 夜雨聆风
夜雨聆风





一文吃透DeepStream核心插件Gst-nvinfer:AI推理的“性能核心”
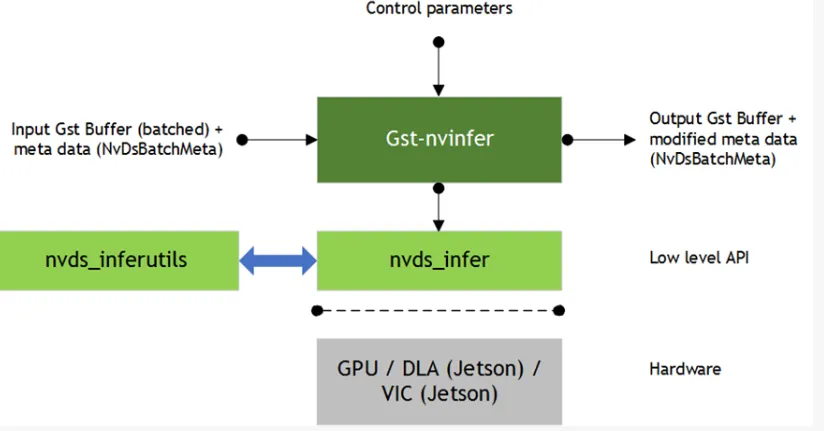
在NVIDIA DeepStream的GStreamer插件体系中,Gst-nvinfer是当之无愧的核心推理组件,它基于NVIDIA TensorRT™实现视频流的高性能AI推理,是连接原始视频数据与计算机视觉任务的关键桥梁。小到边缘端Jetson设备的智能分析,大到云端多GPU的视频集群处理,所有视觉推理需求几乎都由它支撑。
今天我们抛开晦涩的官方文档,用“中英结合+通俗举例”的方式,讲透Gst-nvinfer的核心能力、工作模式、推理流程和配置要点,让新手也能快速上手这个DeepStream必备插件。
一、Gst-nvinfer核心定位:视频流的AI推理引擎
简单来说,Gst-nvinfer的核心作用是对批处理的视频流数据执行AI推理(Inferencing),它接收上游传递的视频帧数据,完成格式转换、缩放、归一化等预处理(Preprocessing),再通过TensorRT引擎运行训练好的AI模型,最终将推理结果以元数据(MetaData)的形式附加在原始视频流上,传递给下游的跟踪、渲染、分析插件。
可以把它比作一个智能视觉分析工厂:
-
上游插件:原材料供应商,提供NV12/RGBA格式的Gst Buffer视频帧+附带的NvDsBatchMeta元数据; -
Gst-nvinfer:核心生产线,完成原材料加工(预处理)和核心检测(AI推理); -
下游插件:成品加工厂,基于推理结果做目标跟踪(Object Tracking)、画面标注、异常报警等后续操作。
目前Gst-nvinfer完美支持四类主流计算机视觉网络(Network),覆盖绝大多数业务场景:
✅ 多类别目标检测(Multi-class object detection):识别画面中人、车、红绿灯、障碍物等多类目标;
✅ 多标签分类(Multi-label classification):对检测出的目标做精细化属性分析,如车辆颜色、车型、行人动作;
✅ 语义分割(Semantic Segmentation):按类别划分画面像素,如区分道路、建筑、植被、天空;
✅ 实例分割(Instance Segmentation):精准勾勒每个目标的像素轮廓,比检测更精细,如区分画面中每一辆车的具体边缘。
二、三种工作模式(Working Mode),适配所有推理场景
Gst-nvinfer设计了三种灵活的工作模式,可单独使用也可组合实现级联推理(Cascaded Inferencing),能满足从基础检测到精细化分析的所有业务需求,这也是它的灵活性所在。
模式1:主模式(Primary mode)—— 全帧推理,基础识别
核心逻辑:对完整的视频帧(Full frames)执行推理,是最基础的推理模式,负责从无到有识别画面中的目标。
适用场景:作为视觉分析的第一步,完成全画面的基础目标检测,为后续分析打基础。
实际举例:交通摄像头用主模式运行YOLOv3模型,对每帧画面做全帧检测,识别出所有车辆、行人和非机动车,生成基础的目标边界框(Bounding Box)。
关键特点:推理覆盖整帧,是级联推理的“第一环”,支持FP32/FP16/INT8多种推理精度。
模式2:副模式(Secondary mode)—— 目标推理,精细化分析
核心逻辑:不处理全帧,仅对上游组件(如主模式Gst-nvinfer、Gst-nvtracker跟踪插件)生成的目标元数据做推理,是对基础检测结果的二次精细化分析。
适用场景:在基础检测之上做属性分析、二次识别,如先检测出车辆,再判断车辆品牌/是否压线;先检测出人脸,再做人脸特征提取。
核心优化:搭配Gst-nvtracker时,会通过目标唯一ID缓存分类结果,仅当目标首次出现或边界框面积增大20%以上时重新推理,大幅节省算力!
实际举例:主模式识别出画面中的“车辆”后,副模式仅对“车辆”目标做推理,完成车辆类型(轿车/货车/公交车)的分类,同时过滤掉宽度小于40像素的误检小目标。
模式3:预处理张量输入模式(Preprocessed Tensor Input mode)—— 跳过预处理,极致高效
核心逻辑:完全跳过自身的预处理流程,直接使用上游Gst-nvdspreprocess插件处理好的张量(Tensor)数据做推理,是效率最高的推理模式。
适用场景:对推理延迟要求极高的低时延场景,或需要自定义预处理逻辑的复杂多模型串联场景。
关键注意:此模式下Gst-nvinfer的批次大小(Batch size),必须与Gst-nvdspreprocess配置的感兴趣区域(ROI,Region of Interest)总数一致;且插件会直接读取GstNvDsPreProcessBatchMeta元数据中的张量,无任何额外处理。
实际举例:工业质检场景中,Gst-nvdspreprocess已完成自定义的图像裁剪、增强,Gst-nvinfer直接读取处理后的张量,运行缺陷检测模型,减少重复预处理的时间损耗。
经典组合:级联推理(Cascaded Inferencing)
将主模式+副模式组合使用,是DeepStream最经典的推理方案,实现“基础检测→精细化分析”的层层递进:
示例流程:主模式(多类别目标检测)→ 副模式1(车辆颜色分类)→ 副模式2(车辆违章行为检测),一套流程完成交通违章的端到端分析。
三、推理全流程:从输入到输出,一步不落讲清
Gst-nvinfer的工作流程可拆解为输入(Input)→ 预处理(Preprocessing)→ 推理(Inferencing)→ 输出(Output) 四步,每一步都有明确的规则和硬件加速支持,也是它实现高性能的关键,我们中英结合讲透每一步。
1. 输入(Input):多格式兼容,模型与视频流双支持
Gst-nvinfer的输入分为视频流数据和模型文件两类,兼容DeepStream生态的所有主流格式,满足开发和部署的不同需求:
视频流输入
-
批处理的Gst Buffer(视频帧),格式为NV12/RGBA; -
已附加在Gst Buffer上的NvDsBatchMeta元数据,且需包含NvDsFrameMeta帧元数据。
模型文件输入
支持多种模型格式,推荐部署时使用TensorRT引擎文件,推理性能最优:
-
ONNX模型:开发阶段常用,方便模型迭代; -
TAO加密模型(TAO Encoded Model):NVIDIA TAO Toolkit训练的加密模型,支持直接加载; -
TensorRT引擎文件(Engine file):预处理后的优化模型,支持动态热更新(On-the-fly model update),运行中替换无需重启流水线; -
同时支持INT8校准文件(INT8-calib-file),用于FP32模型的INT8精度量化。
2. 预处理(Preprocessing):把视频帧变成模型“能读懂”的样子
原始视频帧的格式、尺寸与AI模型的输入要求往往不符,Gst-nvinfer会基于GPU/VIC硬件加速,自动完成格式转换、尺寸缩放、像素归一化,核心仅一个公式,简单易懂:
核心公式
y = net scale factor × (x – mean)
-
x:原始像素值,为INT8类型,取值范围[0,255]; -
mean:均值,从配置文件的mean-file(PPM格式均值文件)或offsets(通道均值数组)中读取,浮点型(Float); -
net scale factor:网络缩放因子,配置文件中指定的像素归一化系数,浮点型(Float); -
y:预处理后的输出像素值,浮点型(Float),为模型可直接接收的格式。
举例子
若配置offsets=123.675;116.28;103.53(RGB三通道均值)、net-scale-factor=0.017,那么红色通道原始像素值x=150时,预处理后的值为:
y = 0.017 × (150 – 123.675) = 0.447525
其他预处理操作
-
格式转换:将NV12/RGBA转换为模型要求的RGB/BGR/GRAY(灰度); -
尺寸缩放:将视频帧/目标裁剪图缩放到网络分辨率(Network Height/Width),可配置是否保持宽高比(Maintain input aspect ratio)、是否对称填充(Symmetric padding); -
硬件加速:缩放可选择GPU/VIC(Jetson专属)作为计算硬件,搭配不同的缩放滤波器(Scaling filter),兼顾速度和效果。
3. 推理(Inferencing):基于TensorRT,实现极致性能
预处理后的浮点型平面数据(RGB/BGR/GRAY)会被送入TensorRT引擎执行推理,这是Gst-nvinfer高性能的核心原因:
TensorRT会对模型做层融合、精度优化、批处理优化,相比PyTorch/TensorFlow原生框架,推理速度可提升数倍甚至数十倍。
推理核心特性
-
多精度支持:FP32(高精度)、FP16(平衡速度和精度)、INT8(超高速度,低显存),平台相关; -
多硬件支持:支持多GPU推理(Multi GPU),可指定gpu-id;支持DLA引擎(仅Jetson AGX Orin/Orin NX); -
自定义支持:支持加载自定义层的IPlugin接口,可通过custom-lib-path加载自定义实现库,适配非标准模型; -
异步推理:副模式下开启classifier-async-mode,可实现异步推理和元数据附加,进一步降低时延。
4. 输出(Output):视频流+元数据,下游无缝衔接
Gst-nvinfer不会修改原始视频帧内容,仅将推理结果以元数据(MetaData) 的形式附加在Gst Buffer上,传递给下游插件,下游可直接读取和使用,无需额外解析。
支持的元数据类型根据网络类型不同而变化,核心包括:
-
NvDsObjectMeta:多类别目标检测的结果,包含目标边界框、类别ID、置信度等; -
NvDsClassifierMeta:多标签分类的结果,包含分类标签、分类置信度、分类类型等; -
NvDsInferSegmentationMeta:语义/实例分割的结果,包含每个像素的类别ID、分割掩码等; -
NvDsInferTensorMeta:原始张量输出,包含模型各输出层的原始数据,适合自定义解析推理结果的场景。
四、核心配置要点:配置文件+Gst属性,新手快速上手
Gst-nvinfer的配置通过配置文件(Configuration File) 和Gst属性(Gst Properties) 实现,其中Gst属性的优先级高于配置文件,方便程序运行中动态修改参数。配置文件采用Key File格式,核心分为三大组,我们挑中英结合+新手必看的关键参数讲解。
1. 核心配置组[property]:插件整体行为,必配!
该组用于配置Gst-nvinfer的整体工作模式、模型路径、预处理参数等,是配置文件的必配组,关键参数如下表(附通俗解释和示例):
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2. 检测配置组:[class-attrs-all/[class-attrs-]]
针对多类别目标检测的精细化配置,[class-attrs-all]对所有类别生效,[class-attrs-
-
threshold:检测置信度阈值,设0.5即保留置信度≥50%的目标,过滤误检; -
nms-iou-threshold:NMS算法的IOU阈值,设0.3即重叠度≥30%的边界框合并,保留置信度更高的; -
roi-top-offset/roi-bottom-offset:ROI上下偏移量,设roi-top-offset=200即忽略画面顶部200像素,避免天空误检; -
detected-min-w/detected-min-h:目标最小宽高,设40即过滤宽高小于40像素的小目标。
3. Gst属性(Gst Properties):动态修改参数
若需要在代码中动态调整配置(如运行中切换模型、修改批次大小),可通过Gst属性实现,核心属性如下,优先级高于配置文件:
-
config-file-path:配置文件的绝对路径; -
unique-id:对应配置文件的gie-unique-id; -
batch-size:动态修改批次大小; -
gpu-id:指定推理使用的GPU设备ID(dGPU专属); -
output-tensor-meta:是否开启原始张量输出; -
crop-objects-to-roi-boundary:是否将目标边界框裁剪到ROI边界。
4. 聚类算法(Clustering Algorithm):解决边界框重叠问题
多类别目标检测模型常会对同一个目标输出多个重叠的边界框,Gst-nvinfer提供5种聚类算法,通过cluster-mode配置,自动合并重叠框,核心类型:
-
0:OpenCV GroupRectangles:基础矩形合并,适合简单背景场景; -
1:DBSCAN:密度聚类,适合复杂背景、目标密集的场景; -
2:NMS(Non-maximum Suppression):非极大值抑制,最常用,按IOU阈值合并,推荐配置; -
3:Hybrid(DBSCAN+NMS):混合聚类,先密度聚类再NMS,适合超高精度需求; -
4:No Clustering:不聚类,保留所有边界框,适合自定义解析场景。
五、性能优化技巧:让Gst-nvinfer效率翻倍
掌握以下几个实用技巧,能让Gst-nvinfer的推理性能和业务效果大幅提升,新手也能直接套用:
- 优先使用TensorRT引擎文件
:用TAO Toolkit或trtexec工具将ONNX模型转换为.engine文件,TensorRT会做硬件专属优化,推理速度远快于直接加载ONNX; - 合理设置批次大小(Batch Size)
:批次越大推理效率越高,但显存占用也越大,Jetson边缘端建议设1-4,云端dGPU建议设16-32,根据硬件显存调整; - 副模式搭配Gst-nvtracker
:开启classifier-async-mode异步推理,利用目标ID缓存推理结果,避免重复推理,算力占用可减少50%以上; - 使用INT8精度推理
:对精度要求不高的场景(如智能监控),将network-mode设为1(INT8),相比FP32,推理速度提升2-3倍,显存占用减少一半; - 开启硬件加速缩放
:Jetson设备将scaling-compute-hw设为2(VIC),分流GPU算力,提升整体流水线效率; - 合理设置推理间隔(interval)
:对静态场景(如室内监控),设interval=2/3,减少推理次数,节省算力,几乎不影响效果; - 开启张量输出(output-tensor-meta)
:非标准模型可开启该参数,直接获取模型原始张量输出,自定义解析推理结果,适配个性化业务需求。
六、典型应用场景(Application Scenarios)
Gst-nvinfer作为DeepStream的核心推理插件,几乎覆盖所有视频AI分析(Video AI Analysis) 场景,典型落地案例包括:
✅ 智能安防监控(Intelligent Security Monitoring):主模式多类别目标检测(人/车/物)→ 副模式行为分类(奔跑/徘徊)→ 异常报警;
✅ 智能交通系统(Intelligent Transportation System, ITS):车辆检测→ 车牌识别→ 违章行为检测(压线/闯红灯/逆行);
✅ 工业视觉质检(Industrial Visual Inspection):产品检测→ 缺陷分类→ 语义分割(精准定位缺陷位置);
✅ 机器人视觉(Robot Vision):环境语义分割→ 障碍物检测→ 目标跟踪,实现机器人自主导航;
✅ 智慧零售(Smart Retail):行人检测→ 顾客属性分类(年龄/性别)→ 行为分析(停留/浏览),实现精准营销。
写在最后
Gst-nvinfer看似配置项繁多,但核心逻辑始终围绕**“基于TensorRT实现视频流的高性能AI推理”** 展开。它将视频预处理、模型推理、结果封装的复杂流程做了高度封装,让开发者无需关注底层硬件和TensorRT细节,只需通过简单的配置文件和Gst属性,就能实现工业级的视频AI分析。
无论是新手入门DeepStream,还是资深开发者做复杂场景落地,掌握Gst-nvinfer都是必修课。结合DeepStream官方示例(如deepstream-test2级联推理、deepstream-infer-tensor-meta-test张量输出),修改配置文件就能快速跑通demo,这是最快的上手方式。
希望这篇“中英结合+通俗举例”的文章,能帮你吃透Gst-nvinfer的核心知识点,让你的DeepStream视频AI项目实现性能和效率的双重提升!
我可以帮你整理Gst-nvinfer多场景配置文件模板,包含目标检测、分类、语义分割的基础配置,中英对照参数注释,直接修改路径即可使用,需要吗?