 夜雨聆风
夜雨聆风





大千万级文档 RAG,这 11 个步骤把幻觉压到极低
但你有没有过这样的经历:demo 里跑得飞起的 RAG,一接上真实业务的几百万份文档,立刻原形毕露——答非所问、引用错乱、一本正经地胡说八道?
大多数 RAG 教程都止步于:
“把 embedding 存进向量数据库,然后把上下文发给 GPT。”
这套架构在演示里行得通。
但在一千万份文档面前,它会彻底崩溃。
那么问题来了:从”能跑的 demo”到”敢上生产的系统”,中间到底差了什么?
在规模化场景下,检索变得嘈杂,延迟上升,无关的文本块到处出现,幻觉也变得更加难以控制。
生产级 RAG 系统真正的难点,从来不在于生成答案。
而在于稳定地检索到正确的信息,并且能证明这个答案确实立足于真实数据。
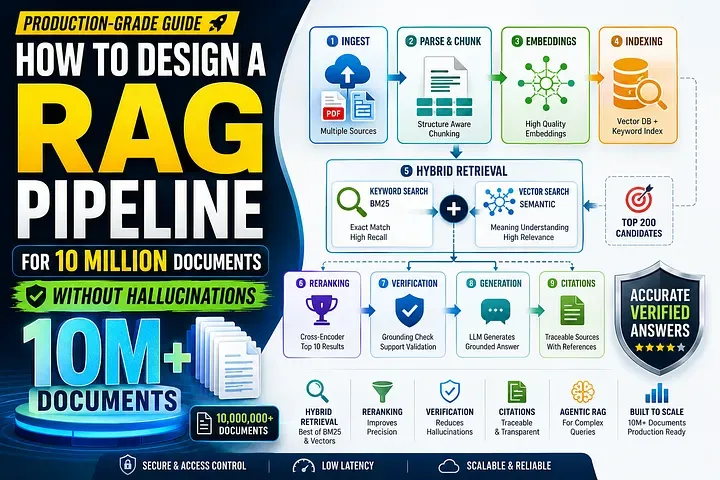
本文要做的,是设计一套真正能扛住数百万份文档的生产级 RAG 架构——靠混合检索、重排序、验证层和引用强制机制,把幻觉摁到最低。
为什么基础 RAG 流水线会失败
一个典型的入门级 RAG 流水线长这样:
User Query ↓Embedding Search ↓Top K Chunks ↓LLM Response简单、快速、容易搭建。
但一旦你的文档数量涨到数百万级,几个问题立刻冒头:
举个例子,用户问:
"How many vacation days are allowed for contractors in Germany?"纯向量检索可能会召回:
……唯独没召回那一节真正确切的承包商政策。
于是 LLM 开始试图”填补空白”。
幻觉,就是从这一刻开始的。
企业级 RAG 的真正目标
大多数人以为,RAG 是为了改善 LLM 的答案。
但真相是:
RAG 首先是一套搜索与检索系统。LLM 只是叠在上面的一层推理。
现代企业级 RAG 系统,重心高度集中在这几件事上:
模型绝不应该凭空编造信息。
如果系统检索不到足够的证据,它就该闭嘴,选择不作答。
高层架构
一套生产级 RAG 流水线,通常长这样:
┌─────────────────────┐ │ Source Systems │ │ PDFs, APIs, DBs │ └──────────┬──────────┘ │ Ingestion Pipeline │ ┌──────────────────┴──────────────────┐ │ │ Metadata Extraction Document Parsing OCR / Tables / Layout Chunking Strategy │ │ └──────────────┬──────────────────────┘ │ Embedding Pipeline │ ┌──────────────┴────────────────┐ │ │ Vector Store Keyword Index (Semantic Search) BM25 / Hybrid │ │ └──────────────┬────────────────┘ │ Retrieval Layer Hybrid + Reranking │ Context Validation │ LLM Generation │ Citation Verification │ Final Response它的扩展性之所以好得多,关键在于一句话:它把检索当成一条多阶段流水线,而不是一次性的向量查询。
第 1 步:搭建可靠的摄取(Ingestion)流水线
在一千万份文档的规模下,摄取本身就变成了一个分布式系统问题。
文档可能来自四面八方:
记住一个原则:原始文档和解析后的内容,必须分开存储。
典型的存储布局:
/documents/{tenant}/{doc_id}/raw.pdf/documents/{tenant}/{doc_id}/parsed.json这样才支持得了:
S3 或 GCS 这类对象存储,在这里很合适。
第 2 步:解析,比你想象的重要得多
糟糕的解析,是导致幻觉的最大隐藏元凶之一。
如果你的解析器破坏了:
……你的 embedding 质量会当场变差。
对企业级 RAG 来说,解析必须是版面感知(layout-aware)的。
几个靠谱的解析工具:
你的目标是保留语义结构,而不只是抠出一堆纯文本。
第 3 步:分块(Chunking)策略,决定成败
大多数教程都用固定大小分块:
chunk_size = 1000overlap = 200这通常是错的。
随机的 token 分块,会把上下文的边界生生切断。
正确的做法,是语义分块(semantic chunking)。
按这些维度来分:
糟糕的分块:
...payment terms continue here...良好的分块:
Section: Contractor Vacation Policy分块分得好,检索精度会直接上一个台阶。
第 4 步:永远不要只用向量检索
这大概是生产环境里最大的一个坑。
在大规模场景下,单靠向量检索,远远不够。
为什么?
因为 embedding 擅长语义相似度,但在这些地方却很弱:
像这样的查询:
ERR_CONNECTION_RESET_1045用纯 embedding,大概率惨败。
所以,生产级 RAG 系统都走混合检索(hybrid retrieval)。
混合检索架构
现代系统会把两条路结合起来:
稀疏检索(BM25)
最擅长:
通常由这些技术驱动:
稠密检索(Embeddings)
最擅长:
通常由这些技术驱动:
检索流水线
别再直接从向量数据库捞数据了,正确的姿势是:
User Query ↓Query Rewriting ↓Hybrid Search(BM25 + Vector) ↓Top 200 Candidates ↓Cross-Encoder Reranker ↓Top 10 Chunks ↓LLM这套架构,能把相关性显著拉上去。
第 5 步:重排序(Reranking)是必选项,不是加分项
在大规模场景下,初次检索注定是嘈杂的。
哪怕是再优秀的 embedding,也会返回一堆”部分相关”的结果。
这正是现代 RAG 系统离不开重排序器(reranker)的原因。
重排序器会对这几点重新打分:
它扮演的是第二道过滤闸门。
主流重排序器:
没有重排序,无关文本块会一路渗进 prompt,幻觉率随之飙升。
第 6 步:元数据过滤,彻底改变游戏
在一千万份文档的规模下,元数据变得不可或缺。
每个文本块,都该带上结构化的元数据:
{ "tenant_id": "acme", "department": "finance", "doc_type": "policy", "country": "germany", "created_at": "2026-01-01"}这样一来,检索瞬间变聪明:
contractor policy germany after 2025而不是在整个语料库里大海捞针。
精度大幅提升,幻觉显著下降。
第 7 步:上下文压缩
大上下文窗口,并不能替你解决检索问题。
把 100 个文本块一股脑塞给 GPT,往往反而把答案质量拉低。
生产系统会在生成之前,先把上下文压一遍:
Retrieved Chunks ↓Deduplication ↓Relevance Filtering ↓Context Compression ↓Structured Context这能让 prompt 始终保持聚焦、句句有据。
第 8 步:基于证据的 Prompt(Grounded Prompting)
绝不要这样写 prompt:
Answer the question.而要用带约束的 prompt:
Answer ONLY using the provided context.If the answer cannot be found, say:"I could not find this information in the knowledge base."仅仅是这一处改动,就能让幻觉肉眼可见地变少。
第 9 步:强制引用
企业级系统,越来越要求答案可被验证。
每个回答,都该附上引用:
The contractor vacation limit is 20 days[Doc-182, Section 4.2]如果没有证据支撑,就该:
模型绝不该抛出一个没有依据的论断。
第 10 步:加上验证层
高级 RAG 系统和演示级 demo 真正拉开差距的地方,就在这一步。
在生成之后,再跑一个验证器(verifier)模型。
流水线:
LLM Answer ↓Verification Model ↓Grounded / Unsupported验证器专门负责揪出:
这一层,能把幻觉再砍下去一大截。
第 11 步:智能体式 RAG(Agentic RAG)
复杂的企业级问题,往往不是一次检索能搞定的。
不是:
retrieve once → generate而是现代系统采用:
plan → retrieve → verify → reason比如这个问题:
"How did vendor payment policies change after the 2025 compliance update?"它可能需要:
这正是智能体式检索大显身手的地方。
推荐的生产技术栈
一套靠谱的开源生产技术栈,大概长这样:
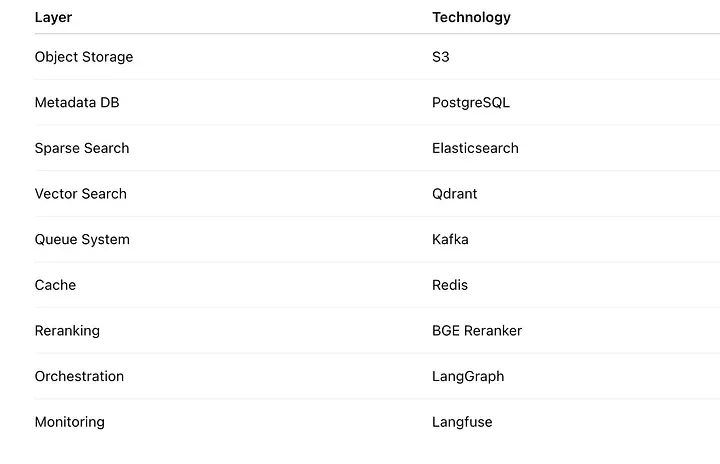
这套架构,足以扛住企业级的工作负载。
团队最常踩的 6 个坑
1. 只用向量检索
混合检索几乎总是更胜一筹。
2. 糟糕的分块
随机的 token 分块,会把语义结构切得稀碎。
3. 没有重排序
单靠 embedding 检索,太吵了。
4. 巨型 Prompt
上下文更多,不等于答案更好。
5. 没有验证层
没有验证,幻觉就变成了隐形的。
6. 没有弃答(Abstention)逻辑
有时候,最正确的答案其实是:
I don't know.生产系统,必须撑得住这句”我不知道”。
你真的能做到零幻觉吗?
并不能完全做到。
LLM 本质上是概率性系统。
但你完全可以构建出一套让幻觉极其罕见的架构,方法就是把这些手段叠在一起:
Hybrid Retrieval+ Reranking+ Metadata Filters+ Grounded Prompting+ Citation Enforcement+ Verification Layers+ Abstention Logic这,就是现代企业级 RAG 系统真实的做法。
结语
关于 RAG,最大的误解,就是把它当成一个 LLM 问题。
它其实是一个信息检索问题。
小规模下,简单的向量检索就够用了。
但到了企业级规模,检索架构就是一切。
今天那些真正在做可靠 AI 系统的公司,绝不只是给 GPT 套个 embedding 就完事。
他们在构建:
因为在生产级 AI 系统里:
检索质量,决定答案质量。
而最好的 RAG 系统,骨子里更愿意:
宁可说一句”我不知道”,也不抛出一个自信却错误的答案。
技术接进业务这一步,你卡在哪个环节了——是分块、检索,还是幻觉摁不住?评论区聊聊你的踩坑现场。
————————————————————-
希望这篇文章能为您带来一些帮助。如果有任何疑问或建议,请在评论区留言,我们将尽力回答!
让我们一起探索并推动前沿技术发展!🚀💻
祝好运!😊✍️