当 AI 可以持续生成代码、解释需求、编写测试、修复 Bug、调用工具、重构系统、甚至自己规划任务时,过去五十年建立起来的软件工程假设,还成立吗?
更进一步说:
软件工程到底是一门“写代码的工程”,还是一门“把复杂业务意图转化为可运行系统的认知工程”?
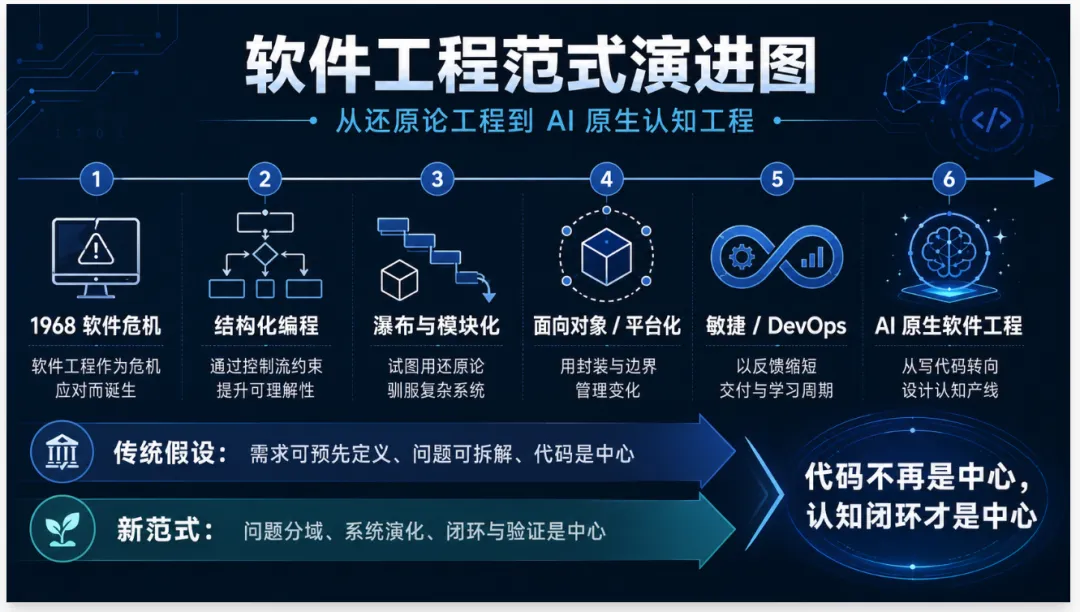
如果软件工程只是写代码,那么 AI 编程工具就是效率工具;如果软件工程本质上是认知工程,那么大模型的出现就不是工具升级,而是一次底层范式革命。你原文里有一个非常关键的判断:过去五十年,软件工程一直在“管理人的不确定性”,但并没有真正完成工程化;大模型让“用能源换取高阶智能”第一次成为可能,因此软件工程才真正迎来成为工程学的历史窗口。 这句话非常重,值得展开成一套完整理论。本文要讨论的核心判断是:AI 时代的软件工程,不是“人类程序员 + AI 辅助工具”的线性增强,而是从“还原论工程”走向“复杂适应系统工程”的范式切换。在这个新范式中,代码不再是中心,中心变成了:业务意图、场景反馈、模型能力、验证体系、组织分工、知识蒸馏、运行闭环。软件行业过去五十年一直试图把复杂世界拆成确定模块,再通过流程、角色、文档、代码和测试把它拼回去。这是一种典型的还原论方法。它曾经非常有效,也支撑了现代软件产业的崛起。但到了 AI 时代,这种方法的边界被彻底暴露:真实业务不是线性需求,复杂系统不是模块拼装,智能体不是函数调用,软件也不再只是代码资产。软件工程正在发生第二次奠基。第一次奠基,是 1968 年 NATO 软件工程会议之后,行业开始意识到软件危机,并试图用工程化方法管理大型软件系统。1968 年的 NATO 软件工程会议正是围绕“软件危机”展开:系统越来越大,越来越依赖软件,但项目延期、超预算、难维护的问题越来越严重。()第二次奠基,就是今天。大模型让软件工程第一次拥有了“可能源化的高阶认知引擎”。但它也带来了新的不确定性:幻觉、漂移、上下文断裂、不可解释、错误自信、隐性知识缺失、安全漏洞扩散。因此,AI 时代软件工程的核心问题,不是如何让 AI 写更多代码,而是如何把概率性认知纳入工程化闭环。
1968 年,Dijkstra 的《Go To Statement Considered Harmful》成为结构化编程时代的标志之一。它试图告诉程序员:不要让程序控制流像迷宫一样跳来跳去,要用顺序、分支、循环这些可理解结构组织程序。Dijkstra 这篇文章发表于 1968 年《Communications of the ACM》,后来成为结构化编程运动的经典文本。()这其实是软件工程第一次非常明确的“还原论化”努力:把混乱的控制流拆成有限结构;把人的任意写法约束成可读、可推理、可验证的模式。
1970 年,Royce 发表《Managing the Development of Large Software Systems》,后来被行业误读成瀑布模型源头。值得注意的是,Royce 原文其实并不是鼓励僵硬瀑布,而是明确指出只按分析和编码两个步骤管理大型软件系统会失败,需要额外的迭代、验证与管理步骤。()但行业最愿意接受的,恰恰是它看起来最像传统工程的部分:需求先确定,然后总体设计,然后详细设计,然后编码,然后测试,最后上线。这套方法背后的哲学假设非常清楚:世界可以被提前理解,需求可以被完整表达,系统可以被分层设计,开发可以按计划执行,测试可以在最后验证。这是一种典型的机械工程式还原论。在桥梁、水坝、机床、房屋等传统工程里,这个假设经常成立。因为物理世界的约束稳定,材料性质可测,空间结构可计算,施工流程可重复。但软件面对的不是纯物理系统,而是业务、组织、流程、用户、制度、数据和技术共同构成的社会技术系统。它的目标不是“造一个不会变的物体”,而是“构建一个能持续适应变化的行为系统”。瀑布模型最大的失败,不是流程太长,而是把复杂问题误判成了繁杂问题。
要理解软件工程范式变化,必须先理解还原论。还原论的基本思路是:复杂整体可以拆成局部;局部可以单独理解;局部正确之后,整体就能通过组合得到正确结果。传统软件工程大量依赖这个假设。需求可以拆成用户故事;系统可以拆成模块;模块可以拆成类和函数;任务可以拆成工单;项目可以拆成里程碑;质量可以拆成测试用例;组织可以拆成产品、开发、测试、运维角色。还原论带来了巨大的工程红利。没有还原论,就没有模块化、组件化、分层架构、微服务、平台化,也没有大型团队协作。但还原论有一个前提:系统整体行为基本等于局部行为的组合。在很多简单系统和繁杂系统里,这个前提成立。比如一个排序函数,一个支付接口,一个库存扣减流程,一个日志采集组件,都可以被清晰拆解、独立验证、组合复用。但复杂业务系统不是这样。复杂系统有三个特点:第一,关系比部件更重要。一个功能在局部看是对的,放到业务流程里可能就是错的。第二,反馈会改变行为。用户会根据系统反馈改变自己的操作,业务部门会根据报表调整考核,考核又会反过来改变数据质量。第三,整体会涌现局部没有的性质。推荐系统、风控系统、调度系统、供应链系统、城市交通系统,都不是单个模块正确就能整体正确。传统软件工程的很多失败,本质上不是程序员不努力,而是错误地用还原论处理复杂系统。这也是为什么很多项目每个需求都完成了,但业务方仍然觉得“不好用”;每个接口都测试通过了,但整体流程仍然卡顿;每个系统都按合同验收了,但企业数字化仍然没有产生价值。这类失败不是编码失败,而是复杂性误判。AI 时代把这个问题放大了。因为 AI 让局部实现变得极快,导致组织更容易误以为“局部完成=整体完成”。过去一个程序员三天写完的功能,现在 AI 三十分钟生成出来。但生成越快,错误路径也越快。没有复杂性判断,AI 只会让团队更高效地制造系统性错误。这就是所谓“AI 加速了软件开发”,但也可能“AI 加速了软件灾难”。
四、Cynefin:AI 时代软件工程的新问题分类器
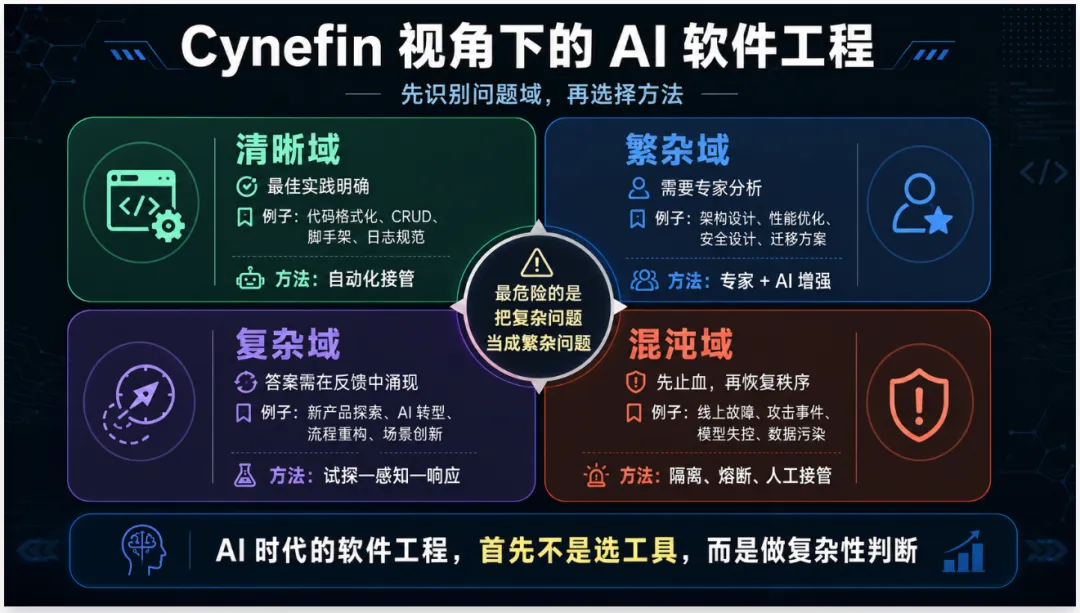
Cynefin 框架非常适合用来重新理解 AI 时代的软件工程。Snowden 和 Boone 在 2007 年《Harvard Business Review》中提出的 Cynefin 框架,将问题情境分为 simple/clear、complicated、complex、chaotic 等类型,强调不同情境需要不同决策方式,而不能用一种管理方法套所有问题。()放到软件工程里,Cynefin 可以帮助我们避免一个常见错误:把复杂问题当成繁杂问题,把混沌问题当成流程问题,把清晰问题交给专家过度设计。
繁杂域的问题有确定答案,但答案不显然,需要专家分析。比如:复杂架构设计,性能瓶颈定位,分布式一致性,数据库优化,安全架构,微服务边界拆分,遗留系统迁移,大型系统容量规划。这类问题不能简单交给 AI 自动生成,因为它需要专业判断。但 AI 可以成为专家的推理伙伴、方案生成器、反例构造器、文档整理器和仿真助手。在繁杂域,AI 的作用是“增强专家”。人的作用是判断权衡、确认假设、定义边界、承担责任。
3. Complex:复杂域,需要试探—感知—响应
复杂域的问题没有提前确定的正确答案,只有通过实验、反馈和演化才能找到可行路径。比如:新产品方向,用户增长机制,企业 AI 转型路径,跨部门流程重构,智能体组织形态,大模型应用场景识别,业务价值闭环设计,数据产品商业模式。这类问题最容易被传统软件工程误伤。团队常常试图先写完整 PRD,再设计完整架构,再估算完整工期。但复杂域不能靠预先规划解决,它只能靠小步试探、反馈学习、持续调整。在复杂域,AI 的作用不是给“标准答案”,而是帮助团队快速生成假设、构造实验、模拟场景、整理反馈、发现模式。在复杂域,工程方法应该从“需求驱动开发”转向“假设驱动学习”。
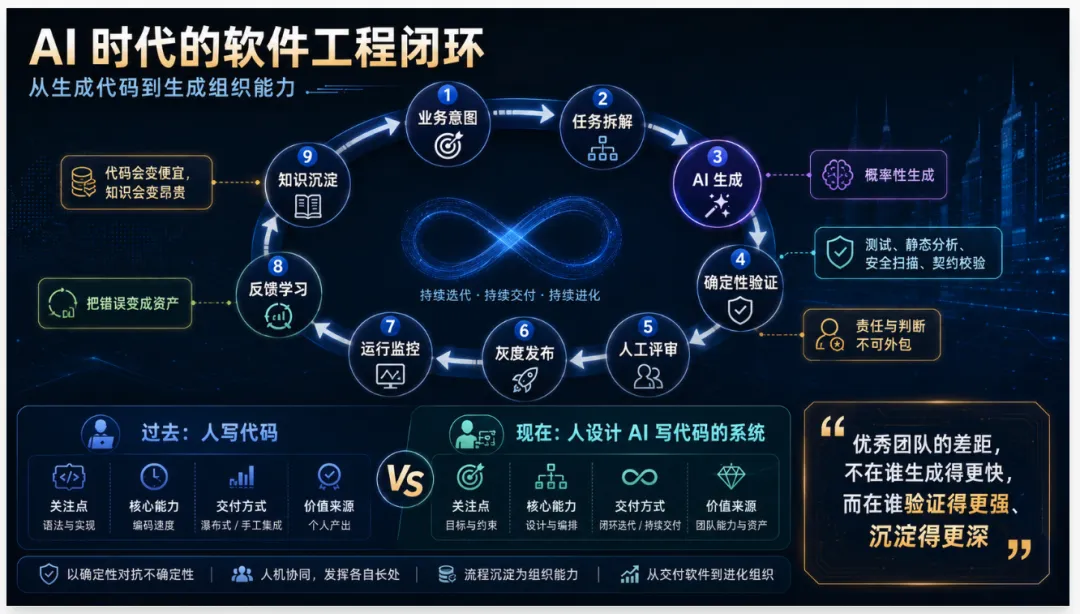
你原文里说得很准确:经典软件工程是人在写代码,AI 软件工程是人在设计“AI 写代码的系统”。这句话背后是角色迁移。程序员不再只是代码生产者,而会变成:目标定义者,上下文组织者,约束设计者,验证体系设计者,偏差拉回者,领域知识蒸馏者,AI 产线调优者。真正高级的软件工程师,不是比 AI 更会写样板代码,而是更会把复杂问题变成 AI 可以稳定处理的工程系统。
2. 从“确定性编程”到“概率性生成 + 确定性验证”
传统软件工程默认开发者写出的代码是确定性产物。AI 生成则是概率性产物。这意味着 AI 软件工程不能建立在“相信 AI”上,而必须建立在“审判 AI”上。编译器、类型系统、单元测试、集成测试、契约测试、静态分析、安全扫描、性能基准、灰度监控,都会从辅助工具变成 AI 产线的“确定性裁判”。你原文提出“确定性的强迫接触”非常关键:AI 的概率输出必须持续接受确定性系统的约束和裁判,才能进入工程级可靠状态。未来优秀团队的差距,不在于谁买了更贵的 AI 工具,而在于谁拥有更成熟的确定性裁判体系。
3. 从“开发流程”到“闭环系统”
传统开发流程是线性的:需求、设计、开发、测试、上线。AI 时代必须变成闭环:生成—验证—反馈—修复—沉淀—再生成。没有闭环,AI 就只是一次性内容生成器。有闭环,AI 才会变成工程产线。闭环的本质,是把错误变成资产。每一次 AI 生成错误,都应该沉淀为:反例,测试,规则,提示词约束,领域知识,设计决策记录,自动化检查项。如果错误只是被人手工改掉,那么团队没有进步;如果错误被产线吸收,那么系统能力上升。
4. 从“代码资产”到“知识资产”
过去企业最重视代码库。未来企业更应该重视:领域本体,业务规则库,架构决策记录,接口契约,测试资产,评审准则,故障案例库,Prompt/Agent 工作流,模型评测集,数据血缘,安全策略,场景指标体系。代码会越来越便宜,知识会越来越贵。AI 可以生成代码,但很难自动获得企业内部长期积累的隐性知识。谁能把隐性知识显性化、结构化、可验证化,谁就拥有 AI 时代真正的护城河。
5. 从“项目交付”到“持续演化”
传统软件项目有明显边界:立项、建设、验收、运维。AI 时代,软件会越来越像一个生命体。需求会变,数据会变,模型会变,用户行为会变,政策会变,外部 API 会变,安全威胁会变。因此,软件交付不再是终点,而是系统学习的起点。未来软件工程的核心指标,不只是“按期上线”,而是:系统是否持续学习,规则是否持续沉淀,模型是否持续评测,反馈是否进入闭环,业务价值是否持续验证,组织知识是否持续增长。
6. 从“个体能力”到“组织认知能力”
传统软件行业非常强调个人英雄:大神、架构师、全栈高手。AI 时代,个人能力仍然重要,但组织能力更重要。因为 AI 会拉平大量个体执行差距。真正的差距会转移到组织层面:谁的上下文管理更好?谁的知识库更好?谁的工程规范更清晰?谁的测试体系更完备?谁的业务反馈更及时?谁的 Agent 分工更合理?谁的安全边界更强?谁能把项目经验变成下一次 AI 产线的默认能力?未来的竞争,不是“一个程序员比另一个程序员强多少”,而是“一个组织的认知产线比另一个组织成熟多少”。
未来真正稀缺的人,不是会调用 AI 的人,而是会设计 AI 工作系统的人。这类人需要同时理解:业务场景,系统架构,数据结构,模型能力,工程验证,组织协作,风险治理,复杂性方法论。他不只是 coder,不只是 architect,也不只是 product manager。他更像“认知工程师”或“AI 产线架构师”。
六、AI 编程的现实冲击:效率提升是真的,风险放大也是真的
不能否认,AI 编程工具已经显著改变开发者行为。GitHub Copilot 的早期受控实验显示,在一个 JavaScript HTTP server 任务中,使用 Copilot 的开发者完成任务速度比对照组快 55.8%。() Stack Overflow 2025 开发者调查显示,84% 的受访者正在使用或计划使用 AI 工具,专业开发者中有 51% 每天使用 AI 工具。()这说明 AI 编程不是概念,而是现实。但另一面也必须看到。AI 生成代码的安全问题正在成为新风险源。Georgetown CSET 2024 年关于 AI 生成代码网络安全风险的报告,将风险归为三类:模型生成不安全代码、模型自身可能被攻击或操纵、以及未来训练反馈回路带来的下游安全影响。() 另有针对 Copilot 等工具生成代码的实证研究显示,AI 生成代码可能包含多种 CWE 类别的安全弱点。()这带来一个非常清晰的判断:AI 编程让代码生产速度提升,但也让缺陷生产速度提升。如果团队仍然用传统 review、传统测试、传统安全扫描来接收 AI 生成代码,就会出现结构性失衡:生成速度提升 10 倍,审查能力只提升 20%,安全治理仍按过去节奏运行,最后系统风险一定积累。所以 AI 软件工程不能只讨论“生成端提效”,必须同时讨论“验证端扩容”。未来软件团队的瓶颈会从“谁写代码”转移到“谁验证代码、谁理解代码、谁治理代码、谁为代码负责”。
AI 很擅长把模糊需求写得像真的一样。这是危险的。过去需求不清楚时,文档会显得混乱,团队还能意识到“没想清楚”。现在 AI 可以把没想清楚的东西包装成结构完整、语言流畅、逻辑自洽的 PRD。这会制造一种新的风险:表达清晰掩盖认知混乱。未来需求分析的关键,不是让 AI 写更漂亮的文档,而是让 AI 持续追问假设、冲突、边界和验证方式。
挑战二:架构一致性被局部生成破坏
AI 很容易生成局部正确代码,却破坏全局架构一致性。比如:绕开已有接口,重复实现业务规则,引入不一致异常处理,破坏领域模型,忽略事务边界,复制错误模式。这类问题不会在编译期暴露,也未必在单测中暴露,但会让系统逐渐腐烂。因此,AI 时代架构治理更重要,而不是更不重要。
AI 的能力高度依赖上下文。但企业软件上下文极其复杂:业务背景,历史决策,代码结构,接口约定,数据口径,权限规则,异常处理,合规要求,客户偏好,组织潜规则。谁能把这些上下文结构化、版本化、可检索、可注入,谁的 AI 工程能力就强。未来企业会出现一种新型基础设施:工程上下文底座。它不是普通知识库,而是面向 AI 产线的组织记忆系统。
挑战五:责任边界变得模糊
AI 写的代码出了问题,谁负责?模型厂商?工具供应商?开发者?架构师?测试人员?项目经理?业务方?企业?这个问题不能靠伦理口号解决,必须靠工程机制解决。每一次 AI 参与的软件变更,都应当有:输入记录,模型版本,上下文来源,生成结果,人工修改,验证报告,发布记录,运行反馈,责任签署。AI 时代的软件工程必须天然具备审计能力。
挑战六:初级岗位被挤压,人才培养链断裂
AI 最先替代的不是顶级架构师,而是初级程序员的典型训练任务:写 CRUD,补测试,查 API,修简单 Bug,写脚本,改页面,做格式转换。问题是,这些任务过去正是初级工程师成长的路径。如果这些任务被 AI 接管,那么新人如何成长为高级工程师?这是软件行业未来十年的大问题。企业不能只想着用 AI 替代 junior,而要重新设计人才培养机制:让新人更早接触场景、架构、测试、反馈、AI 产线和业务价值。
挑战七:软件供给爆炸,价值定义稀缺
AI 会让软件供给大幅增加。未来不是没人会做软件,而是到处都是软件。真正稀缺的是:哪些软件值得做?哪些场景值得智能化?哪些流程值得重构?哪些需求是伪需求?哪些系统会带来真实 ROI?所以软件行业的价值中心会前移。从“如何做出来”转向“为什么做、做什么、做到什么程度、如何证明价值”。这正是精益 AI 方法论的核心命题:场景牵引,价值闭环,小步验证,持续演化。
九、未来趋势:软件行业会走向五个新方向
趋势一:AI 原生软件工程平台出现
未来的 IDE 不会只是写代码的地方,而会成为 AI 研发操作系统。它会集成:需求上下文,代码库理解,测试生成,架构约束,安全扫描,部署流水线,运行监控,反馈学习,智能体协同。开发者不再是在 IDE 里敲代码,而是在一个认知控制台里调度 AI 产线。
趋势二:测试驱动会重新崛起
TDD 过去一直叫好不叫座,因为人写测试成本太高。AI 时代,测试驱动会变成工程底座。因为 AI 生成速度太快,必须有测试作为制动系统。未来可能出现一种新模式:Specification-Driven AI Development先定义规格、契约、测试、约束和评测集,再让 AI 生成实现。这其实是 TDD、BDD、契约编程、形式化方法和 AI 编程的融合。
趋势三:架构师重新变得重要,但工作内容变化
AI 不会让架构师消失,反而会让真正的架构师更重要。但架构师不再只是画图和选型,而要设计:AI 可理解的系统边界,AI 可遵守的编码规范,AI 可验证的接口契约,AI 可调用的工具链,AI 可学习的反馈机制,AI 可审计的责任链。架构师会变成 AI 产线的总设计师。
趋势四:业务专家成为软件生产核心角色
过去业务专家经常只是需求提供者。未来业务专家会成为 AI 软件工程的重要参与者。因为 AI 可以降低技术表达门槛,让业务专家直接参与规则定义、流程建模、场景验证和价值评估。但前提是业务专家要学会把隐性知识表达成 AI 可处理的形式。这会催生一个新岗位:Domain Knowledge Engineer,领域知识工程师。
趋势五:组织会从项目制转向产线制
传统软件团队围绕项目组织。AI 时代更适合围绕产线组织。一条成熟 AI 软件产线可以持续处理某类需求,比如:报表产线,流程应用产线,数据接口产线,移动端页面产线,运维自动化产线,合同审查产线,企业智能体产线。产线的核心不是人多,而是规则、上下文、工具、模型、测试和反馈沉淀得足够深。
十、对软件行业从业者的影响:不是消失,而是分层重组
1. 初级程序员:从“写代码”转向“读代码、验代码、改代码”
初级程序员最需要改变的是学习路径。过去是先学语法,再写功能,再做项目。未来应该是先理解软件系统,再学习如何让 AI 生成,再学习如何验证、调试、约束和重构。初级工程师要尽快掌握:AI 编程工具,测试基础,Git 工作流,代码阅读,安全常识,业务建模,Prompt 与上下文组织。不会用 AI 的初级程序员会被淘汰;只会用 AI 生成代码的初级程序员也会被淘汰;能用 AI 快速学习系统、理解业务、补齐测试、定位问题的人会成长更快。
2. 高级工程师:从实现专家转向系统判断者
高级工程师不能再把优势建立在“我比别人会写代码”上。未来优势来自:理解复杂系统,识别架构风险,拆分问题边界,设计验证机制,发现 AI 生成代码中的隐性错误,把经验沉淀为组织规则。高级工程师要成为“AI 的老师”和“系统的医生”。
AI 会让写 PRD 变得便宜。因此,单纯写文档的产品经理价值会下降。真正有价值的产品经理,要能:识别真实场景,定义业务价值,构造验证实验,发现用户行为模式,协调利益冲突,判断哪些需求不该做,把复杂业务转化为 AI 可执行的场景模型。产品经理会从“需求翻译”走向“价值设计”。
5. 测试工程师:从执行测试转向质量系统设计
AI 时代测试不是被削弱,而是被升级。测试工程师要从手工执行转向:测试策略设计,自动化测试体系,评测集建设,模型输出验证,异常场景生成,安全测试,质量指标体系。未来测试工程师很可能成为 AI 软件工程里最关键的角色之一,因为他们掌握确定性裁判。
6. 项目经理:从进度管理转向流动效率管理
AI 会改变项目管理对象。过去项目经理盯人、盯任务、盯进度。未来要盯:需求流动,上下文流动,反馈流动,缺陷流动,知识沉淀,AI 产线瓶颈,价值实现节奏。项目经理要从“人力调度员”变成“系统流动设计师”。
7. CTO / 技术负责人:从工具采购转向范式转型
企业技术负责人最危险的误判,是把 AI 编程当成采购 Copilot、Cursor、Claude Code 或某个 Agent 平台。真正的问题是:企业是否有 AI 原生研发流程?是否有上下文底座?是否有测试资产?是否有架构规则?是否有安全边界?是否有场景知识沉淀机制?是否有 AI 产线指标?是否有组织级学习闭环?如果没有这些,AI 工具越强,风险越大。
十一、面向企业的软件工程转型路线:从工具试点到认知产线
企业不要一上来就喊“全面 AI 化研发”。更稳健的路线应该是六步。
第一步:识别问题域
用 Cynefin 对研发活动分类:清晰域:直接自动化。繁杂域:专家 + AI 增强。复杂域:小实验 + 快反馈。混沌域:止血机制 + 人工强接管。这一步能避免方法错配。
第二步:选择高形式化场景
优先选择:单元测试生成,接口代码生成,数据校验脚本,报表页面,API 文档,日志分析,运维脚本,低风险内部工具。不要一开始就让 AI 接管核心交易系统、复杂风控逻辑、强合规流程。
第三步:建立确定性裁判
没有验证,不准扩大 AI 使用范围。至少要建设:自动化测试,静态分析,安全扫描,契约校验,代码规范检查,运行监控,回滚机制。
AI 软件工程最难的不是写代码,也不是调模型,而是隐性知识蒸馏。什么是隐性知识?老员工知道但文档没有写的规则;业务专家凭直觉判断的异常;架构师脑子里的历史妥协;运维人员知道的系统脾气;客户不会明说但一定在意的体验;监管不一定写死但不能碰的红线;数据口径背后的组织博弈。这些东西不进入 AI 上下文,AI 就永远像外包团队。真正领先的企业,会把隐性知识变成:结构化规则,可检索知识,可执行约束,可验证测试,可追踪案例,可复用智能体技能。这就是 AI 时代软件组织的核心资产。代码不再稀缺,隐性知识显性化能力才稀缺。
结语:软件工程正在从“人脑手工业”走向“认知工业化”
回看软件工程五十年,会发现它一直有一个未完成的梦想:让软件像其他工程一样可规划、可构造、可验证、可维护、可规模化。但它一直没有真正做到。因为软件工程处理的不是物理材料,而是人类认知;不是稳定结构,而是变化业务;不是单一系统,而是社会技术复杂体。大模型第一次让“高阶认知能源化”成为可能。这是软件工程历史上前所未有的事件。但这不意味着软件工程自动进入黄金时代。如果没有确定性裁判,AI 会制造幻觉;如果没有闭环,AI 不会学习组织经验;如果没有上下文底座,AI 会变成聪明外包;如果没有复杂性判断,AI 会高效执行错误方向;如果没有隐性知识蒸馏,AI 永远无法进入核心业务。所以,AI 时代软件工程的最终命题不是:如何让 AI 写代码?而是:如何把 AI 纳入一个可验证、可纠偏、可演化、可治理的认知生产系统?这就是软件工程的第二次奠基。第一次奠基,软件行业学会了把人组织起来写代码。第二次奠基,软件行业要学会把 AI、人、知识、规则、反馈和价值组织起来生产智能系统。未来真正优秀的软件从业者,不是“最后一批会写代码的人”,而是“第一批会设计认知产线的人”。未来真正强大的软件企业,也不是拥有最多程序员的企业,而是拥有最成熟 AI 软件工程闭环的企业。软件工程不会消失。它只是终于要从“写代码的手工业”,走向“认知生产的工程学”。
 夜雨聆风
夜雨聆风