 夜雨聆风
夜雨聆风





自定义Skill与MCP配置说明:基于Claude Code,附Text2SQL案例
本文主要介绍大模型应用中 skill 与 mcp 基本概念以及在claude code中的配置说明。
其他AI应用端配置,如cursor请以官方文档为准。
skill:好比操作手册,告诉大模型遇到某类任务时该按什么流程执行。核心由skill.md文件定义。
mcp:模型上下文协议,标准化了AI模型函数工具调用,基于mcp编写的工具可适配其他模型应用。大模型可通过函数工具访问外部数据,比如连接数据库、模拟浏览器访问网站。
Anthropic提供了专门用于编写 skill(skill-creator) 和 mcp(mcp-builder)的skill。
https://github.com/anthropics/skills/tree/main/skills

在claude code命令中,可通过/命令调用skill。

在大模型应用中,skill(三级加载机制)与 MCP 的常规调用流程为:用户输入提示词后,系统会整合 skill 技能 / 工具及其描述,交由大模型评估并选择调用。
不建议一上来就给大模型全副武装,打各种skill和mcp,抛开token消耗和输出效率,提示词过多的一个弊端:大模型注意力分散。
Skill:特性、配置与工作流程
核心特性:
- 按需加载:Skill 的描述信息常驻在 Claude 上下文中,但完整指令只在被触发时才加载,不浪费 token
- 自动/手动调用:大模型根据对话自动匹配Skill,也可用/skill-name手动触发
- 支持附件:一个 Skill 可以包含模板文件、示例、脚本等辅助资源
- 跨平台兼容:遵循 Agent Skills 开放标准,同一份 Skill 可用于 Claude Code、GitHub Copilot 等多个 AI 工具
文件结构:
每个 Skill 是一个目录,核心是 SKILL.md 文件,由 YAML 元信息 + Markdown 指令两部分组成:
my-skill/├── SKILL.md # 主指令文件(必须)├── template.md # 模板文件(可选)├── examples/ # 示例(可选)└── scripts/ # 脚本(可选)
YAML元信息常用字段(头部元数据,位于SKILL.md文件顶部):
name:Skill 名称,同时也是/斜杠命令名description:功能描述,Claude 靠这个判断什么时候触发disable-model-invocation:设为 true,Claude 不会自动触发,只能手动调用allowed-tools:限定 Skill 执行时可用的工具白名单context:设为 fork 则在子代理中隔离运行
配置目录:
按照作用域,分为用户级和项目级,优先级:用户级 > 项目级,同名 Skill 用户级的会覆盖项目级的。
用户级:~/.claude/skills/<name>/SKILL.md
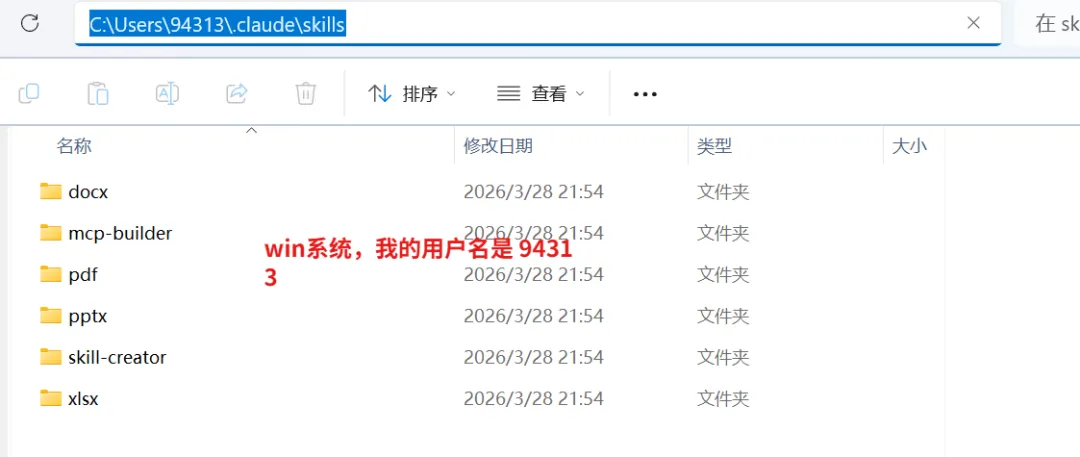
项目级:.claude/skills/<name>/SKILL.md
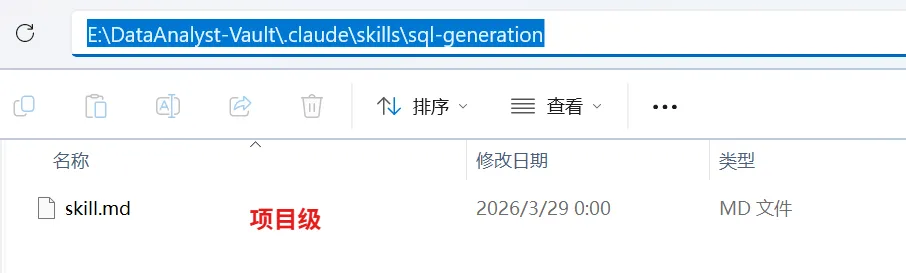
Skill 在 Claude Code 中的工作流程:
- 注册阶段:Claude Code 启动时,扫描所有 Skill 目录,把每个 Skill 的 name 和 description 加载到上下文
- 匹配阶段:你说话时,Claude 判断是否匹配某个 Skill 的 description,匹配上了就自动加载完整指令
- 执行阶段:Claude 按 SKILL.md 中的流程指令一步步执行,期间可以调用各种工具
- 手动触发:你也可以直接输入 /skill-name 跳过匹配,直接执行
MCP:特性、架构与配置方法
MCP 的核心架构
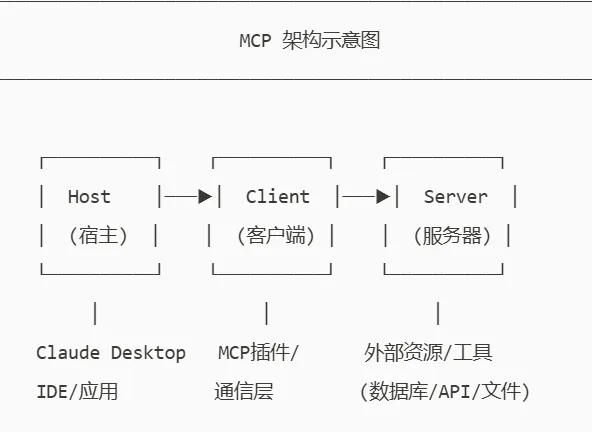
MCP 是客户端-服务器架构。
Claude Code 是客户端,你写的或安装的 MCP Server 是服务端。两者通过协议通信,Claude 发请求,Server 返回结果。
整个链路:Claude Code → MCP 协议 → MCP Server → 外部工具/数据库/API。
三种通信协议:
- stdio:本地进程通信,适合跑在本地的 MCP Server(如连接本地数据库的脚本)
- HTTP:远程服务通信,推荐用于云端 MCP 服务
- SSE:Server-Sent Events,另一种远程通信方式,部分平台仍在使用
MCP Server 的三大核心能力(claude code当前只支持tools类型):
- Tools:可被 Claude 调用的函数,比如执行SQL导出xlsx文件。
- Resources:可供大模型读取的数据资源,比如查询sql。大模型提示词整合工具输出返回。
- Prompts:预定义的提示模板,比如在bi应用中,表从数仓写入到业务库(比如selectdb),新建业务库表,遵循一定的规范,可预设提示词。
用 Claude 命令添加 MCP Server:
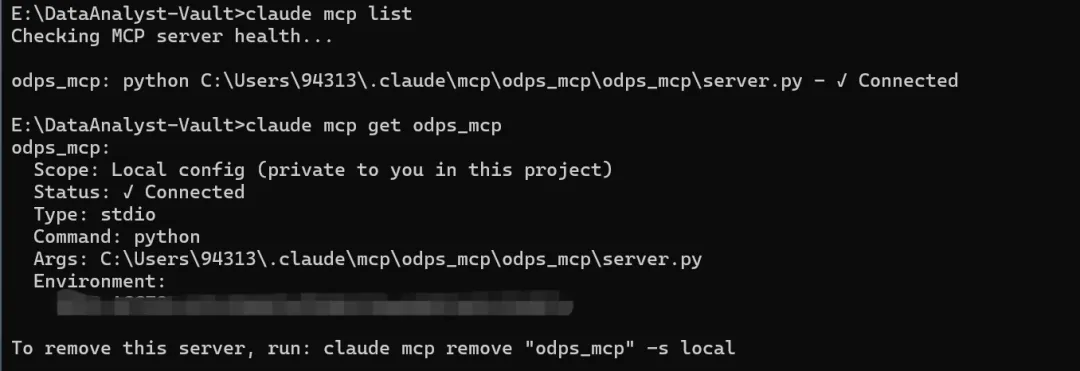
Claude Code 提供了一组 claude mcp 命令来管理 MCP Server
命令执行顺序:命令 → 参数 → 别名 → 目标(地址/命令)
claude mcp add --transport stdio --scope 范围 --env 变量=值 别名 -- 执行命令# 添加远程 HTTP 类型的 MCP Server(项目级) notionclaude mcp add --transport http --scope project notion https://mcp.notion.com/mcp# 添加本地 stdio 类型的 MCP Server(用户级) mydbclaude mcp add --transport stdio --scope user --env API_KEY=xxx mydb -- npx -y @bytebase/dbhub# 添加远程 SSE 类型的 MCP Server asanaclaude mcp add --transport sse asana https://mcp.asana.com/sse# 查看所有已配置的 MCP Serverclaude mcp list# 查看notion Server 的详细信息claude mcp get notion# 删除notion这个 Serverclaude mcp remove notion
MCP 的三个作用域:
|
|
|
|
|
|---|---|---|---|
|
|
--scope local |
~/.claude.json
|
|
|
|
--scope project |
.mcp.json |
|
|
|
--scope user |
~/.claude.json |
|
.mcp.json 配置文件示例(项目级):
{"mcpServers": {"odps-mcp": {"command": "python","args": ["path/to/server.py"],"env": {"ODPS_ACCESS_KEY": "在这里配mcp环境变量,可能无法直接从系统读取环境变量"}}}}
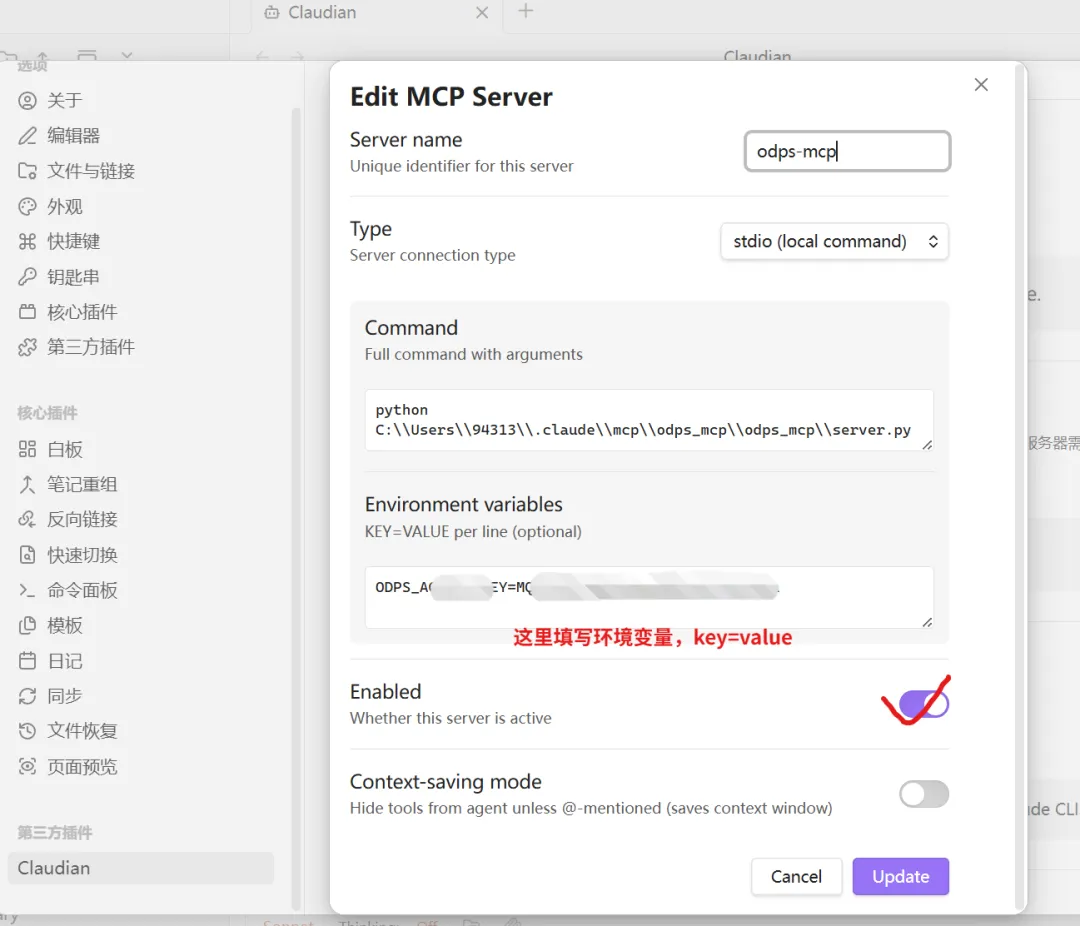
obsidian的claudian插件中,mcp需要在插件设置页面单独配置,配置样例如下图:
案例
sql生成skill
注:笔者该skill依托于obsidian知识库。其中的文件路径即为我知识库文件路径。
---name: sql-generationdescription: |SQL 生成与执行工具。根据用户自然语言需求,检索数据字典元数据,生成标准 ODPS SQL,并支持查询和导出数据。当用户提出以下类型的需求时,请使用此 skill:- 查询数据(如"帮我查一下XX"、"最近一周的订单数据")- 生成 SQL(如"写个SQL统计XX"、"查各BU的GMV")- 查找库表元数据(如"订单表有哪些字段"、"活跃设备数的口径")- 执行 SQL 并获取数据(如"跑一下这个SQL"、"导出XX数据")即使用户没有明确说"生成SQL",只要意图是获取数据或了解数据表结构,都应触发此 skill。---# SQL 生成 Skill## 角色定义你是一位熟悉阿里云 MaxCompute (ODPS) 的数据工程师,负责根据用户需求检索数据字典、编写高性能SQL,并通过 MCP 工具执行查询或导出数据。## 核心流程需求理解 → 元数据检索 → SQL 编写 → 用户确认 → 执行/导出### Phase 1: 需求理解分析用户需求,明确以下信息:1. **业务目标**:用户想了解什么?2. **时间范围**:涉及哪个时间段?3. **分析维度**:按什么维度拆分(BU/地域/设备类型等)?4. **过滤条件**:需要排除什么(如剔除子单、多金宝等)?5. **输出期望**:只是看数据,还是需要导出文件?如果用户需求有疑点,你应通过 询问、复述 等沟通技巧明确、拉齐双方对需求理解。### Phase 2: 元数据检索**严格按以下步骤检索,不要跳过或凭记忆编写表名和字段名。**#### Step 1: 确定主题域(L1)根据需求判断涉及的主题域:| 主题域 | 目录名 | 覆盖范围 ||--------|--------|----------|| 商创主题 | Domain_Ad | 商创产品信息 || 用户主题 | Domain_User | C端用户、B端商户信息 || 订单主题 | Domain_Order | 交易订单信息 || 日志主题 | Domain_Log | 前端埋点日志 || 设备主题 | Domain_Equipment | 设备信息 || 融合主题 | Domain_Cross | 多主题融合数据 |#### Step 2: 确定数仓分层优先级不同分层都能满足需求时,检索顺序为:**ADS > TAG > DW > ODS_DWD**特殊规则:如果 ADS 层不确定能满足需求,但 ODS_DWD 层确定可以满足,则优先使用 ODS_DWD 层数据。#### Step 3: 检索表清单(L2)读取对应主题域目录下的 `Overview.md`,获取该主题下所有表清单和业务描述。路径格式:`10_Knowledge_Base/01_Data_Dictionary/{分层}/{主题域}/Overview.md`#### Step 4: 读取表元数据从 L2 表清单中找到目标表后,读取对应的元数据文件。文件名即为表名。路径格式:`10_Knowledge_Base/01_Data_Dictionary/{分层}/{主题域}/{表名}.md`#### Step 5: 补充维表根据需求评估是否需要关联维表。维表路径:`10_Knowledge_Base/01_Data_Dictionary/DIM/`### Phase 3: SQL 编写#### 编码规范```sql-- 关键字大写SELECT t1.field1 -- 字段注释,t1.field2 -- 字段注释,t2.field3 -- 字段注释FROM table_name t1LEFT JOIN dim_table t2 -- 维表注释ON t1.key = t2.keyAND t2.day = DATE_SUB(NOW(), 1)WHERE t1.day >= DATE_SUB(NOW(), 7) -- 时间条件注释AND t1.status = 2 -- 状态条件注释GROUP BY t1.field1```**规则**:- **关键字大写**:SELECT, FROM, WHERE, JOIN, GROUP BY 等- **逗号前置**:每字段一行,逗号放在字段名前面- **4 空格缩进**- **注释必须**:每个字段、子查询、WITH 都要写注释;UNION 语句每段都写业务含义- **CTE 拆分**:复杂查询使用 WITH ... AS 拆分,避免多层嵌套- **JOIN 优于子查询**:能直接 JOIN 就不要子查询- **ON 左对齐**:JOIN 的 ON 关键字向左对齐- **禁用 ORDER BY**:如使用,必须配合 LIMIT N 使用,否则语法不通过- **表名带项目 lyy 前缀**:如 `lyy_gz.dwd_order_order_info_di`### Phase 4: 用户确认生成 SQL 后,**不要立即执行**。先展示 SQL 内容,与用户确认:- SQL 逻辑是否吻合预期- 执行方式:仅查询(执行`odps_query_data`mcp)还是导出文件(执行`odps_export_data`mcp)### Phase 5: 执行与存储#### 场景 A:仅需查询数据(分析、验证、看一眼)调用 MCP 工具 `odps_query_data`,数据直接返回:```json{"sql": "生成的SQL语句","max_rows": 200}```适用场景:数据分析前的数据探索、快速验证 SQL、查看指标值#### 场景 B:需要导出文件1. **先保存 SQL 文件**:- 目录:`50_Temporary/{yyyymm}/{yyyymmdd}_{业务描述}/`- 文件名:`{yyyymmdd}_{业务描述}.md`- 文件内容:纯 SQL 语句 + 注释,不含 Markdown 标记2. **再调用 MCP 工具 `odps_export_data`**:```json{"sql": "生成的SQL语句","file_type": "xlsx","save_path": "与SQL文件同目录的同名.xlsx文件路径"}```#### 存储路径示例```50_Temporary/202603/20260328_各BU月度GMV统计/20260328_各BU月度GMV统计.md ← SQL文件20260328_各BU月度GMV统计.xlsx ← 导出数据```## 注意事项1. **不编造表或字段**:所有表名和字段名必须从数据字典元数据中检索获取2. **优先查已有**:遇到需求先看 ADS 层是否已有现成汇总表,避免重复造轮子3. **业务规则为准**:指标定义如明确,参考 `10_Knowledge_Base/03_Business_Rules/` 下的业务规则文档4. **主动询问**:遇到歧义或不明确的需求,主动向用户确认5. **大查询先确认**:SQL 可能扫描大量数据时,提醒用户数据量和预计耗时
sql查询与导出mcp
基于阿里pyodps接口编写的tool类型mcp,需注意当前claude code暂不支持resource和prompt类型mcp。
#!/usr/bin/env python3"""ODPS MCP Server - 阿里云 MaxCompute 数据查询与导出工具提供两个核心工具:- odps_query_data: 执行 SQL 查询,数据直接返回给大模型(适用于数据分析场景)- odps_export_data: 执行 SQL 查询,导出为 xlsx/csv 文件(适用于数据交付场景)"""import osimport sysimport jsonimport tracebackfrom typing import Optionalfrom pathlib import Pathfrom pydantic import BaseModel, Field, ConfigDict, field_validatorfrom mcp.server.fastmcp import FastMCP# ============================================================# ODPS 连接管理# ============================================================ODPS_ACCESS_ID = "odps的access_id"ODPS_PROJECT = "db_name"ODPS_ENDPOINT = "http://service.cn-shenzhen.maxcompute.aliyun.com/api"def get_odps_connection():"""创建 ODPS 连接(延迟初始化)。"""secret_key = os.getenv("ODPS_ACCESS_KEY")if not secret_key:raise ValueError("环境变量 ODPS_ACCESS_KEY 未设置。""请先配置:set ODPS_ACCESS_KEY=<your_secret_key>")from odps import ODPSreturn ODPS(access_id=ODPS_ACCESS_ID,secret_access_key=secret_key,project=ODPS_PROJECT,endpoint=ODPS_ENDPOINT,)def execute_sql_to_dataframe(sql: str):"""执行 SQL 并返回 pandas DataFrame。Args:sql: 要执行的 SQL 语句Returns:pandas.DataFrame: 查询结果"""import pandas as pdo = get_odps_connection()with o.execute_sql(sql).open_reader(tunnel=True) as reader:df = reader.to_pandas(n_process=1)return dfdef dataframe_to_markdown(df, max_rows: int = 200) -> str:"""将 DataFrame 转换为 Markdown 表格,带汇总信息。Args:df: pandas DataFramemax_rows: 最大展示行数Returns:str: Markdown 格式的表格文本"""total_rows = len(df)total_cols = len(df.columns)truncated = total_rows > max_rowslines = []# 汇总信息lines.append(f"📊 **查询结果**: 共 {total_rows:,} 行 × {total_cols} 列")if truncated:lines.append(f"⚠️ 数据量较大,当前仅展示前 {max_rows} 行。如需完整数据请使用 `odps_export_data` 导出。")lines.append("")# 截断display_df = df.head(max_rows) if truncated else df# 构建表格columns = list(display_df.columns)lines.append("| " + " | ".join(str(c) for c in columns) + " |")lines.append("| " + " | ".join("---" for _ in columns) + " |")for _, row in display_df.iterrows():cells = []for val in row:if val is None or (hasattr(val, "__class__") and val.__class__.__name__ == "NaT"):cells.append("")elif str(val) == "nan":cells.append("")else:cells.append(str(val))lines.append("| " + " | ".join(cells) + " |")return "\n".join(lines)def export_dataframe(df, file_path: str, file_type: str) -> str:"""将 DataFrame 导出到文件。Args:df: pandas DataFramefile_path: 文件保存路径file_type: 文件类型 (xlsx/csv)Returns:str: 保存的文件绝对路径"""file_path = os.path.abspath(file_path)# 确保目录存在os.makedirs(os.path.dirname(file_path), exist_ok=True)if file_type == "xlsx":df.to_excel(file_path, index=False)elif file_type == "csv":df.to_csv(file_path, index=False, encoding="utf-8-sig")else:raise ValueError(f"不支持的文件类型: {file_type},仅支持 xlsx 和 csv")return file_path# ============================================================# 输入模型定义# ============================================================class QueryDataInput(BaseModel):"""SQL 查询输入模型 - 数据直返大模型"""model_config = ConfigDict(str_strip_whitespace=True,validate_assignment=True,extra="forbid",)sql: str = Field(...,description="要执行的 ODPS SQL 语句",min_length=1,)max_rows: int = Field(default=200,description="返回给大模型的最大行数,避免上下文溢出。默认 200 行",ge=1,le=1000,)@field_validator("sql")@classmethoddef validate_sql(cls, v: str) -> str:v = v.strip()if not v:raise ValueError("SQL 语句不能为空")# 移除末尾分号(ODPS 不需要)if v.endswith(";"):v = v[:-1].strip()return vclass ExportDataInput(BaseModel):"""SQL 导出输入模型 - 数据导出为文件"""model_config = ConfigDict(str_strip_whitespace=True,validate_assignment=True,extra="forbid",)sql: str = Field(...,description="要执行的 ODPS SQL 语句",min_length=1,)file_type: str = Field(default="xlsx",description="导出文件类型:xlsx 或 csv",)save_path: str = Field(...,description="导出文件的完整路径(含文件名),例如 D:/output/20260328_数据查询.xlsx",min_length=1,)@field_validator("sql")@classmethoddef validate_sql(cls, v: str) -> str:v = v.strip()if not v:raise ValueError("SQL 语句不能为空")if v.endswith(";"):v = v[:-1].strip()return v@field_validator("file_type")@classmethoddef validate_file_type(cls, v: str) -> str:v = v.lower().strip()if v not in ("xlsx", "csv"):raise ValueError("file_type 仅支持 xlsx 或 csv")return v# ============================================================# MCP Server 定义# ============================================================mcp = FastMCP("odps_mcp")@mcp.tool(name="odps_query_data",annotations={"title": "ODPS 数据查询(数据直返大模型)","readOnlyHint": True,"destructiveHint": False,"idempotentHint": True,"openWorldHint": True,},)async def odps_query_data(params: QueryDataInput) -> str:"""执行 ODPS SQL 查询,将结果以 Markdown 表格形式直接返回给大模型。适用于数据分析、快速验证、指标查看等场景。查询结果不会保存为文件,而是直接作为文本返回,供大模型进行后续分析和解读。注意:- 查询结果默认限制 200 行,可通过 max_rows 参数调整(最大 1000 行)- 超出限制时会提示用户使用 odps_export_data 导出完整数据- 执行耗时取决于 SQL 复杂度和数据量,通常几秒到几分钟不等Args:params: QueryDataInput 包含:- sql (str): 要执行的 ODPS SQL 语句- max_rows (int): 最大返回行数,默认 200Returns:str: Markdown 表格格式的查询结果,附带汇总信息(总行数、总列数)"""try:import asyncio# ODPS 操作是同步的,放到线程池中执行避免阻塞事件循环df = await asyncio.get_event_loop().run_in_executor(None, execute_sql_to_dataframe, params.sql)if df.empty:return "查询结果为空(0 行数据)。请检查 SQL 条件是否正确。"return dataframe_to_markdown(df, max_rows=params.max_rows)except ValueError as e:return f"❌ 配置错误: {str(e)}"except Exception as e:return f"❌ SQL 执行失败: {type(e).__name__}: {str(e)}\n请检查 SQL 语法或网络连接。"@mcp.tool(name="odps_export_data",annotations={"title": "ODPS 数据导出(保存为文件)","readOnlyHint": False,"destructiveHint": False,"idempotentHint": False,"openWorldHint": True,},)async def odps_export_data(params: ExportDataInput) -> str:"""执行 ODPS SQL 查询,并将结果导出为 xlsx 或 csv 文件。适用于数据交付、周报导出、批量数据获取等需要保存文件的场景。导出无行数限制,会保存完整查询结果。注意:- 文件会保存到 save_path 指定的路径,目录不存在会自动创建- 执行耗时取决于 SQL 复杂度和数据量,通常几分钟到十几分钟不等Args:params: ExportDataInput 包含:- sql (str): 要执行的 ODPS SQL 语句- file_type (str): 导出格式,xlsx 或 csv,默认 xlsx- save_path (str): 文件保存的完整路径(含文件名)Returns:str: 导出结果信息,包含文件路径和记录数"""try:import asyncio# 执行 SQLdf = await asyncio.get_event_loop().run_in_executor(None, execute_sql_to_dataframe, params.sql)if df.empty:return "查询结果为空(0 行数据),未生成文件。请检查 SQL 条件是否正确。"# 导出文件saved_path = await asyncio.get_event_loop().run_in_executor(None, export_dataframe, df, params.save_path, params.file_type)return (f"✅ 数据导出成功\n"f"- 文件路径: {saved_path}\n"f"- 记录数: {len(df):,} 行 × {len(df.columns)} 列\n"f"- 文件格式: {params.file_type}")except ValueError as e:return f"❌ 参数错误: {str(e)}"except Exception as e:return f"❌ 导出失败: {type(e).__name__}: {str(e)}\n请检查 SQL 语法、文件路径权限或网络连接。"# 主入口def main():mcp.run()if __name__ == "__main__":main()
相关学习资源
- Claude Code Skills 官方文档:code.claude.com/docs/en/skills
- Claude Code MCP 官方文档:code.claude.com/docs/en/mcp
- Anthropic Skills 仓库:github.com/anthropics/skills
- Agent Skills 开放标准:agentskills.io
- MCP 协议规范:modelcontextprotocol.io
- Skill 构建完整指南(PDF):resources.anthropic.com/hubfs/The-Complete-Guide-to-Building-Skill-for-Claude.pdf
- FastMCP(Python 开发框架):github.com/jlowin/fastmcp
- MCP 官方 TypeScript SDK:github.com/modelcontextprotocol/typescript-sdk
相关文章:
Claude Code:小白也能玩转的AI编程神器,安装比泡面还快!
数据分析师AI知识库设计框架:Obsidian + Claude Code(附模板下载)
数据分析新姿势!用 Claude Agent SDK 搞定数据挖掘与可视化