 夜雨聆风
夜雨聆风





怎么快速分析读取源码生成文档?好用工具推荐:Zread | Claude 上下文压缩算法全解析
大家好,我是小松鼠。
一名AI时代的学习者,专注探索个体在新时代的生存模式。
这是我的 第 66 篇 AIGC 文章。
claude code的源码的风波还没有结束,每天都有新的消息,简直是快乐源泉~~
本篇我会借着这个话题和大家重点讲两个东西,
第一,有没有什么好用的工具能够快速的去解析源码,并且生成好看的文档。
第二,来重点讲一下cc的上下文压缩算法。
一、工程文档分析工具-Zread
很多小伙伴,在接触一些源码工程文件时无从下手,
即使是用了Claude自带的/init命令去分析,也始终觉得看不懂。
智谱官方出品的一款CLI工具,安装使用非常简单,我会把命令列给大家。
- 1.安装
npm install -g zread_cli- 2.安装后启动
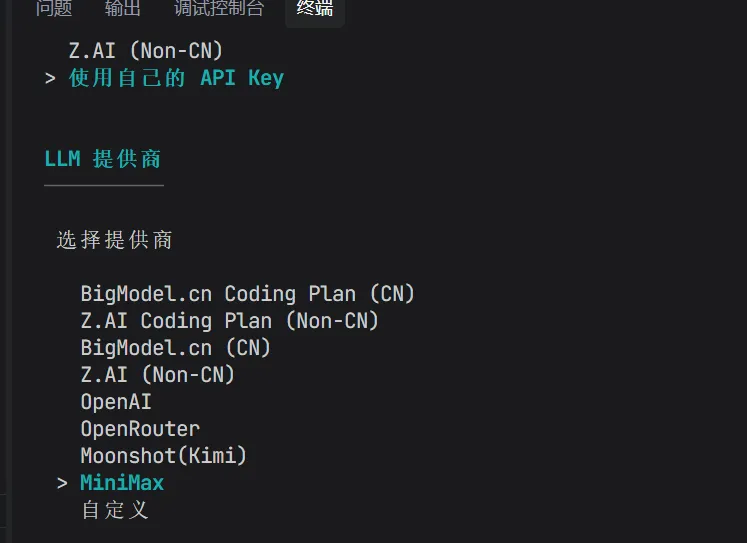
Zread- 3.选择登录方式(就是输入自己的APIkey)
非常好的一点是,它支持各种API key,比如我用的是minimax,一样可以正常使用。
- 4.启动完成后运行分析项目
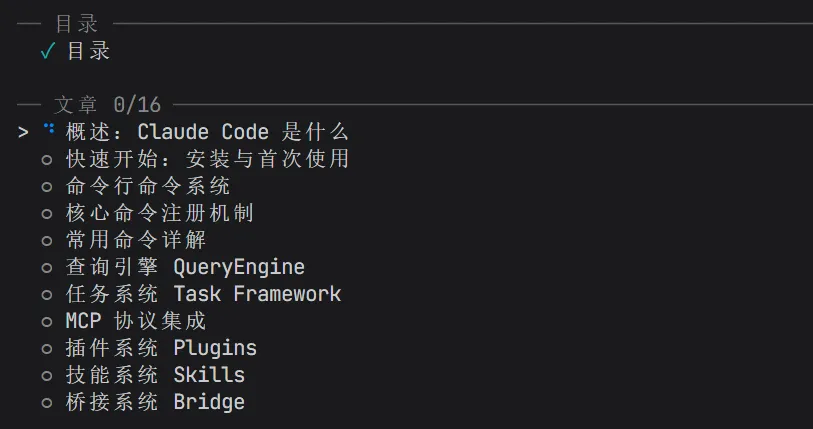
他会提示你是否要生成文档,敲回车就可以了
随后就分析我的工程目录,然后生成了如下的大纲,
再一个个去生成文档。
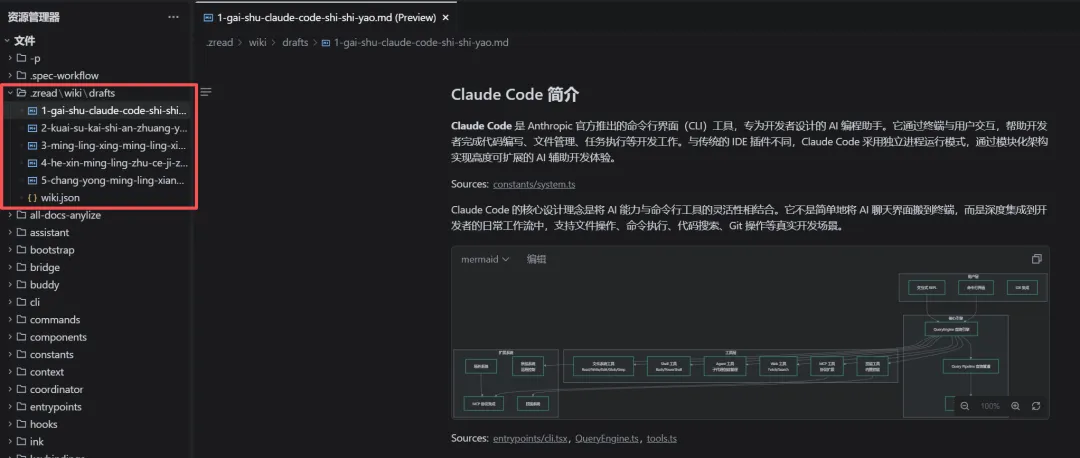
- 5.生成各个模块的md说明文件
耐心等吧,生成的md文件会放在项目的.zread目录。
- 6.可以浏览器预览效果,看起来很不错
也可以等待生成完毕后,用zread browse 命令,打开一个web窗口。
注意,这是个静态网页,你可以部署到自己的网站上去。
命令汇总:

强烈建议大家去安装使用一下Zread,对我们AI时代去提效学习很有帮助,
好了,接下来我们开始讲本篇的主角,上下文压缩算法。
小松鼠提醒下,生成文档,不代表你学会了。
就比如下面的内容,是我结合文档和源码学习之后才输出的。
只有你理解后的结构化的东西才是知识,否则只是无用的信息而已。
二、上下文管理是什么
先达成共识:大模型没有“记忆”
上下文的概念,在我们相关的文章中出现过多次。
总之,每次我们向官方的模型接口发送消息时,实际上是把我们跟大模型的所有对话,全部塞进数组传过去的。
而不是大模型记住了你的对话。
这些对话是记录在我们本地的。
而大模型本身对单次的数据长度是有一定限制的,也就是所说的上下文窗口。
(随着你和大模型的对话越来越多,每次一起传过去的内容就越来越多)
那么,如何更高效地利用这个窗口,以及压缩我们一些无关的信息,就成了agent必须要研究的方向。
当会话越来越多,上下文装不下了怎么办?
Claude Code的解决方案是:
不用等到接口返回说塞爆了,才想起来去做压缩。
而是在运行的过程中,就已经自己偷偷做笔记,把旧内容压缩成摘要。
Claude Code用了一套压缩工具箱,针对不同场景用不同工具。
三、微压缩——每轮都在做的轻量清洁
微压缩每轮查询前都会执行,耗时<1ms,纯规则操作,不调用LLM。
它只压缩工具输出,比如文件读取结果、Shell命令输出、搜索结果等。
这些内容通常很长但语义不重要,可以用[Old tool result content cleared]代替。
因为工具输出通常很长但不重要——比如你运行ls -la显示的100行文件列表,压缩后只需要一个标记告诉模型”这里有个工具结果但已经被清理了”,模型就能理解上下文,不需要真的传输那些内容。
微压缩有两个调用方式:
方式A:超时触发微压缩
超过一定时间(比如1小时)没说话,Claude Code在本地判断:当前时间减去最后一条助手消息的时间戳,是否超过了60分钟?这个判断是在本地做的,不是API告诉它的。如果超过了,Claude Code就主动清理那些”旧的工具输出”。
具体删的是什么?是工具调用返回的结果(tool_result),比如文件读取内容、Shell命令输出、搜索结果。普通对话消息不会被删。
为什么这么做?因为Claude Code赌的是——长时间idle后继续工作,那些旧的工具输出大概率跟现在没关系了。删掉能省token,但确实有丢失上下文的风险,所以只删工具输出,保留用户和助手的对话本身。
const keepRecent = Math.max(1, config.keepRecent)const keepSet = newSet(compactableIds.slice(-keepRecent))保留配置中设定好的,最近N个工具结果,之前的都清空。
方式B:通知API缓存去做微压缩调整
在说这个设计之前,先要搞清楚API缓存的真正作用。
我们每次发请求时,会把完整的历史消息都发过去。API服务器收到后,会把这次请求的内容缓存起来。下次请求时,如果发现”这段前缀我之前处理过”,就跳过计算直接用缓存结果。
缓存帮API省的是”计算过程”,不是”发送的token量”。你发的token量是一样的,只是API不用重复计算了。
也就是说,cluade code这个cli,不仅考虑了本身运行环境中,本地的上下文管理,
还考虑了,如何让远端模型的api调用更加的精准,不浪费算力。
这里是真不好理解,画个图吧~~
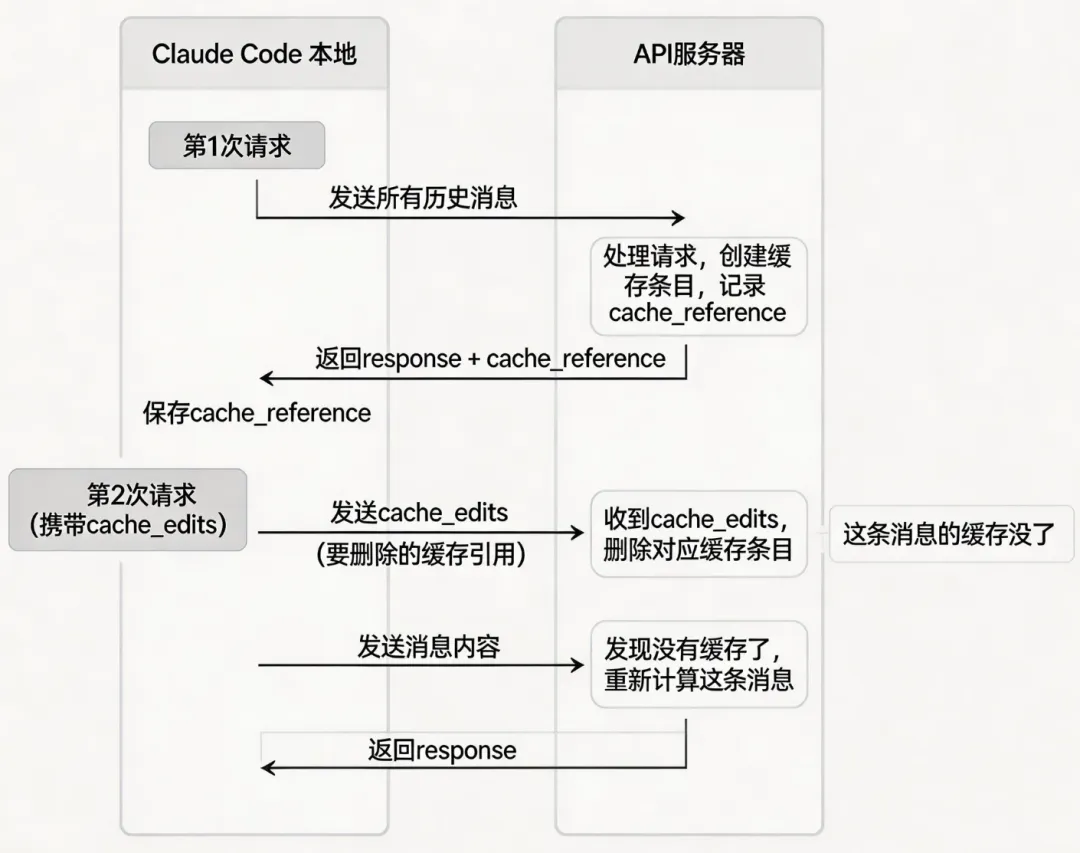
解释一下:
Claude Code在发送API请求时,会在请求体里携带一个cache_edits字段,告诉API:”不要用这些缓存结果了,把它们删掉”。
{"messages":[...],"cache_edits":[{"type":"delete","cache_reference":"xxx工具结果的引用"}]}为什么要删缓存?
假设我们之前判定某些旧工具输出没用了(时间触发微压缩认为这些过时了),本地消息内容可能改成了[Old tool result content cleared]。
但API服务器端的缓存还保存着”这条消息我之前处理过了“的记录。
如果不删掉这个缓存,API会认为”这段我之前算过,直接用缓存就行”。但这个缓存里存的是旧的工具输出结果,这些结果已经没意义了。API为这些无用的结果”跳过计算”节省的是无意义的算力。
注意哦,这里它并不是跳过,而是又重新用了缓存中的计算结果,实际上这部分结果已经毫无意义了。
通过cache_edits删掉这个缓存后,API下次就会重新计算这条消息。虽然token量没省,但避免了为”已经没用的旧结果”浪费计算资源。
所以cache_edits节省的不是token,而是API的计算资源。
asyncfunctioncachedMicrocompactPath(messages, ...) {const toolsToDelete = mod.getToolResultsToDelete(state)// 创建cache_edits块,交给API层处理const cacheEdits = mod.createCacheEditsBlock(state, toolsToDelete) pendingCacheEdits = cacheEdits// 返回消息根本没变!本地历史还是完整的return { messages }}这样设计的好处是:Claude Code本地保存着完整的消息历史(方便后续追溯),同时通知API”不要再为这些旧工具结果维护缓存了”。省的是API的计算资源,不是发送的token量。
思考一个问题:为什么有些国产模型在CC上表现不佳?
claude code这个壳实际上是专门为claude code模型准备的,他自己的模型中对这些特殊的标志位有一些黑盒处理,我们看不到。
假如说我们用一些国产的一些模型API调用,它远端并没有像claude code本身的模型一样去支持对这些特殊标志位的识别,那使用效果自然大打折扣。
四、自动压缩的触发时机
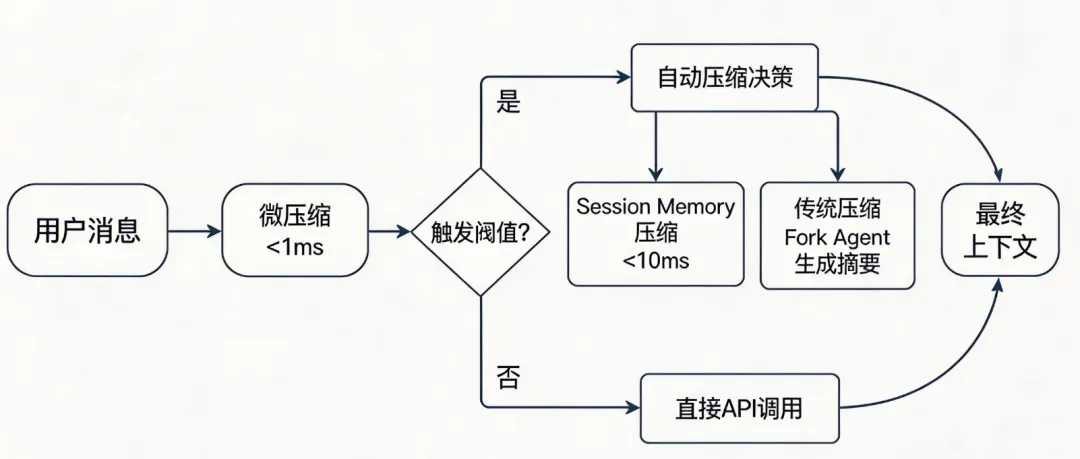
当上下文快满时,Claude Code需要决定”要不要压缩”以及”用什么方式压缩”。
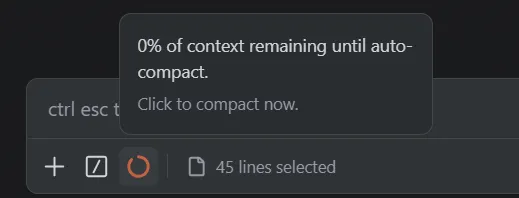
我图中已经用满了,它快触发自动压缩了。
那么请问我本地是怎么知道这个需要压缩的量的呢?
阈值怎么算?
有效上下文窗口 = 模型上下文窗口 - 摘要输出预留(20K)自动压缩阈值 = 有效上下文窗口 - 13K缓冲以Opus 200K上下文为例:有效窗口18万token,触发点在16.7万token左右。
有效上下文窗口 = 200k-20k = 180k触发点 = 180k-13k = 167k还有两个保护机制:
- 1.断路器:连续失败3次就跳过,不再尝试。代码注释里有个真实数据——2026年3月10日,发现1279个会话连续失败50+次(最多3272次),每天浪费约25万次API调用。
这是源码里的注释。。。并且这次压缩它调用的是远端的API来思考压缩。
自动压缩会优先尝试Session Memory压缩(不调API,用本地已有的记忆文件),失败才回退到传统压缩(Fork Agent调API生成摘要)。
- 2.递归保护:压缩代理(querySource是session_memory或compact)不会触发自动压缩。
防止 "压缩代理触发压缩→触发代理需要压缩→无限递归"。整体流程一览
五、Session Memory压缩
刚有提到压缩会优先使用session memory压缩,最后才会用到fork agent。
说白了就是利用平时存储的记忆,再加上最近几轮对话。去生成压缩后的文本内容。
Session Memory压缩 = 已有摘要(Session Memory文件)+ 最近的消息
要理解这个工作原理,需要先回答下面这几个问题。
- 1.记忆是什么时候存的?
每轮对话结束后,Claude Code会自动调用extractMemories,把对话中的关键信息提取成结构化的摘要,写入Session Memory文件。这个过程在后台悄悄运行,用户完全看不到。
- 2.什么叫摘要?怎么识别的?
extractMemories会分析对话内容,通过LLM来识别哪些是关键信息。比如:
– 你让Claude修复bug → 提取”修复了xxx文件的yyy问题”
– 创建了哪些文件 → 提取”创建了xxx文件”
– 遇到什么错误 → 提取”遇到了xxx错误,已解决”
这不是简单的关键词匹配,而是理解对话内容后提取的语义摘要。
没错,他偷偷就在消耗你的token在做这些记忆的事情~~
- 3.用户能在对话框中看到吗?
不能。Session Memory文件存在本地,用户完全看不到。它是Claude Code的内部记忆,只有Claude Code自己会读取。
- 4.Session Memory满了怎么办?
如果当前这轮对话有很多新内容,extractMemories还没来得及提取,或者对话太复杂摘要写不下,Session Memory文件里的内容就不够完整。
这时候就回退到传统压缩,让LLM重新生成一个更完整的摘要。
设计哲学
回过头看,Claude Code的上下文压缩设计体现了几个核心原则:
- 1.渐进式降级:尽可能用廉价的规则操作延迟昂贵的LLM调用。从微压缩(<1ms)→ Session Memory压缩(<10ms)→ 传统压缩(5-30s),每层都比上一层代价更高。真没那么玄乎,就是不同场景用不同工具。
- 2.缓存优先:微压缩专门设计了缓存编辑路径不破坏API缓存;传统压缩通过Fork Agent共享API缓存。
- 3.安全性保证:永远不切断tool_use/tool_result配对,永远不切断共享message.id的消息块。
六、传统压缩的优化:Fork Agent 调用远端API压缩
当我们本地的压缩不足以处理问题的时候,就需要让远端大模型API来帮助我们进行压缩了。
这里有意思的一点是,调远端模型API的时候用到了fork Agent。
为什么用Fork Agent而不是直接调API?
直接调API的方式是:把完整的历史消息都发给API,让它生成摘要。
用Fork Agent的方式是:创建一个子进程,复用主会话的一些参数,只发一个摘要请求给API。
两者的区别:
直接调API:发送所有历史消息给API → API要完整处理一遍 → 慢且贵
Fork Agent:因为复用了主会话的缓存key(system prompt、tools、model、messages前缀都相同),API发现”这段前缀我之前处理过”,直接用缓存跳过计算 → 只需要发一个摘要prompt → 快且省
所以用Fork Agent的优势是:省token(不用发所有历史)、省计算(API跳过历史部分)、快(只需要处理摘要请求)。
const result = awaitrunForkedAgent({promptMessages: [summaryRequest], // 只有摘要请求消息 cacheSafeParams, // 复用主会话的缓存参数maxTurns: 1, // 限制只产生一个回复skipCacheWrite: true, // 不写新缓存})为什么能共享API缓存?因为API服务器的缓存key只依赖:system prompt、tools、model、messages前缀。子代理只发一个摘要消息,这些条件完全一致,所以能命中主会话的API缓存。
这里有个容易混淆的点:Fork Agent不是访问本地的缓存,而是共享API服务器端的缓存。
数据存在哪:
– 对话历史、Session Memory:存在本地文件里,重启后还在
– API返回的cache_reference:存在Message对象里,跟着messages一起持久化
– API服务器的Prompt Cache:存在API服务器端,重启本地不影响,但长时间不请求可能会被清理
所以”共享”发生在API服务器端,不是在本地。
Claude Code本地并没有存什么缓存,cache_reference只是API返回的一个索引值。
另外,还需要强力禁止工具调用的前导词
这里怎么理解?
可以看到上面代码的参数里,压缩代理只有一次机会(maxTurns: 1)。
压缩代理被设置为maxTurns: 1,只能生成一轮回复。
这时候上下文已经快满了,如果去调用工具可能会导致意想不到的情况
流程是这样的:
- 1. 发送请求给API,指令是”只能回复文字,不许调用任何工具”
- 2. 模型如果忽略指令,尝试调用工具
- 3. Claude Code的canUseTool函数返回deny,拒绝所有工具调用
- 4. 但模型已经用掉了这一轮的机会
- 5. maxTurns: 1 = 只有一次机会,没有第二次
- 6. 这轮没有文字输出 → 压缩失败
所以压缩时,连skill、MCP、内置工具全部都不能用。
压缩的目的是生成一段文字摘要,如果模型跑去调用工具了,就没办法在这轮里生成摘要了。
七、压缩算法
整个压缩的过程中,它会用到一个有意思的算法,我需要把这个讲一下。
在说这个复杂的算法之前,先解释几个概念:
我们经常用的deepseek来举例,对话时,会收到所谓的思维链。
Claude code使用时也是一样,会把思考过程流式输出。
- 1.流式输出: API通过SSE连接边算边返回数据,就像打字一样一点点出来。一个完整的回复会被切成多个”块”(block),比如:
块1: <thinking>我想想这个问题...</thinking>块2: <tool_use>调用Read工具读取文件</tool_use>块3: <text>好的,我读取到了这个文件的内容</text>这三个块共享同一个message.id,因为它们是同一次API响应产生的。
这里好理解吧,我明明只问了一个问题,但是他打了好几段的话,实际上是这一个问题产生的。
- 2.中间切断: 假设有一组消息,Index N到N+3都属于同一个message.id。如果压缩时想保留N+2之后的消息,就相当于在中间”切断”了——把N和N+1给丢弃了。
- 3.tool_use/tool_result配对: 每个tool_result必须对应一个tool_use,通过tool_use_id来配对。就像写信和收信要对上号一样,API要求每个tool_result的tool_use_id必须能找到对应的tool_use。破坏配对会怎样? 如果压缩丢弃了tool_use,但tool_result还在引用它,API就会报错:”孤立的tool_result引用了不存在的tool_use”。
问题出在哪?
流式输出时,一个API响应会产生多个消息块,存储时这些块是分开存放的。比如:
Index N:assistant,message.id:X,content: [thinking]IndexN+1:assistant,message.id:X,content: [tool_use:ID_123]IndexN+2:assistant,message.id:Y,content: [text回复]Index N和N+1都是message.id = X,是同一次API响应。它们存储在不同的索引位置,但共享同一个message.id。
压缩时如果直接按索引”切断”(比如只保留N+2之后),就会在共享message.id的消息中间”切断”——把N和N+1丢弃了,但N+3的tool_result可能还引用着ID_123。这样就会丢弃了tool_use但保留了tool_result,破坏配对关系。
源码注释里的真实bug场景:
Session存储(压缩前):Index N:assistant,message.id:X,content: [thinking]IndexN+1:assistant,message.id:X,content: [tool_use:ORPHAN_ID]IndexN+2:assistant,message.id:X,content: [tool_use:VALID_ID]IndexN+3:user,content: [tool_result:ORPHAN_ID, tool_result:VALID_ID]如果startIndex=N+2(只保留N+2之后的消息):旧代码:检查N+2的tool_results,找不到,返回N+2normalizeMessagesForAPI合并后:msg[1]:assistantwith [tool_use:VALID_ID] ←ORPHAN被排除了!msg[2]:userwith [tool_result:ORPHAN_ID, tool_result:VALID_ID]API报错:孤立的tool_result引用了不存在的tool_use解决方案:向后搜索,把所有共享message.id的消息都包含进来
exportfunctionadjustIndexToPreserveAPIInvariants(messages, startIndex) {// Step 1: 处理tool_use/tool_result配对// 向前搜索,把包含缺失tool_use的assistant消息都纳入范围// Step 2: 处理thinking块分离// 向前搜索,把共享同一message.id的assistant消息都纳入范围}这样保证了:压缩后发给API的消息,永远不会切断tool_use和tool_result的配对关系。
设计哲学
回过头看,Claude Code的上下文压缩设计体现了几个核心原则:
- 1.渐进式降级:尽可能用廉价的规则操作延迟昂贵的LLM调用。从微压缩(<1ms)→ Session Memory压缩(<10ms)→ 传统压缩(5-30s),每层都比上一层代价更高。真没那么玄乎,就是不同场景用不同工具。
- 2.缓存优先:微压缩专门设计了缓存编辑路径不破坏API缓存;传统压缩通过Fork Agent共享API缓存。
- 3.安全性保证:永远不切断tool_use/tool_result配对,永远不切断共享message.id的消息块。
尾声:
今天我们又是讲了非常多的干货。
先是告诉了大家一个好用的代码工程分析工具Zread。可以方便的生成美观的文档。
但是就和你想的一样,这种生成的文档,涉及到一些复杂的功能,它会写一些神奇的东西让你看不懂。
如果你仅仅让AI生成了文档不去学习的话,是永远不会理解知识的。
就比如剩下我说的这些上下文管理和压缩的内容,是先有大纲的基础上,小松鼠去不断的结合源码,以及和claude code问询思考。自己理解的基础上,整理后得到的结果。
也许这些内容会显得有些枯燥,但学习就是这样的,只有深入思考,才能不断进步。
也不要怕难,慢慢就懂了。
世上无难事只怕有心人
看到这里了,如果觉得不错:
✓ 点个「赞」,让我知道你在看
✓ 点个「在看」,分享给更多朋友
✓ 点个「转发」,帮助更多人
✓ 加个「星标⭐」,第一时间收到推送
也可以加我的个人微信围观学习:archerqc

小松鼠爱你们!