 夜雨聆风
夜雨聆风





AI技术暗线史 | 算力暴政:当计算成本决定技术方向
一个算法在纸上优雅了三十年无人问津,而它被载入史册的那一刻,只是因为有人终于买得起足够多的游戏显卡?
一、2012年秋天,那场其实不该发生的革命
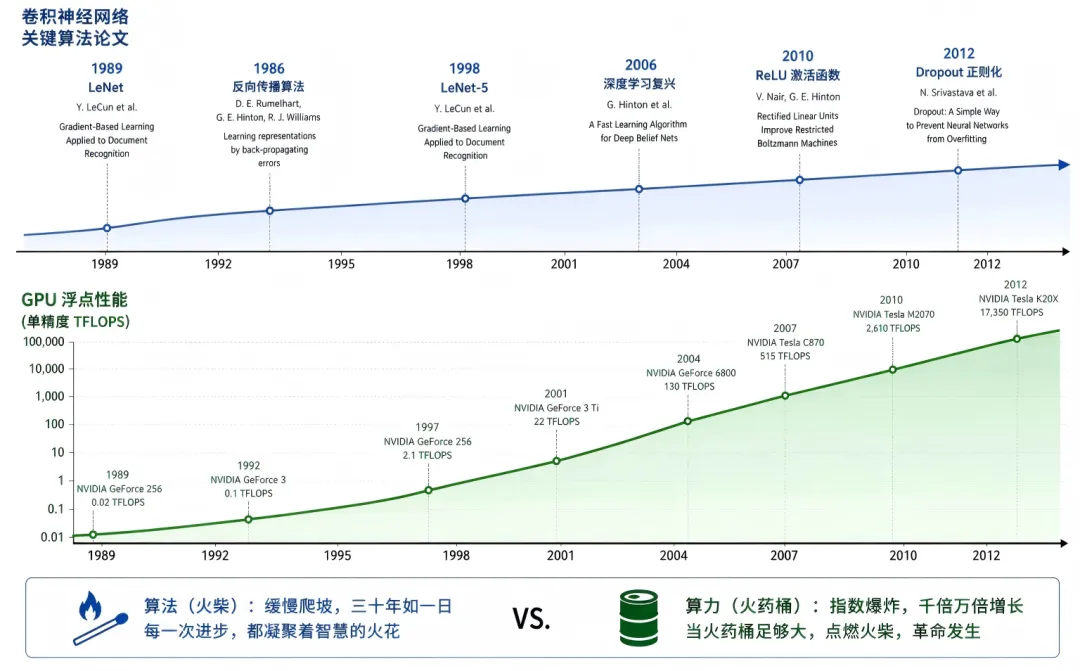
2012年9月,多伦多大学的一间实验室里,Alex Krizhevsky 正盯着屏幕上的训练曲线。他的卷积神经网络 AlexNet 正在 ImageNet 竞赛数据集上吞噬图片——120万张,1000个类别。两个 NVIDIA GTX 580 游戏显卡在机箱里嘶吼了六天。
最终,错误率:15.3%。第二名是26.2%。差距大到评委怀疑作弊。
但这里有一个被大多数人忽略的诡异细节:AlexNet 在算法层面几乎没有任何原创性突破。
卷积神经网络?Yann LeCun 在1989年就用 LeNet 识别手写邮编了。ReLU 激活函数?Hinton 团队在2010年证明了其在深度模型中的有效性,但那距离2012年也不过两年。Dropout 正则化?也是 Hinton 组2012年刚挂上 arXiv 的。GPU 通用计算?吴恩达团队2009年就在斯坦福做过 GPU 训练的稀疏自编码器。
AlexNet 真正的创新只有一件事:把所有这些已有组件,甩到两块 GPU 上去跑了一个足够大的数据集。
这不是一个算法故事。这是一个算力故事。
二、「苦涩的教训」:一段所有算法工程师都该读的墓志铭
2019年3月,强化学习先驱 Rich Sutton 写了一篇短文,标题只有两个词:The Bitter Lesson(苦涩的教训)。
他开篇就说:
「从70年的人工智能研究中可以得出的最大教训是:利用算力的通用方法,最终总是击败利用人类知识的专用方法。」
他列举了一系列令人难堪的历史案例:
-
计算机象棋:1997年深蓝击败卡斯帕罗夫,靠的不是精妙的棋局理解,而是一台使用专门 VLSI 芯片进行每秒数亿步 α-β 剪枝并行搜索的暴力美学机器。人类棋手试图把「棋理」编码进程序,结果被这台极度擅长大规模搜索的并行计算机碾压。 -
语音识别:1970年代,研究者花了大量精力构建音素、声学模型、语言学的规则体系。结果呢?2000年代,基于 HMM 的统计模型用更少的人类知识、更多的数据和算力,横扫了所有基准。 -
计算机视觉:SIFT 特征、HOG 描述子、Gabor 滤波器……整个90年代和2000年代,视觉研究者手工设计了成百上千种特征提取器。然后 ImageNet 来了,卷积神经网络来了,端到端学习把所有这些精巧的手工设计扔进了历史的垃圾堆。
Sutton 的结论残忍而诚实:研究者的心智资源是有限的,而算力的增长是指数的。 任何把人类知识硬编码进算法的努力,最终都会被「更通用但更能吃算力」的方法超越。
这不仅仅是技术判断。这是对 AI 研究范式的根本性质疑——我们津津乐道的「算法创新」,有多少只是算力红利到来时的顺势而为?

三、Scaling Law:当预言变成教条
2020年,OpenAI 发表了那篇注定改变行业走向的论文——Scaling Laws for Neural Language Models。
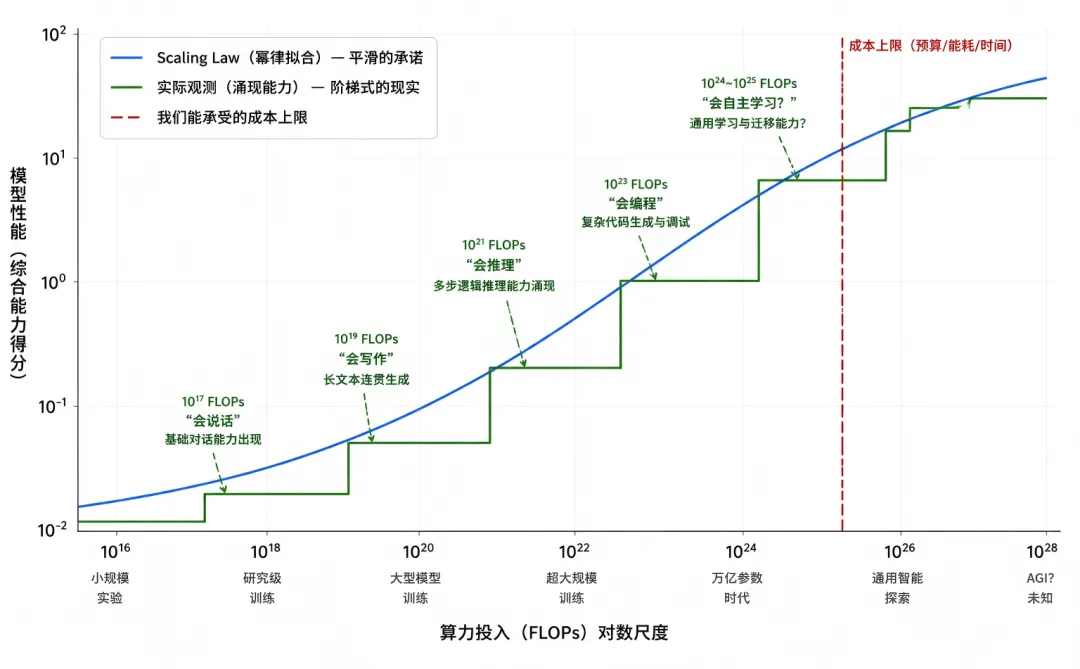
核心发现可以用一句话概括:模型性能(以交叉熵损失衡量)与模型参数量、数据量、算力投入之间,呈现跨越多个数量级的平滑幂律关系。
用更直白的话说:你花钱越多,效果就越好。而且这个规律不是线性的边缘递减,而是在对数-对数坐标上画出一条漂亮的直线——它似乎没有天花板。
这带来的后果是什么?
它把 AI 竞争从「谁更聪明」变成了「谁更富」。
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
1× |
|
|
|
|
|
~1,000× |
|
|
|
|
|
~10,000× – 100,000× |
|
|
|
|
|
~1,000,000× |
从几千美元到十亿美元,不过七年。这不是技术演进,这是军备竞赛。
Scaling Law 从一篇论文变成了某种准宗教信条:你不信 Scaling Law?那是因为你 scaling 得还不够。每一次模型能力的跃升——从 GPT-2 的笨拙到 GPT-4 的惊人——似乎都在为这个教条背书。
但这里有一个微妙的现实:Scaling Law 主要描述了训练损失的平滑下降,而某些高阶能力(如逻辑推理、代码理解)的涌现¹ 并非线性跟随,往往在算力投入超过某个神秘的阈值后,才突然展现。 这并非否定 Scaling Law——损失确实在降,能力也确实在涨——而是揭示了下游任务上的呈现方式远比单纯看 Loss 曲线更复杂、更具戏剧性。我们追逐的是幂律曲线,但真正想要的是阶梯跃迁。两者之间,隔着一段我们尚不理解的黑域。
¹ 学界对「涌现」的具体定义和存在性仍有争论(如 Anthropic 等机构认为某些所谓的「涌现」可能是评估指标选取造成的视觉错觉),此处指模型在特定任务上表现出的、远超预期规模对应的非线性跳跃。
四、DeepSeek 的反叛与 MoE 的复仇
2025年初,一条消息震动了硅谷:中国团队 DeepSeek 发布的 V3/R1 模型,性能逼近 GPT-4o 和 Claude 3.5 Sonnet,但训练成本据称仅为后者的十分之一甚至更低。
这怎么可能?
答案藏在 Mixture-of-Experts(混合专家) 架构里——一个在1991年就被提出的古老思想。
MoE 的原理可以用一个不精确但直观的比喻来理解:传统的 Dense 模型就像一家万人公司的全员大会——公司有一万名员工,但处理任何一个人的简单查询(比如「你们几点下班?」)时,这一万人都要站起来听一遍、思考一遍。 而 MoE 就像一个智能总机系统:它训练了一个「路由器」(gate),能自动判断来者的问题该分给电子工程师部还是客服部。公司总规模依然可以是一万人(总参数量巨大),但处理每件事时,只需要激活几个相关部门的专家(实际激活参数很少)。这让模型既「大」又「快」——大的是知识容量,快的是推理效率。
2017年,Google 把 MoE 塞进了 Transformer(Sparsely-Gated MoE),但训练不稳定、负载均衡困难——有的「专家部门」被挤爆,有的门可罗雀。2021年,Google 的 Switch Transformer 用更简洁的门控机制一定程度上缓解了这个问题。但真正把 MoE 从实验室搬进战场、并证明其商业可行性的,是 DeepSeek。
DeepSeek 的创新不在「发明」MoE,而在工程化的极致——包括辅助损失函数的精心设计(确保各个「专家部门」被均匀使用)、细粒度的专家切分、以及极致的通信优化。他们用约2048块 H800 GPU(受出口管制的降级版)训练出了对标顶尖水平的模型。
这不仅仅是技术路线的胜利。这是对「算力暴政」的一次正面反抗。
当 OpenAI、Anthropic、Google 在追逐十万卡集群、百万 GPU 数据中心时,DeepSeek 用了一个数量级更少的算力,撬动了相近的能力。这证明 Scaling Law 并不是唯一的游戏规则——效率同样是武器。

五、边缘计算:算力暴政下的一纸独立宣言
但反抗算力暴政的,不只有训练阶段。推理阶段同样在发生一场静默的叛乱。
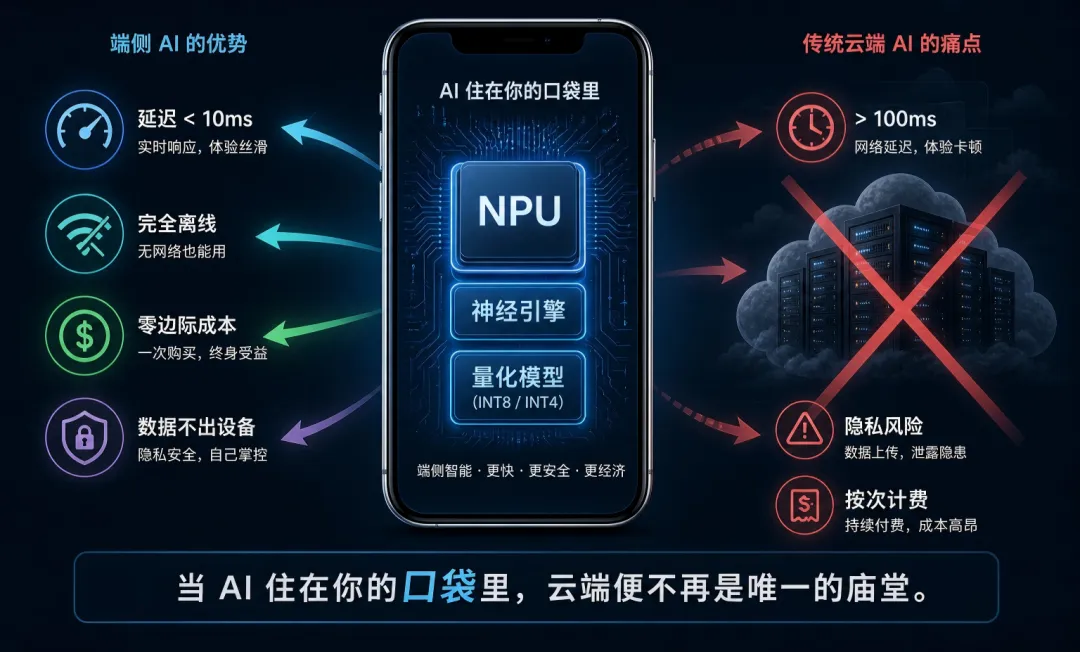
当前的主流范式是「云端大模型」:你的问题被加密传输到数千公里外的数据中心,经过数千亿参数的神经网络推理,再把结果传回来。这个模式的问题显而易见:
-
延迟:光线穿过光纤需要时间,GPU 推理需要时间。对于实时交互,每多50毫秒延迟,用户体验就下降一个档次。 -
隐私:你的每一次查询、每一段对话,都途经了别人的服务器。 -
成本:GPT-4 级别的推理,单次查询成本可能高达数美分。如果日活十亿用户呢? -
网络依赖:飞机上、地下车库、偏远地区——断网即断智。
因此,2024-2025 年,设备端 AI(on-device AI) 成为苹果、高通、联发科、Google 的共同押注方向:
-
苹果的 Apple Intelligence 在 A17 Pro / M 系列芯片上本地运行约 30 亿参数的语言模型,处理日常任务。十年前的手机跑一个 1B 参数的模型如同天方夜谭,而今天苹果凭借 A17 Pro 的 16 核神经引擎,已将 30 亿参数级别的 LLM 流畅地塞进了口袋——这在十年前是不可想象的成就。 -
在产品演示中,高通宣称骁龙 8 Gen 3 可以在手机上运行 100 亿参数的量化模型,峰值 token 生成速度可达 20 tokens/秒(具体性能取决于量化方案、上下文长度及运行环境)。 -
Google 的 Gemini Nano 在 Pixel 手机上本地处理短信摘要、键盘智能回复。
这是技术民主化,还是另一种收编?
细想一层:当 AI 能力被塞进芯片,控制算力的人就变成了控制芯片的人。 苹果控制着 iPhone 的神经引擎,高通控制着安卓阵营的 Hexagon NPU,NVIDIA 控制着几乎所有云端推理的 GPU。算力的主权从「谁有更多服务器」悄然转变为「谁定义计算架构」。
控芯者同样拥有巨大权力。但这与「算力暴政」的本质区别在于——至少,它把数据的主权,从遥远的云服务器,第一次真正意义上地交还到了用户的物理设备里。你的消息在你的手机上被摘要,你的照片在你的设备上被分类,你的语音在本地芯片上被转写。云端从未碰过这些数据。这不是暴政的终结,但它至少撕开了云端垄断的一道口子——一条通向另一种算力治理可能的裂隙。
我们到底在为什么买单?
回到开头那个问题:AlexNet 凭什么赢?
不是因为它更聪明。是因为两块 GTX 580 让它的浮点算力超过了同时代任何传统视觉系统的数百倍。是因为 ImageNet 数据集让它可以吃进比以往多三个数量级的标注样本。是因为摩尔定律的惯性恰好在那一年,把 GPU 的价格打到了一个博士生也能自费买两块的地步。
我们今天所处的 AI 时代,从某种意义上就是 AlexNet 故事的无限循环重播:
-
Transformer 架构(2017)之所以成为主宰,不是因为它在理论上比 LSTM 更优美,而是因为它天然适合并行化——天然适合吃算力。 -
GPT 系列的成功,不是因为它找到了通往 AGI 的秘径,而是因为它证明了「下一个 token 预测 + 足够多 token」这个极其简单粗暴的配方,在足够大的算力下可以产生令人恐惧的结果。 -
各家公司争先恐后地建设万卡集群,不是因为确信 Scaling Law 会永远有效,而是因为 「不确定哪条路能通向 AGI,但算力是所有路的共同起点。」
算力从未中立。它一直在悄悄选择赢家。