试回潮并不意味着学校要回到“无技术时代”。相反,它提醒AIED研究者和教育实践者:AI越强,评价越要能看见人的理解、判断与责任。
四、口试也可以被重新设计
AIED不应只关注“AI如何教学生”,也要关注“AI时代如何证明学生真的学会了”。从已有案例看,至少有四种可操作的设计方向。
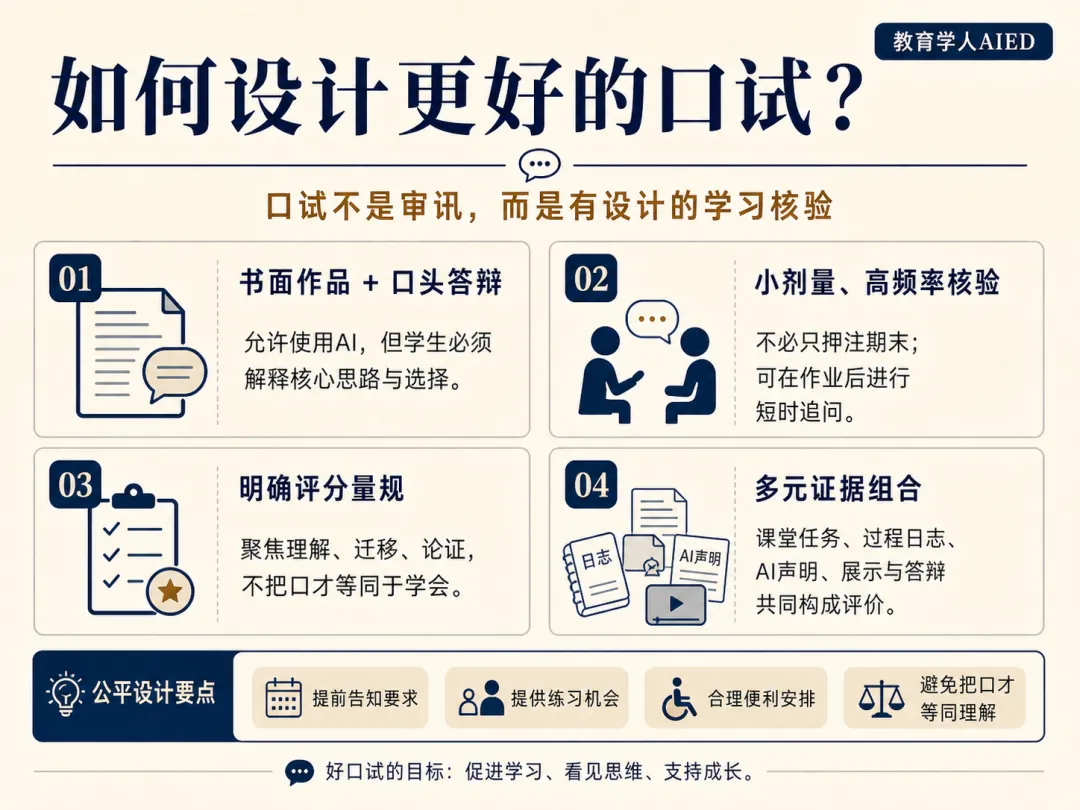
第一,书面作品+口头答辩。这适用于论文、项目报告、实验报告、代码作业、设计作品等任务。学生可以使用AI,但必须声明使用范围,并在答辩中解释核心选择:为什么选这个理论?为什么这样建模?为什么删掉AI建议中的某个部分?如果条件变化,结论是否仍成立?这种模式不是禁止AI,而是要求学生对成果负责。
第二,小剂量、高频率的“理解核验”。不必每次都做高风险期末口试。教师可以在大作业后随机抽取学生进行5—10分钟追问,也可以在小组项目中让每位成员单独解释自己负责的部分。康奈尔的案例中,有课程在70人规模下由教师与助教分担20分钟答辩,也有工程课程在180人班级中使用4分钟模拟面试。关键不是拉长考试时间,而是为学习证据增加一个“活的窗口”。
第三,允许AI进入现场,但不允许AI替学生思考。2026年一篇关于“会话式考试”的预印本提出,让学生在受监督环境中使用文档和有限AI工具,同时现场编程并解释推理过程;研究者在两天内完成58名学生的小组口试,认为这种形式把真实实践与即时表现结合起来。该研究仍处于预印本阶段,但它给出一个重要启发:AI时代的“安全评价”未必等于无AI评价,也可以是“有边界、有追问、有解释责任”的AI协作评价。

第四,AI可以辅助口试,但不应替代教师判断。纽约大学斯特恩商学院的Panos Ipeirotis尝试用语音AI代理开展口试,其预印本报告称系统为一门本科AI/ML课程完成36次口试,总成本约15美元,并通过多模型评分达到较高一致性;但论文也明确记录了失败模式,例如AI代理会一次堆叠多个问题、无法按要求随机化案例、克隆教师声音被部分学生感到不适。

这个案例的价值不在于证明“AI考官已经成熟”,而在于提醒我们:AI评价系统必须有结构化流程、人工复核、隐私保护和申诉机制,不能只靠提示词约束。
五、给学校和教师的三点建议
第一,不要把口试设计成“抓作弊审讯”。
如果学生把口试理解为惩罚和盘问,它会增加焦虑并伤害师生关系。更好的表达是:这是一次学习核验,也是一次反馈机会。教师可以提前公布题型、评价标准和示例问题,先从学生熟悉的问题开始,再逐步进入迁移与反思。
第二,不要让口试成为新的不公平。
口试可能不利于严重焦虑、语言表达困难、听说障碍、内向或缺少相关经验的学生。公平设计包括:提供练习机会,明确评分量规,允许合理便利安排,训练助教,使用双评或抽样复核,避免把“口才好”误判为“理解深”。
第三,不要只改一个作业,要改整门课的评价结构。
最稳妥的设计不是“全部改口试”,而是形成多元证据:课堂即时任务、过程日志、AI使用声明、同伴互评、书面作品、现场展示、短口头答辩。这样既能降低单一评价的偏差,也能避免教师工作量失控。口试应成为评价组合中的关键节点,而不是所有课程的唯一解。
结语:AI时代,教育得要求学生“说出个所以然”
生成式AI让教育评价进入一个新的阶段:答案越来越便宜,解释越来越珍贵;成品越来越相似,过程越来越关键;文本越来越流畅,理解越来越困难。
口试的回归,不是怀旧,也不是技术恐惧,而是教育对“学习证据”的一次再校准。未来的好教育评价,不一定是没有AI的教育评价,而是能够回答三个问题的评价:学生是否理解?学生是否能迁移?学生是否能对自己与AI共同生成的成果负责?
AI可以生成答案,但不能替学生拥有知识。真正的学习,终究要经得起追问。
主要参考资料:
[1] Gecker, J. (2026). Perfect homework, blank stares: Why colleges are turning to oral exams to combat AI. Associated Press.
——文章主新闻来源,支撑“美国高校重新使用口试应对AI作业”的基本事实。
[2] Freeman, J. (2025). Student Generative AI Survey 2025. Higher Education Policy Institute.
——支撑“学生大规模使用生成式AI完成学习与评估任务”的背景判断。
[3] Liang, W., Yuksekgonul, M., Mao, Y., Wu, E., & Zou, J. (2023). GPT detectors are biased against non-native English writers. Patterns, 4, 100779.
——支撑“AI检测器不能作为学术诚信治理的可靠基础,且可能误伤非英语母语学生”。
[4] Bastani, H., Bastani, O., Sungu, A., Ge, H., Kabakcı, Ö., & Mariman, R. (2025). Generative AI without guardrails can harm learning: Evidence from high school mathematics. Proceedings of the National Academy of Sciences, 122(26), e2422633122.
——支撑“AI可以帮助学习,也可能替代学习;关键在于是否保留学生的认知努力”。
[5] Nallaya, S., Gentili, S., Weeks, S., & Baldock, K. (2024). The validity, reliability, academic integrity and integration of oral assessments in higher education: A systematic review. Issues in Educational Research, 34(2), 629–646.
——支撑“口试能观察理解过程,但需要设计评分量规、支架和公平机制”。
[6] Lodge, J., Howard, S., Bearman, M. L., Dawson, P., & Associates. (2023). Assessment Reform for the Age of Artificial Intelligence. Tertiary Education Quality and Standards Agency.
——支撑“AI时代评价改革不能只靠防作弊,而要重构学习证据”。
