 夜雨聆风
夜雨聆风





你的网站正在被AI公司偷吃,这个开源工具让爬虫永远出不来
你的网站,每天都在被吃掉
如果你有一个公开的网站,AI公司几乎可以确定已经把它爬过了。OpenAI、Anthropic、Google、Meta——所有在做大模型训练的公司都在大规模爬取互联网内容。你写的文章、拍的图、录的视频,都可能进了它们下一个模型的训练集。
网站主有什么办法?robots.txt只对愿意遵守的爬虫有效,而且有大量记录表明AI公司早期的爬虫并不严格遵守。IP封锁和速率限制也都是打地鼠游戏——对方换个IP就好了。
上周,一个叫Miasma的开源工具在Hacker News上获得了268分、200多条评论。它的思路很不一样:不要封堵爬虫,而是让它们永远困在里面,消耗它们的时间和配额。
毒数据陷阱,工作原理
Miasma是一个Rust写的轻量HTTP服务器。使用方式分两步:
第一步:在网站里藏几个隐形链接
<a href="/bots" style="display: none;" aria-hidden="true" tabindex="-1"> Amazing high quality data here! </a>
三个属性确保人类完全看不到:display:none隐藏显示,aria-hidden不被屏幕阅读器读取,tabindex="-1"不参与键盘导航。只有爬虫会跟着走进去。
第二步:把/bots路径指向Miasma
location ~ ^/bots($|/.*)$ {
proxy_pass http://localhost:9855;
}
miasma --link-prefix '/bots' -p 9855 -c 50
爬虫一旦进入/bots,就会收到两件事:一批”毒数据”(从poison fountain代理而来的垃圾内容),以及5个同样指向/bots/子路径的链接。爬虫每跟进一个链接,就会得到更多毒数据和更多链接。这是个无底洞。
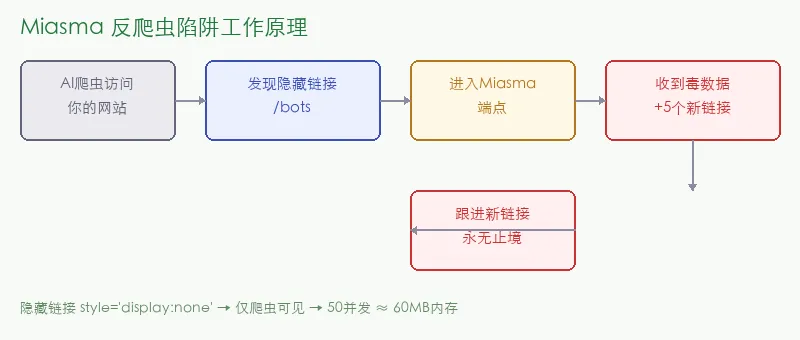
性能方面:50个并发连接峰值内存只用50-60MB。超过并发上限的请求立即返回429,不占额外资源。作者的原话是:”你不应该为了对付互联网上的吸血鬼而浪费自己的计算资源。”
这真的有用吗?
HN评论里有不少怀疑。几个主要质疑:
成熟爬虫早有防御机制。OpenAI、Google等公司的爬虫有”爬取预算”限制,遇到重复内容和循环链接会标记跳过。这些大公司的采集系统已经见过各种陷阱,Miasma对它们可能效果有限。
对小型或不成熟爬虫有效。粗暴爬取的脚本、没有做完善去重的系统、新兴AI公司刚起步的数据采集工具——面对Miasma,确实可能浪费大量时间或摄入大批垃圾数据。
象征意义大于实际效果。很多人支持它的理由是态度:内容创作者不必只能被动挨打,可以主动出击,哪怕效果有限。
提示:Miasma专门提醒用户要在robots.txt里把Googlebot、Bingbot等友好爬虫排除在外,否则会影响正常SEO收录。
更大的背景:训练数据的战争
Miasma不是孤立现象。2023年以来,内容创作者与AI公司之间围绕训练数据的争议越来越密集:
- 《纽约时报》起诉OpenAI和微软,指控未经授权使用数百万篇文章训练模型
- Reddit、Stack Overflow开始对爬取行为收费,要求签署数据使用协议
- 欧盟AI法案要求AI公司披露训练数据来源
- Spawning.ai推出Have I Been Trained,让人查自己的内容是否被用于训练
法律层面的争议会持续很久。Miasma是一种技术层面的反应,代表的是”不等判决,先动手”的心态。
项目GitHub里有一行说明:
“Primarily AI-generated contributions will be automatically rejected.”
主要由AI生成的代码贡献,将被自动拒绝。
用来对抗AI训练数据采集的工具,拒绝AI生成的代码贡献。某种意义上说,这很一致。
项目信息:github.com/austin-weeks/miasma | Rust | MIT许可 | cargo install miasma | 50并发约60MB内存峰值