





文档内容
绝密★考试结束前
2025 学年第一学期浙江省 9+1 高中联盟高二年级期中考试
技 术
考生须知:
1.本卷满分100分,考试时间90分钟;
2.答题前,在答题卷指定区域填写班级、姓名、考场、座位号及准考证号并核对条形码信息;
3.所有答案必须写在答题卷上,写在试卷上无效,考试结束后,只需上交答题卷;
4.参加联批学校的学生可关注“启望教育”公众号查询个人成绩分析。
第一部分 信息技术(共 50 分)
一、选择题(本大题共12小题,每小题2分,共24分。在每小题给出的四个选项中,只有一个符合题目
要求)
阅读下列材料,回答第1至3题:
7月12日,台风“格美”逼近浙江沿海。浙江省防汛指挥中心连夜启用“智慧防汛平台”:沿海地区
水文传感器5分钟上报一次水位;平台把来源于传感器、气象卫星、监控画面、人工上报等多源数据绘制
成实时“风险一张图”,并标注可能淹没的街区;当区域综合风险指数>0.7时,系统自动生成“立即组织
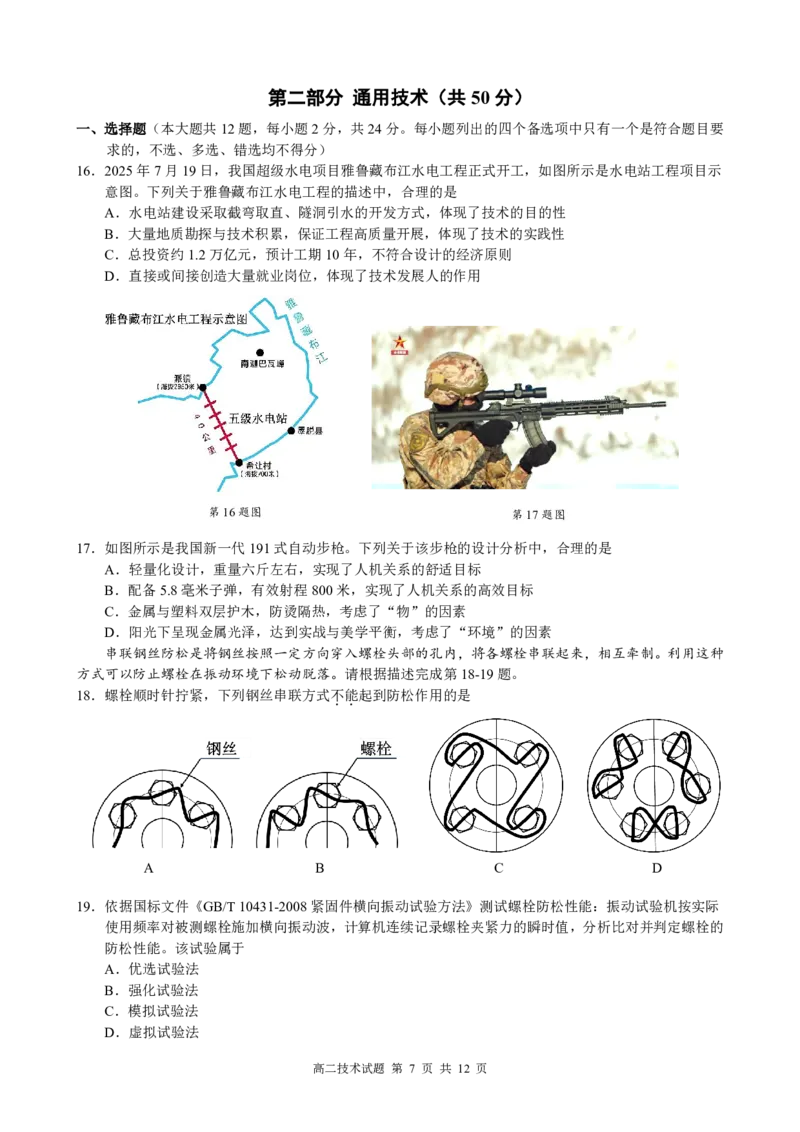
人员转移”等决策建议。
1.下列关于材料中涉及数据、信息和知识的说法,正确的是
A.传感器上报的水位数值中不包含信息
B.平台中数据的客观性为科学研究提供了可靠的依据
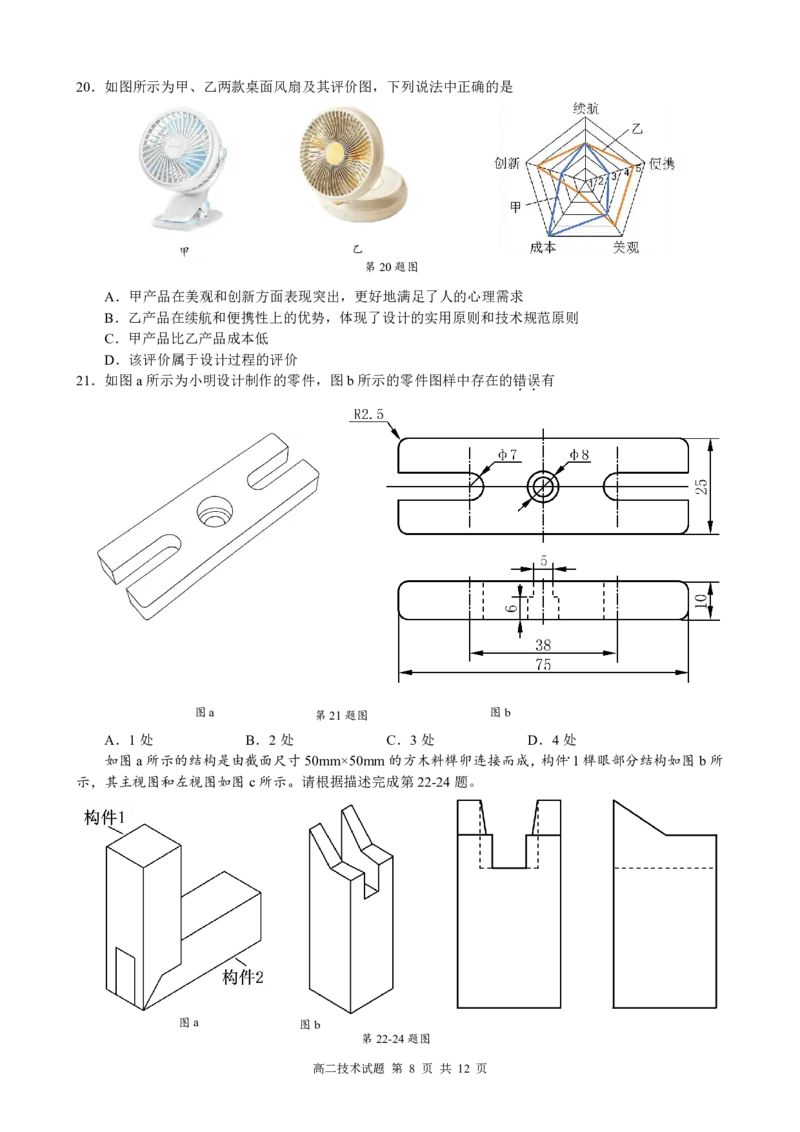
C.“风险一张图”的绘制,体现了信息的真伪性
D.系统自动生成决策建议,说明只要积累数据就能变成知识
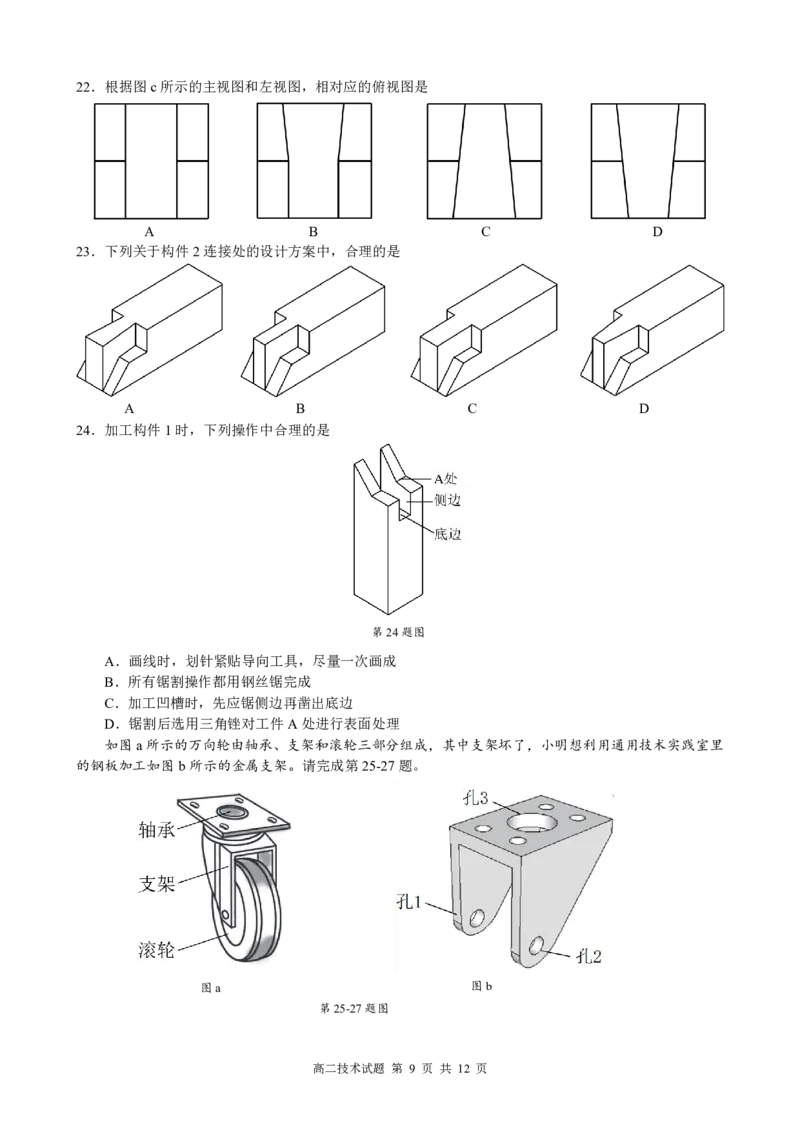
2.下列关于数据采集与编码的说法,正确的是
A.数据只能以二进制方式进行编码
B.该平台中所有数据都由传感器自动采集获得
C.水文传感器只在水位发生变化时采集相关数据
D.监控中的视频数据在取值上是离散的、不连续的
3.浙江省共11个地市,现有水文传感器总量约2.8–3.2万套,河网密集城市传感器数量相对更多,但最
多的地市不超过3500套,若使用二进制对所有传感器进行编码,二进制码的前几位表示地市,后几位
表示地市内水文传感器编号,则需要二进制位数最少是
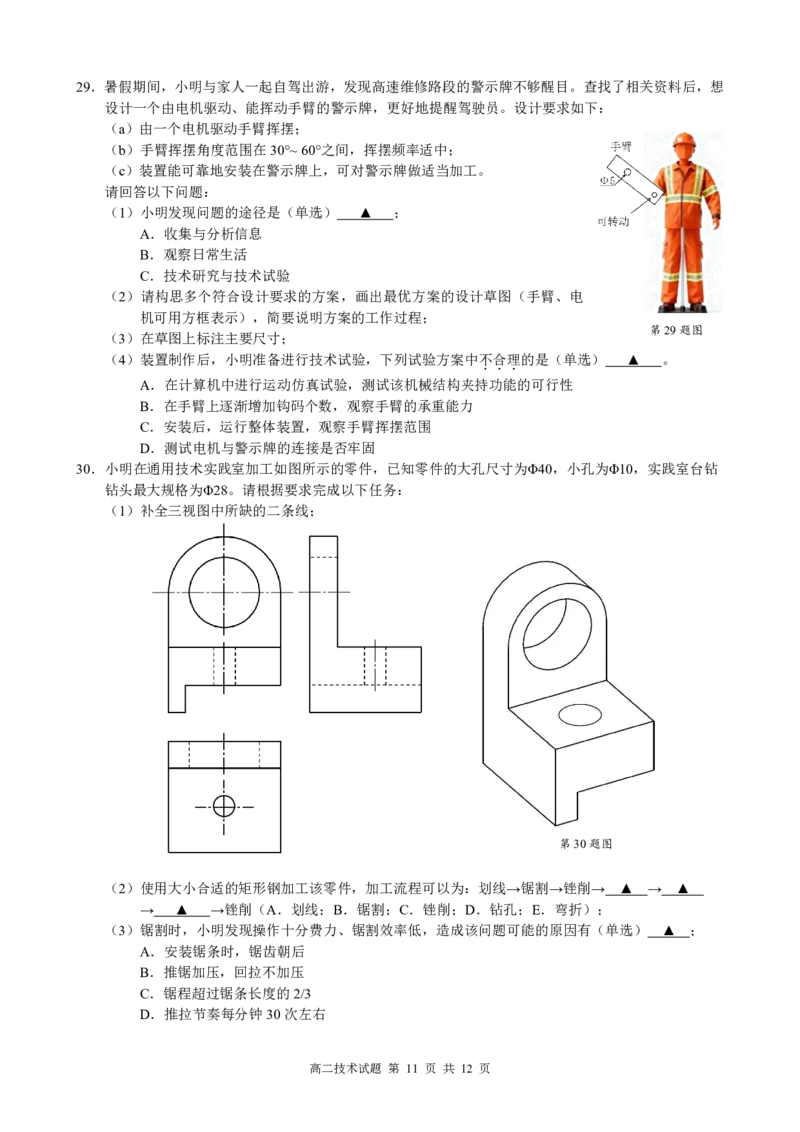
A.14 B.15 C.16 D.17
阅读下列材料,回答第4至6题:
省“智慧防汛平台”在2小时内完成1.8万个传感器、5颗遥感卫星、3000路视频监控、500架无人
机的数据汇聚,形成3.2TB的实时数据流。平台利用分布式大数据处理框架对多源数据进行分钟级清洗、
融合与建模,并通过AI风险预测模型提前3小时生成“人员转移热力图”,实现灾情“秒级”预警与“千
人千面”推送。
4.下列关于“智慧防汛平台”数据管理与安全的说法,不
.
正
.
确
.
的是
A.文件管理不适用于该平台的数据管理
B.异地容灾会增加数据存储的成本
高二技术试题 第 1 页 共 12 页
{#{QQABBQSkwwg4kIQACa6aVQWUCAsYkJGSJIgOAQAcKARCAAFIFCA=}#}C.该平台数据均为结构化数据
D.可以通过数据加密、校验的方式提高数据本身的安全
5.下列关于大数据的说法,正确是
A.该平台中的数据,数据量庞大,价值密度高
B.“智慧防汛平台”的应用,体现了大数据让决策更精准
C.“智慧防汛平台”社会意义重大,要求其中数据必须准确无误
D.该平台通过大量历史数据,分析因果关系,实现“秒级”预警
6.下列关于人工智能的说法,正确是
A.平台 AI 仅涉及计算机科学,与水文、气象、社会学等学科无关
B.历史台风数据训练得到风险预测模型,属于数据驱动的人工智能方法
C.无人机系统无需提供地图数据,通过“试错–奖励”机制不断优化群体行为,属于联结主义
D.防汛专家根据AI“疏散图”,结合现场经验修正疏散方案,这属于跨领域人工智能
7.某同学根据第7题图所示流程图编写的Python程序段如下:
bmi=float(input())
ifbmi<24:
ifbmi<18.5:
r="过轻"
else:
r="正常"
elifbmi>=28:
r="肥胖"
ifbmi<28:
r="超重"
print(r) 第7题图
用下列输入数据测试程序段与流程图,两者得到的r值不同的是
A.17 B.25 C.28 D.29
8.下列Python表达式中,值与其它三项不
.
一
.
样
.
的是
A.10//3>3 B.15%4*2!=6
C.ord("G")-ord("A")==len("ABCDEFG") D."he"in"hello"
9.高二年级正在开展“红色经典阅读”活动。使用字典reading_data={"1班":[3,5,2,4……],"2班":[4,4,3,5,……],
"3班":[2,1,3,5……]}按学号顺序存储各班每位同学的阅读篇数,如1班2号同学阅读了5篇。现要获取
3班10号同学阅读数量,下列语句正确的是
A.reading_data["3班"][9] B.reading_data{"3班"}[9]
C.reading_data{"3班"}[10] D.reading_data[2][10]
10.有如下Python程序段:
s=input();dic={}
foriinrange(len(s)-1):
word=s[i:i+2]
ifwordindic:
dic[word]+=1
else:
dic[word]=1
max_word=""
max_count=0
forkeyindic:
ifdic[key]>max_count:
高二技术试题 第 2 页 共 12 页
{#{QQABBQSkwwg4kIQACa6aVQWUCAsYkJGSJIgOAQAcKARCAAFIFCA=}#}max_count=dic[key]
max_word=key
print(max_word,max_count)
运行该程序段后,若输入的值为"bananaandananas",则输出的结果为
A.an4 B.an5 C.ana4 D.ana5
11.有如下Python程序段: @
@@
n=5
@@@
foriinrange(1,n+1):
@@@@
s="" @@@@@
第11题图
print(s)
执行程序后,得到如第11题图所示的字符画,第一行有4个空格,第二行有3个空格,以此类推,
则加框处的正确代码为
A. B. C. D.
forjinrange(n-i): forjinrange(n-i+1): forjinrange(n-i): forjinrange(n-i+1):
s+="" s+="" s+="" s+=""
forjinrange(i-1): forjinrange(i-1): forjinrange(i): forjinrange(i):
s+="@" s+="@" s+="@" s+="@"
12.有如下Python程序段:
fromrandomimportrandint
s="abcde"
res=""
foriinrange(len(s)):
k=randint(0,3) #产生0-3范围内的随机整数
ifk%2==1:
res+=chr((ord(s[i])-ord("a")+k)%26+ord("a"))
else:
res+=chr((ord(s[i])-ord("a")-k)%26+ord("a"))
执行该段程序后,变量res的值不
.
可
.
能
.
是
A.bzzde B.dedef C.ybddf D.abcde
二、非选择题(本大题共3小题,其中第13题8分,第14题9分,第15题9分,共26分)
13.仓库中有AB两种类型的货物,无序摆放成一列。现需通过交换货物顺序整理货物,使得相同类型的
货物都挨在一起。假设每次交换只能对调一组AB货物的位置。给定原有摆放顺序,求出货物有序的
最少交换次数,并输出按照最少次数交换后,A货物在前,还是B货物在前。假设原货物顺序为
“BABAABABAB”,如图a所示。若A货物在前,最少需要交换2次,即0、2位置的B货物分别与
6、8位置的A货物交换。若B货物在前,则最少交换3次 ,即1、3、4位置分别与5、7、9位置交
换。程序运行结果如图b所示。
图a 图b
(1)若货物原顺序为“BBBBBAABABABBAA”,A货物在前的最少交换次数为 ▲ 次,B货
物在前的最少交换次数为 ▲ 次。
(2)为实现上述功能,请填写划线处代码。
s=input("请输入原始货物顺序:")
n=len(s);a=[0]*n;cntA=0
高二技术试题 第 3 页 共 12 页
{#{QQABBQSkwwg4kIQACa6aVQWUCAsYkJGSJIgOAQAcKARCAAFIFCA=}#}foriinrange(0,n):
if ① :
cntA+=1
a[i]=cntA
cntB=len(s)-cntA
ans1=cntA-a[cntA-1] #把A交换到前面所需交换的次数
ans2= ② #把B交换到前面所需交换的次数
print("最少交换次数为:", ③ ,"次")
ifans1ans2:
print("交换后B在前")
else:
print("交换后A或B在前均可")
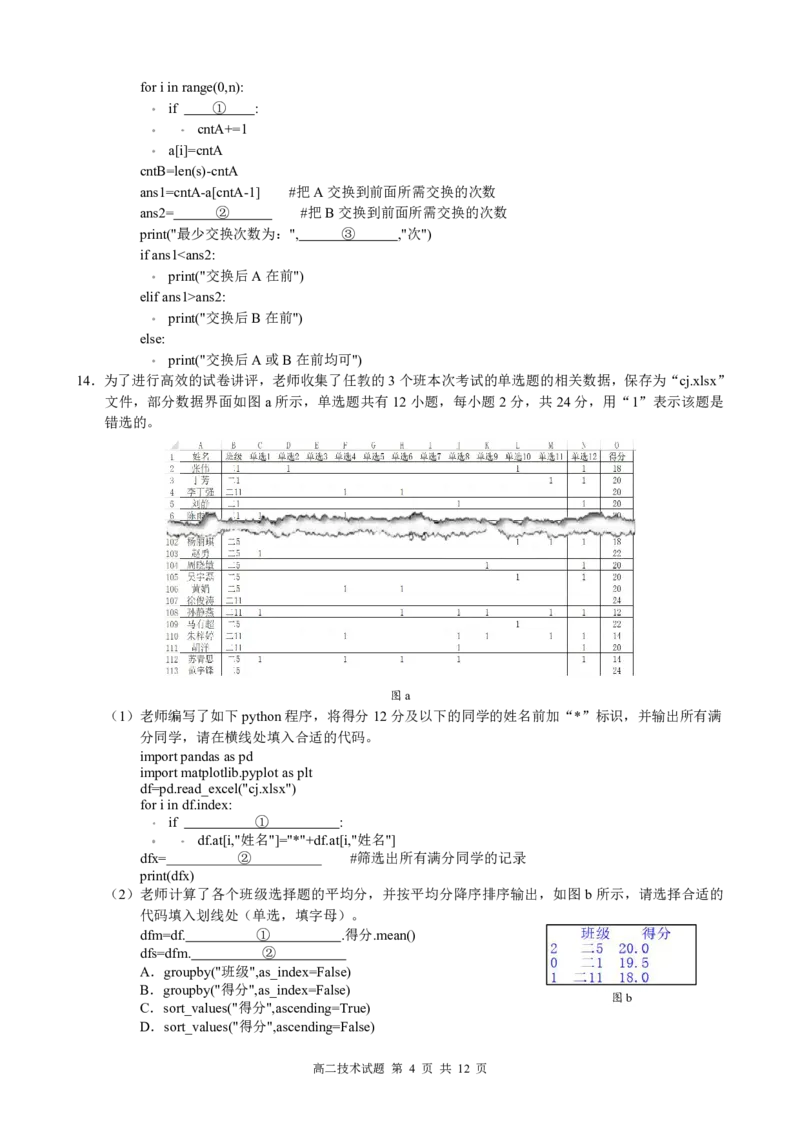
14.为了进行高效的试卷讲评,老师收集了任教的3个班本次考试的单选题的相关数据,保存为“cj.xlsx”
文件,部分数据界面如图a所示,单选题共有12小题,每小题2分,共24分,用“1”表示该题是
错选的。
图a
(1)老师编写了如下python程序,将得分12分及以下的同学的姓名前加“*”标识,并输出所有满
分同学,请在横线处填入合适的代码。
importpandasaspd
importmatplotlib.pyplotasplt
df=pd.read_excel("cj.xlsx")
foriindf.index:
if ① :
df.at[i,"姓名"]="*"+df.at[i,"姓名"]
dfx= ② #筛选出所有满分同学的记录
print(dfx)
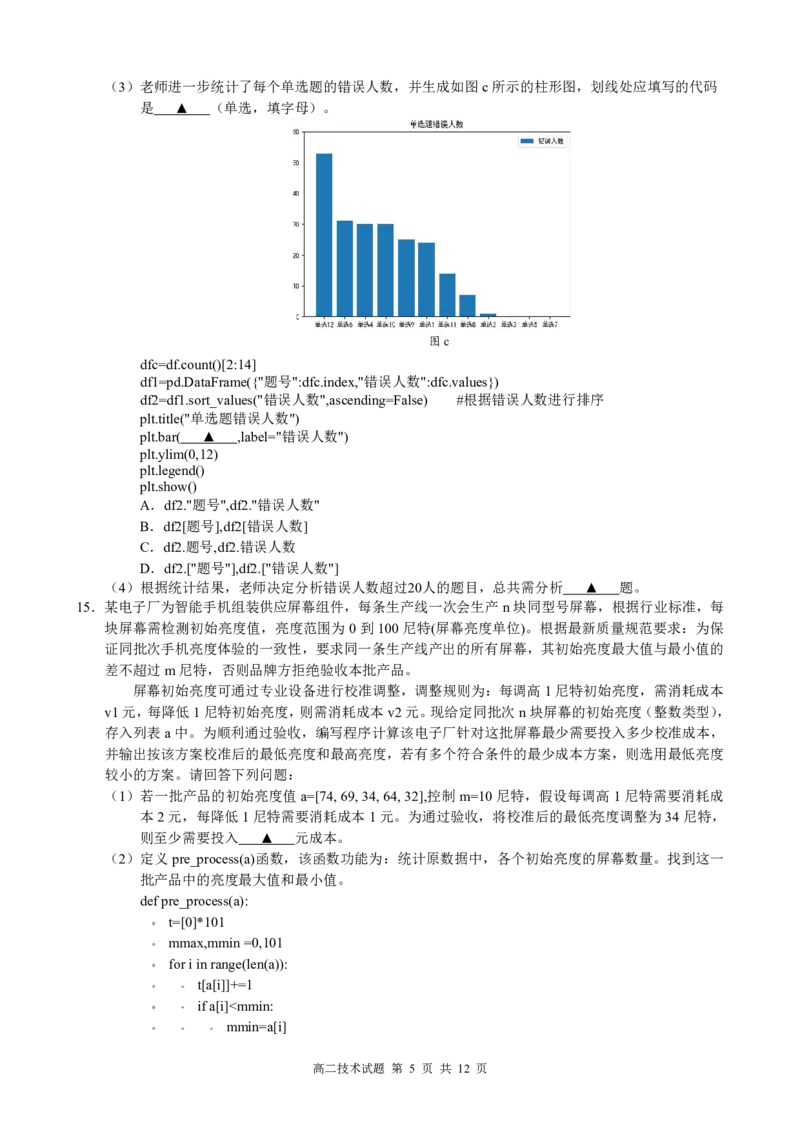
(2)老师计算了各个班级选择题的平均分,并按平均分降序排序输出,如图b所示,请选择合适的
代码填入划线处(单选,填字母)。
dfm=df. ① .得分.mean()
dfs=dfm. ②
A.groupby("班级",as_index=False)
B.groupby("得分",as_index=False)
图b
C.sort_values("得分",ascending=True)
D.sort_values("得分",ascending=False)
高二技术试题 第 4 页 共 12 页
{#{QQABBQSkwwg4kIQACa6aVQWUCAsYkJGSJIgOAQAcKARCAAFIFCA=}#}(3)老师进一步统计了每个单选题的错误人数,并生成如图c所示的柱形图,划线处应填写的代码
是 ▲ (单选,填字母)。
图c
dfc=df.count()[2:14]
df1=pd.DataFrame({"题号":dfc.index,"错误人数":dfc.values})
df2=df1.sort_values("错误人数",ascending=False) #根据错误人数进行排序
plt.title("单选题错误人数")
plt.bar( ▲ ,label="错误人数")
plt.ylim(0,12)
plt.legend()
plt.show()
A.df2."题号",df2."错误人数"
B.df2[题号],df2[错误人数]
C.df2.题号,df2.错误人数
D.df2.["题号"],df2.["错误人数"]
(4)根据统计结果,老师决定分析错误人数超过20人的题目,总共需分析 ▲ 题。
15.某电子厂为智能手机组装供应屏幕组件,每条生产线一次会生产n块同型号屏幕,根据行业标准,每
块屏幕需检测初始亮度值,亮度范围为0到100尼特(屏幕亮度单位)。根据最新质量规范要求:为保
证同批次手机亮度体验的一致性,要求同一条生产线产出的所有屏幕,其初始亮度最大值与最小值的
差不超过m尼特,否则品牌方拒绝验收本批产品。
屏幕初始亮度可通过专业设备进行校准调整,调整规则为:每调高1尼特初始亮度,需消耗成本
v1元,每降低1尼特初始亮度,则需消耗成本v2元。现给定同批次n块屏幕的初始亮度(整数类型),
存入列表a中。为顺利通过验收,编写程序计算该电子厂针对这批屏幕最少需要投入多少校准成本,
并输出按该方案校准后的最低亮度和最高亮度,若有多个符合条件的最少成本方案,则选用最低亮度
较小的方案。请回答下列问题:
(1)若一批产品的初始亮度值a=[74,69,34,64,32],控制m=10尼特,假设每调高1尼特需要消耗成
本2元,每降低1尼特需要消耗成本1元。为通过验收,将校准后的最低亮度调整为34尼特,
则至少需要投入 ▲ 元成本。
(2)定义pre_process(a)函数,该函数功能为:统计原数据中,各个初始亮度的屏幕数量。找到这一
批产品中的亮度最大值和最小值。
defpre_process(a):
t=[0]*101
mmax,mmin=0,101
foriinrange(len(a)):
t[a[i]]+=1
ifa[i]mmax:
mmax=a[i]
returnt,mmax,mmin
方框中语句有误,可修改为以下选项中的 ▲ (单选,填字母)
A.ifa[i]>mmax B.else C.elifa[i]>=mmax
(3)实现上述功能的部分Python程序如下,请在划线处填入合适的代码。
defcal(x,v1,v2,m): #计算最低亮度为x的校准成本
s=0
forjinrange(mmin,x):
s+=v1*t[j]*(x-j)
forjinrange(x+m+1,mmax+1):
s+= ①
returns
'''
读取同批次n块屏幕的初始亮度,依次存入列表a中,代码略
读取m值,限定一个批次内亮度最大与最小的差值不超过m(允许等于m) ,代码略
读取v1、v2,分别代表每调高、降低1尼特的成本价格,代码略
'''
t,mmax,mmin=pre_process(a)
ans=max(v1,v2)*len(a)*100 #初始化为一个不可能的最大值
ansi=0
ifmmax-mmin<=m:
print("本批次产品无需校准,可直接通过验收")
else:
foriinrange(mmin,mmax-m+1): #枚举最低亮度
②
ifs
