 夜雨聆风
夜雨聆风





消息太多时,OpenClaw最该做的是过滤而不是跟风
AI × 量化交易,每天更新!
策略 · 代码 · 数据 · 工具
→ 关注,让 AI 帮你做投研
今天的主题是:舆情过滤不能只看功能。
很多人用OpenClaw时,第一反应是问它能不能更快、更自动、更省事。可真正决定这套工具有没有价值的,往往不是功能列表,而是人有没有把输入、判断、确认、复盘这几步摆正。
今天把“消息太多的时候,OpenClaw最该做的是过滤”“热度不是信号,情绪也不是结论”“一个上午几十条快讯,为什么越看越乱”三个问题放在一起聊,因为它们本质上讲的是同一件事:别急着让工具往前冲,先让流程站稳。
消息太多时
OpenClaw最该做的是过滤
很多人第一次想把舆情过滤用起来,注意力会自然落到功能上。能不能自动读数据,能不能生成报告,能不能把某个动作接到任务里。功能当然重要,但如果只看功能,很容易漏掉更底层的一件事:舆情不是交易信号,它最多提醒你重新检查计划。
对容易被市场消息牵着情绪跑的人来说,最危险的地方恰恰在于:快讯、群消息和截图会不断制造紧迫感,很多人被热度推着走。工具越顺手,人越容易把“我想做”包装成“系统建议我做”。

先把舆情过滤看成流程
过去很多投研动作都散在脑子里。真正进入舆情过滤场景时,看到消息就临时判断,看到价格就临时调整,做错了再靠记忆补一句解释。OpenClaw的价值,是把这些动作拉到明面上,让人看见输入、判断、执行和复盘之间到底隔了几步。
所以聊舆情过滤,不能只问它能做什么,还要问它应该站在哪个位置。围绕RSS源、新闻标题、发布时间、关键词、情绪分数、事实核验,它可以整理信息,也可以检查偏离,还可以留下复盘证据。但只要让它直接替人拍板,流程重心就会从“检查”滑向“下注”。
重点:舆情过滤可以提高流程密度,但不能替代风险责任。

具体到舆情过滤,最值得盯住的不是某个炫目的功能,而是这些细节有没有被写下来:RSS源、新闻标题、发布时间、关键词、情绪分数、事实核验分别从哪里来、谁能改、出错后谁负责确认。只要这些问题还停留在口头上,系统越顺,人越容易放松。

一个和RSS源有关的现场

阿敏一个上午刷到几十条快讯,几乎每条都像大事。有人说利好,有人说风险,有人贴图,有人喊机会。她让OpenClaw做舆情汇总,结果报告越看越紧张,最后不是因为计划变化而行动,而是因为自己不想错过。
这个场景里,真正的错误不是用了OpenClaw,而是把热度当重要性,把情绪当结论,把二手转述当事实。很多新手以为自己只是多问了一句,其实是把一个尚未验证的判断送进了下一步。
后果也不抽象。消息越密,判断越碎,交易动作越容易变成即时反应。如果当天行情顺着走,人会觉得系统很灵;如果行情反着走,人又会怪工具没判断准。可真正应该被复盘的,是当初有没有把边界写清楚。
很多人后面回看自己的问题,会发现它并不复杂。不是不知道舆情过滤该怎么做,而是当时没有一个稳定位置来接住判断。一旦位置清楚,OpenClaw的回答就不会漂在空中,而会落到某个表、某条日志、某个确认动作上。

舆情过滤顺序很重要
我更建议把RSS源、新闻标题、发布时间、关键词、情绪分数、事实核验先搭出来。它们不一定高级,但足够把舆情过滤里那些混在一起的动作拆开。
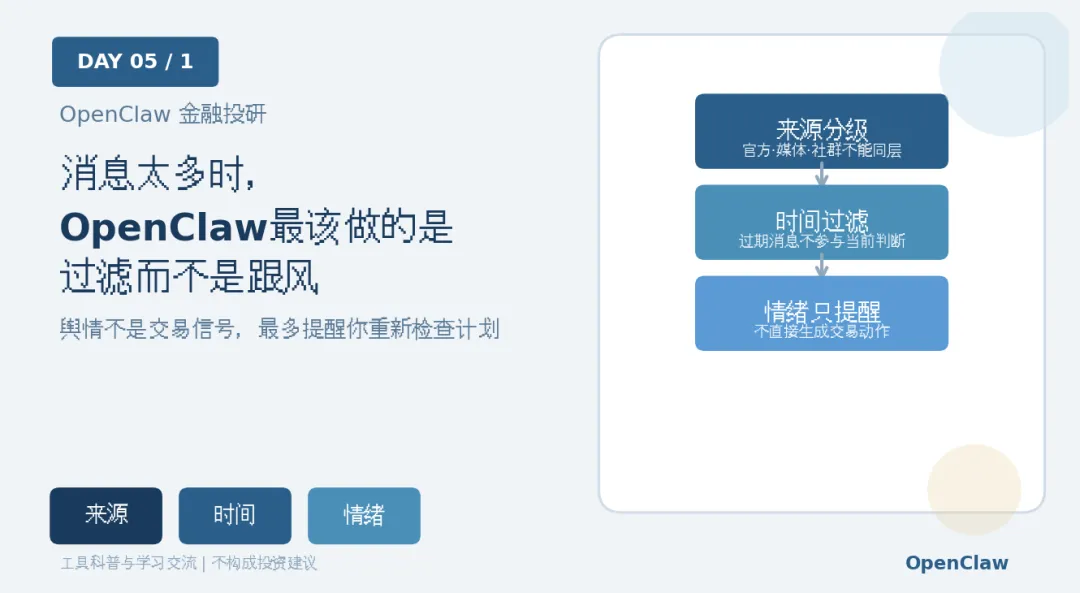
第一,先按来源分级,官方公告、主流媒体、社群传闻不能放在同一层。这一步的意义,是把当天的注意力先收窄,不让市场上每一条消息都进来打扰。
第二,每条信息都保留时间,过期消息不参与当前判断。盘中最需要被看见的,不是机会,而是自己有没有偏离。
第三,情绪分数只作为提醒,不直接生成交易动作。只要涉及真实执行,就不要让一句自然语言直接变成动作。
第四,最终报告只输出和原计划有关的风险变化。复盘不是写作文,而是给下一次留一个可重复使用的提醒。
放到舆情过滤里看,舆情过滤的目标不是更快下判断,而是让自己慢半拍,确认这条消息到底和自己有没有关系。
热度不是信号
情绪也不是结论
热度不是信号,情绪也不是结论,这句话听起来像经验,其实背后是一类非常常见的上手事故。
很多新手不是不谨慎,他们只是低估了舆情过滤里的“顺手”。屏幕上多一个按钮,报告里多一句判断,任务里多一个开关,人就会觉得事情已经被系统接住了。问题也正是在这个舒服的瞬间开始的。

舆情过滤的坑
快讯、群消息和截图会不断制造紧迫感,很多人被热度推着走。这类问题在文档里看不出来,在演示里也很难看出来,只有真正把工具放进自己的日常流程,才会暴露。

比如你以为自己只是配置了RSS源、新闻标题、发布时间、关键词、情绪分数、事实核验,但它们之间的顺序如果不清楚,最后就会变成一条含糊的链:信息进来,OpenClaw分析,人被说服,任务继续往前走,盘后再来解释。
重点:舆情过滤越顺滑,越要先检查它有没有刹车。
这也是为什么我不太建议新手一开始就追求“全自动”。舆情过滤里的很多坑,只有在低风险环境里多跑几遍才会暴露。暴露得早,是好事;拖到真实执行里才暴露,成本就不一样了。

舆情过滤里一个小动作的连锁反应
还有一种更常见的情况。新手往往不是一次性犯大错,而是在舆情过滤上做了一个看似省事的小动作:少看一眼RSS源,少写一句确认,少保存一份记录。当时它不显眼,等到盘后复盘,才发现整个链条都说不清楚。

这个案例里,把热度当重要性,把情绪当结论,把二手转述当事实。它看起来不像大错误,更像一个为了省事的动作。可投研和交易里的很多风险,就是从省事开始的。
麻烦的是,消息越密,判断越碎,交易动作越容易变成即时反应。等你意识到不对时,系统日志里可能已经出现了一串你没认真确认过的输出。
这也是公众号文章里值得反复讲的地方:真实风险通常不戏剧化。它不像电影里突然报警,更像是一个人赶时间,少写了一行备注,少看了一次确认,少留了一份日志。舆情过滤要解决的,正是这些不起眼的小缺口。

把错误挡在低风险位置
第一步,先按来源分级,官方公告、主流媒体、社群传闻不能放在同一层。不要嫌这一步慢,它是在帮你把错误留在小范围里。
第二步,每条信息都保留时间,过期消息不参与当前判断。OpenClaw可以承担提醒、整理和复盘,但不该在你还没稳定前承担执行。
第三步,情绪分数只作为提醒,不直接生成交易动作。凡是说不清谁负责的动作,都先不要接入自动化。
第四步,最终报告只输出和原计划有关的风险变化。日志不是给别人看的,是给未来那个忘记细节的自己看的。
也可以做一次逆向检查:假设明天舆情过滤出了问题,你能不能从日志里还原当时发生了什么。如果还原不了,就说明不是分析能力不够,而是证据链太薄。先补RSS源,再谈更复杂的设置。
如果只能给舆情过滤留一句提醒,就是这个:舆情过滤的目标不是更快下判断,而是让自己慢半拍,确认这条消息到底和自己有没有关系。
一个上午几十条资讯
为什么越看越乱
聊舆情过滤,最容易陷入两个极端。一个极端是把OpenClaw想得太神,什么都想交给它;另一个极端是只把它当聊天工具,用完一段回答就关掉。放到容易被市场消息牵着情绪跑的人身上,两种都可惜。
更稳的做法,是把舆情过滤拆成三层:输入层、判断层、执行层。拆开以后,你会发现很多所谓高级问题,其实是最基础的层次没有分清。

把舆情过滤拆成三层
输入层
解决的是信息从哪里来。RSS源、新闻标题、发布时间、关键词、情绪分数、事实核验都属于输入和证据。没有稳定输入,后面再漂亮的分析都像建在沙子上。
判断层
解决的是信息怎么被解释。围绕舆情过滤,最怕的不是判断保守,而是判断没有依据。你需要让OpenClaw说明它参考了哪些事实,忽略了哪些噪音,对原计划造成了什么影响。
执行层
解决的是谁来动作。到了舆情过滤这一层,就不能只看效率,还要看权限、确认和暂停条件。
三层拆开以后,责任也会清楚。输入层错了,就查数据和文件;判断层错了,就查规则和提示词;执行层错了,就查权限和确认。这种拆法看起来笨,但它能让舆情过滤从一段回答变成一套能复盘的流程。

舆情过滤每一层都要留下证据
把场景拆开看会更清楚。输入端有RSS源、新闻标题、发布时间、关键词、情绪分数、事实核验,判断端有AI给出的分析,执行端有人自己的确认。一旦这三层混在一起,把热度当重要性,把情绪当结论,把二手转述当事实就会变得很自然。很多问题不是突然发生的,而是从层次混乱开始的。
这段经历的关键,不在于某个功能有没有打开,而在于把热度当重要性,把情绪当结论,把二手转述当事实。一旦三层混在一起,AI给出的每一句话都可能被人误读成行动指令。
重点:围绕舆情过滤,能追溯的流程才有资格被优化。追溯不了,只能靠感觉争论。
拆层还有一个好处,是团队沟通会变简单。你不用再说“AI好像分析错了”,而是能说清楚错在输入、规则还是权限。这句话一说清,舆情过滤就从玄学变成了可改进的工程。

让OpenClaw进入舆情过滤工作流
输入层先做:先按来源分级,官方公告、主流媒体、社群传闻不能放在同一层。
判断层再做:每条信息都保留时间,过期消息不参与当前判断。这一步要让结论变得可检查,而不是只显得专业。
执行层最后做:情绪分数只作为提醒,不直接生成交易动作。到了这里,任何含糊的权限都会变成风险。
如果已经进入较复杂的使用阶段,还要补上第四步:最终报告只输出和原计划有关的风险变化。
最简单的练习,是把今天的舆情过滤流程画在纸上。左边写输入,中间写判断,右边写动作。任何跨过中间直接从输入走到动作的箭头,都要停下来重看。这张小图能救下很多看不见的错误。
舆情过滤的目标不是更快下判断,而是让自己慢半拍,确认这条消息到底和自己有没有关系。 这不是降低工具价值,而是让舆情过滤能长期留在流程里的前提。
最容易漏掉的是“中间那一步”

围绕舆情过滤,很多人复盘自己为什么用不好工具,会把原因归结为模型不够强、提示词不够准、服务器不够稳。这些当然会影响结果,但更常见的问题,是中间那一步没有被看见。从“我看到一条消息”到“我改变今天的计划”,中间应该有事实核对、原计划对照、风险变化判断、人工确认。如果这几步被一句自然语言带过去,OpenClaw再聪明,也只是在帮一个含糊的判断写得更像样。
所以在舆情过滤这件事上,第一件事不是追求更复杂的自动化,而是把这些中间步骤显性化。你可以让它帮你整理事实,但不要让它替你承担风险责任;你可以让它检查偏离,但不要让它把偏离自动翻译成动作;你可以让它写复盘,但必须保留当时的输入、时间、数据来源和人工确认记录。这些东西看起来没有炫技感,却是普通人把AI投研工具用稳的关键。
注意:围绕舆情过滤,OpenClaw可以提高投研流程的密度,但它不替任何人承担市场风险。

本文仅做AI投研工具科普,不构成投资建议,不提供荐股、带单或收益承诺。