 夜雨聆风
夜雨聆风





高质量AI数据集建设全流程文档
一、数据集建设的标准体系框架
高质量AI数据集建设需要遵循完整的技术标准体系。根据国家标准GB/T 36073-2018《数据管理能力成熟度评估模型》,数据集建设涉及数据管理、数据质量、数据安全和数据治理四个核心领域。
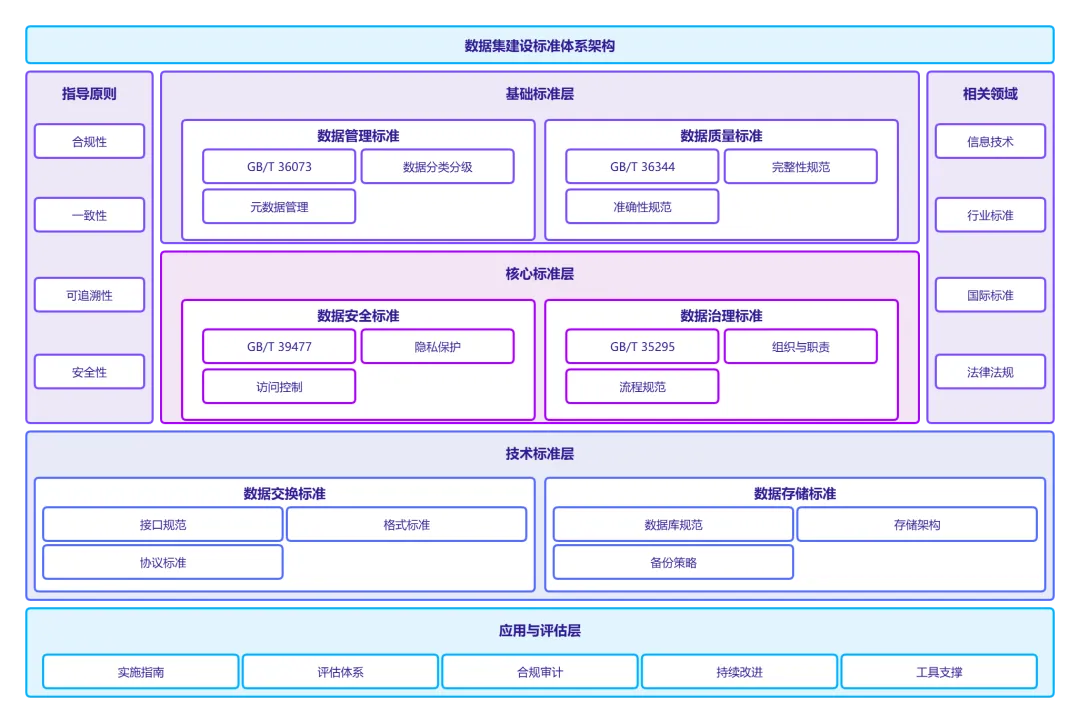
数据集建设过程中需要重点参照的标准包括:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
行业特定场景还需要参照相应行业标准,如金融领域的JR/T 0197-2020《金融数据安全 数据安全分级指南》、医疗领域的WS/T 500-2016《电子病历共享文档规范》等。
二、建设全流程操作指南
2.1 需求分析阶段
需求分析阶段的核心目标是明确数据集建设目标、范围和质量要求。
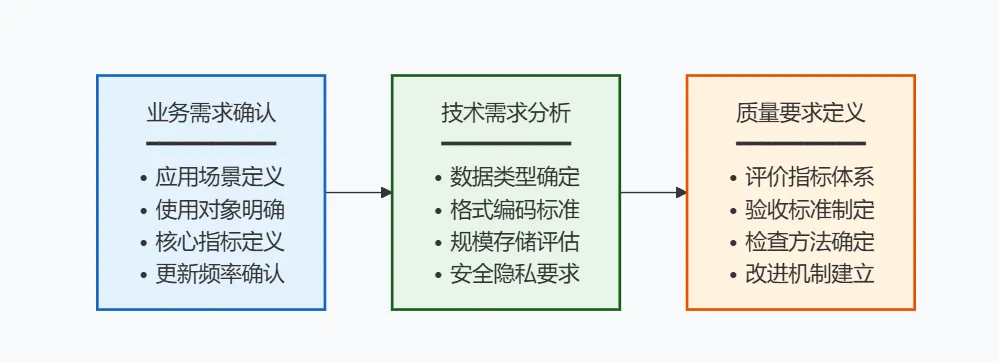
该阶段需完成三项核心工作:
-
业务需求确认:明确数据集的应用场景、使用对象、核心指标和更新频率要求。 -
技术需求分析:确定数据类型(文本、图像、音频、视频等)、格式编码标准、存储规模和安全隐私保护要求。 -
质量要求定义:依据GB/T 36344-2018制定包含规范性、完整性、准确性、一致性、时效性、可访问性六个维度的评价指标体系。
2.2 数据采集阶段
数据采集阶段的目标是获取高质量、多样化的原始数据。
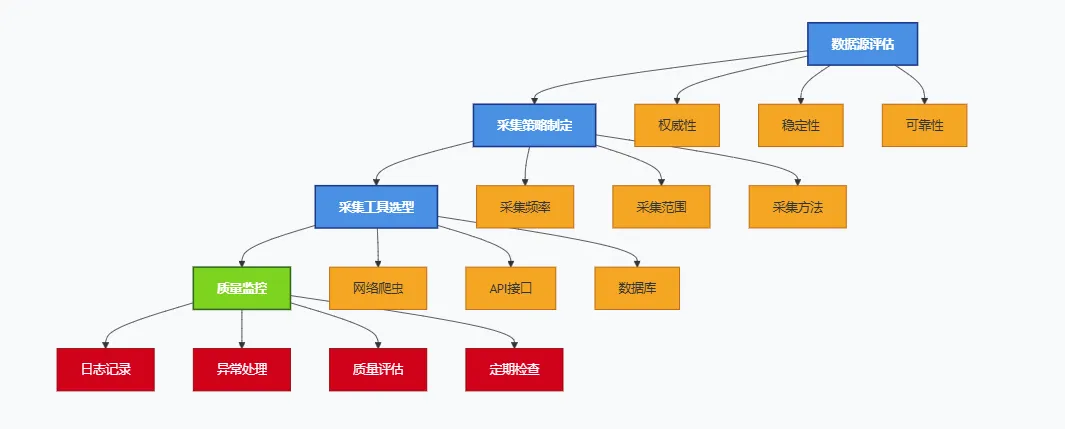
常用采集工具选择:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2.3 数据清洗与预处理阶段
数据清洗阶段是提升数据质量的关键环节,需遵循标准化流程。
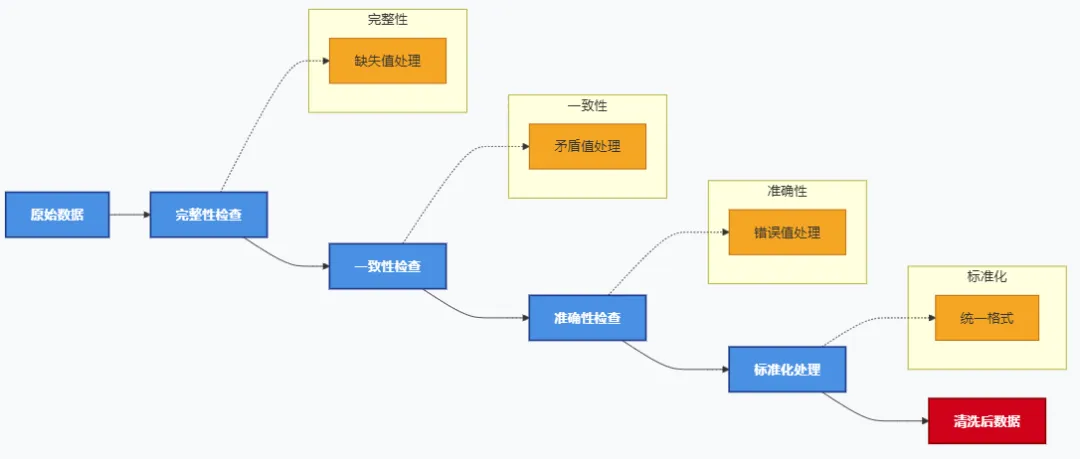
清洗过程中使用的核心工具:
-
Python数据处理库:Pandas、NumPy用于结构化数据处理 -
数据质量工具:Great Expectations、Deequ用于自动化质量检查 -
ETL工具:Apache Spark用于大规模数据处理 -
文本处理:NLTK、spaCy、jieba用于自然语言清洗 -
图像处理:OpenCV、PIL用于图像数据预处理
2.4 数据标注阶段
数据标注是构建高质量监督学习数据集的核心环节,需要严格的规范和质量控制机制。
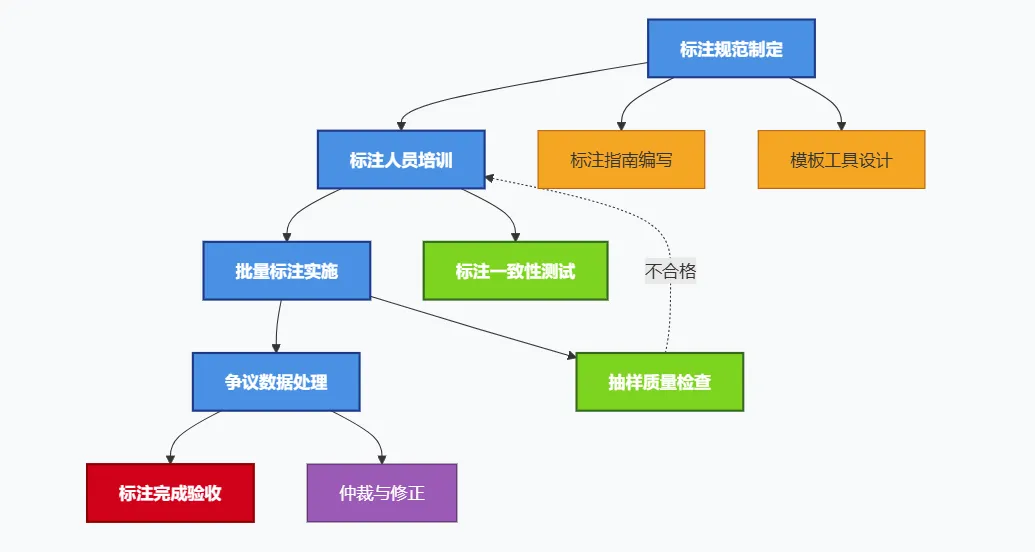
标注工具选型建议:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
标注质量控制的关键指标是标注者间一致性(Inter-Annotator Agreement),建议达到0.8以上方可验收。
2.5 数据存储与版本管理
数据存储阶段需要建立安全、高效、可追溯的数据管理机制。
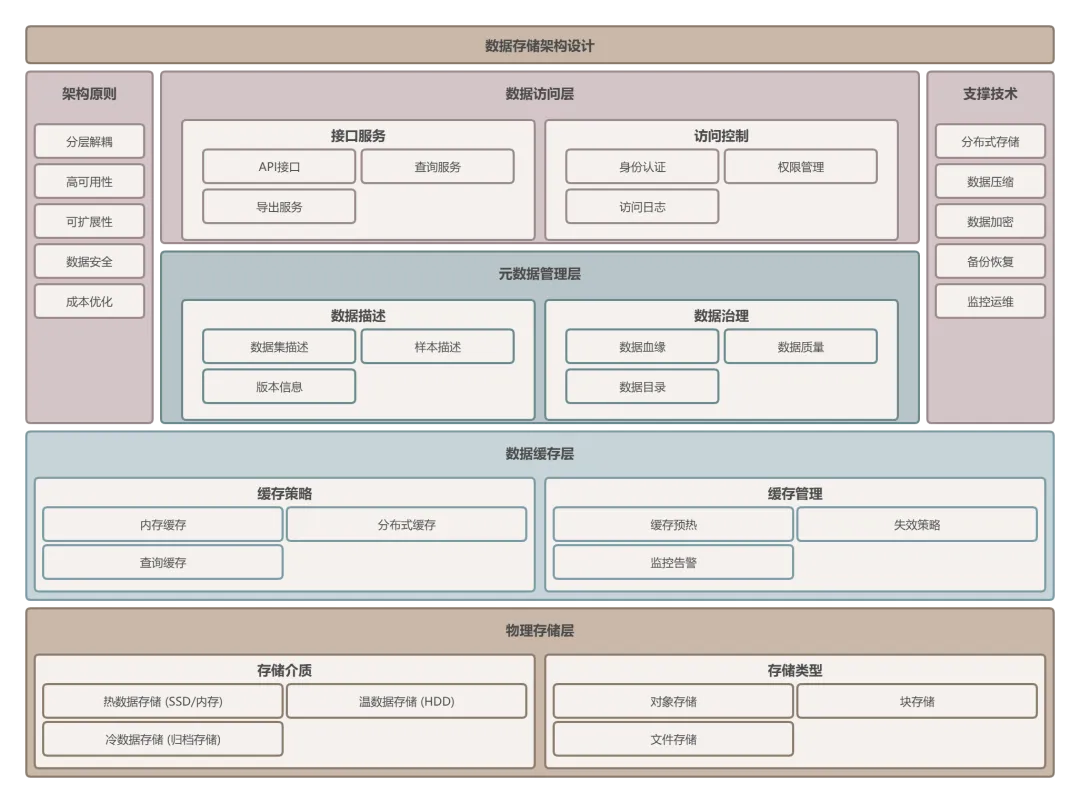
存储技术选型方案:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
版本管理采用语义化版本号规范:主版本号.次版本号.修订号(如V2.1.0),每次数据变更均需记录版本历史,包含变更内容、变更原因和责任人信息。
2.6 质量验证与评价
质量验证阶段采用GB/T 36344-2018定义的六维评价体系进行综合评估。
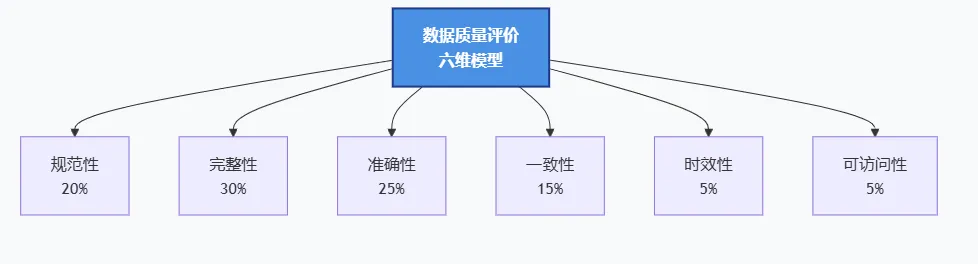
各维度评分标准:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
质量验证完成后,使用附录3中的质量评价报告模板生成完整的评估文档,包含数据质量评价、模型应用评价、分类准确性评价和综合评价建议四个核心部分。
三、标准化格式规范
3.1 数据格式选择
不同数据类型需采用标准化格式以确保互操作性:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.2 问答对标准格式示例
通识类文本问答对应采用JSON Lines格式,每行一个独立记录:
{"id": "qa_20260415_001","type": "general_qa","category": "technology","question": "什么是机器学习?","answer": "机器学习是人工智能的一个子领域...","metadata": {"source": "tech_encyclopedia","difficulty": "beginner","language": "zh-CN","quality_score": 0.95,"verified": true }}3.3 图像标注标准格式示例
目标检测任务采用COCO格式标准:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
四、常见问题与解决方案
4.1 数据质量问题处理矩阵
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
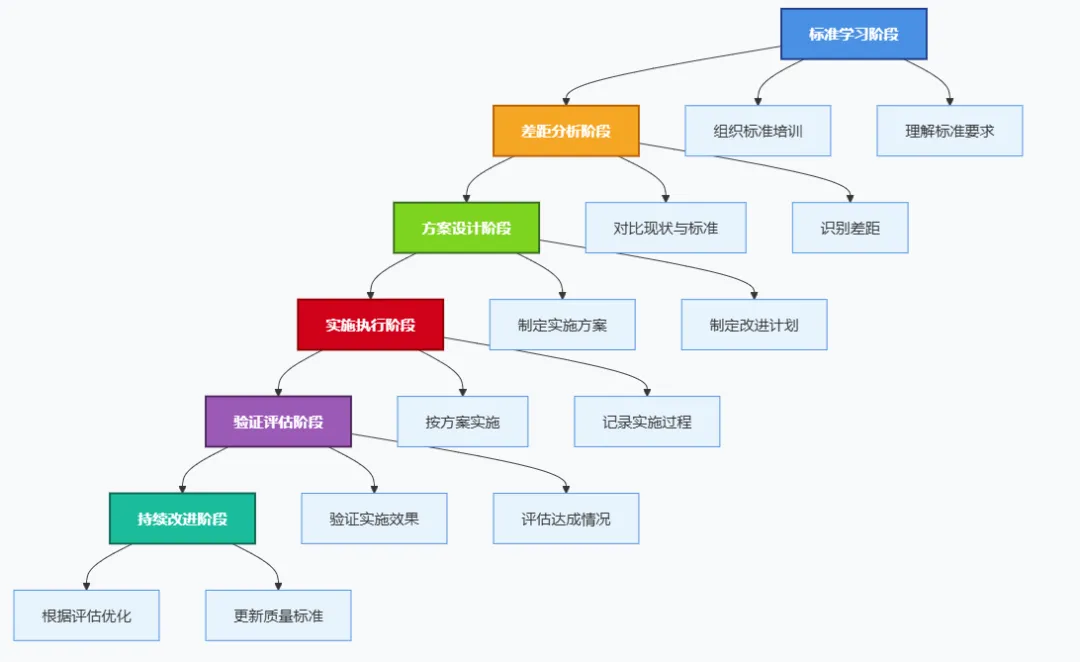
4.2 标准实施关键步骤
4.3 关键注意事项
-
需求阶段:避免需求不明确即开始建设,必须完成充分的需求分析和确认。 -
采集阶段:重视数据质量源头控制,严格审核数据源的合法性和权威性。 -
清洗阶段:清洗规则需保持一致,全过程可追溯,避免过度清洗导致信息丢失。 -
标注阶段:标注规范需明确详细,建立标注质量检查机制,计算标注者间一致性。 -
存储阶段:建立完善的数据备份机制和版本控制体系,实施数据访问权限管理。 -
验证阶段:质量检查需覆盖全部六个维度,模型验证需充分进行。 -
发布阶段:文档体系需完善,包含元数据、使用说明、许可协议等内容。
数据集建设是一项系统性工程,需要贯穿标准规范、流程管理和质量控制的全链条思维。通过严格遵循国标行标要求,采用标准化的格式规范和操作流程,可以有效保障数据集的最终质量,为AI模型训练提供可靠的数据基础。

广告人士勿入,切勿轻信私聊,防止被骗

