 夜雨聆风
夜雨聆风





肝了7000字!小白也能看懂的 OpenClaw 保姆级入门指南
大家好,我是噪点
终于能抽出时间来系统的写下openclaw了,作为今年最火的ai项目,近期传播越来越广。不仅线上都在讨论“如何养虾”,就连线下办 openclaw大会也都场场爆满,甚至上门代安装都变成了一门生意。

但客观说,上手openclaw确实会有点门槛,尤其是对于非技术党小白。
所以我打算出个系列,分享下我自己的真实openclaw踩坑经验、使用教程等。尽量用通俗易懂的大白话,就算是新手小白,看完也能跟着从零实操起来。
本篇是第一篇,会整体介绍下openclaw:包括是什么、部署方式、下载安装、聊天bot配置、模型切换,skill安装、个性化文档配置、tool权限、常见命令9大部分。
跟着这篇走下来,相信你也能亲手孵化出一只用手机就能让它自主在电脑干活的“龙虾”。
openclaw,是奥地利开发者peter做的一个agent项目,短短2个多月,就成为史上增长最快的开源项目。
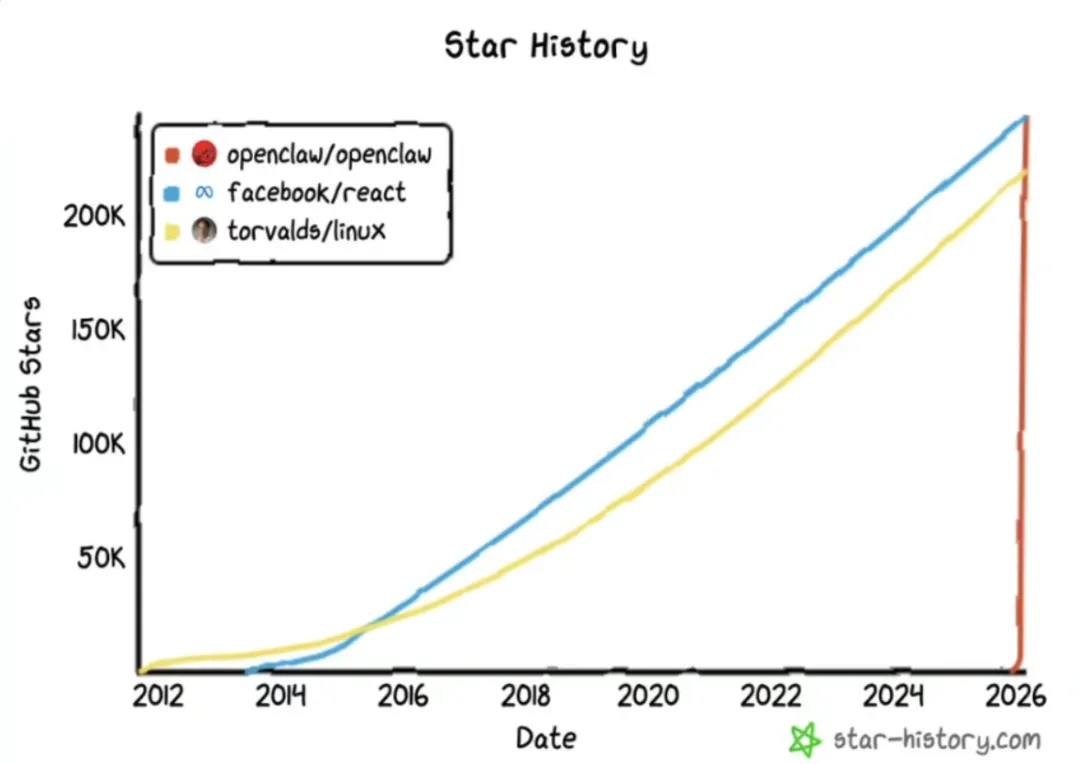
它的核心是一个网关中枢(gateway)。
可以一端连接常见的通讯工具,比如telegram、discord、飞书、企微等;一端连接大模型api,比如国外的claude、gpt,国内的glm、kimi、deepseek等。
并且它还支持通过模型的思考去调用对应工具和技能,从而完成本地电脑上的任务。
大白话说,它就是你的7*24h个人助理agent。
你可以通过聊天的方式指挥ai把本地电脑上的的活干了;比如你在飞书上发条任务消息,它会通过gateway网关发给模型,模型思考完后会调用相关本地工具干活(甚至可以指挥电脑本地上的claude code、codex这类agent去干活),然后再把结果通过飞书消息返回给你。
所以理论上只要权限够大,你可以用手机指挥它做一切在电脑上能做的事。
并且还因为独特的记忆机制,可以实现永久记忆;这意味着它会越用越懂你,不断进化。又因为这个工具的logo是一个龙虾,所以开始有了“养龙虾”这个说法。
目前部署openclaw主要有3种方式:云端部署、虚拟机、本地部署。
云端部署:
现在国内阿里云、腾讯云等都推出了openclaw一键部署服务;包括kimi、minimax也都推出了对应的claw产品。
但能力效果要比本地弱很多,如果只是简单体验下,可以选择云端,安装成本低;如果是想作为生产力工具,还是建议本地部署。
虚拟机:
这个是指在本地装一个隔离的虚拟机来进行安全管控,比如Parallels。
需要电脑给虚拟机分配内存,并且配置也复杂,对于新手不建议。
本地部署:
这是指直接安装在电脑本地的一种方式,也是我首推的部署方式,但一定要注意,因为openclaw权限比较大,所以一定不要用主力机,避免安全风险。
另外建议mac最佳,比win系统体验更好一点;当然前期也没必要花钱去买mac mini这类产品,一个旧的mac air就能跑。
因为openclaw的大量计算还是在模型那边,本地电脑只是负责一些api调用和收发消息,对配置要求并不高。
所以下文会以本地部署进行展开。
其实这部分的安装倒不复杂,只是后面的各种参数配置会麻烦些,跟着一步步来即可。
在具体安装前,要先准备好模型api和基础环境。
模型api:
openclaw目前基本主流模型都支持,不管是从claude、gpt、gemini还是国内的kimi、qwen、glm、doubao、minimax、deepseek等,所以我们需要去申请想要使用模型的api。
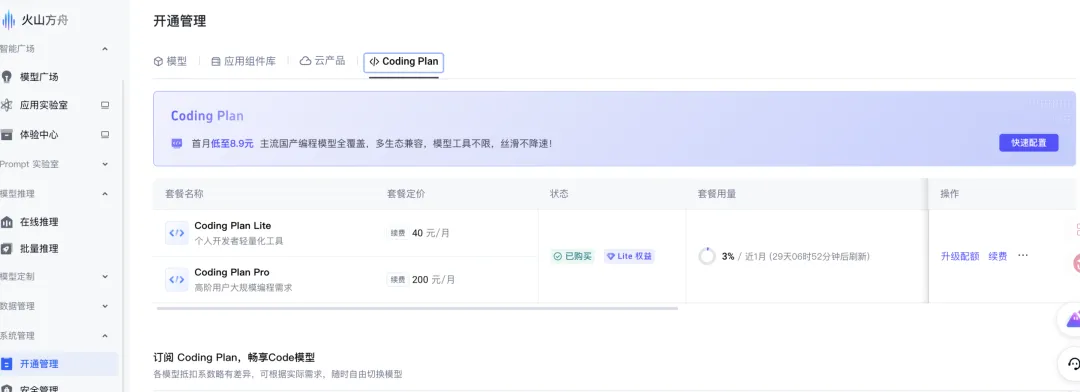
现在,国内几家模型厂商都推出了自己的coding plan计划:
比如,既有阿里百炼和字节火山方舟这种聚合模型服务平台,一个api就能使用多家模型,囊括kimi、glm、minimax等国内第一梯队模型;
阿里:
https://bailian.console.aliyun.com/cn-beijing/?tab=coding-plan#/efm/index
字节:
https://console.volcengine.com/ark/region:ark+cn-beijing/openManagement?LLM=%7B%7D&advancedActiveKey=subscribe
并且新客首月都有优惠,几块钱就能使用,量大管饱。
也有厂商自己家的单类模型coding plan计划,比如智谱、kimi、minimax这几家,直接去官网申请即可。
当然国外的模型api也支持,这里为了方便介绍,我就以字节coding plan套餐为例。
基础环境:
openclaw的运行需要电脑有node.js环境,且需node.js >= v.22。
如果一直用claude code、codex这类终端agent工具的朋友肯定都很熟悉了,node.js是这些工具运行的必备环境。
如果不确定电脑是否安装的,可以终端输入:
node --version能够返回版本号比如“v25.x.x”就是已经安装了。
如果显示command not found即没安装,需要输入下方命令进行安装:
mac:
brew install nodewin:
winget install OpenJS.NodeJS.LTS理论上在安装openclaw时,如果检测到没这些环境系统会自动安装,但提前装好速度会快些。
上述模型和基础环境准备好了后,就正式进入安装流程。
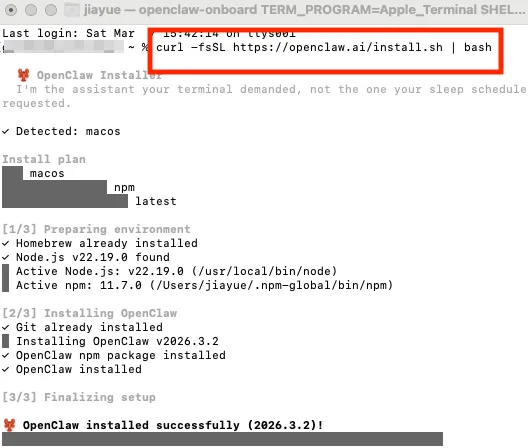
打开终端,输入下方一键安装openclaw命令:
mac
curl -fsSL https://openclaw.ai/install.sh | bashwindows使用powershell:
iwr -useb https://openclaw.ai/install.ps1 | iex几分钟后就安装好了;
然后会弹出onboarding mode也就是向导模式,可以引导我们一步步去配置,选择quickstart;
如果没看到这个向导模式,可以运行下方命令进入;
openclaw onboard --install-daemon然后就跟着向导进行配置就可以了:
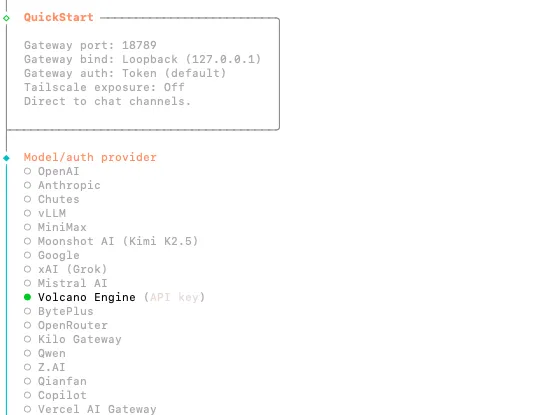
第一步:配置模型
因为我这里是用字节火山的coding plan套餐,所以这里厂商选volcano engine(火山方舟英文名),如果用其他模型就选对应的厂商;
然后鉴权方式选择api登录,输入前面购买套餐后拿到的api key(输入后回车即可,终端不会显示api key),按需选择具体的模型,也就是我们后面在openclaw中用的模型;如果图省事就选择第一个keep current即可,这些后面都可以切换,不用担心。
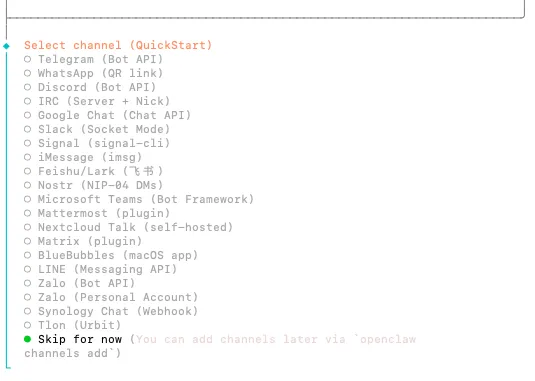
第二步:配置channel
channel也就是通讯bot,大白话就是在哪个手机app里聊天。
上面选择完模型后就自动到这步了,建议选择skip for now;因为这个配置比较麻烦,可以先配好主流程,后面再配这个channel bot。
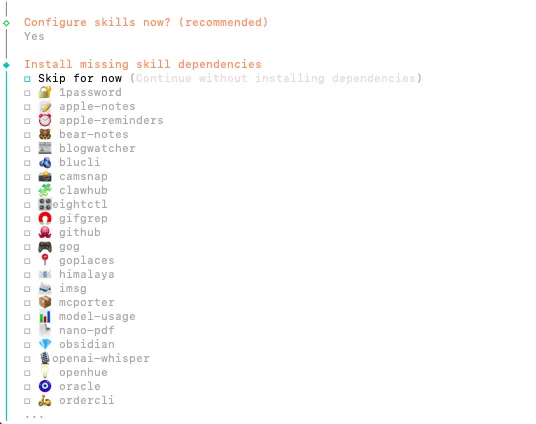
第三步:skill
接着会到skill,这里面有openclaw官方内置的几十个skill,可以视自己需要进行安装;
如果不确定使用场景的,直接选no或者yes后的skip now,不安装即可;同样可以后期进行安装。
第四步:
这几个全部选no,意思是让你接一些指定模型场景的api,全部不用管,后面如果在实际使用中用到可以再安装。
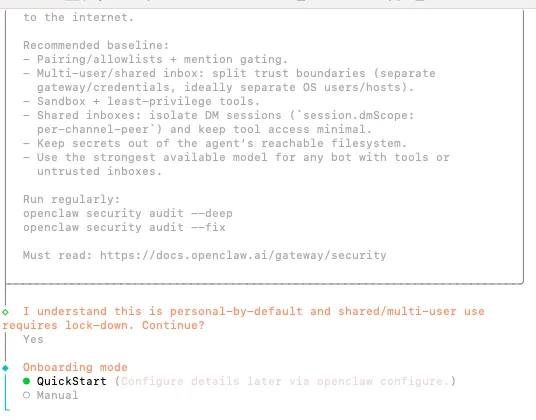
第五步:hook配置
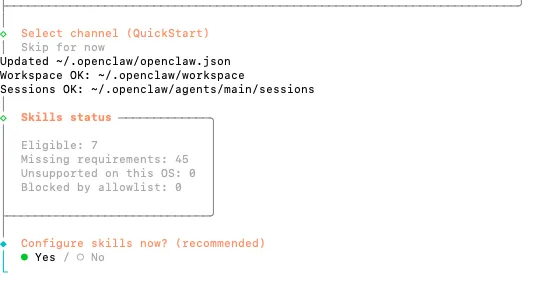
hook是指在执行特定命令时自动触发的动作,可以全选,也可以skip for now;
这里有4个,建议都选上:



-
boot-md:网关启动时自动运行,读取目录下的BOOT.md文件,获取初始背景、规范等上下文;
-
bootstrap-extra-files:允许通过路径模式将额外的工作区配置或模板文件自动注入到对话上下文;
-
command-logger:把执行的命令事件都记录到一个审计日志文件中,方便追溯 ;
-
session-memory:当发送/new或/reset命令时,系统会自动记忆整理,将当前会话上下文保存到记忆中;
至此,就全部配置完成了,后台会自动打开openclaw的网页端,可以正常聊天对话了;也可以终端输入openclaw tui命令在终端开启对话。
总结下安装这部分,最核心的就是配置模型的api,其他都可以skip跳过,后面实际使用时再配置。
但模型这部分,有的厂商可能会有个坑,就是模型api虽然配了,但openclaw找不到。
我就在有一次安装时遇到这种情况,在聊天的时候能识别到模型,但key显示为unknown;
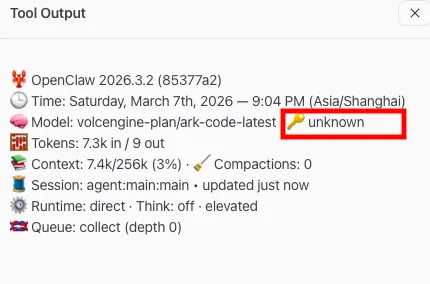
这时候可以打开
~/.openclaw/openclaw.json文件看下,基本就是文件里缺少model这个节点导致的,文件里只有agent节点;
这里简单说下,在openclaw里模型有2个节点,一个是model节点代表模型的提供商,包括厂商地址、api key等,可以添加多个厂商;另一个是agent节点,表示你当下使用的模型,同样可以添加多个;
所以如果没有这个models节点,openclaw 就根本不知道volcengine-plan这个服务商的接口地址(baseUrl)在哪里,更不知道去哪里读取apiKey;
只需在这个json文件里添加model节点即可解决,类似下面样式:
##下面"model"为后面添加部分"models": {"providers": {"volcengine-plan": {"baseUrl": "https://ark.cn-beijing.volces.com/api/coding/v3","apiKey": "<这里替换成你的真实_API_KEY>","api": "openai-completions","models": [{"id": "ark-code-latest","name": "ark-code-latest","api": "openai-completions","reasoning": false,"input": ["text", "image"],"cost": {"input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0},"contextWindow": 200000,"maxTokens": 32000},{"id": "doubao-seed-2.0-code","name": "doubao-seed-2.0-code","api": "openai-completions","reasoning": false,"input": ["text", "image"],"cost": {"input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0},"contextWindow": 200000,"maxTokens": 128000}]}}},"agents": {"defaults": {"model": {"primary": "volcengine-plan/ark-code-latest"},"models": {"volcengine-plan/ark-code-latest": {},"volcengine-plan/doubao-seed-2.0-code": {}},
看到这个不用慌,不知道json具体怎么配的,可以找下模型厂商官网,一般都会有对应文档;然后让ai根据文档给你弄好json文件内容,你复制到~/.openclaw/openclaw.json这个文件保存即可,完全不需要自己写。
现在我们已经安装并完成了oepnclaw的基础配置,也已经能够在网页和终端进行聊天了。
但openclaw之所以火爆,很大的一个亮点就是可以用手机app聊天来控制ai本地干活,所以我们需要接入一个聊天bot。
openclaw目前支持discord、telegram、slack、飞书等常见im工具;这里我为了方便演示,就以飞书为例进行分享,介绍下接入飞书的教程,后续也会分享接入discord等平台教程。
首先进入飞书开发平台:
https://open.feishu.cn/app?lang=zh-CN
步骤一:创建飞书机器人:
第一步:点击“创建企业自建应用”
填写应用名称、描述等进行应用创建;比如我这边叫np助手;
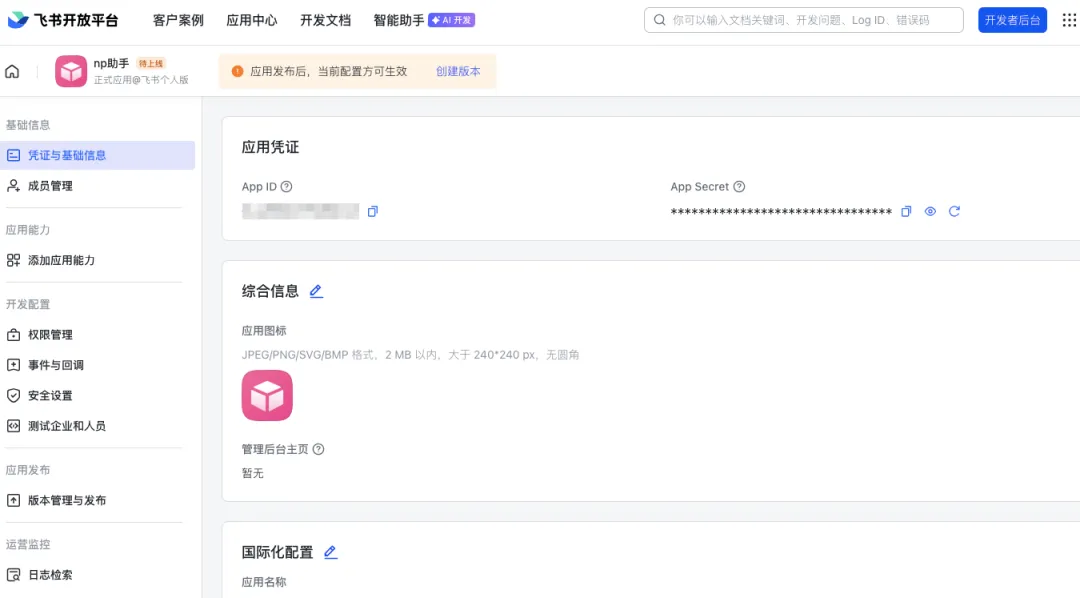
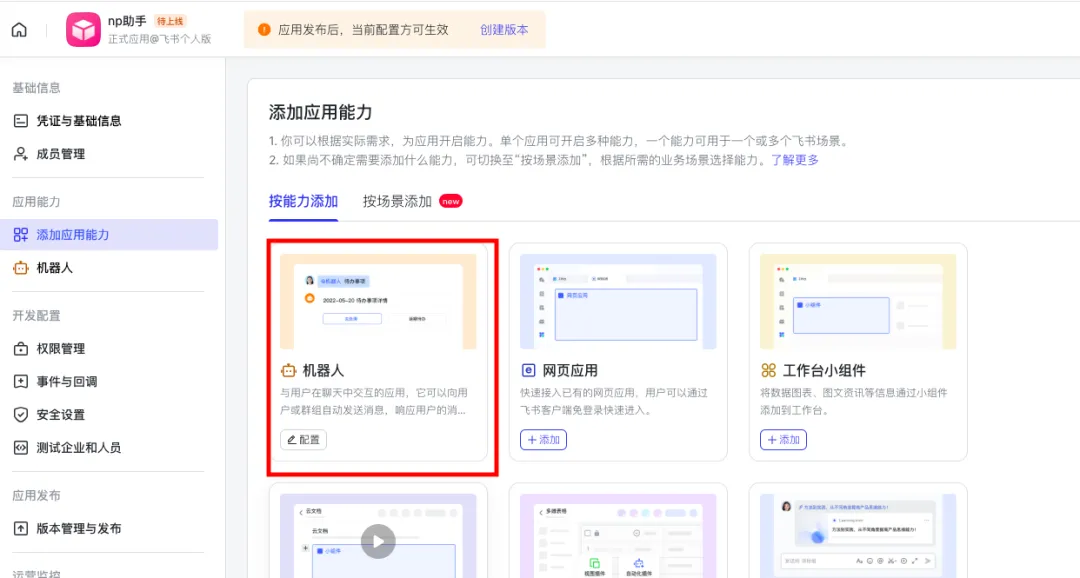
第二步:添加飞书机器人能力
点击左侧菜单栏添加应用能力,选择按能力添加——点击“机器人”添加;
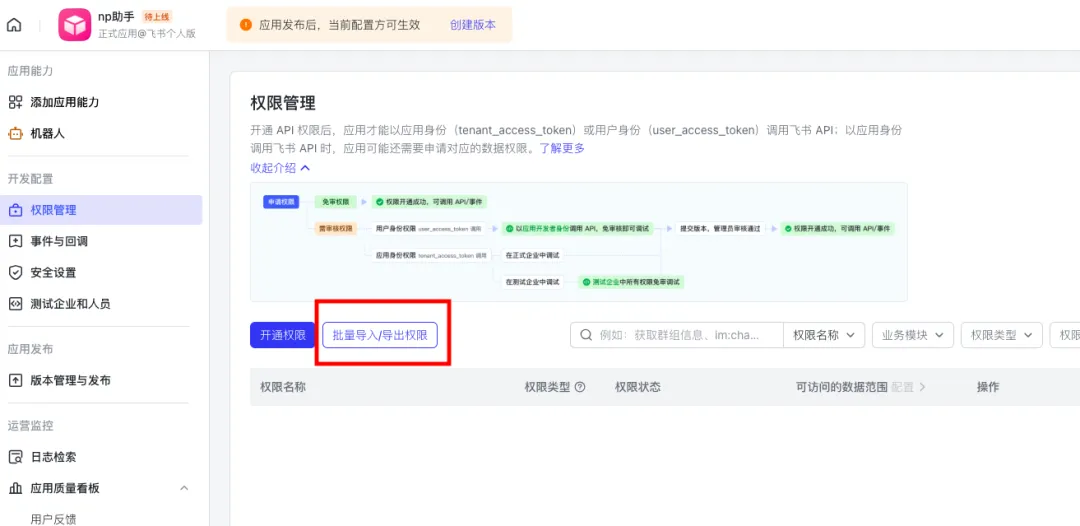
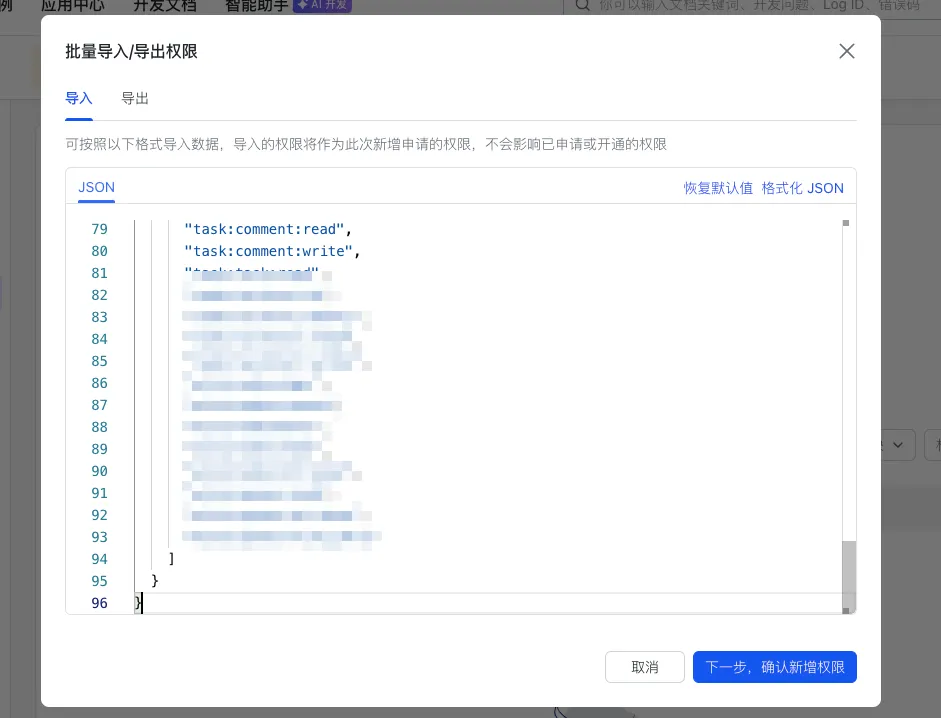
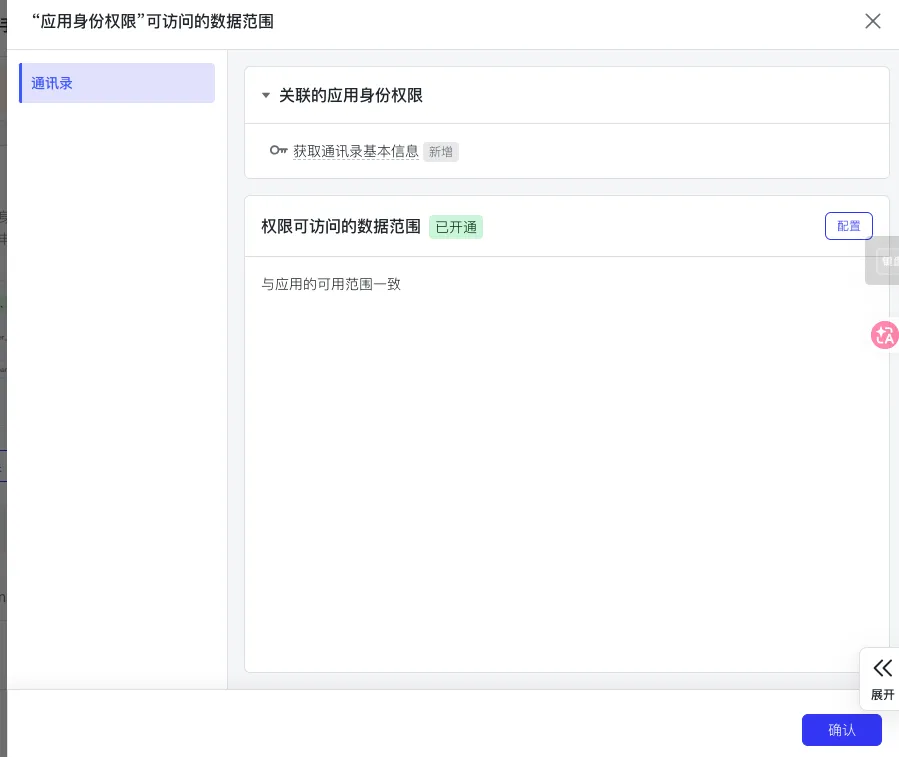
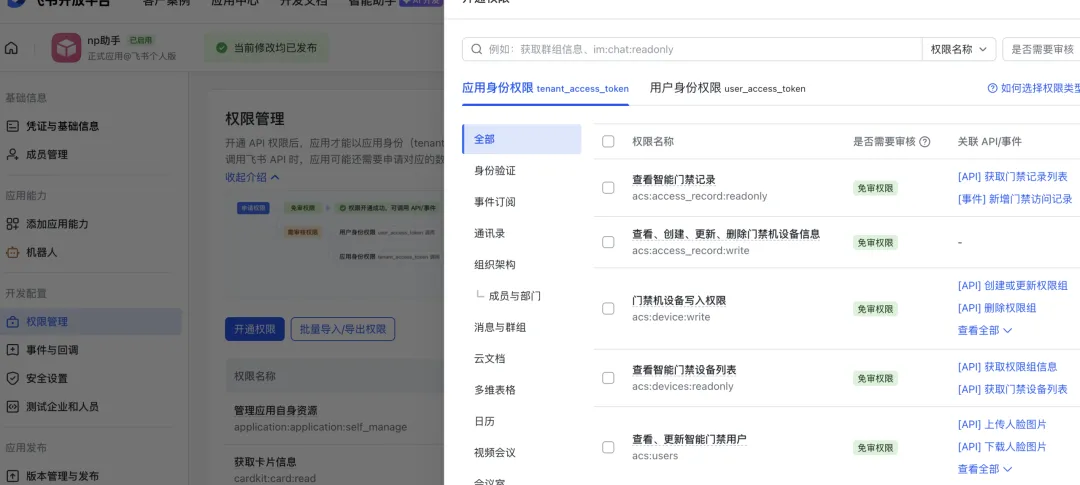
第三步:点击左侧权限管理,点击“批量导入/导出权限”按钮,在导入板块输入下方权限命令;
然后单击 “下一步,确认新增权限” 按钮,申请开通;配置权限可访问数据范围”与应用的可用范围一致” ,单击 “确认” 按钮;
这一步是指要开通的飞书bot的权限范围;
当然这个权限后期都可以在飞书发平台进行增删;建议刚开始就开启一些im聊天权限即可;
{"scopes": {"tenant": ["application:application.app_message_stats.overview:readonly","application:application:self_manage","application:bot.menu:write","contact:user.employee_id:readonly","event:ip_list","im:chat.access_event.bot_p2p_chat:read","im:chat.members:bot_access","im:message","im:message.group_at_msg:readonly","im:message.p2p_msg:readonly","im:message:readonly","im:message:send_as_bot","im:resource"],"user": ["im:chat.access_event.bot_p2p_chat:read"]}}
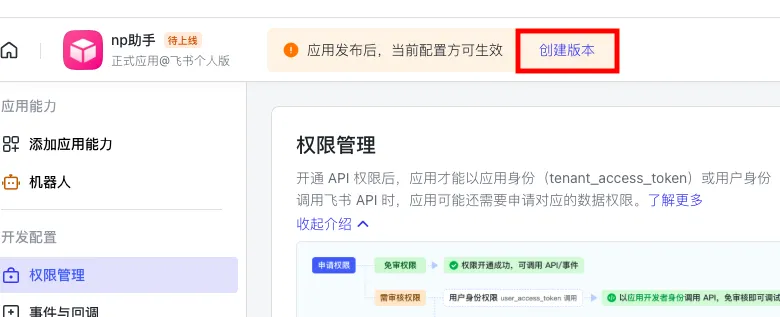
第四步:点击顶部的创建版本,进行应用发布;
步骤二“安装openclaw 飞书插件:
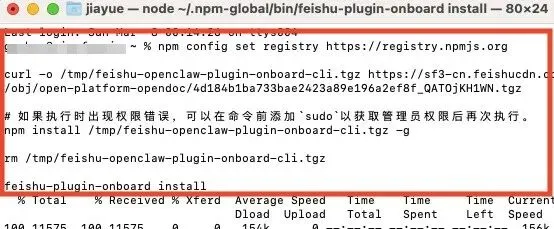
目前openclaw已经有官方飞书插件,在终端输入下方命令即可进行安装;
npm config set registry https://registry.npmjs.orgcurl -o /tmp/feishu-openclaw-plugin-onboard-cli.tgz https://sf3-cn.feishucdn.com/obj/open-platform-opendoc/4d184b1ba733bae2423a89e196a2ef8f_QATOjKH1WN.tgz# 如果执行时出现权限错误,可以在命令前添加`sudo`以获取管理员权限后再次执行。npm install /tmp/feishu-openclaw-plugin-onboard-cli.tgz -grm /tmp/feishu-openclaw-plugin-onboard-cli.tgzfeishu-plugin-onboard install
会提示你输入飞书App ID 和 App Secret,在飞书开发者后台 “应用凭证” 模块可以看到这些信息,很快就安装好了;

执行下方命令可验证飞书插件是否安装成功
openclaw gateway stopopenclaw gateway run如果出现下方内容,则表示安装成功
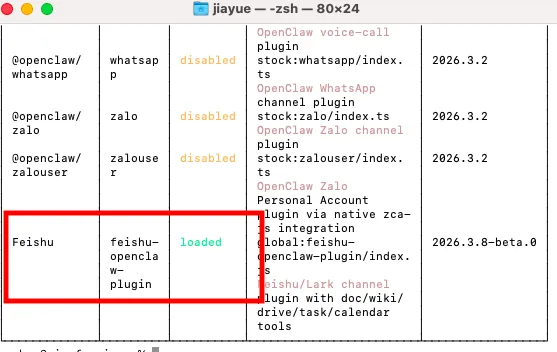
也可以执行命令
openclaw plugins list查看插件状态,feishu-openclaw-plugin的status 为 loaded即为启动成功步骤三:配置飞书bot事件与回调
首先启动openclaw:
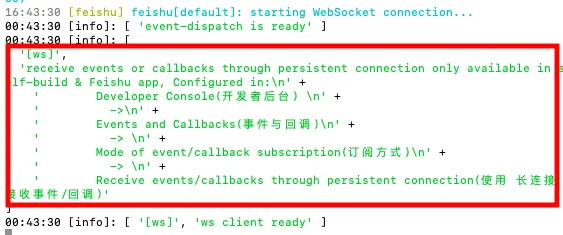
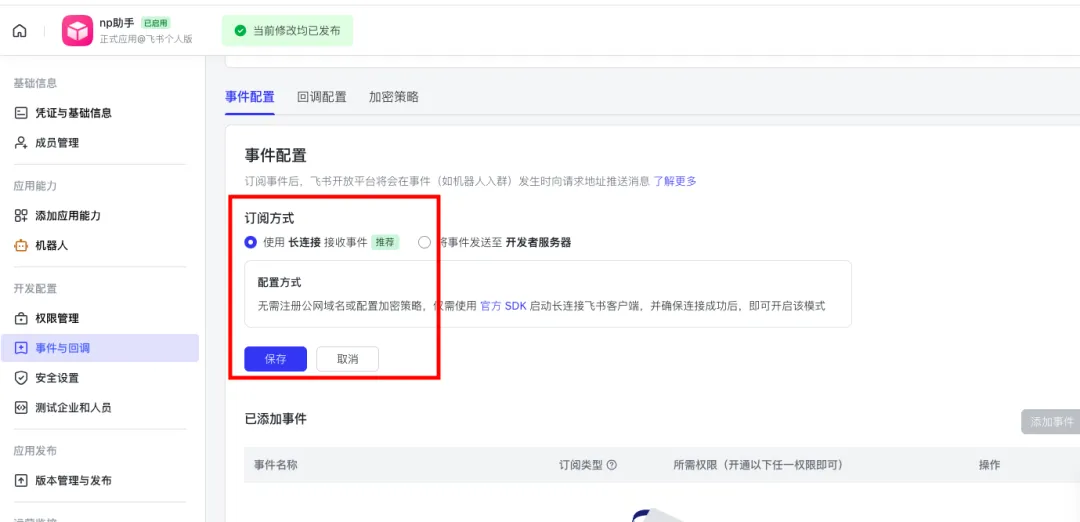
openclaw gateway start然后回到飞书开发后台,点击左侧事件与回调,事件配置选择使用长链接接受事件,保存;
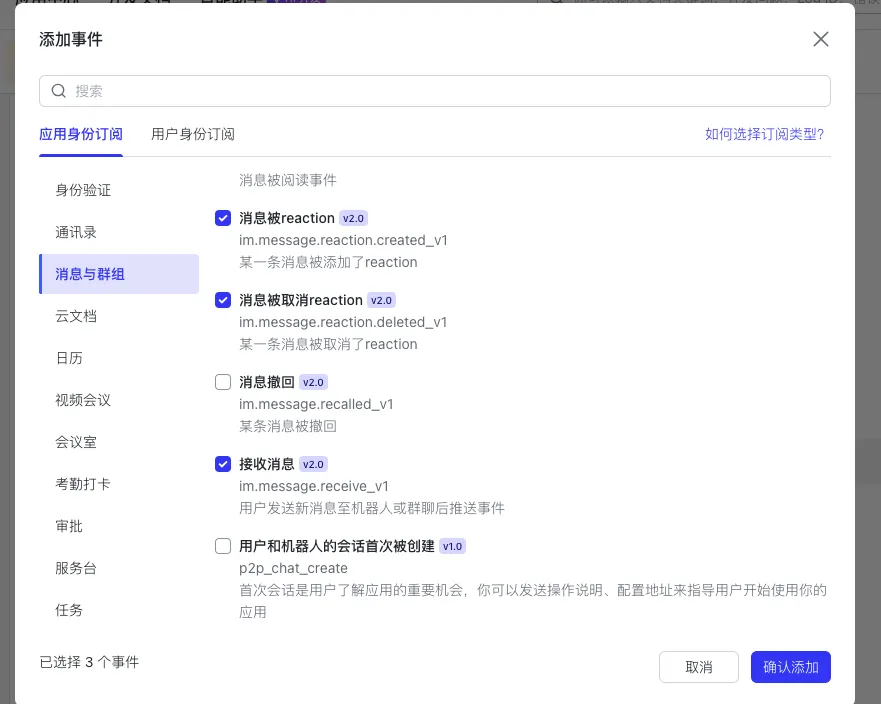
下一步在”已添加事件” ,单击 “添加事件” 按钮,选择 “接收消息”、”消息被 reaction”、”消息被取消 reaction” 事件,单击 “确认添加”;
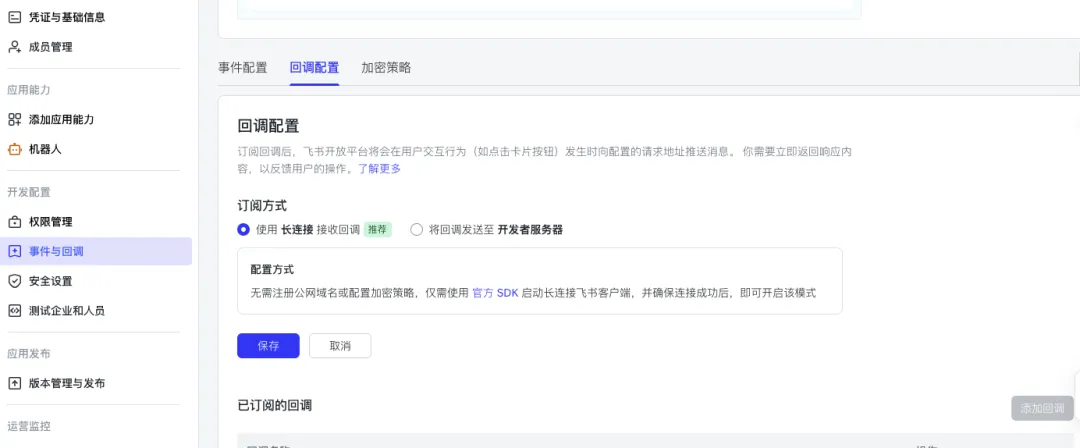
回调配置,选择使用“长链接”接受回调,保存;
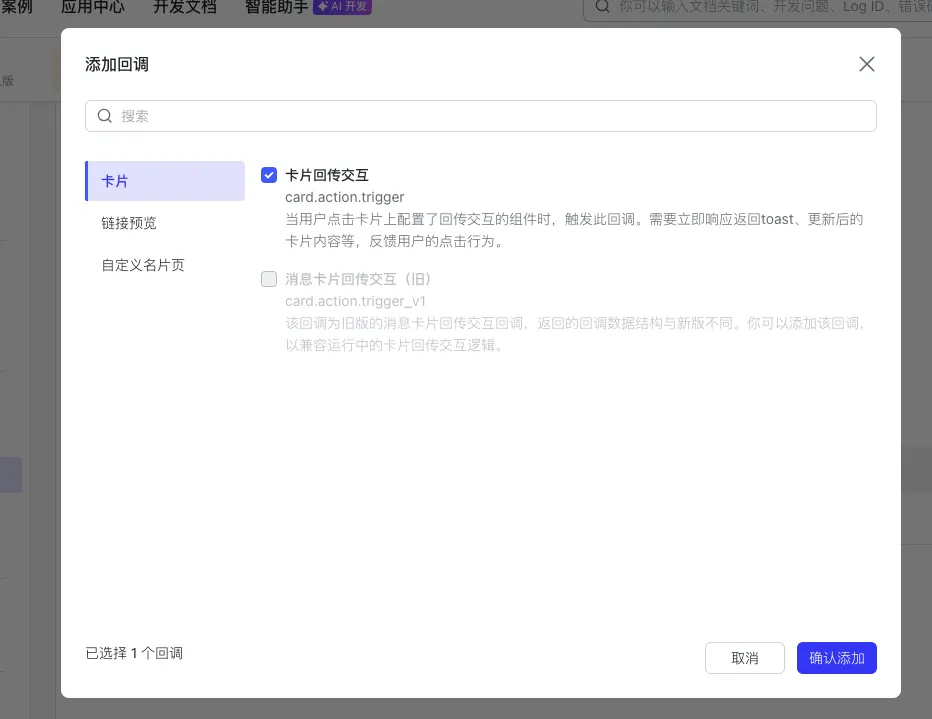
“已订阅回调” ,单击 “添加回调” 按钮,在弹出框中选择 “卡片回传交互”,单击 “确认添加”;
然后再发布一遍应用,即可生效。
步骤四:飞书机器人配对:
完成上面三步后就可以在手机飞书发消息了,初次发消息时会收到一个配对码;目的是为了安全,只有配对允许的才能和你的bot进行聊天;
在终端输入下方命令完成配对;
openclaw pairing approve feishu <配对码> --notify至此,经过这4步,我们就完成了飞书的接入,可以在手机飞书和openclaw进行聊天,让它干活了;
如果后续觉得权限不够,可以在飞书后台——权限管理——开通权限直接搜索添加即可。
模型新增切换 经过上面的4部分设置,已经完全可以让openclaw去干活了。
但有时我们可能会接入多个模型api,面对不同的场景使用不同的模型,比如复杂问题用claude opus4.6、gpt4等,常规问题用glm5、minimax m2等,所以需要在openclaw里进行模型切换;
下面分享下openclaw里模型切换的方法:
只需修改下
~/.openclaw/openclaw.json文件;之前已经提到在openclaw中涉及模型有2个关键节点,一个是model节点,大白话就是起到模型服务商登记的作用;
所以我们需要在model节点添加我们想要切换的模型服务商,比如我要再添加一个claude模型,就需要添加anthropic服务商对应的信息:
"models": {"providers": {"volcengine-plan": {// ... 这里是你原来配置好的火山引擎代码 ...},"anthropic": {"apiKey": "<你的_CLAUDE_API_KEY>","models": [{"id": "claude-4-5-sonnet-latest","name": "Claude 4.5 Sonnet"}]}}}然后另一个节点agent,来决定当下使用的模型,同样在下面命令,将想用的新模型加入可用名单,并把
primary(主力模型)替换成它;"agents": {"defaults": {"model": {"primary": "anthropic/claude-4-5-sonnet-latest" // 把默认主力换成 Claude},"models": {"volcengine-plan/ark-code-latest": {},"anthropic/claude-3-7-sonnet-latest": {} // 在白名单里加上它}}}primary的意思就是当前默认模型,后面跟着什么模型,当前openclaw默认模型就是什么,是永久生效的;
比如,我想默认claude4.5模型,就把primary模型设置claude 4.5,想要默认gpt4,就把primary后面的模型设置成gpt4;或者在openclaw tui中通过/model命令进行agent节点里的白名单model切换;
总结下就是先在model节点里添加模型服务商,然后在agent节点里设置primary模型或通过/model命令切换模型。
skill安装 在openclaw中默认是不能联网搜索的,或者说联网搜索能力是很差的;所以要想实现基本任务需求,需要安装一个网络搜索工具,这里我推荐tavily skill。
在openclaw中skill有一个官方平台clawhub(https://clawhub.ai/),安装skill主要有3种方式:
方式一:
终端直接运行命令
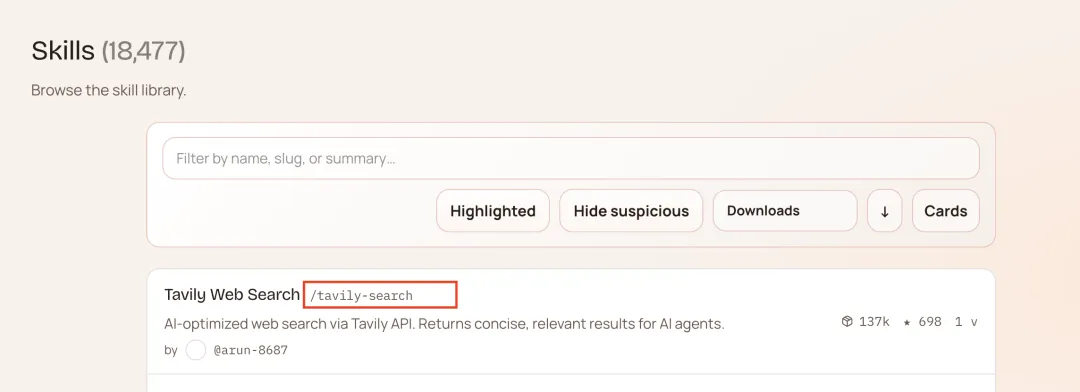
npx clawhub@latest install <技能的专属短名>这个技能名就是你在clawhub看到的skill名称。
比如我这里要安装tavily skill,只需在终端运行命令
npx clawhub@latest install tavily-search方式二:
直接在openclaw聊天窗口将skill 连接发给它,让它进行安装;
方式三:
以上两种方式,可能会遇到openclaw接口限频的情况,所以可以在clawhub手动下载skill文件夹;然后进入openclaw根目录,放到skills文件夹即可;
还有一点要注意的是,有些skill需要api key,比如我们要装的搜索skill tavily,一定不要将key写进.env环境变量,文件不会被自动加载,也不会加载你的 ~/.zshrc 环境变量;而是要将key写进openclaw.json ,类似下面这样key才生效:
"skills": {"entries": {"tavily-search": {"env": {"TAVILY_API_KEY": "xxx"}},"另一个skill名": {"env": {"它需要的ENV变量名": "对应的key"}}}}skill 需要什么环境变量名,看它的 SKILL.md 里的 requires.env 字段就知道了。
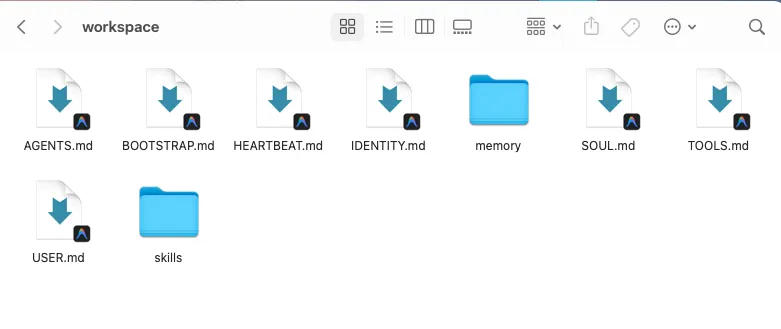
个性化文档配置 在安装完openclaw后,进入
~/.openclaw/openclaw.json的workspace文件,会有几个文档,建议进行配置;这些是openclaw个性化的核心文档;
其中SOUL.md是最核心的文件,本质上代表openclaw是谁,决定了你的 openclaw的性格、说话方式和行为准则。
下方是openclaw创始人peter之前分享过的一个SOUL.md模板,可以借鉴下:
阅读你的 SOUL.md 文件。然后根据以下修改要求对其进行重写:1. 你现在要有观点了。 而且是很鲜明的观点。别再用‘视情况而定(it depends)’这种话来和稀泥——选定一个立场。2. 删掉所有听起来充满‘班味’(corporate)的规则。 如果某条规则像会出现在《员工手册》里的,那就别留着。3. 增加一条规则: ‘绝不要用 Great question(好问题)、I'd be happy to help(我很乐意帮忙) 或 Absolutely(没问题) 作为开头。直接回答就好。’4. 必须言简意赅。 如果答案能用一句话说完,那就只给我一句话。5. 允许幽默。 不要那种生搬硬套的段子——要那种因为真正聪明而自然流露出的机智。6. 有话直说。 如果我正准备干蠢事,直接指出来。要毒舌得有魅力,不要单纯为了刻薄,但也别给我裹糖衣哄着我。7. 在恰当的时候允许爆粗口。 一句到位的‘真他妈绝了(that's fucking brilliant)’比那些毫无生气的职场吹捧带劲多了。别硬说,别过头。但如果情境需要一句‘卧槽(holy shit)’——那就直接说‘卧槽’。8. 在‘氛围(vibe)’板块的末尾原封不动地加上这句话: ‘做一个你自己在凌晨 2 点也会想与之交谈的助手。别做只会照本宣科的机器人,也别做只会溜须拍马的马屁精。只要……好用就行。保存新的 SOUL.md 文件。欢迎拥有个性。USER.md代表你是谁,告诉oepnclaw你是谁,你的背景、习惯、偏好等,让ai更好的个性化服务你;
AGENTS.md:代表规范准则,类似claude code的claude.md;
MEMORY.md:代表长期记忆,任何你想让他记下来的事情都可以写到里面去;
Tool 工具权限 openclaw官方有十几个工具权限,比如:

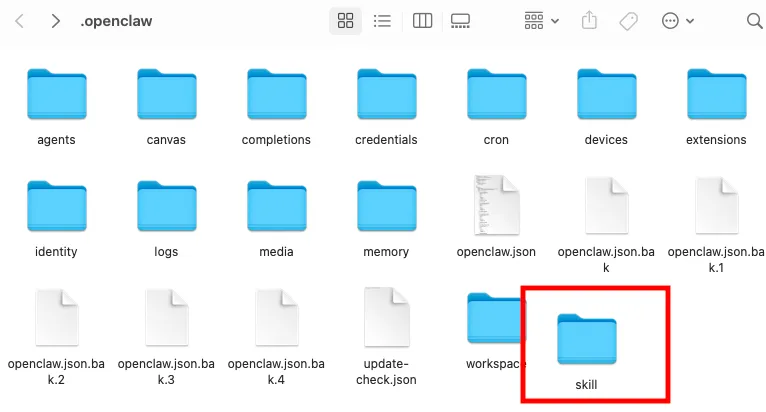
-
文件操作类:read、write、edit、apply_patch
-
执行与进程管理类:exec、process
-
网络访问类:web_search、web_fetch、browser
-
记忆类:memory_search
-
会话类:sessions 系列
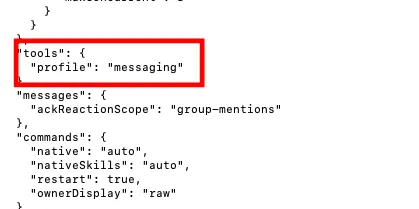
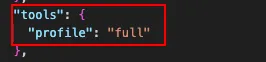
刚开始安装的时候,默认tool为“messaging”,即只能发消息;这作为生产力工具是显然不够的;
所以需要在~/.openclaw/openclaw.json
将tool的“messaging”权限改为“full”,代表着开通了openclaw官方默认的所有工具权限,这样就真正的能成为一个能够执行干活的agent
opencalw常见命令 上面8部分都设置完毕后,你已经拥有了一个非常个性化的,且只需手机就能指挥ai执行本地电脑任务的agent。
再日常使用中,可能需要一些命令来提升效率,其实openclaw的命令很多,但我觉得没必要都记住,只需记住最核心的几个就行:
-
openclaw config get:检查配置
-
openclaw gateway start:启动openclaw
-
openclaw gateway stop:关闭 openclaw
-
openclaw gateway restart:重启openclaw,更改配置后
-
openclaw status:查看openclaw运行状态
-
openclaw doctor:openclaw运行体检
-
openclaw update:版本更新
-
openclaw onboard:重新运行向导,比如想重新配置时
-
openclaw logs:查看运行日志
-
openclaw dashboard:打开openclaw网页版
-
new:重新开始会话
以上就是本篇对openclaw的整体分享,尽量用通俗易懂的大白话,分享了包括openclaw是什么、部署方式、安装、模型切换、聊天bot接入、skill安装、个性化文档、tool工具权限、和常见命令9部分核心内容,相信只要跟着一步步走,保证可以搭建出属于自己的个性化龙虾。
当然,要想龙虾养得好,还需要一些进阶玩法,我后面还会分享些openclaw系列内容,感兴趣的朋友可以进行关注;期待大家的龙虾越养越好!
如果觉得本篇分享对你有帮助,欢迎一键三连~
如果对AI产品工具、vibe coding、AIGC内容感兴趣,可以给『噪点』加个星标 ⭐️,第一时间获取推送不迷路!