


















文档内容
第84讲 成对数据的统计分析
知识梳理
知识点一、变量间的相关关系
1、变量之间的相关关系
当自变量取值一定时,因变量的取值带有一定的随机性,则这两个变量之间的关系叫相关关
系.由于相关关系的不确定性,在寻找变量之间相关关系的过程中,统计发挥着非常重要的
作用.我们可以通过收集大量的数据,在对数据进行统计分析的基础上,发现其中的规律,对
它们的关系作出判断.
注意:相关关系与函数关系是不同的,相关关系是一种非确定的关系,函数关系是一种确定的
关系,而且函数关系是一种因果关系,但相关关系不一定是因果关系,也可能是伴随关系.
2、散点图
将样本中的n个数据点(x,y)(i=1,2,⋅⋅⋅,n)描在平面直角坐标系中,所得图形叫做散点图.
i i
根据散点图中点的分布可以直观地判断两个变量之间的关系.
(1)如果散点图中的点散布在从左下角到右上角的区域内,对于两个变量的这种相关关系,我
们将它称为正相关,如图(1)所示;
(2)如果散点图中的点散布在从左上角到右下角的区域内,对于两个变量的这种相关关系,我
们将它称为负相关,如图(2)所示.
3、相关系数
若相应于变量x的取值x,变量y的观测值为y(1≤i≤n),则变量x与y的相关系数r=
i i
n n
(x-x)(y-y) xy-nxy
i i i i
i=1 = i=1 ,通常用r来衡量x与y之间的线性
n n n n
(x-x)2(y-y)2 x2-nx2 y2-ny2
i i i i
i=1 i=1 i=1 i=1
关系的强弱,r的范围为-1≤r≤1.
(1)当r>0时,表示两个变量正相关;当r<0时,表示两个变量负相关.
(2)r 越接近1,表示两个变量的线性相关性越强;r 越接近0,表示两个变量间几乎不存在
线性相关关系.当|r|=1时,所有数据点都在一条直线上.
(3)通常当r >0.75时,认为两个变量具有很强的线性相关关系.
知识点二、线性回归
1、线性回归
线性回归是研究不具备确定的函数关系的两个变量之间的关系(相关关系)的方法.
对于一组具有线性相关关系的数据(x ,y ),(x ,y ),⋯,(x ,y ),其回归方程y=bx+
1 1 2 2 n n
a的求法为
第 页 共 页
884 1043 n n
(x-x)(y-y) xy-nxy
i i i i
b= i=1 = i=1
n n
(x-x)2 x2-nx2
i i
i=
1 i=1
a=y-bx
1 n 1 n
其中,x= x,y= y,(x,y)称为样本点的中心.
n i n i
i=1 i=1
2、残差分析
对于预报变量y,通过观测得到的数据称为观测值y,通过回归方程得到的y称为预测值,观
i
测值减去预测值等于残差,e 称为相应于点(x,y)的残差,即有e =y -y.残差是随机误差
i i i i i i
的估计结果,通过对残差的分析可以判断模型刻画数据的效果以及判断原始数据中是否存在
可疑数据等,这方面工作称为残差分析.
(1)残差图
通过残差分析,残差点x,e
i i
比较均匀地落在水平的带状区域中,说明选用的模型比较
合适,其中这样的带状区域的宽度越窄,说明模型拟合精确度越高;反之,不合适.
n
(2)通过残差平方和Q=(y-y)2分析,如果残差平方和越小,则说明选用的模型的拟
i i
i=1
合效果越好;反之,不合适.
(3)相关指数
n
(y-y)2
i i
用相关指数来刻画回归的效果,其计算公式是:R2=1- i=1 .
n
(y-y)2
i
i=1
R2越接近于1,说明残差的平方和越小,也表示回归的效果越好.
知识点三、非线性回归
解答非线性拟合问题,要先根据散点图选择合适的函数类型,设出回归方程,通过换元将陌生
的非线性回归方程化归转化为我们熟悉的线性回归方程.
求出样本数据换元后的值,然后根据线性回归方程的计算方法计算变换后的线性回归方程系
数,还原后即可求出非线性回归方程,再利用回归方程进行预报预测,注意计算要细心,避免
计算错误.
1、建立非线性回归模型的基本步骤:
(1)确定研究对象,明确哪个是解释变量,哪个是预报变量;
(2)画出确定好的解释变量和预报变量的散点图,观察它们之间的关系(是否存在非线性
关系);
(3)由经验确定非线性回归方程的类型(如我们观察到数据呈非线性关系,一般选用反比
例函数、二次函数、指数函数、对数函数、幂函数模型等);
(4)通过换元,将非线性回归方程模型转化为线性回归方程模型;
(5)按照公式计算线性回归方程中的参数(如最小二乘法),得到线性回归方程;
(6)消去新元,得到非线性回归方程;
(7)得出结果后分析残差图是否有异常.若存在异常,则检查数据是否有误,或模型是否
合适等.
第 页 共 页
885 1043知识点四、独立性检验
1、分类变量和列联表
(1)分类变量:
变量的不同“值”表示个体所属的不同类别,像这样的变量称为分类变量.
(2)列联表:
①定义:列出的两个分类变量的频数表称为列联表.
②2×2列联表.
一般地,假设有两个分类变量X和Y,它们的取值分别为{x ,x }和{y ,y },其样本频
1 2 1 2
数列联表(称为2×2列联表)为
总
y y
1 2
计
a +
x a b
1
b
c +
x c d
2
d
n =
总 a b
a+b+c
计 +c +d
+d
a c
从2×2列表中,依据 与 的值可直观得出结论:两个变量是否有关系.
a+b c+d
2、等高条形图
(1)等高条形图和表格相比,更能直观地反映出两个分类变量间是否相互影响,常用等高
条形图表示列联表数据的频率特征.
a c
(2)观察等高条形图发现 与 相差很大,就判断两个分类变量之间有关系.
a+b c+d
3、独立性检验
n(ad-bc)2
计算随机变量χ2= 利用χ2的取值推断分类变量X和Y是否
(a+b)(c+d)(a+c)(b+d)
独立的方法称为χ2独立性检验.
0. 0.
α 0.10 0.05 0.001
010 005
2. 3. 6. 7. 10.
x
α
706 841 635 879 828
【解题方法总结】
常见的非线性回归模型
(1)指数函数型y=cax(a>0且a≠1,c>0)
两边取自然对数,lny=lncax ,即lny=lnc+xlna,
y=lny
令
,原方程变为y=lnc+xlna,然后按线性回归模型求出lna,lnc.
x=x
第 页 共 页
886 1043(2)对数函数型y=blnx+a
y=y
令
,原方程变为y=bx+a,然后按线性回归模型求出b,a.
x=lnx
(3)幂函数型y=axn
两边取常用对数,lgy=lgaxn ,即lgy=nlgx+lga,
y=lgy
令
,原方程变为y=nx+lga,然后按线性回归模型求出n,lga.
x=lgx
(4)二次函数型y=bx2+a
y=y
令
x=x2
,原方程变为y=bx+a,然后按线性回归模型求出b,a.
b
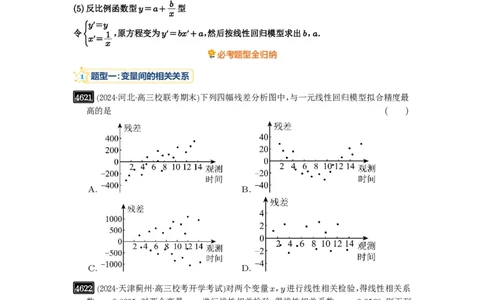
(5)反比例函数型y=a+ 型
x
y=y
令 1 ,原方程变为y=bx+a,然后按线性回归模型求出b,a.
x=
x
必考题型全归纳
1 题型一:变量间的相关关系
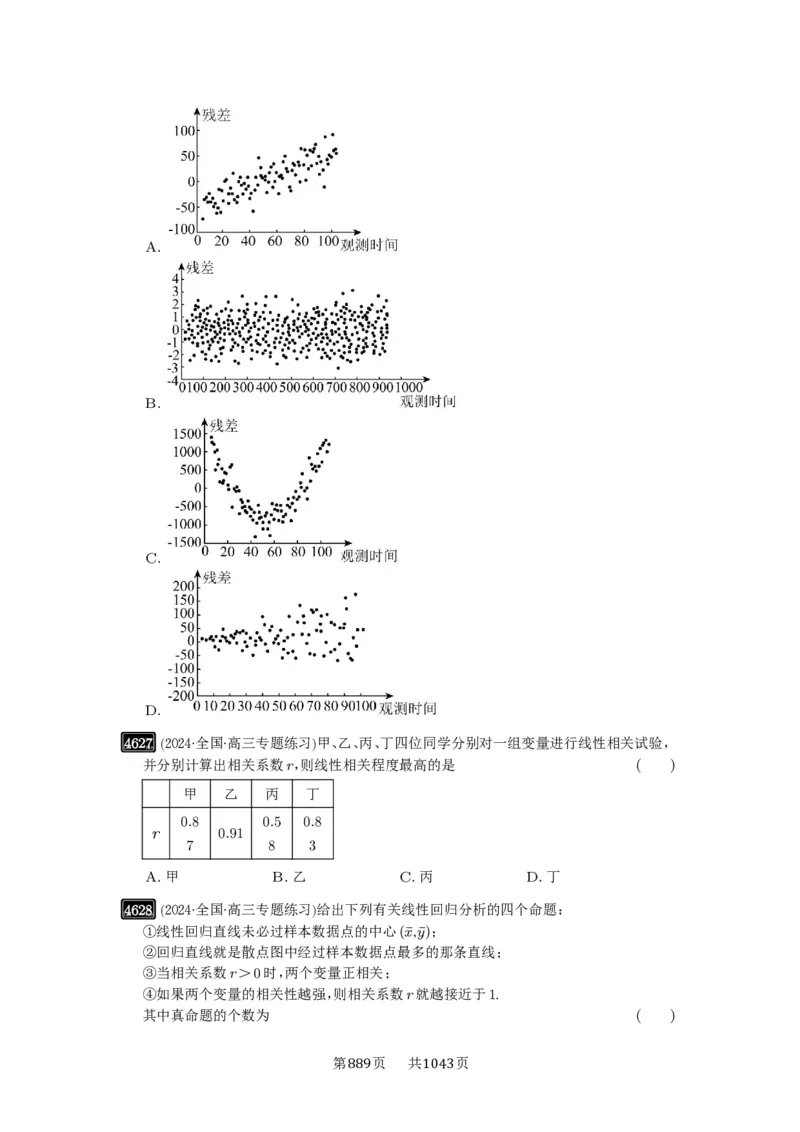
4621 (2024·河北·高三校联考期末)下列四幅残差分析图中,与一元线性回归模型拟合精度最
高的是 ( )
A. B.
C. D.
4622 (2024·天津蓟州·高三校考开学考试)对两个变量x,y进行线性相关检验,得线性相关系
数r =0.8995,对两个变量u,v进行线性相关检验,得线性相关系数r =-0.9568,则下列
1 2
判断正确的是 ( )
A.变量x与y正相关,变量u与v负相关,变量x与y的线性相关性较强
B.变量x与y负相关,变量u与v正相关,变量x与y的线性相关性较强
C.变量x与y正相关,变量u与v负相关,变量u与v的线性相关性较强
D.变量x与y负相关,变量u与v正相关,变量u与v的线性相关性较强
4623 (2024·宁夏吴忠·高三盐池高级中学校考阶段练习)在如图所示的散点图中,若去掉点
P,则下列说法正确的是 ( )
第 页 共 页
887 1043A.样本相关系数r变大 B.变量x与变量y的相关程度变弱
C.变量x与变量y呈正相关 D.变量x与变量y的相关程度变强
4624 (2024·四川成都·高三统考阶段练习)已知建筑地基沉降预测对于保证施工安全,实现信
息化监控有着重要意义.某工程师建立了四个函数模型来模拟建筑地基沉降随时间的变
化趋势,并用相关指数、误差平方和、均方根值三个指标来衡量拟合效果.相关指数越接
近1表明模型的拟合效果越好,误差平方和越小表明误差越小,均方根值越小越好.依此
判断下面指标对应的模型拟合效果最好的是 ( )
A.
相关指数 误差平方和 均方根值
0.949 8.491 0.499
B.
相关指数 误差平方和 均方根值
0.933 4.179 0.436
C.
相关指数 误差平方和 均方根值
0.997 1.701 0.141
D.
相关指数 误差平方和 均方根值
0.997 2.899 0.326
4625 (2024·高三课时练习)甲、乙、丙、丁四位同学各自对,A,B两变量的线性相关性做试
验,并用回归分析方法分别求得相关系数r与残差平方和m如下表:
甲 乙 丙 丁
0.8 0.7 0.6 0.8
r
2 8 9 5
m 106 115 124 103
则能体现A,B两变量有更强的线性相关性的是 ( )
A.甲 B.乙 C.丙 D.丁
4626 (2024·河北石家庄·统考三模)观察下列四幅残差图,满足一元线性回归模型中对随机误
差的假定的是 ( )
第 页 共 页
888 1043A.
B.
C.
D.
4627 (2024·全国·高三专题练习)甲、乙、丙、丁四位同学分别对一组变量进行线性相关试验,
并分别计算出相关系数r,则线性相关程度最高的是 ( )
甲 乙 丙 丁
0.8 0.5 0.8
r 0.91
7 8 3
A.甲 B.乙 C.丙 D.丁
4628 (2024·全国·高三专题练习)给出下列有关线性回归分析的四个命题:
①线性回归直线未必过样本数据点的中心(x,y);
②回归直线就是散点图中经过样本数据点最多的那条直线;
③当相关系数r>0时,两个变量正相关;
④如果两个变量的相关性越强,则相关系数r就越接近于1.
其中真命题的个数为 ( )
第 页 共 页
889 1043A.1 B.2 C.3 D.4
2 题型二:一元线性回归模型
4629 (2024·天津蓟州·高三校考开学考试)为研究某种细菌在特定环境下,随时间变化的繁殖
情况,得到如下实验数据:
天数x(天) 3 4 5 6
繁殖个数y(千个) 3 4
2.5 4.5
由最小二乘法得y与x的线性回归方程为y=0.7x+a,则当x=7时,繁殖个数y的预测
值为 ( )
A.4.9 B.5.25 C.5.95 D.6.15
4630 (2024·湖南长沙·高三长郡中学校联考阶段练习)某社区为了丰富退休人员的业余文化
生活,自2018年以来,始终坚持开展“悦读小屋读书活动”.下表是对2018年以来近5年该
社区退休人员的年人均借阅量的数据统计:
年份 2018 2019 2020 2021 2022
年份代码x 1 2 3 4 5
年人均借阅量y(册) y y 16 22 28
1 2
5
(参考数据:y =90)通过分析散点图的特征后,年人均借阅量y关于年份代码x的回归
i
i=1
分析模型为y=5x+m,则2024年的年人均借阅量约为 ( )
A.31 B.32 C.33 D.34
4631 (2024·辽宁·辽宁实验中学校考模拟预测)已知x,y的对应值如下表所示:
x 0 2 4 6 8
m 2m 3m+
y 1 11
+1 +1 3
若y与x线性相关,且回归直线方程为y=1.6x+0.6,则m= ( )
A.2 B.3 C.4 D.5
4632 (2024·广西南宁·南宁二中校联考模拟预测)某单位在当地定点帮扶某村种植一种草莓,
并把这种原本露天种植的草莓搬到了大棚里,获得了很好的经济效益.根据资料显示,产
出的草莓的箱数x(单位:箱)与成本y(单位:千元)的关系如下:
x 10 20 30 40 60 80
y y y y y y y
1 2 3 4 5 6
(1)根据散点图可以认为x与y之间存在线性相关关系,请用最小二乘法求出线性回归方
程y=bx+a(a,b用分数表示)
(2)某农户种植的草莓主要以300元/箱的价格给当地大型商超供货,多余的草莓全部以
200元/箱的价格销售给当地小商贩.据统计,往年1月份当地大型商超草莓的需求量为
第 页 共 页
890 10431 1 1 1
50箱、100箱、150箱、200箱的概率分别为 , , , ,根据回归方程以及往年商超
10 5 2 5
草莓的需求情况进行预测,求今年1月份农户草莓的种植量为200箱时所获得的利润情
况.(最后结果精确到个位)
6
附: x-x
i
i=1
y-y
i
6
=790,y =54,在线性回归直线方程y=bx+a中b=
i
i=1
n
x-x
i
i=1
y-y
i
n
x-x
i
i=1
,a=y-bx.
2
4633 (2024·江西·高三统考开学考试)某新能源汽车销售部对今年1月至7月的销售量进行统
计与分析,因不慎丢失一些数据,现整理出如下统计表与一些分析数据:
月份 1月 2月 3月 4月 5月 6月 7月
月份代号x 1 2 3 4 5 6 7
37. 39. 44.
销售量y(单位:万辆) 15.6 m n s
7 6 5
其中y=31.2.
(1)若m,n,s成递增的等差数列,求从7个月的销售量中任取1个,月销售量不高于27
万辆的概率;
7
(2)若 y-y
i
i=1
2=670.48,x与y的样本相关系数r=0.99,求y关于x的线性回归方程
y=bx+a,并预测今年8月份的销售量(b精确到0.1).
n
x-x
i
附:相关系数r= i=1
y-y
i
n
x-x
i
i=1
n
2 y-y
i
i=1
,线性回归方程y=bx+a中斜率和截距的最
2
n
x-x
i
小二乘估计公式分别为b= i=1
y-y
i
n
x-x
i
i=1
,a=y-bx.
2
参考数据: 7≈2.65, 670.48≈25.89.
4634 (2024·四川成都·高三石室中学校考开学考试)已知某绿豆新品种发芽的适宜温度在
6℃~22℃之间,一农学实验室研究人员为研究温度x(℃)与绿豆新品种发芽数y(颗)之间
的关系,每组选取了成熟种子50颗,分别在对应的8℃~14℃的温度环境下进行实验,得
到如下散点图:
7 7
其中y=24,(x-x)(y -y)=70,(y-y)2=176.
i i i
i=1 i=1
第 页 共 页
891 1043(1)运用相关系数进行分析说明,是否可以用线性回归模型拟合y与x的关系?
(2)求出y关于x的线性回归方程y=bx+a,并预测在19℃的温度下,种子的发芽的颗
数.
n
(x-x)(y-y)
i i
参考公式:相关系数r= i=1 ,回归直线方程y=bx+a,其中b=
n n
(x-x)2(y-y)2
i i
i=1 i=1
n
(x-x)(y-y)
i i
i=1 ,a=y-bx.参考数据: 77≈8.77.
n
(x-x)2
i
i=1
4635 (2024·安徽亳州·蒙城第一中学校联考模拟预测)为调查某地区植被覆盖面积x(单位:公
顷)和野生动物数量y的关系,某研究小组将该地区等面积花分为400个区块,从中随机
抽取40个区块,得到样本数据x i ,y i (i=1,2,⋯,40),部分数据如下:
x ⋯ 2.7 3.6 3.2 3.9 ⋯
50. 63. 54.
y ⋯ 52.1 ⋯
6 7 3
40 40 40
经计算得:x =160,y =2400, x-x
i i i
i=1 i=1 i=1
40
2=160, x-x
i
i=1
y-y
i
=1280.
(1)利用最小二乘估计建立y关于x的线性回归方程;
(2)该小组又利用这组数据建立了x关于y的线性回归方程,并把这两条拟合直线画在同
一坐标系xOy下,横坐标x,纵坐标y的意义与植被覆盖面积x和野生动物数量y一致.
设前者与后者的斜率分别为k ,k ,比较k ,k 的大小关系,并证明.
1 2 1 2
附:y关于x的回归方程y=a+bx中,斜率和截距的最小二乘估计公式分别为:b=
n n
xy-nx⋅y xy-nxy
i i i i
i=1 ,a=y-bx,r= i=1
n x i 2-nx 2 n x i 2-nx 2
i=1 i=1
n y2-ny2 i
i=1
3 题型三:非线性回归
4636 (2024·湖南·校联考模拟预测)若需要刻画预报变量w和解释变量x的相关关系,且从已
知数据中知道预报变量w随着解释变量x的增大而减小,并且随着解释变量x的增大,预
报变量w大致趋于一个确定的值,为拟合w和x之间的关系,应使用以下回归方程中的
(b>0,e为自然对数的底数) ( )
A.w=bx+a B.w=-blnx+a C.w=-b x+a D.w=be-x+a
4637 (2024·全国·高三专题练习)云计算是信息技术发展的集中体现,近年来,我国云计算市
场规模持续增长.已知某科技公司2018年至2022年云计算市场规模数据,且市场规模y
与年份代码x的关系可以用模型y=cec2x(其中e为自然对数的底数)拟合,设z=lny,得
1
到数据统计表如下:
年份 2018年 2019年 2020年 2021年 2022年
年份代码x 1 2 3 4 5
第 页 共 页
892 1043云计算市场规模y/千万
7.4 11 20 36.6 66.7
元
z=lny 2 2.4 3 3.6 4
由上表可得经验回归方程z=0.52x+a,则2025年该科技公司云计算市场规模y的估计
值为 ( )
A.e5.08 B.e5.6 C.e6.12 D.e6.5
4638 (多选题)(2024·福建厦门·厦门一中校考三模)在对具有相关关系的两个变量进行回归
分析时,若两个变量不呈线性相关关系,可以建立含两个待定参数的非线性模型,并引入
中间变量将其转化为线性关系,再利用最小二乘法进行线性回归分析.下列选项为四个同
学根据自己所得数据的散点图建立的非线性模型,且散点图的样本点均位于第一象限,则
其中可以根据上述方法进行回归分析的模型有 ( )
x+c
A.y=cx2+c x B.y= 1
1 2 x+c
2
C.y=c 1 +lnx+c 2 D.y=cex+c2 1
4639 (2024·全国·高三专题练习)已知变量的关系可以用模型y=kemx拟合,设z=lny,其变
换后得到一组数据如下.由上表可得线性回归方程z=3x+a,则k= ( )
x 1 2 3 4 5
z 2 4 5 10 14
A.e-3 B.e-2 C.e2 D.e3
4640 (2024·全国·高三专题练习)某校课外学习小组研究某作物种子的发芽率y和温度x(单
位:°C)的关系,由实验数据得到如图所示的散点图.由此散点图判断,最适宜作为发芽
率y和温度x的回归方程类型的是 ( )
A.y=a+bx B.y=a+bx2 b>0
C.y=a+bex D.y=a+blnx
4641 (2024·全国·高二专题练习)兰溪杨梅从5月15日起开始陆续上市,据调查统计,得到杨
梅销售价格(单位:Q元/千克)与上市时间t(单位:天)的数据如下表所示:
时间t/(单位:天) 10 20 70
销售价格Q(单位:元/千克) 100 50 100
根据上表数据,从下列函数模型中选取一个描述杨梅销售价格Q与上市时间t的变化关
系:Q=at+b,Q=at2+bt+c,Q=a⋅bt,Q=a⋅logt.利用你选取的函数模型,在以下四
b
个日期中,杨梅销售价格最低的日期为 ( )
第 页 共 页
893 1043A.6月5日 B.6月15日 C.6月25日 D.7月5日
4642 (2024·四川泸州·高三四川省泸县第四中学校考开学考试)抗体药物的研发是生物技术
制药领域的一个重要组成部分,抗体药物的摄入量与体内抗体数量的关系成为研究抗体
药物的一个重要方面.某研究团队收集了10组抗体药物的摄入量与体内抗体数量的数
据,并对这些数据作了初步处理,得到了如图所示的散点图及一些统计量的值,抗体药物
摄入量为x(单位:mg),体内抗体数量为y(单位:AU/mL).
10 10 10 10
tz t z t2
i i i i i
i=1 i=1 i=1 i=1
29.2 12 16 34.4
(1)根据经验,我们选择y=cxd作为体内抗体数量y关于抗体药物摄入量x的回归方程,
将y=cxd两边取对数,得lny=lnc+dlnx,可以看出lnx与lny具有线性相关关系,试根
据参考数据建立y关于x的回归方程,并预测抗体药物摄入量为25mg时,体内抗体数量
y的值;
(2)经技术改造后,该抗体药物的有效率z大幅提高,经试验统计得z服从正态分布N∼
0.48,0.032 ,那这种抗体药物的有效率z超过0.54的概率约为多少?
附:①对于一组数据u i ,v i i=1,2,⋯,10
,其回归直线v=βu+a的斜率和截距的最小
n
uv-nuv
i i
二乘估计分别为β= i=1 ,a=v-βu;
n
u2-nu2
i
i=1
②若随机变量Z~Nμ,σ2 ,则有P(μ-σ0,c ≠0)哪一个适宜作为繁殖个数y关于天数x
1 1 2 1 2
变化的回归方程类型?(给出判断即可,不必说明理由)
(2)对于非线性回归方程y =c ec 2x(c ,c 为常数,且c >0,c ≠0),令z=lny,可以得到繁
1 1 2 1 2
殖个数的对数z关于天数x具有线性关系及一些统计量的值.
6 x y z x -x i
i=1
6
x -x 2 i i=1
y -y
i
6
x -x i i=1
z -z
i
3.5 62.8 3.5
17.50 596.57 12.09
0 3 3
(ⅰ)证明:“对于非线性回归方程y =c ec 2x,令z=lny,可以得到繁殖个数的对数z关于天
1
数x具有线性关系(即z=βx+α,β,α为常数)”;
(ⅱ)根据(ⅰ)的判断结果及表中数据,建立y关于x的回归方程(系数保留2位小数).
附:对于一组数据u 1 ,v 1 ,u 2 ,v 2 ,⋯,u n ,v n
,其回归直线方程v=βu+α的斜率和截距
n
u-u
i
的最小二乘估计分别为β= i=1
v-v
i
n
u-u
i
i=1
,α=v-βu.
2
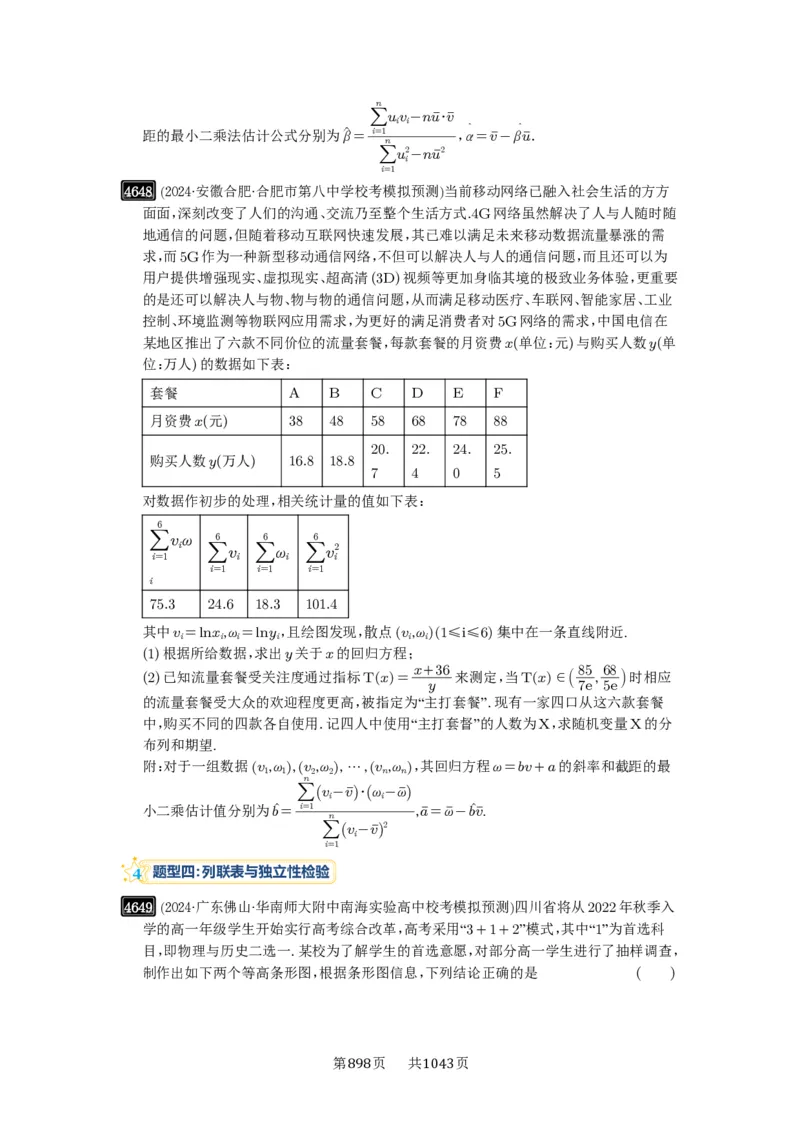
4644 (2024·重庆沙坪坝·高三重庆八中校考阶段练习)在正常生产条件下,根据经验,可以认
为化肥的有效利用率近似服从正态分布N(0.54,0.022),而化肥施肥量因农作物的种类不
同每亩也存在差异.
(1)假设生产条件正常,记X表示化肥的有效利用率,求P(X≥0.56);
(2)课题组为研究每亩化肥施用量与某农作物亩产量之间的关系,收集了10组数据,并对
这些数据作了初步处理,得到了如图所示的散点图及一些统计量的值.其中每亩化肥施用
量为x(单位:公斤),粮食亩产量为y(单位:百公斤)
参考数据:
10 10
xy 10 10 10 tz 10 10 10
i x y x2 i t z t2
i=1 i i i i=1 i i i
i=1 i=1 i=1 i=1 i=1 i=1
i i
650 91.5 52.5 1478.6 30.5 15 15 46.5
t =lnx,zi=lny(i=1,2,⋯,10).
i i i
(i)根据散点图判断,y=a+bx与y=cxd,哪一个适宜作为该农作物亩产量y关于每亩
化肥施用量x的回归方程(给出判断即可,不必说明理由);
(ii)根据(i)的判断结果及表中数据,建立y关于x的回归方程;并预测每亩化肥施用量为
第 页 共 页
895 104327公斤时,粮食亩产量y的值.(e≈2.7)
附:①对于一组数据(u,v)(i=1,2,3,⋯,n),其回归直线v=βu+α的斜率和截距的最
i i
n
uv-nuv
i i
小二乘估计分别为β= i=1 ,α=v-βu;
n
u2-nu2
i
i=1
②若随机变量X∼N(μ,σ2),则P(μ-σ0.75,则线性相关程度较高),下列说法不
正确的有 ( )
A.变量x与y正相关且相关性较强 B.b=1.9
第 页 共 页
904 1043C.当x=20时,y的估计值为40.3 D.相应于点5,11 的残差为0.8
4663 (2024·山东青岛·高三山东省青岛第五十八中学校考开学考试)已知一组样本数据
x 1 ,y 1 ,x 2 ,y 2 ,,x n ,y n ,根据这组数据的散点图分析x与y之间的线性相关关系,若求
得其线性回归方程为y=-30.4+13.5x,则在样本点9,53 处的残差为 ( )
A.38.1 B.22.6 C.-38.1 D.91.1
4664 (2024·陕西咸阳·统考模拟预测)2020年初,新型冠状病毒(COVID-19)引起的肺炎疫
情爆发以来,各地医疗机构采取了各种针对性的治疗方法,取得了不错的成效,某医疗机
构开始使用中西医结合方法后,每周治愈的患者人数如下表所示:
第x周 1 2 3 4 5
治愈人数y(单位:十人) 2 9 10 13 16
由上表可得y关于x的线性回归方程为y=bx+1,若第6周实际治愈人数为18人,则此
回归模型第6周的残差(实际值减去预报值)为 ( )
A.-1 B.0 C.1 D.2
4665 (2024·云南昆明·高三昆明一中校考阶段练习)小王经营了一家小型餐馆,自去年疫情管
控宣布结束后的第1天开始,经营状况逐步有了好转,该店第一周的营业收入数据(单位:
百元)统计如下:
天数序号x 1 2 3 4 5 6 7
营业收入y 11 13 18 ※ 28 ※ 35
其中第4天和第6天的数据由于某种原因造成模糊,但知道7天的营业收入平均值是23,
已知营业收入y与天数序号x可以用经验回归直线方程y=bx+a拟合,且第7天的残差
是-0.6,则a+b的值是 ( )
A.10.4 B.6.2 C.4.2 D.2
4666 (2024·全国·高三专题练习)已知建筑地基沉降预测对于保证施工安全,实现信息化监控
有着重要意义.某工程师建立了四个函数模型来模拟建筑地基沉降随时间的变化趋势,
并用相关指数、误差平方和、均方根值三个指标来衡量拟合效果.相关指数越接近1表明
模型的拟合效果越好,误差平方和越小表明误差越小,均方根值越小越好.依此判断下面
指标对应的模型拟合效果最好的是( ).
A.
相关指数 误差平方和 均方根值
0.949 5.491 0.499
B.
相关指数 误差平方和 均方根值
0.933 4.179 0.436
C.
相关指数 误差平方和 均方根值
0.997 1.701 0.141
第 页 共 页
905 1043D.
相关指数 误差平方和 均方根值
0.997 2.899 0.326
4667 (多选题)(2024·湖北·荆门市龙泉中学校联考模拟预测)某学校一同学研究温差x(°C)
与本校当天新增感冒人数y(人)的关系,该同学记录了5天的数据:
x 5 6 8 9 12
y 17 20 25 28 35
经过拟合,发现基本符合经验回归方程y=2.6x+a,则 ( )
A.样本中心点为8,25
B.a=4.2
C.x=5,残差为-0.2
D.若去掉样本点(8,25),则样本的相关系数r增大
第 页 共 页
906 1043

