夜雨聆风
夜雨聆风





别轻易把文档丢给AI了!研究表明,AI会偷偷改内容,顶尖模型也是

你们有没有过这种经历。
晚上把一份文档说明丢给AI,留一句,帮我整理一下,顺便改得更清楚。第二天打开,你大概率会觉得,挺好,字更顺了,结构更清楚了,排版也像样了。
可容易出问题的,往往就是这种时候。危险的不是把内容写得很烂,而是写得贼像对的。
比如合同本来写的是,付款时间为验收后30天。AI却写成付款时间为交付后30天。
乍一看差不多,可实际天差地别。
微软研究院上个月的一篇论文,专门研究了这件事。标题叫《LLMs Corrupt Your Documents When You Delegate》,翻得更通俗一点,就是,当你把持续修改文档这件事交给大模型,它很可能会在一轮一轮操作里,把文档慢慢改坏。

这里最关键的词,不是文档,也不是模型。
是“Delegate”,委托。
什么叫委托。不是问AI一个问题,拿到一个答案。而是你把一份已经存在的材料交给它,让它接着改,接着补,接着整理,接着沿着前面的思路往下做。
这其实特别像真实工作。老板给你一份方案,让你改三轮。客户把合同打回来,让你再修两版。同事发来一份表格,让你统一格式,再补几列说明。
作者做了一个新测试,叫DELEGATE-52。可以把它理解成一场大规模压力测试,看AI在长期改文件这件事上,到底稳不稳。

它测了从Python代码,到数据库文件,再到乐谱、会计台账、字幕、菜单、家谱等52个领域的不同文档。

怎么测的呢。先让模型做一次正向修改。比如,把一个表按类别拆开。再让它做一次反向修改。比如,把拆开的内容重新合并回原来的样子。
如果模型真的靠谱,那改完再改回来,文档应该和最初差不多。如果改不回来,就说明它在这个过程中把内容弄丢了,或者弄变了。
这种来回修改一直做很多轮,模拟真实工作里那种,你改一版,我再补一版,他又重排一版,最后又回头改前面的情况。
结果挺意外,全军覆没。
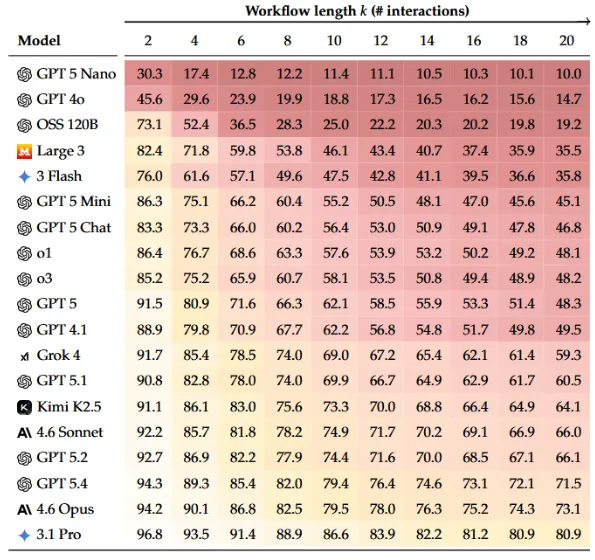
一共测了19个模型,到了20次交互,全部模型平均退化大约一半。就连Gemini 3.1 Pro、Claude 4.6 Opus、GPT 5.4这些顶尖模型,平均也会损坏大约四分之一内容。
这里的四分之一,不是说页面少了四分之一。而是内容保真度少了四分之一。换成更好理解的话,就是你交给它的原始意思、原始结构、原始细节,到了很多轮之后,已经有相当一部分被它改得不再是原来那样了。
最容易让人误判的一点是,短测试看起来往往没事。
前两次交互时,这些顶尖模型的表现大多还在94%到97%左右,看起来完全能用。可一旦拉到20次交互,Gemini 3.1 Pro掉到80.9%,Claude 4.6 Opus掉到73.1%,GPT 5.4掉到71.5%。
很像刚入职的实习生,第一件小事他做得挺漂亮,于是你开始放心,把更多事情交给他。结果到了第十件、第十五件,你才发现前面的几个小错已经连成一片了。
AI现在在很多文档任务上,就是这种状态。
更麻烦的是,它不是每一轮都小错一点点。
论文发现,很多损失都来自少数几次重大的突然失误。平时看着还行,改着改着,某一轮忽然把关键字段改错了,把某条逻辑链断掉了,把某个重要限定条件抹掉了,一次就能掉很多分。
它不是那种一眼就能看出来的低级错误。不是乱码,不是整段消失,不是排版塌掉。而是你读着很顺,觉得没问题,可里面有几颗螺丝已经被拧歪了。
而且模型越强,有时反而越难看出来。弱一点的模型,常见问题是直接删东西,漏段落,丢字段。你一看就知道不对。
强一点的模型,更像一个会说漂亮话的人。它保留外观,保留结构,甚至保留一种很专业的语气,然后把意思悄悄换掉。
比如把“建议”写成“决定”,把“可能”写成“将会”。句子更完整了,语气更稳了,问题也更隐蔽了。
论文里还有几个细节,也值得聊聊。
第一,代码任务确实是个例外。
52个领域里,编程是唯一一个大多数模型都达到了ready门槛的领域。因为代码相对更规整,很多错误还能靠测试、运行结果、语法检查抓出来。文档、纪要、合同、说明书就不是这样。它们很多错误不影响阅读,但会影响意思。
第二,给AI加工具,不等于自动变稳。
很多小伙伴现在用OpenClaw、Claude Code这种Agent之前,喜欢安装一大堆Skill或插件工具,觉得这样会大大提升AI能力。
论文专门测了这件事。结果是,在一套基础工具框架下,模型平均还更差了一些。
为啥呢?你可以把它理解成,一个本来就容易分心的人,现在手边工具更多了,步骤更多了,来回切换更多了,未必就更稳。更何况,模型很多时候并没有像人类那样只改一句、只替一列、只动一个字段,而是还是在大块大块地重写。
这很像你本来只是让同事帮你改一行字。结果他打开Excel、复制一份、重新排序、再粘回去,流程变复杂了,出错点也更多了。
第三,文档越长,情况越糟。
这也好理解。一页纸的请假说明,和一份40页的合作协议,根本不是一个难度。
论文里测到,文档越长,模型后面改坏的概率越高。现实工作偏偏最常见的,就是长文档、长表格、长上下文。
第四,旁边的无关材料也会添乱。
比如你把主文档交给AI时,还顺手把几份参考材料、旧版本、会议记录、相关制度文件一股脑都塞进去。人有时候都要花半天分清哪些该看,哪些不用看,模型当然也会被带偏。
这和我们平时办公太像了。桌面上同时开着三个版本的合同。邮箱里躺着两份旧纪要。群里还有一张截图。
你让AI从这堆东西里继续改,很难保证它不会把不该混进去的内容混进去。
第五,时间越长,不会自动变好。
论文把交互一直拉到100次,性能还是继续往下掉,没有出现明显稳定。意思很简单,现在的模型不是改着改着就学会稳住了,而是改着改着,还是会继续出新错。
当然,这篇论文也不是在说,AI一点都不能用。这点必须说清楚。
作者自己的表述其实很克制。他们测的是一个基础版的Agent框架,不是全世界最先进、最精细的工程系统。所以不能把结论粗暴理解成,只要用了AI Agent就一定不行。
但这篇论文至少证明了一件事。
今天的AI,很适合帮你起草,很适合帮你提速,很适合帮你先走第一步。可它还远远没有稳到,你可以放心把一整条文档工作链路交给它,然后自己彻底不看。
这也是为什么,很多人用AI写东西觉得挺爽,用AI改东西却越来越心虚。
写,是从空白到内容。改,是从原意到原意。后者难得多。
那咱到底该怎么用,才更安全一点。我觉得至少有五条,很实用。
第一,不要整包托管。
不要一句“你帮我全改完”就交出去。最好拆成小段,小节,小模块。比如先只让它改摘要,再只让它整理表格标题,再只让它润色一段说明。每次改动范围越小,翻车越容易被发现。
第二,重要材料尽量看改动,不只看成稿。
如果工具支持diff,就看diff。因为整篇从头读一遍,人很容易被“读起来挺顺”骗过去。可一旦你只看改了哪几句,很多问题马上就冒出来了。
第三,把最敏感的东西单独检查。
金额、日期、时间、付款条件、地名、人名、版本号、试点范围、是否生效、是否包含例外条款,这些地方最容易出大事,也最值得人工逐项过一遍。
第四,越是长文档,越别偷懒。
十页以上的方案,几十行以上的表,带多个附件的合同,带历史版本的制度文件,这些都不要轻信“它应该没问题”。文档越长,越该设检查点。
第五,结构化任务更适合交给AI,不好验证的任务更要谨慎。
如果一项工作有明确对错,有现成校验方式,有规则能卡住,比如代码测试、固定格式转换、严格字段检查,那AI通常更值得信任。反过来,凡是那种读起来很通顺,但对错要靠人理解上下文才能判断的内容,风险都更高。
所以,下一次,当你准备把一份合同、一份方案丢给AI,然后安心去喝咖啡时,不妨多问自己一句:这版看起来没问题的东西,是不是真的没问题?
如果你有任何看法,欢迎在评论区一起讨论 💬
如果有一点收获,可以点赞、转发、推荐文章,关注「AI机器人茶馆」 🌟