夜雨聆风
夜雨聆风





AI时代的软件工程:把环境搭建成一个可持续运行的系统
周末参加了腾讯云架构师深圳同盟的线下活动,各位老师都相当精彩。我今天主要分享下何明璐老师的《AI时代的软件工程-从面向代码到SDD面向规约驱动》
何老师的b站账号叫人月聊IT,内容相当高质量,也很高产。在流量时代,属于清流了,关键全部免费观看。不止方法论,也有实操。
一句话总结作者的分享
软件工程的核心方法论,就是分解与集成:
用 Fork 的思想拆解复杂问题,用 Join 的思想合并分散结果。
从需求拆解到系统构建,从数据采集到业务反推,整个软件生命周期都在重复 “分而治之、合而为之”。
AI 时代的本体建模,并非让这套过程完全由人工走向全自动,而是对其中高成本、高重复、高复杂度的环节进行优化与增强,让分解更清晰、集成更顺畅、数据关联更天然,最终把 “分而治之、合而为之” 的沉重流程变得更轻量化、更高效、更可控。让AI软件真正自带业务语义、能够自我进化、具备持续学习与自适应迭代能力。
软件工程的本质是什么
软件工程,就是一群人通过规范输出、流程输出、技术标准输出,去约束、协调、控制团队里每个人的行为,减少内耗、避免混乱、防止系统失控的一套方式。
它的目的,就是集中力量,用最低的长期总成本,把软件做成、用好、维护住。
软件工程的本质,是解决大型软件全生命周期的复杂性
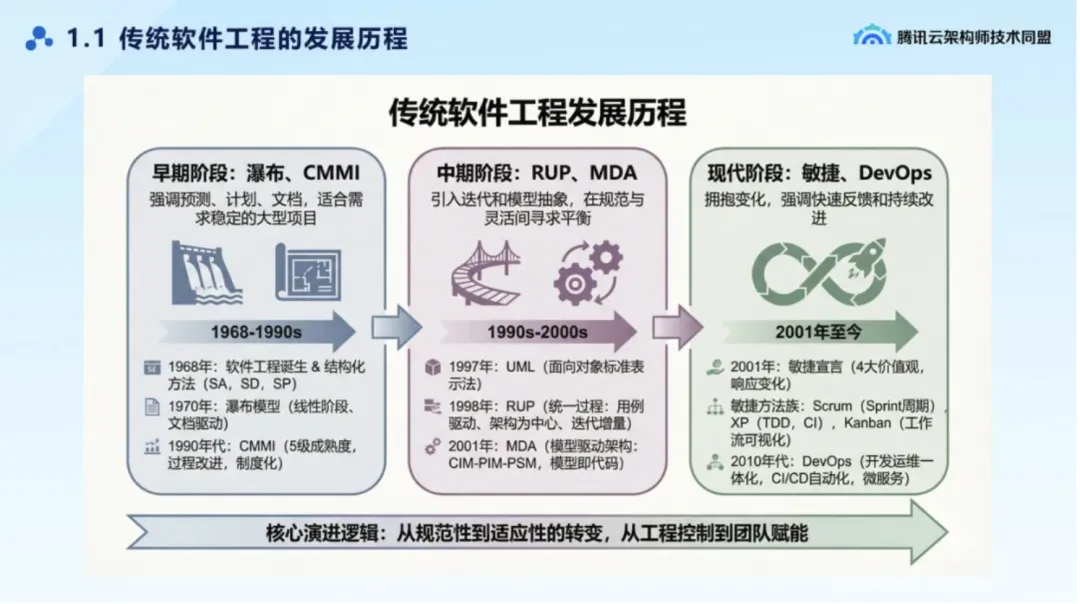
传统软件工程发展历程
软件工程的解决方式的思路
-
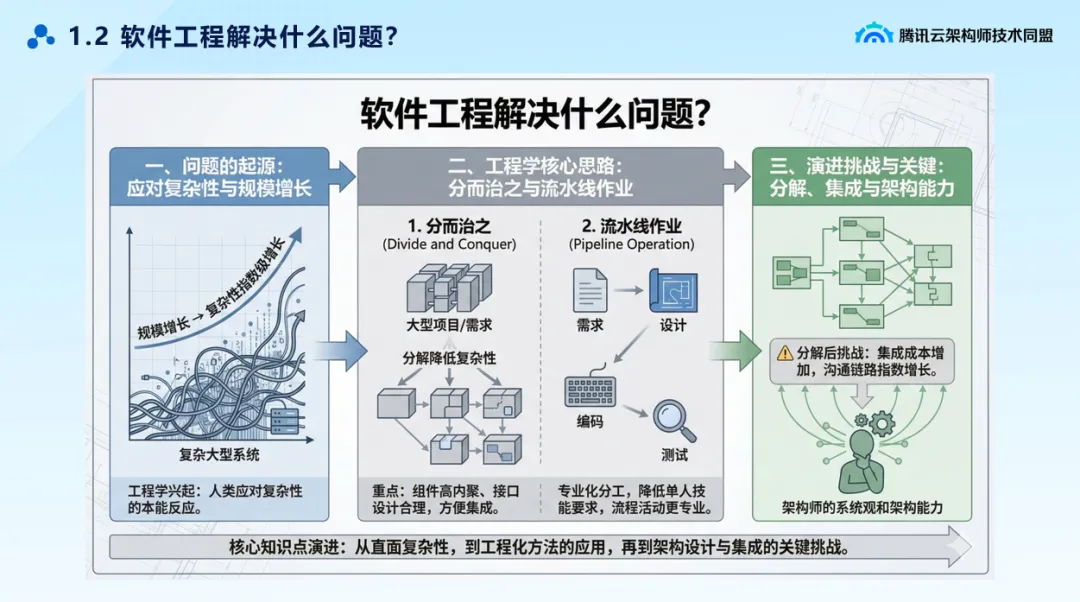
分而治之,把大系统拆分为细粒度组件/模块,定义接口再集成 -
流水线作业,通过需求、设计、开发、测试的专业化分工,降低对单个人的技能要求。
传统软件工程的误区
在早期软件开发实践中,行业内普遍存在一种导向:
初级开发者应当专注于编写高质量代码、熟练掌握 API 集成,将编码能力视为核心竞争力。笔者刚步入编程领域时,Java 8 尚未发布,开发者广泛使用 Google Guava 库来提升开发效率,其核心原因正是当时的开发模式完全面向代码。在需求实现过程中,大量工作集中在集合转换、数据处理等编码层面,只要在这些方面投入足够精力,就能高效完成代码编写。
但我们必须清醒认识到,代码仅仅是软件工程中的一个环节,而非全部。
《人月神话》中早已指出:十个人也无法在一个月生出一个小孩。并行工作虽能提升局部效率,却无法消除复杂系统固有的分解成本与集成成本。
核心问题在于:即便开发过程实现了并行化,复杂系统的拆解依然需要大量时间,系统集成与整合同样面临高昂成本。分解与集成,已然成为大型软件系统构建过程中最具挑战性的关键环节。
矛盾会在工程推进中不断转化:系统分解得越细致,团队沟通成本就越高,明确需求与目标的耗时越长,过长的传递链路也更容易引发理解偏差。分解仅仅是工程的起点,等到进入集成合并阶段时,需求往往已经发生变化。从最初的分解设计到最终的集成交付,周期短则数月,长则逾年,整个过程充满权衡与妥协。
没有银弹,只有焦油坑。
由此可见,传统软件工程大多只解决了次要任务—— 即通过代码实现模型的自动化执行。但软件构建的根本任务(将现实世界抽象为复杂概念结构、完成业务建模)依然复杂且难以自动化,系统的整体复杂度并未被真正解决,只是从技术实现环节前移到了业务建模环节。
需求乱、协作乱、系统乱、长期失控:这才是软件工程的真正复杂度。
这也正是许多人感到困惑之处:为什么行业长期以来都只聚焦于代码层面的问题优化?正如前文所提到的 Guava 库的例子,本质上依然停留在提升编码效率,并未触及软件工程的核心矛盾。
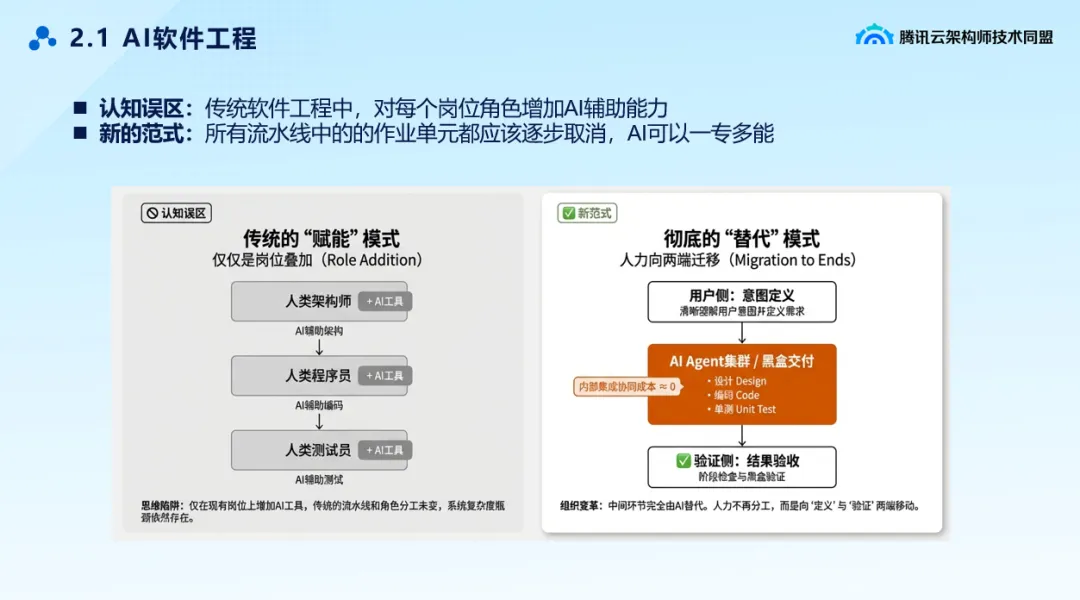
AI软件工程的误区
AI软件工程并非是产品+AI,开发+AI等。这些只是效率的提升
而是彻底重构开发模式。AI可以一专多能,单个组件内部的全流程流水线作业,都能由AI自主闭环完成,不再需要复杂的多角色分工。
这个过程优化的就是上面说的流水线作业。而架构师+ai。程序员+ai这些只能在单个个体上提效。流水线作业不优化。说明前面说的分而治之之后的合并过程还是一样复杂,这等于没解决主要矛盾。
流水线作业:思考这个问题的时候,你的身份可以先思考是一个组内。而不是在一个大公司里面的一个大领导的位置。大领导思考的流水线作业是各部门间的利益关系,你看到的往往不是软件工程本身。
方法论:从面向代码,走向面向规约(Spec Coding)
传统开发以代码为中心,程序员核心能力是写代码;AI时代以规约为中心,规约即代码(Spec as Programming)。开发者的核心能力不再是编写算法与逻辑,而是精准、清晰、可验证地定义需求、规则与约束,只要规约足够准确,AI就能自动生成可靠、可落地的完整代码。
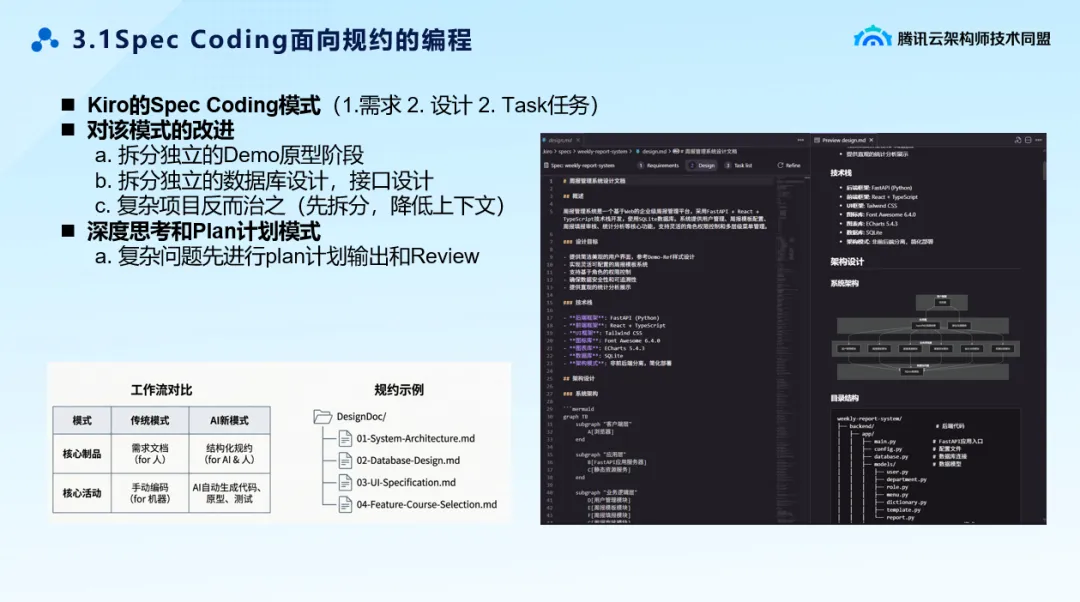
SDD VS BMAD
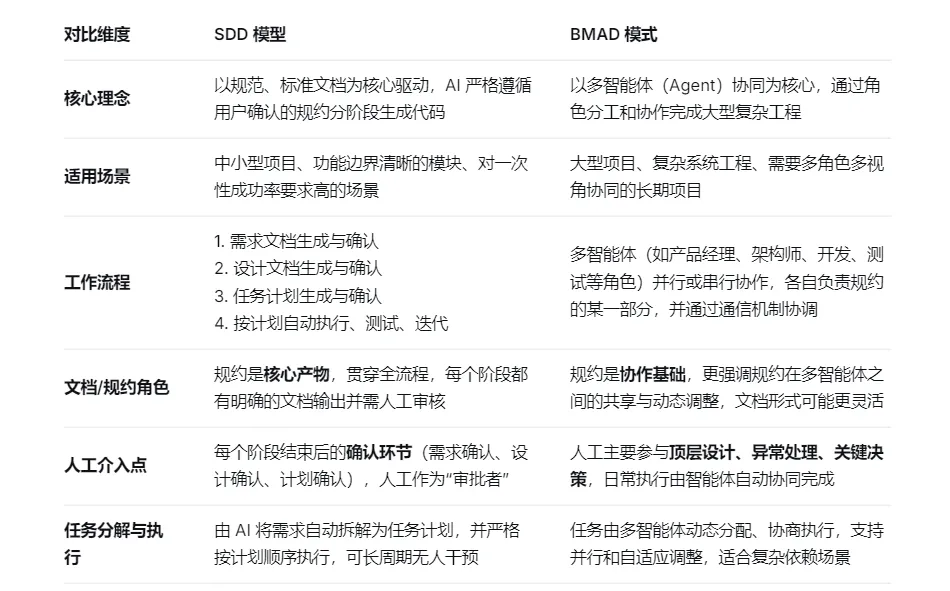
实践论: 亚马逊的Kiro这个AI IDE工具
这个工具何老师实践后,据说一次的成功率相当高。而且何老师还做了改进
常规的spec作业流程
-
需求->首先给我一份需求文档,它就会按流程、按场景、按可验证性详细的列出我要实现的最终的软件需求。然后确认后进入设计环节 -
设计->基于需求去出完整的组件模块的设计、接口的设计、数据库的设计。设计的文档出来以后又需要进行确认,完了没有问题,它才会进入到详细任务安排模式 -
task->执行任务,跑单侧,交给人验收结果
改进后
-
独立的Demo原型阶段 -
拆分独立的数据库设计和接口设计 -
提前增加一个复杂项目的分而治之的过程
原型的意义无非是为了快速的和用户去沟通确认,以减少后续需求变更。
组织级工程能力沉淀:实现Skill经验显性化
Skill可以简单的理解为提示词工程、上下文工程加MCP加代码片段,加参考模板、最佳实践的一个组合。
前面说的Spec Coding,还是个人层面的工作方式升级。但团队用AI,不能各写各的——需要标准化。我复盘了我们团队的现状,至少这些东西可以做成Skill:
-
需求文档的标准格式(减少来回确认) -
基于我们技术栈的Code Review检查清单 -
单元测试的断言模式模板
这些原本靠老带新口口相传,现在可以固化下来。AI生成代码前先过一遍Skill,输出自然符合团队规范,省掉大量沟通成本。但这里有个关键限制:Skill能解决单个模块的规范问题,解决不了”怎么拆系统”的问题。
所以核心点还是叫分而治之。
回顾一下:
-
大型的系统,你首先要分解的复杂性 -
分解完的单个组件,你的流水线作业协同的复杂性
回到开头的核心矛盾。AI能跑通单个模块的全流程——需求→设计→代码→测试,但”拆成哪些模块、模块间怎么接口”,还得人拍板。何老师强调的原型阶段,本质就是用低成本方式先验证分解方案。别等代码写完了才发现:这两个模块其实该合并,那个接口定义根本对不上业务流。他改进后的流程把”分而治之”显式提出来,我觉得是点睛之笔:
-
先跑独立Demo,和用户快速确认需求 -
拆分数据库和接口设计,提前暴露集成风险 -
再进入模块级的Spec Coding
原型不是为了好看,是为了减少后续返工。 这个顺序不能省。
企业级祖传系统的重构方法—AI逆向工程
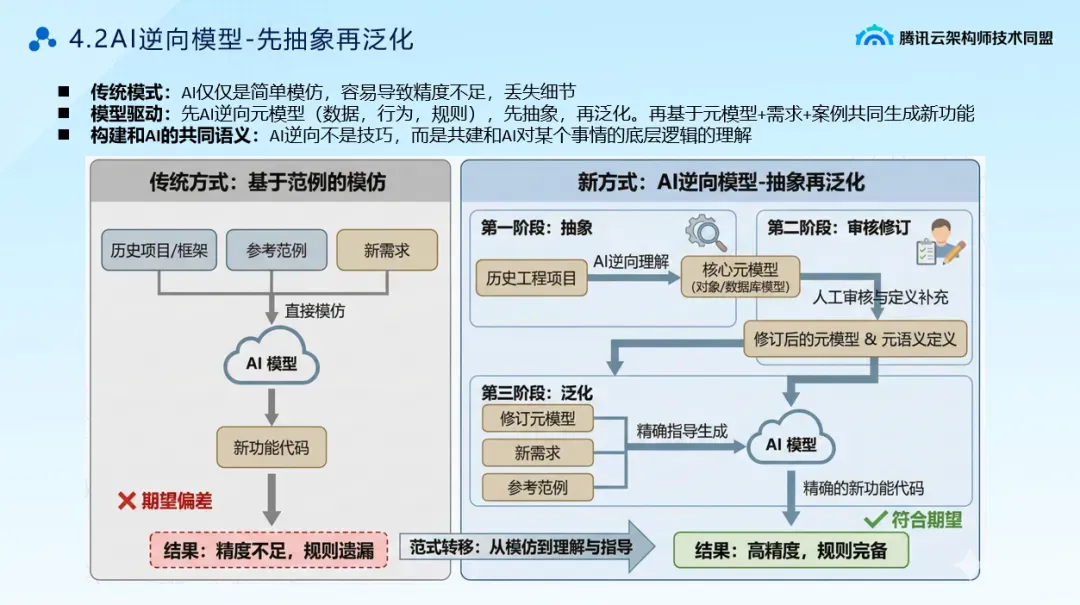
大家都很怕祖传代码,祖传项目,文档确实,维护的人也没有,完全没有用户手册。但是一般这种系统还存在都有他存在的意义。
AI时代是否可以使用代码反推文档。但是必须要注意先抽象,再泛化
抽象的过程
比如说我要写一个技术方案,我们原来经常用的方法就是我丢给他一个类似的技术方案,让他参考,让他模仿的技术方案,然后帮我输出一个新的技术方案。
但是我们在使用的过程中发现AI输出的技术方案,虽然说跟我原来的很类似很像,但是有一些关键点它丢失掉了。那么更好的解决方案是什么样?
我应该先丢给AI两到三个技术方案,让他先抽象出我写技术方案的核心的模式、要点、关键项、约束规则,把它形成一个写技术方案的元模型。
泛化
这个元模型我拿到了以后,我首先会对这个原模型进行审核检查和补充,然后接着我再将这个元模型加上参考的技术方案丢给AI,让它输出新的技术方案。
这就叫先抽象再泛化的过程。
通过这种方式,通过原模型的精确化语义的表达,那么这个时候AI输出的时候可以进一步的提升精度,也不会丢失相关的细节。我一直在强调,AI逆向不是技巧,而是共建和AI对某个事情底层逻辑的关键理解,这个点太重要了。
对比:传统做法 vs 元模型方法
|
|
|
|
|---|---|---|
| 输入 |
|
|
| AI理解层次 |
|
|
| 关键约束保留 |
|
|
| 输出稳定性 |
|
|
| 人工介入点 |
|
|
AI 逆向工程打破了 “源码无法反向生成文档” 的困境,可通过现有源码自动输出完整的需求文档、系统架构设计、用户操作手册等,显著降低老系统维护与迭代成本。其核心实现方法仍是先抽象元模型,再泛化生成:先从源码中提炼统一元模型,明确核心逻辑与关联关系,再基于该模型泛化生成各类文档,保证输出精度,避免 AI 直接复制参考内容时丢失关键细节。
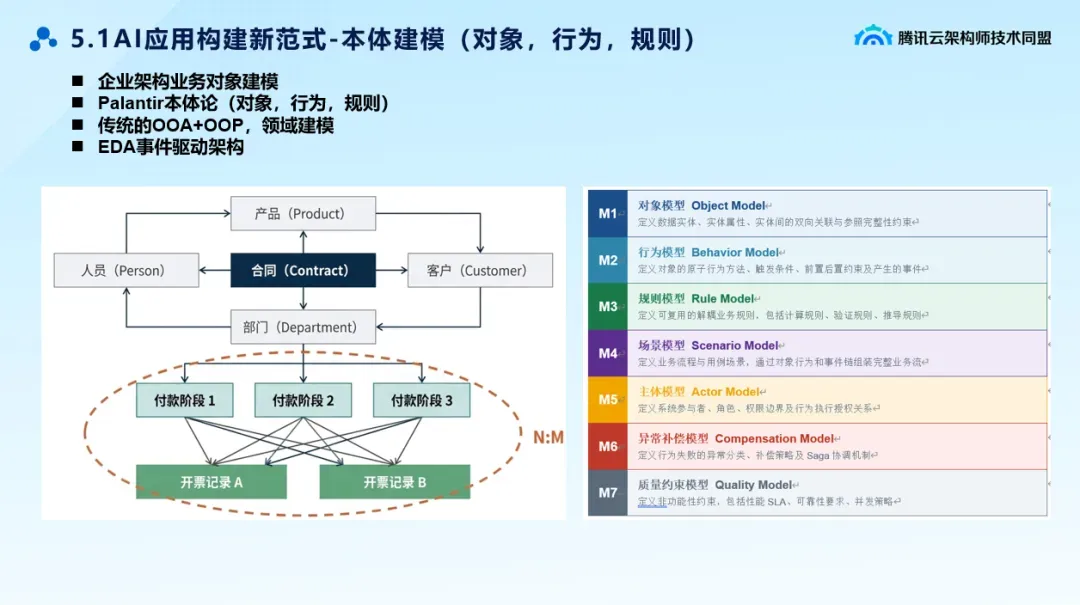
下一代软件工程范式:本体建模支撑AI原生应用
本体论的两种思想方式
-
类似于企业架构、业务对象建模,包括传统的面向对象分析设计理念,它本身也是类似于本体论的思想,但是这个模型建完以后,它更多的是驱动新的业务系统的构建。
本质是为了更大效率的写代码完成系统
-
另外一个就是Palantir的本体论的思想。Palantir的本体论,不是说你要去新构建一个新的OLTP系统,它更多的是在考虑你已经有的数据分析类的系统怎么跟你的类似于ERP、CRM这一些事务操作类的系统直接进行集成和打通,怎么样实现数据驱动业务,怎么样实现数据反向贯穿这个业务流程。
本质是系统构建好后的数据反推业务。也就是数字化
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
用一套统一模型同时干两件事:既能驱动新系统开发,又能支撑业务数据分析?
把整个本体模型分成了M1到M7,7部分的模型。
-
对象模型 -
行为模型 -
规则模型 -
场景模型 -
主体模型 -
异常补偿模型 -
质量约束模型
回顾Spec Coding面向规约的编程,在SDD的模式下面我们会拆分出相关的需求文档、测试文档和设计文档。我的理解,整个本体模型本身也是可以驱动整个应用系统构建的。整个本体模型也是一组相当精准的Spec的定义。
这比SDD更彻底——SDD还要拆分需求文档、设计文档、测试文档,本体模型本身就是最精准的规约定义。
通过跟AI大模型的交互,大模型自己评估完的结果就是这么一个本体模型,基本上可以完完全全的覆盖你传统的软件需求。这个本体模型是完全可以支撑你应用系统新的构建。
三步落地
他演示的实操视频已经跑通:
-
建本体:基于原始需求快速生成M1-M7模型,配套编辑器人工修正 -
配能力:基于本体构建底层Skill包(提示词+工具+代码模板) -
搭应用:本体模型 + Skill包 → 前端轻应用(AI语义对话 + 传统UI结合)
结果:系统不是只有数据增删改查,而是自带业务语义、能自我迭代——这才是真正的AI原生,不是套个AI壳子。
感兴趣的可以看看原文。
何老师本人分享的原文:
B站视频相关视频主要讲解方法论。如下,第一个8分钟,第二个13分钟。
基于本体论思想,构建个人思维元模型(一)
基于本体论思想,构建个人思维元模型(二)
微信公众号主要讲解实操,原文很长,需要耐心阅读: