 夜雨聆风
夜雨聆风





连Anthropic自己都翻车了,但源码里藏着一份教材
3月31日,Anthropic更新Claude Code的npm包时,顺手把一个60MB的调试文件打包进去发布出去了。
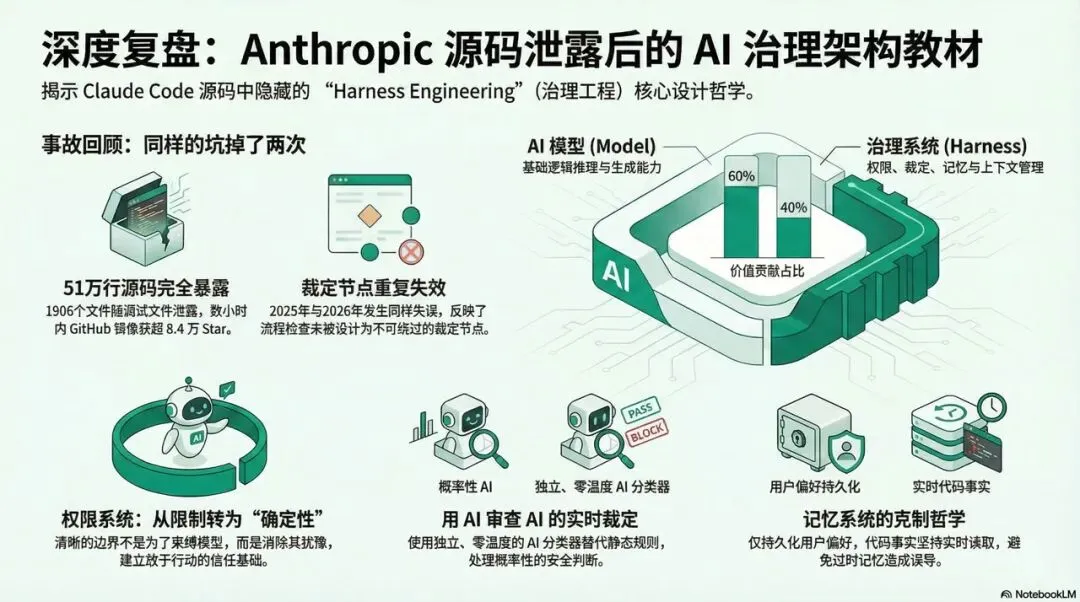
任何人都可以用这个文件还原出Claude Code完整的TypeScript源码。1906个文件,51万行代码,全部暴露。安全研究员Chaofan Shou——Solayer Labs的一位实习生——第一个在X上发出来,帖子很快累积了超过2800万次浏览。几小时内,源码被镜像到GitHub,获得超过8.4万个Star,8.2万次Fork。
Anthropic随即删包,发声明,承认是”人为失误”,”没有客户数据或凭证被泄露”。
然后更尴尬的事情被翻出来了:这不是第一次。2025年2月Claude Code刚发布时,同样的事故发生过一次,当时Anthropic紧急删除了旧版本。一年多过去,同样的错误,同样的地方,又来了一遍。
我看到有人评论:Anthropic的构建流水线可能需要Claude Code来审查一下。这个玩笑够狠,但也够准确。
NotebookLM的音视频概览,解读的比较通俗易懂,对于时间比较紧张的读者朋友,可以听听,会有启发。
先说这件事本身
这个失误有一个值得注意的背景:Anthropic在3月一共发布了十几个Claude Code版本,引入了自主权限委托、移动端远程执行、AI调度的后台任务……功能扩张速度和发布频次都到了一个新高度。出事的版本,恰好就在这个月末。
功能扩张和流程失控,往往是同一枚硬币的两面。
Anthropic在声明里说”正在推出措施防止再次发生”。这句话是真的——但它同时也是一个判断工程问题:这类发布前的检查,到底有没有被设计成不可绕过的裁定节点?还是依赖于某个人”记得做”?
如果是后者,那和”规则写在文档里”没有本质区别。规则覆盖已知情况,裁定层处理的是”有没有人必须在这里说可以”。一个配置文件的检查,如果可以被任何人在任何时候跳过,它就不是裁定节点,只是建议。
源码里真正值得看的东西
这次泄露吸引了大量工程师去分析Claude Code的内部架构。看完这些分析,有一个判断很清晰:Claude Code好用,不是因为它调用了一个更强的模型,而是因为它在模型外面建了一套认真的Harness。
我们上一篇刚讲完Harness Engineering。这份源码,是一份活的教材。
第一个值得记下来的设计:权限系统的真实意图
外界普遍把Claude Code的四层权限流水线理解成”安全措施”。但一位前Anthropic工程师给出了一个更准确的解释:这套权限系统最初的设计意图,不是限制,而是给模型足够的确定性,让它敢于执行。
没有清晰边界的Agent,在每一步都在犹豫”我能做吗”——这种犹豫会真实地降低它的执行质量。有了边界,它在边界内直接行动,边界外才停下来问人。
安全边界不是能力的限制,而是信任的基础。因为用户相信系统有底线,才敢给它更大的权限。这个逻辑翻过来看,对所有Agent产品设计都适用。
第二个值得记下来的设计:用AI审查AI
这套系统里危险命令的拦截,不是靠规则列表,而是靠一个独立运行的AI分类器——用Claude Sonnet(温度设为0,确保确定性输出)来判断主AI想要执行的操作是否应该被放行。
这不是规则,这是裁定机制的工程化实现。
规则能覆盖已知情况,但规则有边界。Anthropic的工程师们清楚地知道规则列表会有漏洞,所以在规则层之上加了一个概率性的裁定层。用AI来做实时裁定,而不是让规则列表独自面对所有情况——这个设计决策,恰好就是判断工程在系统层面的落地。
第三个值得记下来的设计:记忆系统的克制
Claude Code的自动记忆功能,只记用户偏好,不记代码事实。
原因很简单:代码会变,但记忆不会自动更新。如果记忆里存着”函数X在文件Y的第30行”,下次对话时代码已经重构,这条记忆就成了误导。
所以它的设计决策是:代码相关的事实,永远实时从源码读取;只有人的判断标准和偏好,才值得被记住。
这是一个关于”什么应该被持久化”的清醒判断。在Agent系统里,错误的记忆比没有记忆更危险。
泄露本身带来了什么
这份源码现在已经被镜像到互联网的各个角落,Anthropic的版权删除申请短暂下架了8000多份副本,但这个数字本身说明了问题——内容已经扩散,删不完了。
竞争对手现在有了Claude Code完整的架构蓝图。Cursor、Copilot、Windsurf不需要逆向工程,可以直接研究权限系统、多Agent协作框架、上下文压缩逻辑。这是真实的竞争情报损失。
但还有另一面:工程师社区的自发分析,在几小时内产生了大量高质量的架构解读。那句评论说得有意思——”这不只是暴露了代码,而是暴露了一份现代AI Agent系统应该怎么建的教材”。
Harness Engineering作为一个概念,在这次泄露之后获得了比任何技术文章都更直观的佐证。
写在最后
Claude Code泄露事件里,有两件事同时为真:
Anthropic在构建AI安全边界这件事上,做得相当认真——源码里的权限系统、裁定机制、记忆管理,都是经过深度设计的。
但Anthropic自己的发布流程里,有一个基础的裁定节点失效了,而且失效了两次。
这两件事不矛盾。它们共同说明的是:懂得如何为AI设计裁定机制,和真正把裁定机制建进自己的工程流程,是两回事。
知道是一回事,落地是另一回事。
我是「AioGeoLab」主理人塔迪Tardi,AioGeoLab是深度洞察AI第一性原理和应用实践的前瞻性研究实验室,目前有两个主要研究方向:
「塔迪GEO判断工程」是基于GEO的价值SEO化,在AI从“说”到“做”的重要跃迁阶段,试图回答,如何让AI敢于行动、不因为责任问题而畏手畏脚,而做的一个前沿研究项目。
「塔迪硅基禅心」是传统东方智慧、未来AI前沿、当下应用实践,深层共鸣的探索。不是用AI解读经典,也不是用经典指导AI。 这是一场跨越2500年的对话,在算法与古老智慧之间,照见意识、智能与存在的本质。 塔迪的微信 – tardyai2025。