 夜雨聆风
夜雨聆风





开发者狂喜:F2这个Python库能下载所有平台作品

你以为只要有网就能下载,其实第一个坑就在“怎么批量拿”
我第一次做竞品分析的时候,手动打开抖音、TikTok、微博,一个一个复制链接,再找在线工具解析下载。一个账号分析完,半小时过去了,还经常遇到链接失效、画质压缩。后来用了一些开源下载器,发现它们要么只支持单一平台,要么跑着跑着就报错,还得折腾Cookie、Token。那时候我最大的错觉是:只要工具够多,就能解决问题。后来才明白——真正缺的不是下载器,而是一套能跨平台、自动化、还能顺手提取数据的脚本管线。
90%的人死在“手动重复”这件事上
你再怎么勤快,一天也手动扒不了50个视频。但做内容的人都知道,素材库的厚度直接决定选题效率。你看见一个同行发了爆款,想下载它的合集、点赞列表、甚至评论数据做深挖——手动操作一遍,可能连下载的耐心都没了。更常见的是:你下载了几个视频,觉得够了,结果等到自己要用时,发现少了几条关键内容,或者画质根本不是你要的版本。你不是不努力,你只是一直在做看起来很努力的事——一条一条地复制、粘贴、等待、保存。 方向不对,努力越多,偏得越远。真正该做的事,是先把“获取数据”这个环节变成一次配置、无限运行。
为什么很多人试过自动化工具还是放弃了?
不是工具不好用,是大多数人把顺序搞反了。他们先下载一个软件,然后对着命令行发懵,或者看到要配置Cookie就退缩。本质上,卡住不是因为智商不够,而是因为你没有先想清楚:我要从哪些平台、拿什么类型的数据、用多大频率、存成什么格式。当你没有这些判断,任何一个工具都会变成“看起来很强大但用不起来”的东西。另外,很多下载器只解决视频下载,但你需要的是“数据管道”——从用户信息、作品列表、直播流、弹幕,到文件名格式化、目录组织、甚至通知推送。如果中间缺了一环,你就得手动补,那自动化又变成了半自动。
真正管用的顺序,和你想的不一样
- 先定义你的“数据资产”清单
:别急着找工具。写下你关注的所有平台(抖音、TikTok、Twitter、微博),每个平台你需要拿什么:单个作品?整个主页?点赞记录?收藏夹?直播录播?弹幕?有没有需要实时监控的? - 评估获取难度
:哪些数据需要登录?哪些可以游客态访问?哪些可能要处理反爬签名?这一步决定你要不要用更高级的库,也决定你配置Cookie的复杂度。 - 选一个能统一管所有平台的脚本框架
:然后才是安装、配置、测试。测试时只跑一个账号的一个接口,确认通了,再扩展到批量。千万不要先装环境,再想做什么。
这个东西可以帮你省力气,但有前提
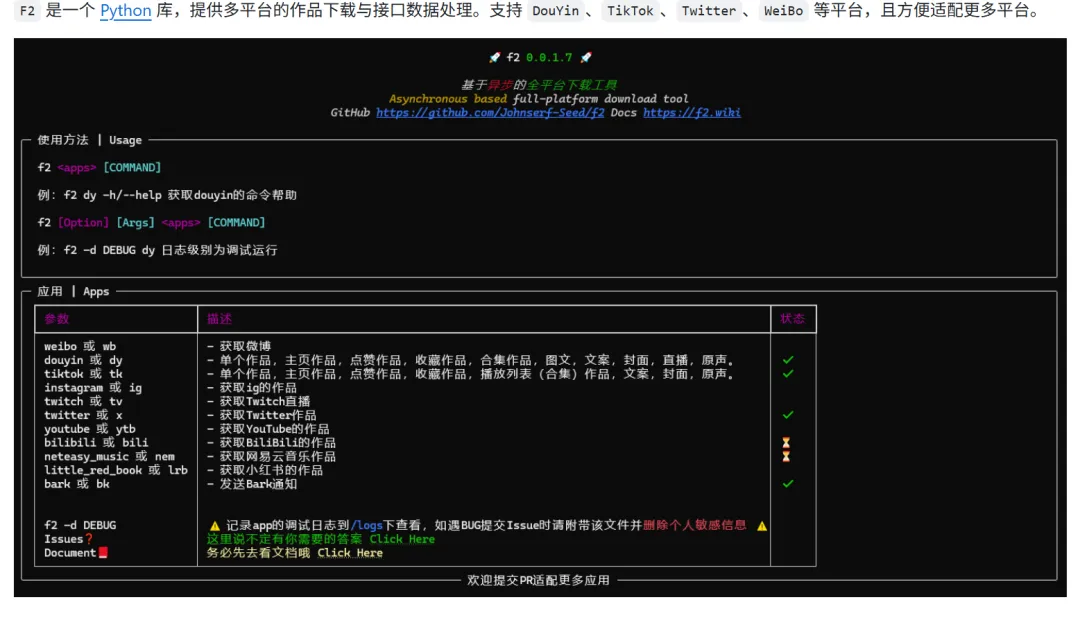
你当前阶段需要的,不是一个“更快的下载器”,而是一个能把多平台数据获取标准化、批量化、可编程的底层库。我最终用的是 F2,它是一个Python库,专门提供不同类型平台的作品下载与接口数据处理。它不是我需要运营的“核心产品”,而是我素材管线的“水管阀门”——一旦接好,就能自动流水。它能帮你补的短板是:把从“手动复制链接”到“存好文件夹”之间所有的重复劳动封装掉。
具体来说,它做三件事情:
-
统一了多个平台的API调用(抖音、TikTok、Twitter、微博、Bark通知等),你不用为每个平台写不同的网络请求。 -
内置了令牌生成、签名算法(比如抖音的ab算法、XBogus)、ID提取器,省去你在反爬上的研究时间。 -
支持直播流下载和弹幕转发,适合做实时分析或内容二次创作。 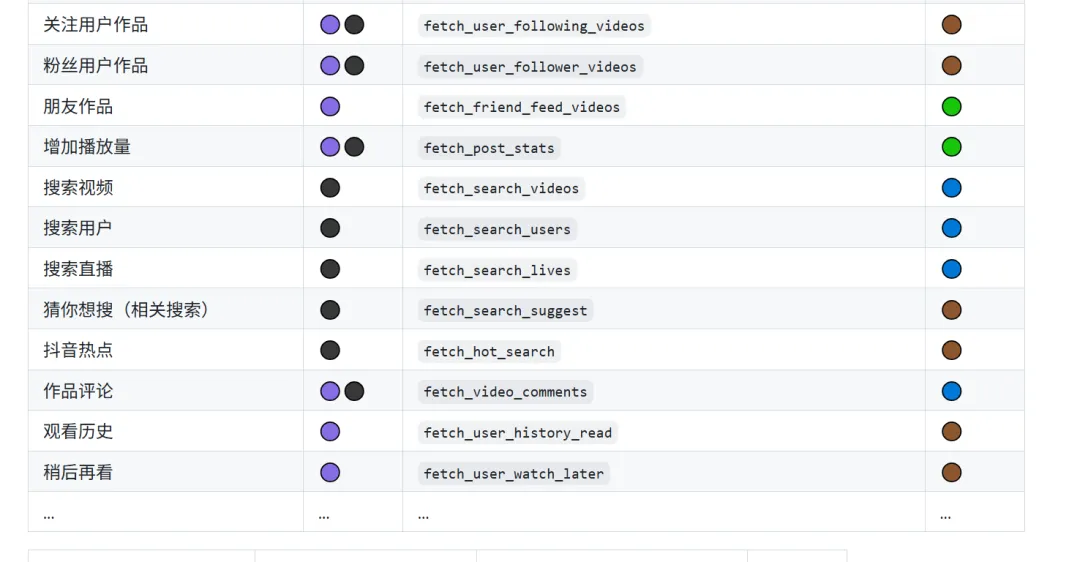
亮点与推荐用法:不是面面俱到,是每个点都打得准
根据它的README,我挑了几个最值钱的能力:
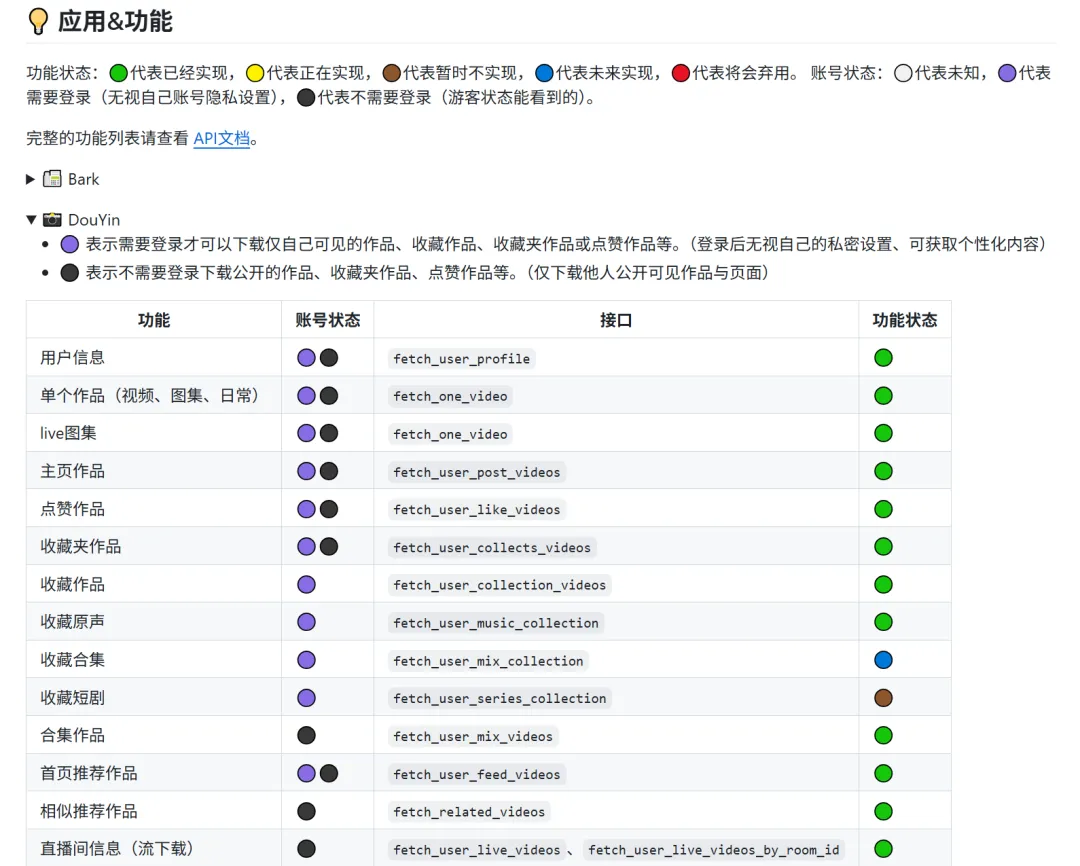
- 批量作品下载 + 数据提取
:比如抖音的 fetch_user_post_videos可以拉取某用户主页所有作品,fetch_user_like_videos拿点赞列表。配合AwemeIdFetcher提取作品ID,再批量下载。推荐用法:每周跑一次竞争对手主页,自动更新素材库。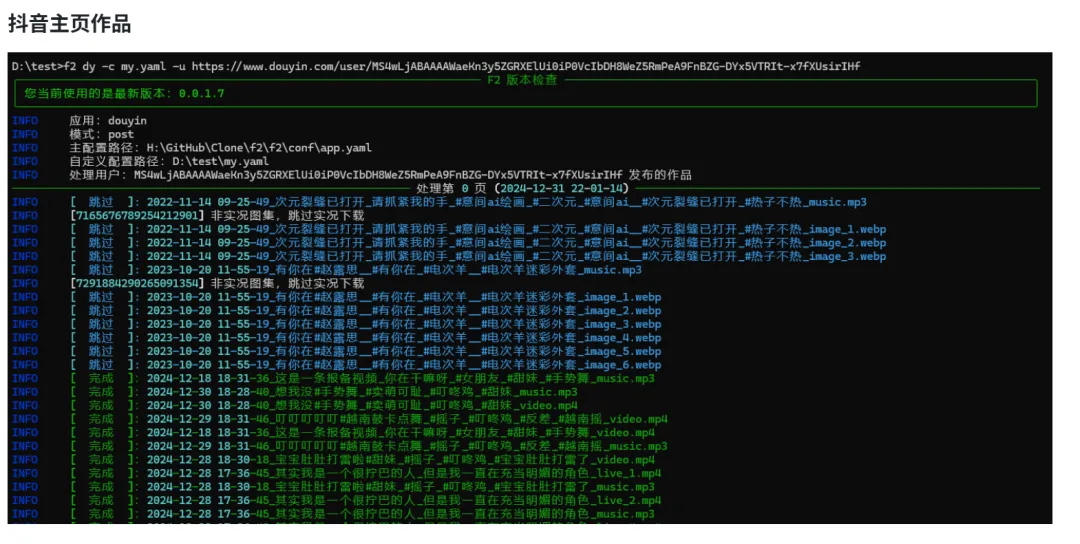
- 直播流录制与弹幕转发
: fetch_user_live_videos可以录制直播,fetch_live_danmaku获取弹幕。对做直播复盘、剪辑高光片段的人来说,这个功能是刚需。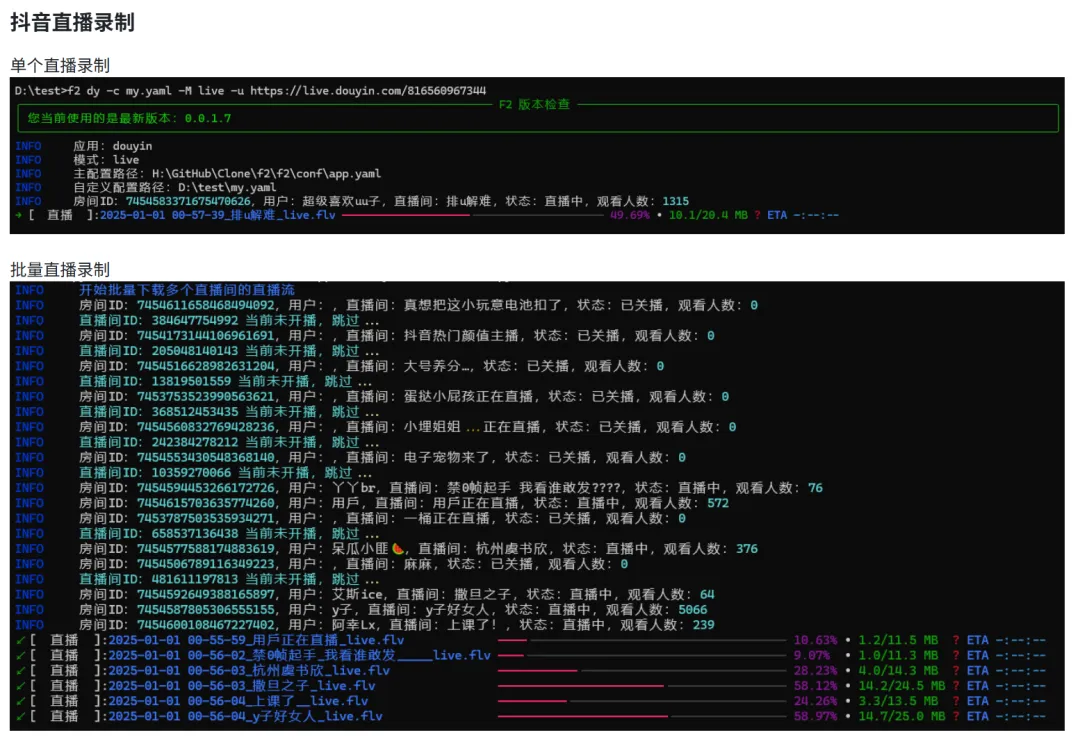
- 签名与Token管理
: ABogusManager、XBogusManager、TokenManager等工具类,让你不需要关心平台的反爬升级。推荐放在工作流最前面,定期生成新token避免封号。 - Bark通知推送
:下载完成后可以通过Bark推送到手机,适合无人值守下载场景。设置 enable_bark=true即可。
它只适合两类人,你是其中之一吗
适合:
-
内容运营、自媒体编导,需要持续监控竞品账号、批量获取素材进行分析或二创。 -
数据分析师 / 爬虫工程师,需要从多个社交平台采集公开数据,做趋势研究或模型训练。
不适合:
-
只是偶尔下载一两个视频的普通用户,用浏览器扩展或在线工具更快,没必要装Python环境。 -
对命令行完全零基础且不愿意学配置的纯小白(虽然文档有安装指引,但需要点动手能力)。
工具从来不是门槛,这个才是
普通人做不起来内容、跑不通数据,问题从来不是少一个“更好的下载器”。真正的差距在于:你有没有把重复劳动抽象成一次配置,然后让机器替你执行。 很多人宁愿每天花30分钟手动下载,也不愿意花2小时学一个工具。因为手动下载有“即时满足感”,而学工具需要延迟满足。但一个月下来,手动消耗了10小时,自动化只花了一次配置时间。想通了这件事,再决定下一步:你是继续“看起来很努力”,还是真正开始搭建数据管线。
想太多不如动起来
先从一个最小的闭环开始:选定一个平台、一个接口,配好环境,跑通一次下载。当你看到脚本自动下载完几十个视频、文件名整整齐齐归入文件夹时,那种“从被动搬运变主动设计”的感觉,才是你真正开始掌握自己的内容库。把这篇文章收藏起来,下次当你又想手动复制链接的时候,翻出来问问自己:我能不能用一行脚本、一个命令搞定它?
持续分享优质 AI 开源项目与源码实战,一个人摸索很容易踩坑。
对 Agent、智能体感兴趣的朋友,无论新手还是大佬,都欢迎一起交流。私信「时之」拉你进群。
想拿到仓库地址,直接动手试试?
GITHUB: https://github.com/Johnserf-Seed/f2