夜雨聆风
夜雨聆风





从1078份PDF中看出AI的极限:深度了解 LogicsParsingBench
在文档智能技术飞速发展的今天,无论是传统pipeline OCR还是端到端大模型,AI能看图识字已经不稀奇了。但是,如果我们塞给 AI 一篇满是微积分公式的论文、一份排版花哨的小学教材、或者一页多栏交错的报纸,它真能提取准确吗?
为了准确解析模型在文档识别方面的真实实力,LogicsParsingBench测评基准应运而生。如果说之前的评测集都是基础能力测试,那LogicsParsingBench就是一场直面真实世界复杂文档的’全能挑战赛’。
相比于目前业界领先、以文档类型多样和标注丰富著称的OmniDocBench,我们提出的LogicsParsingBench更加硬核——它囊括了更多复杂的版面结构与专业科学元素,并同步对评分规则进行了升级。那么,这份特殊的“考卷”到底长什么样?为什么说它难?

LogicsParsingBench 并不是随便拿几张图片凑数,它的试题库相当考究:
-
精挑细选的考题:数据集包含1,078张精心筛选的高质量页面级PDF图像,囊括了中英文双语样本,力求还原真实世界里最复杂的文档场景。 -
涵盖九大类型:样本横跨了9大主要文档类型(包括手写笔记、书籍、文本习题册、报告、技术手册、报表、学术论文、法律文书以及网页截图等富媒体文档),并细分了20多个子类。 -
重点考察STEM领域:这个基准极其强调对学术和科学文档的考察,大量收录了数学、物理、化学等学科的材料,这些文档里密密麻麻地嵌套数学公式、多层级符号和复杂的化学结构式。


除了内容深奥,考题的“长相”也很刁钻。LogicsParsingBench中有相当比例的页面包含了高度复杂的版面结构,比如:
-
像报纸一样的多栏交错布局。 -
图片和文字混在一起的混排结构与浮动元素。 -
特殊的竖排文字或旋转文本块。 -
让人眼花缭乱的跨页表格与分栏断行。
这些“排版刺客”不仅增加了视觉分析的难度,更是对 AI 模型的版面分析、区域关系理解以及还原阅读顺序的能力提出了极其苛刻的要求。

既然考题变难了,那传统死板的阅卷方式就不管用了。因此,LogicsParsingBench 引入了两项关键的改变:
-
更“顾全大局”的全局文本评估(Global Text Evaluation): 以前的评测喜欢以文本块为单位,进行逐个比对,所以AI 只要分段习惯和标准答案不一样就会被扣分。而现在,我们会把一页里所有的正文拼接成一整个长字符串,再来计算文本差异,这样一来,评估更加强调整体文本识别的准确性,不再纠结于局部的分块细节。 -
更严格的输出归一化(Stricter Content Normalization): 针对表格、公式等结构化内容,不同 AI 输出的习惯都不一样。我们则会在打分前进行严格的标准化:移除多余的空格和不可见字符、统一常见符号、简化特定的格式标签,一句话总结:阅卷更关注“意思对不对(语义准确性)”,忽略排版上肉眼难以察觉的小问题(表面格式差异)。

我们将市面上主流的文档解析方案全部纳入评测,分成三类:Pipeline 工具、专家级视觉语言模型、通用视觉大模型,以及我们自研的两代模型:Logics-Parsing 和 Logics-Parsing-v2:
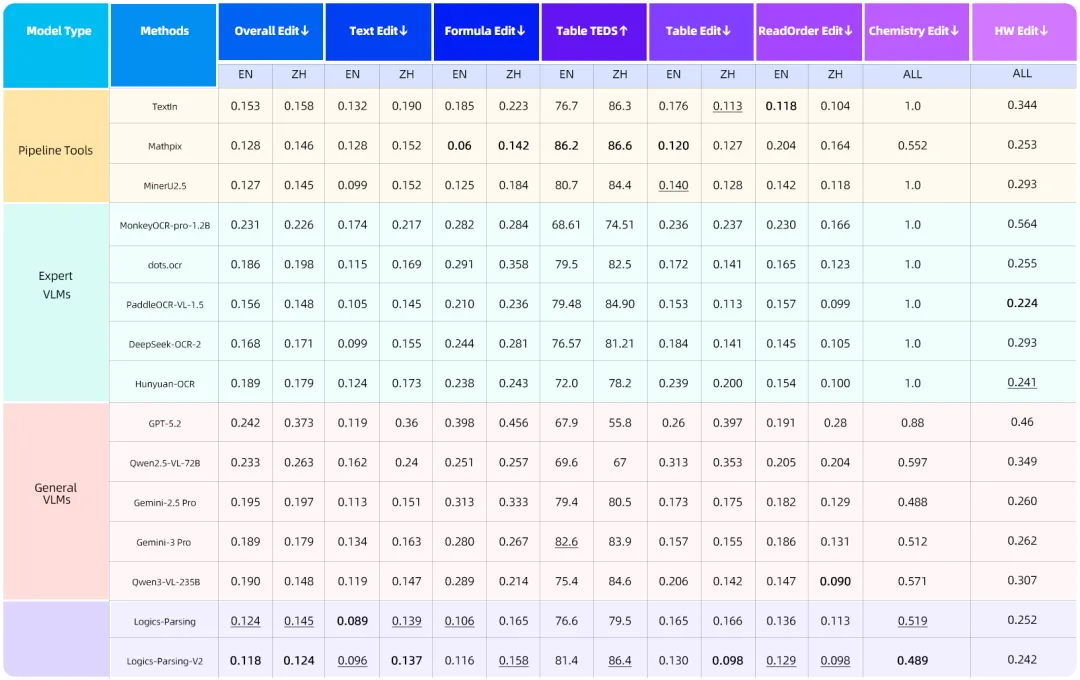
榜单解读:
-
传统的基于流水线pipeline构建的方法(版面分析+元素检测+元素OCR识别)仍然有着不错的效果,在多项指标上都领先于现有的基于大模型的方法,特别是Mathpix,在数学科学相关内容的识别上依然优势明显。 -
近两年来,针对文档解析的专家大模型层出不穷,凭借数据、模型、文档解析任务的针对性优化,PaddleOCR-VL-1.5、DeepSeek-OCR-2这些模型在各项指标上都有着比较全面的表现,而Gemini-3pro作为目前最强的通用多模态大模型之一,其在文档解析上的实力确实不容小觑,在大部分指标的比拼上都能跟最新的专家模型打得有来有回; -
从数值分布上来说,目前各主流模型的得分差异性比较明显,这说明该评测集覆盖的样本范围更广、难度更大、多样性更丰富。此外,目前各个模型的得分仍然有较大的提升余地,意味着后续的模型迭代更新还有很大的发展空间。 -
阿里的Logics-Parsing和Logics-Parsing-V2在多项指标上都位列前两名,并且取得了总分第一的成绩。相比于Logics-Parsing,V2模型通过更小的参数量(4B),在总分、表格识别、阅读顺序理解、手写字识别等关键任务上均大幅超越前代模型,体现了其在文档结构理解、多数据模态感知与语义解析等各项能力上的系统性全面升级。
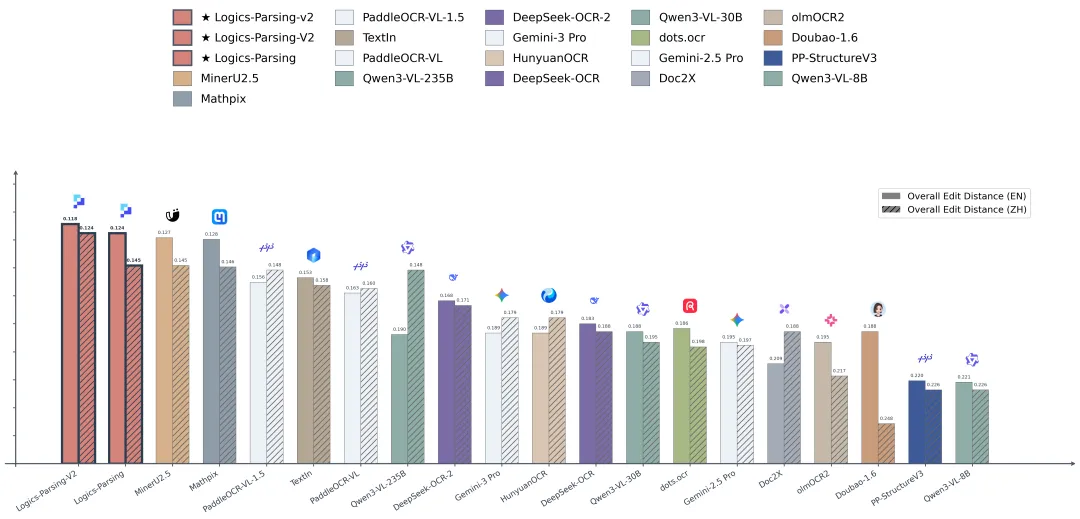
为了更加直观地进行对比,我们将总分排名前20名的模型绘制成比分柱状图。从上图中不难看出,Logics-Parsing-V2 是当前的最优选择,并且相比其他模型拥有更加均衡的中英文文档解析能力。除此之外,Logics-Parsing-V2还首次原生支持Parsing-2.0场景的结构化解析,包括乐谱、流程图、思维导图、代码/伪代码块等高难度文档元素,这些能力通常仅见于千亿参数级别的超大规模通用VLM模型,而如今,仅拥有4B参数量的Logics-Parsing-V2即可高效、精准地完成此类任务,真正实现了“小模型,大能力”。
想要查看完整榜单,欢迎访问【晓天衡宇·评测集社区】https://skylenage.net/sla/evaluation/detail?id=OFW6tlGUt2F4merPuEF26
总结:用评测倒逼技术进化
总而言之,LogicsParsingBench 的出现,弥补了现有评测集在复杂逻辑结构和专业科学内容上的空白。它通过构建更具挑战性的测试集和更合理的评测机制,促使着整个文档智能(Document Intelligence)领域向着更深层次的语义理解和跨模态推理迈进。
👇关注晓天衡宇•评测社区官方账号,获取更多大模型相关知识~