 夜雨聆风
夜雨聆风





PDF解析王者降临!OpenDataLoader如何让AI与无障碍合规变得轻而易举
PDF解析王者降临!OpenDataLoader如何让AI与无障碍合规变得轻而易举
探索GitHub上的开源宝藏,为你的AI与无障碍合规需求找到完美解决方案
PDF Parser for AI-ready data. Automate PDF accessibility. Open-source.
在数字化浪潮席卷全球的今天,PDF作为信息传递的重要载体,其处理能力直接关系到AI应用的效率与无障碍合规的落地。今天,我们要向大家隆重介绍一款来自GitHub的开源神器—— OpenDataLoader PDF ,它不仅以0.90的准确率荣登PDF解析性能榜首,更开创性地将PDF无障碍自动化带入开源世界。

上图展示了OpenDataLoader的强大能力:它能够精确识别PDF中的标题、段落、表格、图片等元素,并为每个元素标注边界框和语义类型,为AI理解和无障碍处理提供结构化基础。
为什么说它是PDF解析的”王者”?
OpenDataLoader在权威基准测试中脱颖而出,成为综合表现最强的PDF解析工具。让我们通过一组数据来直观感受它的实力:
| 引擎 | 总体准确率 | 阅读顺序 | 表格提取 | 速度(秒/页) |
|---|---|---|---|---|
| opendataloader [hybrid] | 0.90 | 0.94 | 0.93 | 0.43 |
| opendataloader | 0.72 | 0.91 | 0.49 | 0.05 |
| docling | 0.86 | 0.90 | 0.89 | 0.73 |
| marker | 0.83 | 0.89 | 0.81 | 53.93 |
从表格中可以看出,OpenDataLoader在混合模式下以 0.90的综合准确率 遥遥领先,特别是在表格提取方面达到了 0.93 的惊人准确率。虽然纯本地模式速度极快(0.05秒/页),但混合模式在保持较高速度的同时大幅提升了复杂内容的处理能力。
双模并行:本地与AI的完美结合
OpenDataLoader创新性地采用 混合模式 ,将本地快速处理与AI智能分析相结合:
• 本地模式 :处理简单文档时,速度高达20页/秒,满足批量处理需求
• 混合模式 :自动识别复杂内容(表格、公式、图表、扫描件等),路由至AI后端处理,确保高准确率
这种设计让用户无需在速度和准确性之间妥协,可以根据文档特点灵活选择最适合的模式。
AI与RAG的完美拍档
对于构建AI应用和RAG(检索增强生成)系统的开发者来说,OpenDataLoader提供了前所未有的便利:
3行代码,搞定PDF解析
安装:pip install -U opendataloader-pdf
使用:
opendataloader_pdf.convert(
input_path=[“file1.pdf”, “folder/”],
output_dir=”output/”,
format=”markdown,json”
)
OpenDataLoader支持多种输出格式,满足不同场景需求:
| 格式 | 适用场景 |
|---|---|
| JSON | 结构化数据,包含边界框和语义类型 |
| Markdown | 干净的文本,适合LLM上下文和RAG分块 |
| HTML | 带样式的网页显示 |
| 带注释的PDF | 可视化调试,查看检测到的结构 |
无障碍合规:开源界的里程碑
PDF无障碍合规是许多组织面临的严峻挑战。全球各地的法规(如欧盟的EAA、美国的ADA/Section 508、韩国的数字包容法)都要求PDF文档必须具备适当的结构标签。传统的手动修复方式成本高昂(每份文档50-200美元),且难以规模化。
OpenDataLoader与PDF协会和Dual Lab(veraPDF开发者)合作,开创性地提供了 端到端的PDF无障碍自动化解决方案 :
• 布局分析 :自动检测文档结构(标题、段落、表格、列表等)
• 自动标记 :为未标记的PDF生成结构标签(2026年第二季度发布)
• PDF/UA导出 :将标记PDF转换为符合PDF/UA标准的文档(企业版功能)
• 验证支持 :使用veraPDF进行自动化合规检查
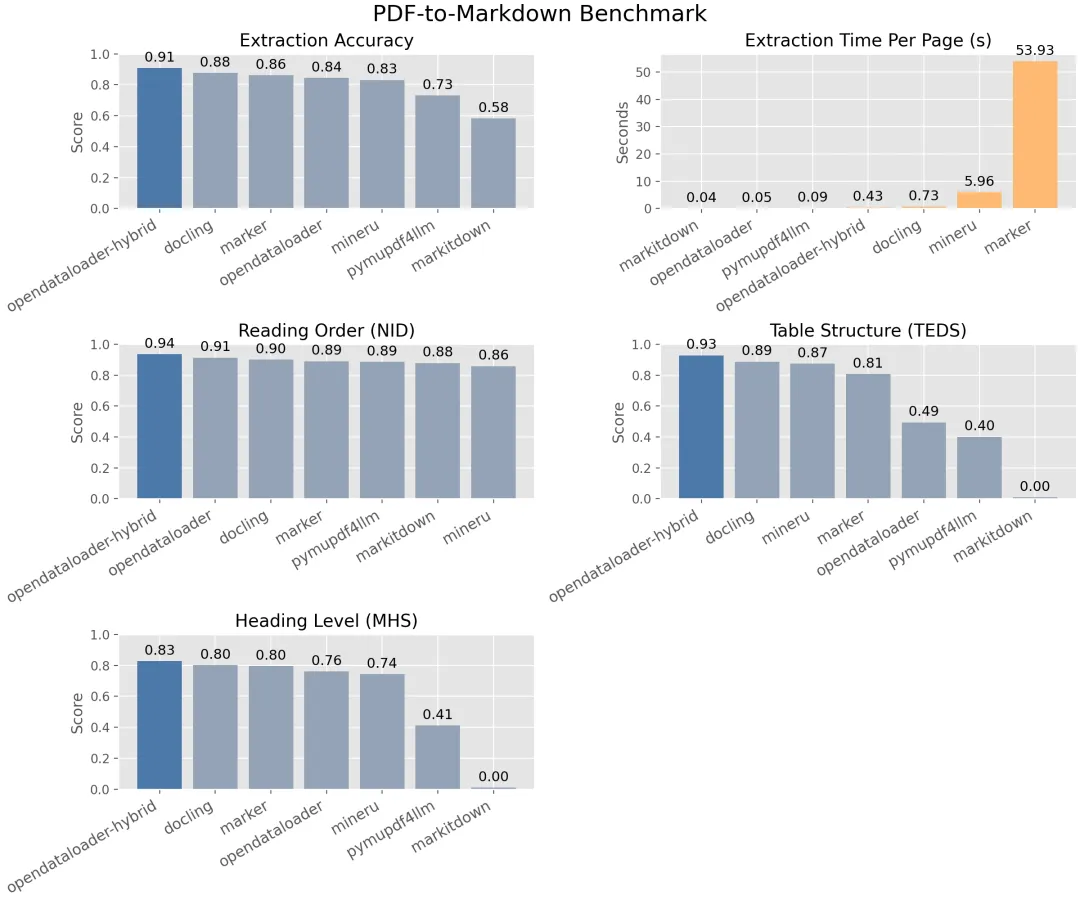
这张基准测试图表直观展示了OpenDataLoader在各种PDF解析任务中的卓越表现,特别是在复杂内容处理方面遥遥领先。
多语言支持:打破语言壁垒
OpenDataLoader对多语言PDF文档提供了强大支持:
扫描PDF处理示例
1. 安装混合模式:pip install "opendataloader-pdf[hybrid]"
2. 启动后端(带OCR):opendataloader-pdf-hybrid --port 5002 --force-ocr --ocr-lang "ko,en"
3. 处理PDF:opendataloader-pdf --hybrid docling-fast file.pdf
支持的语言包括英语、韩语、日语、简体中文、繁体中文、德语、法语、阿拉伯语等80多种语言,为全球用户提供了便利。
高级功能:满足专业需求
除了基础的文本提取,OpenDataLoader还提供了多项高级功能:
• 公式提取 :识别LaTeX格式的数学公式,适合科研文档处理
• 图表描述 :使用AI为图表生成描述文本,提升可访问性
• AI安全防护 :自动过滤提示注入攻击和隐藏文本
• 结构树支持 :尊重PDF原生结构标签,精确还原作者意图
• LangChain集成 :与主流AI框架无缝对接
企业级解决方案:从开源到专业
虽然OpenDataLoader的核心功能完全开源(Apache 2.0许可证),但还提供了企业级增强功能:
• PDF/UA导出 :生成符合国际标准的无障碍PDF
• 无障碍工作室 :可视化标签编辑器,便于精细调整
• Hancom数据加载器集成 :企业级AI文档分析(即将推出)

项目持续获得社区关注和贡献,趋势图显示了其在开源社区的活跃度和影响力。
如何开始使用?
入门OpenDataLoader非常简单,只需三步:
快速开始指南
1. 确保安装Java 11+和Python 3.10+
2. 安装库:pip install -U opendataloader-pdf
3. 开始解析:
import opendataloader_pdf
opendataloader_pdf.convert(
input_path=[“file.pdf”],
output_dir=”output/”,
format=”markdown,json”
)
对于Node.js和Java用户,OpenDataLoader也提供了完整的SDK支持,详见项目文档。
总结:为什么选择OpenDataLoader?
在众多PDF解析工具中,OpenDataLoader凭借以下独特优势脱颖而出:
• 性能之王 :0.90的综合准确率,遥遥领先于竞品
• 双模设计 :本地快速与AI智能的完美平衡
• 开源无障碍 :首个端到端开源PDF自动标记工具
• 结构完整 :为每个元素提供边界框和语义信息
• 安全可靠 :内置AI安全防护,保护数据隐私
• 多语言支持 :80+语言OCR,覆盖全球需求
• 企业级扩展 :从开源到专业,满足不同规模需求
无论你是AI开发者构建RAG系统,还是企业需要满足无障碍合规要求,OpenDataLoader都能为你提供强大、可靠、灵活的解决方案。它不仅是一个工具,更是推动文档处理智能化和无障碍化的重要力量。
立即访问GitHub项目 https://github.com/opendataloader-project/opendataloader-pdf
探索更多可能,开启你的PDF处理新篇章