 夜雨聆风
夜雨聆风





RAG实战:让AI回答你自己的文档
大家好,我是小民,见字欢喜。
前面我们用Python接入了DeepSeek API,搭了一个自己的AI助手,还做了多轮对话、文章总结、日报生成这些实用的功能。
我手头有一堆自己的文档,想让AI根据这些内容来回答,而不是瞎编,该怎么做呢?
今天咱们就来解决这个——RAG(检索增强生成)。
01 先说说RAG是什么
RAG = Retrieval(检索)+ Augmented(增强)+ Generation(生成)
一句话解释➔不是让AI凭记忆瞎编,而是先从你的文档里找到相关内容,再让AI根据这些内容来回答。
举个例子👇
普通AI ➔ “公司的年假政策是……(可能瞎编)”
RAG ➔ 先去文档里找到“年假政策”那一页,然后把内容给AI,让AI照着回答
流程如下👇
用户提问 → 检索文档 → 找到相关内容 → 拼接提示词 → AI回答
02 我们这次做什么
沿用之前的deepseek-demo工程,给它加上RAG能力。
实现目标
上传一份公司制度文档,问它“年假多少天?”AI会从文档里找到答案,而不是瞎编。
技术选型
这里我选了一套比较轻量的方案
-
向量库:Chroma(轻量,适合新手) -
Embedding模型:BAAI/bge-small-zh-v1.5(国产,中文效果好) -
大模型:就用我们之前封装好的 DeepSeekClient
03 环境准备
3.1 安装新依赖
在PyCharm的Terminal里执行安装
pip install chromadb sentence-transformers
3.2 更新requirements.txt
requests>=2.31.0python-dotenv>=1.0.0chromadb>=0.4.0sentence-transformers>=2.2.0
04 准备测试文档
在项目根目录下新建一个docs/文件夹
创建一个company_policy.txt,内容如下👇
公司年假政策1. 入职满1年,享有5天年假2. 入职满3年,享有10天年假3. 入职满5年,享有15天年假年假需提前3天申请,经部门经理审批。公司病假政策1. 病假需提供医院证明2. 每月最多3天带薪病假3. 超过部分按事假处理公司加班政策1. 工作日加班按1.5倍工资计算2. 周末加班按2倍工资计算3. 法定节假日加班按3倍工资计算加班需提前在系统提交申请。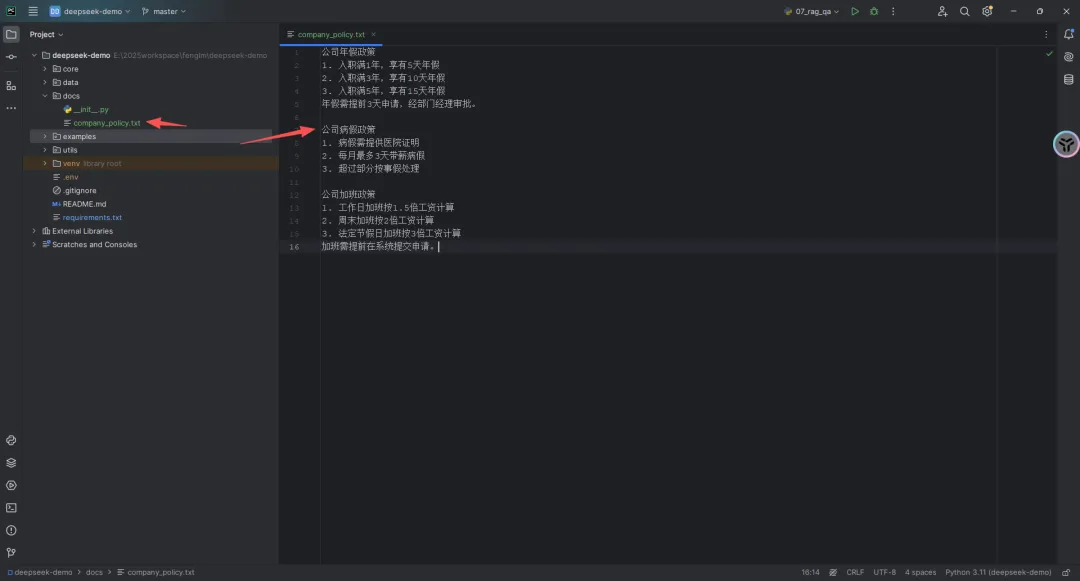
05 核心代码:RAG模块
在core/文件夹下新建rag.py,完整代码我会在最后统一提供。这里先看一下核心逻辑:
-
初始化时自动加载文档,切块并存入向量库 -
search() 方法检索最相关的文档块 -
ask() 方法完成“检索 + 生成”的完整流程
关键点👇
-
用chromadb.utils.embedding_functions.SentenceTransformerEmbeddingFunction绑定Embedding模型 -
文档按段落切块,用collection.add()自动向量化 -
检索时用 query_texts,Chroma会自动计算相似度
封装之后,使用起来也非常简单:
from core.rag import RAGrag = RAG(docs_path="../docs/company_policy.txt")answer = rag.ask("年假有多少天?")print(answer)06 运行效果
代码写完之后,我在examples/07_rag_qa.py里写了一个测试脚本👇
from core.rag import RAG# 初始化RAG(会自动加载docs/company_policy.txt)rag = RAG(docs_path="../docs/company_policy.txt")# 测试几个问题questions = ["年假有多少天?","怎么请病假?","加班工资怎么算?"]for q in questions:print(f"问题:{q}")print(f"回答:{rag.ask(q)}")print("-" * 50)右键运行,效果还不错👇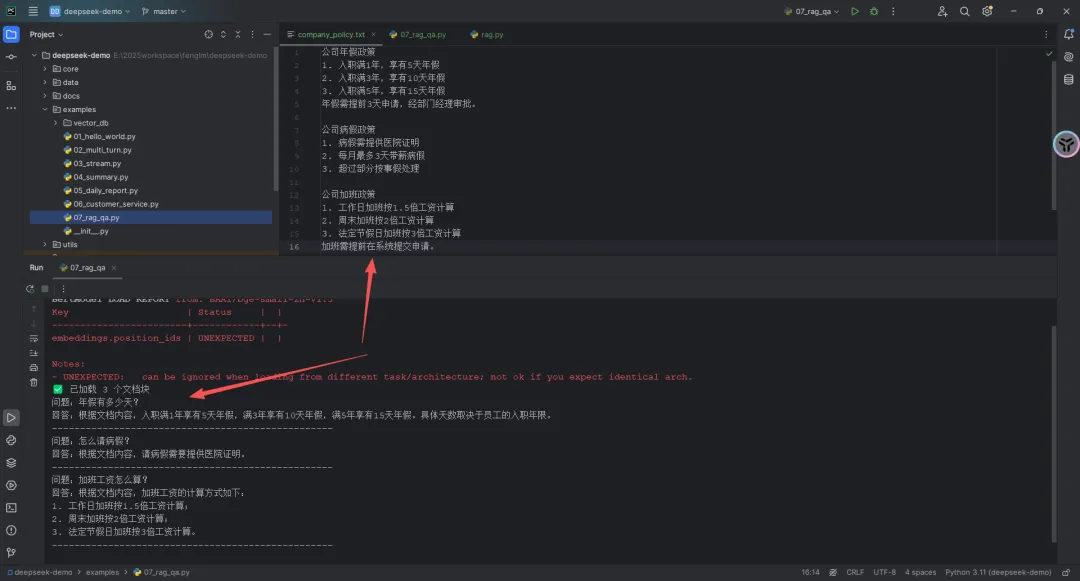
输出示例👇
✅ 已加载 3 个文档块问题:年假有多少天?回答:根据文档内容,入职满1年享有5天年假,满3年享有10天年假,满5年享有15天年假。具体天数取决于员工的入职年限。-----------------------------------------问题:怎么请病假?回答:根据文档内容,请病假需要提供医院证明。-----------------------------------------问题:加班工资怎么算?回答:根据文档内容,加班工资的计算方式如下:1. 工作日加班按1.5倍工资计算;2. 周末加班按2倍工资计算;3. 法定节假日加班按3倍工资计算。-----------------------------------------07 几个踩过的坑
-
Embedding模型下载慢或失败
第一次运行时会自动下载模型(约300MB),国内用户可能有点慢,解决方法:在代码开头加一行👇
import osos.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'-
向量库版本冲突
如果之前运行过,再运行时报错“embedding function conflict”,直接删除项目根目录下的vector_db文件夹,重新运行即可。
-
文档路径找不到
确保docs/company_policy.txt在项目根目录下,不是放在core/或examples/里面。
-
切块策略太简单
目前是按段落切块(\n\n),如果你的文档没有空行,可以自己改成按固定字数切,网上有很多现成方案。
08 还能怎么玩?
有了这个RAG基础,我们还可以做很多事,如👇
-
公司知识库问答➔上传公司制度、产品手册,给员工用 -
个人笔记问答➔把Obsidian/Notion导出,问自己的笔记 -
法律合同查询➔上传合同PDF,问条款 -
论文阅读助手➔上传论文PDF,问核心观点
最后来个小结
今天我们做了一个简单的RAG系统,让AI能根据自己的文档来回答问题,其实核心就三步👇
-
把文档切块、向量化、存起来 -
用户提问时,检索相关的文档块 -
把文档块+问题一起给AI,生成答案
这个功能在之前搭的deepseek-demo工程上只加了两个文件(rag.py和07_rag_qa.py),但能力却提升了一大截——AI不再是“一本正经的胡说八道”,而是“有据可查”了。
好了,今天的分享就到这里了
你想用RAG做什么呢?欢迎在留言区聊聊~

关注公众号后,在对话框回复「RAG」,我把完整源码发你~