 夜雨聆风
夜雨聆风





Karpathy最新分享:Software 3.0 范式、Agentic Engineering ,以及AI的「锯齿智能」
2026 年初,Andrej Karpathy 受邀在 Sequoia Ascent 大会发表演讲,带来了他对当前 AI 发展阶段的系统性思考。演讲涵盖三个核心主题:Software 3.0 范式、Agentic Engineering 的崛起,以及他新提出的「锯齿智能」(Jagged Intelligence)概念。
这是一篇完整解读。
一、Software 3.0:自然语言成为编程语言
Karpathy 首先提出了软件三代演进框架,帮助我们定位当下所处的历史节点。
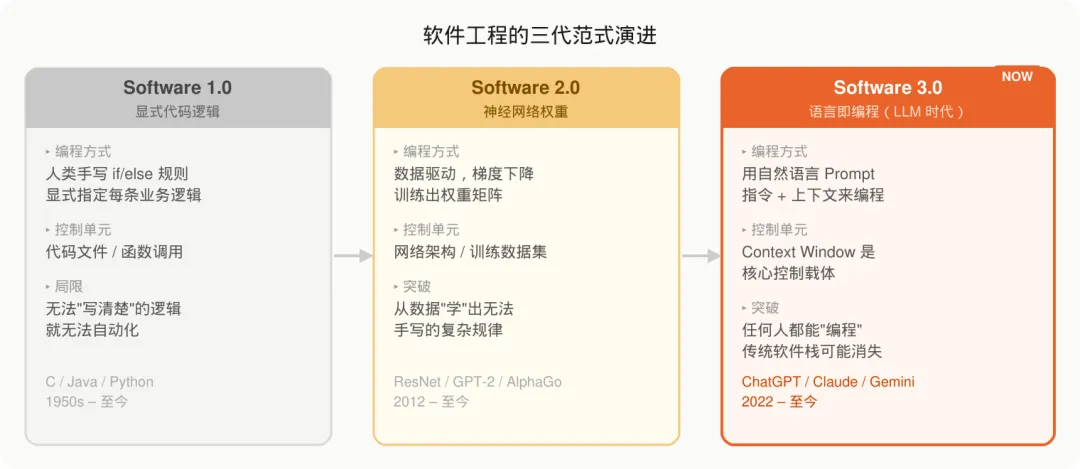
Software 1.0 是传统软件开发。程序员用 if/else 和显式逻辑,把业务规则一行一行写进代码。能做什么,取决于能不能”写清楚”。
Software 2.0 以神经网络为核心。不再手写规则,而是通过数据和梯度下降训练出权重矩阵。深度学习属于这一代——从数据中”学”出了人类根本无法手工编写的复杂规律。
Software 3.0 就是我们现在所在的阶段。大语言模型让自然语言成为编程语言。一段 Prompt,一段上下文,就可以指挥一个「万能员工」完成任务。Context Window 取代了代码文件,成为核心控制载体。
Karpathy 举了一个具体例子说明 3.0 的破坏力:传统的菜单识别 App(拍照 → OCR → 图像生成 → UI 渲染)涉及多个模块和完整工具链,而在多模态大模型时代,整个技术栈可能被一个模型的直接处理所取代。软件架构会在不知不觉间”蒸发”。
二、「锯齿智能」:AI 的能力为何如此参差?
这是整场演讲最核心的概念,也是理解 AI 行为最有洞察力的框架。
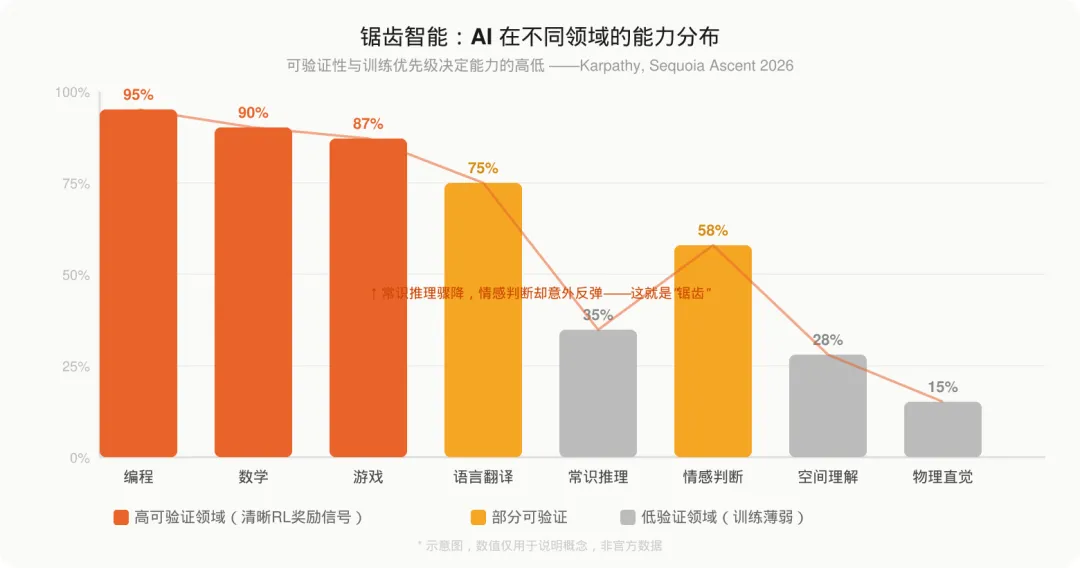
Karpathy 观察到:LLM 的能力分布绝不是平滑均匀的,而是锯齿状的——在某些领域极度卓越,在另一些领域却令人匪夷所思地糟糕。
同一个模型,可以在编程竞赛题上碾压绝大多数工程师,却在一些看起来很简单的常识场景里给出离谱的答案——Karpathy 用 “bizarrely dumb” 来形容这种反差。
为什么会形成锯齿?
Karpathy 给出了明确的解释:AI 的能力高低,由两个关键变量决定——
第一,可验证性(Verifiability):这个任务的结果能否被自动地、精确地判断对错?编程有单元测试,数学有标准答案,象棋有胜负——这些都是清晰的 RL 奖励信号,模型可以稳定地优化。而情感是否恰当、文章是否有洞察力,很难被精确量化,RL 就无从发力。
第二,训练优先级:预训练和强化学习阶段,是否大量覆盖了这个领域?Karpathy 举了一个有趣的例子:AI 的象棋能力在训练数据扩充之后出现了显著跃升——能力的提升直接对应着该领域训练覆盖度的增加。这说明训练数据和 RL 的覆盖范围,直接决定了模型在某个领域的天花板,而不是模型本身存在某种固有的”天赋差异”。
Karpathy 将这个洞察提炼成了一句极度精炼的话:
“传统软件自动化的是你能明确描述的事;LLM 自动化的是你能验证的事。”
这一句话,是理解 AI 能力边界最简洁的钥匙。
三、可验证性框架:从根本上理解能力分布
基于可验证性和训练覆盖度两个维度,我们可以把所有任务映射到一个矩阵里。

AI 能力强项区(右上):高可验证 + 大量训练。编程、数学、游戏、科学计算属于这里。RL 的奖励信号清晰,模型能力随训练持续逼近专家顶点。
参差不齐区(左上):低可验证 + 大量训练。创意写作、情感判断、观点输出属于这里。模型见过大量相关数据,有时表现出色,有时又令人失望——因为没有清晰的”对错”标准来稳定优化。
AI 弱项区(左下):低可验证 + 训练不足。物理直觉、空间推理、具身交互属于这里。这是当前 AI 最明显的能力边界,需要全新的训练范式才能突破。
创业机会区(右下):高可验证 + 但尚未被顶级大模型充分训练。这是 Karpathy 给创业者最重要的一个提示:专业医疗诊断、工业质检、科学实验验证——这些领域有清晰的正确/错误信号,但大型通用模型在这里的数据覆盖严重不足。如果能在这里构建领域专用的 RL 环境并进行专项微调,即使基础模型在此表现平庸,专项模型也可能大幅超越。
四、Stripe Bug:当工程判断力缺席时
Karpathy 在演讲中分享了一个来自他自身经历的反例,很值得每个使用 AI Agent 写代码的工程师思考。
他让 AI Agent 完成一个任务:将 Stripe 支付记录与 Google 账号关联,用于识别付费用户。
Agent 给出的方案:用邮箱地址匹配 Stripe 购买记录与 Google 账号。
这个方案表面上看起来合理,实际上是一个糟糕的系统设计——很多用户的 Stripe 付款邮箱和 Google 登录邮箱根本不是同一个。正确做法是使用持久性用户 ID,而非邮箱字段。
Agent 在编写代码层面是完美的,但在系统架构判断这一层,它缺少理解业务边界的上下文。这个 bug 如果流入生产,会悄无声息地导致数据错误,且极难排查。
这个例子说明了一个关键分工:AI 擅长执行,人类必须负责设计边界、定义约束、保证系统完整性。
五、两种开发者:Vibe Coding vs. Agentic Engineering
Karpathy 对目前两种截然不同的 AI 使用方式做了清晰区分:
Vibe Coding(氛围编程)
-
降低了编程门槛。任何人通过描述意图就能让 AI 生成软件 -
代码通常能运行,但可能臃肿、充满冗余、存在安全隐患 -
适合快速原型验证,但不适合需要长期维护的生产系统
Agentic Engineering(智能体工程)
-
这是 Karpathy 认为专业工程师正在演进的角色 -
工作内容变了:监督 Agent 执行规格、审查 diff、管理权限和安全边界、保证系统完整性 -
Karpathy 的类比很贴切:建筑师监督施工队——不亲自砌砖,但对结构的正确性负最终责任
两者并不互斥,但对专业从业者而言,能力重心正在从「写代码」向「看代码、管 Agent、审设计」转移。
传统的编程面试已经开始失去意义。更有效的评估方式是:能否用 Agent 交付真实的生产级项目?能否防范对抗性 Agent 攻击?能否写出高质量的 Spec,并在 Agent 产出后做有效的 Quality Review?
六、什么变得更稀缺了?
在 AI 能大量生成代码的时代,什么反而变得更有价值?
品味(Taste):Agent 产出的代码通常能运行,但往往冗余、copy-paste 泛滥、缺乏设计感。识别「好」与「勉强能用」之间差距的能力,越来越稀缺。
工程判断力:存储设计、内存效率、安全边界的权衡,需要对系统整体有认知——Stripe Bug 就是典型案例。Agent 做局部最优,人做全局判断。
Spec 设计:Agent 需要高质量的规格说明才能工作得好。写出清晰、完整、歧义最小的 Spec,是新时代高价值的工程师技能。
真正的理解:Karpathy 说了一句值得反复咀嚼的话:
“你可以把思考外包出去,但你不能把理解外包出去。”
知道什么值得做、为什么要做、设计是否正确——这是指挥 AI 的前提,也是不可外包的核心能力。
七、AI 不是动物,也不是幽灵
Karpathy 还提出了一个重要的认知框架:LLM 既不是有内在好奇心、情感和生存本能的「动物」,也不是某种超自然存在的「幽灵」。
它是「人类产物的统计模拟」——由预训练数据、后训练调整、强化学习和经济激励共同塑造。
这个框架帮助我们避开两种常见陷阱:既不会因为 AI 的流畅表现而高估它的理解深度,也不会因为它某次离谱的错误就否定它的真实价值。经验性地、冷静地探索模型的能力边界,才是正确的使用姿态。
结语
「锯齿智能」是 Karpathy 对当前 AI 现状最精准的描述之一。它解释了为什么 AI 能在 LeetCode 上碾压人类,却会在账号匹配这种设计问题上犯低级错误;为什么它能精确翻译学术论文,却在物理常识上频繁翻车。
这种不均匀不是 bug,是训练机制的必然结果。理解它,是每一个与 AI 协作的工程师和创业者真正开始掌控局面的起点。
原文链接:Sequoia Ascent 2026 — Andrej Karpathy (https://karpathy.bearblog.dev/sequoia-ascent-2026/)
欢迎关注 AI觉醒观测者,持续追踪 AI 领域最值得关注的思想与进展。